FineVLA là một framework mới cho fine-grained instruction alignment trong Vision-Language-Action (VLA). Paper gốc, project page và repo chính thức đều nhấn mạnh cùng một vấn đề: nhiều VLA policy hiện nay học từ instruction rất ngắn kiểu "pick up the cup", trong khi robot thật cần biết dùng tay nào, tiếp cận từ hướng nào, chạm vào vùng nào, xoay ra sao, và trạng thái cuối phải như thế nào.
Bài này hướng dẫn cách đọc và chạy FineVLA theo hướng thực dụng cho robot dual-arm. Bạn sẽ thấy FineVLA không chỉ là một model, mà là một hệ sinh thái gồm FineVLA-Tool để dựng data, RoboFine-Bench để đánh giá video understanding, RoboFine-VLM để annotate, và FineVLA-Policy để train policy. Nếu bạn mới bắt đầu với VLA, hãy đọc phần ý tưởng và smoke test trước khi đụng tới distributed training.
Nguồn chính của bài:
- Paper: FineVLA: Fine-Grained Instruction Alignment for Steerable Vision-Language-Action Policies
- Project page: finevla.xlang.ai
- GitHub: xlang-ai/FineVLA
- Benchmark: xlangai/RoboFine-bench
- VLM annotator: xlangai/RoboFine-VLM-397B-A17B
FineVLA giải quyết vấn đề gì?
VLA policy nhận observation từ camera, nhận instruction bằng ngôn ngữ tự nhiên, rồi output robot action. Với robot single-arm đơn giản, instruction cấp mục tiêu đôi khi đã đủ:
"Pick up the red block."
Nhưng với dual-arm manipulation, instruction này thường thiếu những chi tiết quyết định behavior:
Coarse instruction:
"Pick up the cup."
Fine-grained instruction:
"Use the right arm to approach the cup from the front-right side,
close the gripper around the upper body of the cup, lift vertically
until it clears the table, then keep the cup upright while moving it
to the target area."
Hai instruction trên cùng nói về một task, nhưng signal học được rất khác nhau. Instruction đầu chỉ nói what. Instruction thứ hai nói cả what và how. Với robot dual-arm, phần "how" thường là thứ làm policy khác nhau: active actor, approach direction, contact region, trajectory, orientation, object interaction, failure recovery.
FineVLA đặt giả thuyết rất rõ: nếu chỉ đổi language supervision từ coarse sang fine-grained, trong khi giữ nguyên video, action và state, policy có học behavior steerable tốt hơn không? Kết quả của paper cho thấy có, nhưng không phải cứ dùng 100% fine-grained là tốt nhất. Tỉ lệ trộn FG:Raw khoảng 1:2 đến 1:1 cho kết quả mạnh nhất.
Bức tranh tổng thể
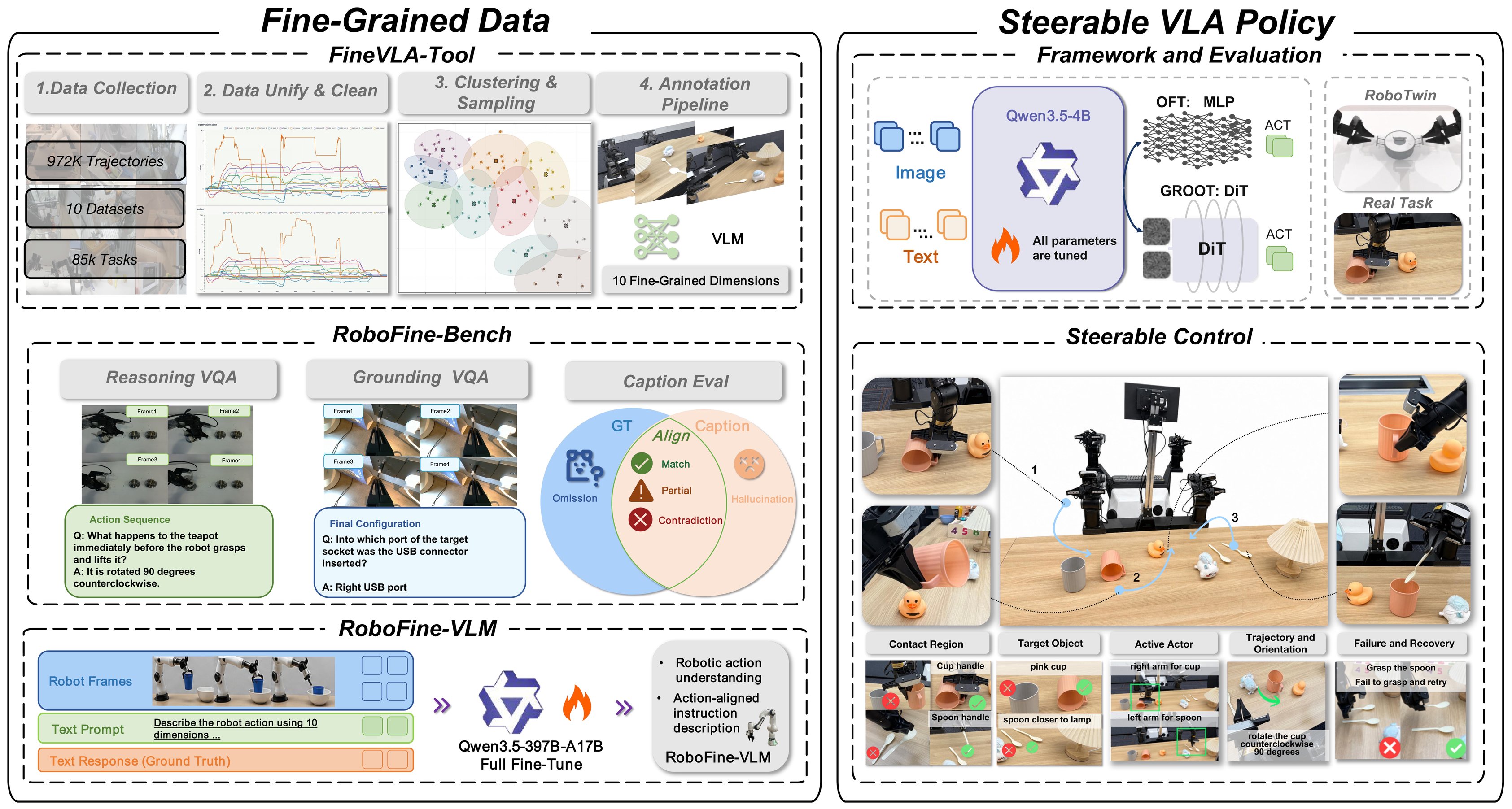
FineVLA có bốn phần chính:
Raw robot datasets
BridgeData-V2, BC-Z, RT-1, Galaxea, RoboMIND, RoboCOIN, RH20T, RDT, DROID
|
v
FineVLA-Tool
1. Convert to unified format
2. Canonicalize state/action
3. Cluster with DTW
4. Annotate 10 fine-grained dimensions
|
v
FineVLA-Data
47,159 human-verified fine-grained trajectories
|
+--> RoboFine-Bench
| 500 videos, 10,816 atomic facts, 1,030 VQA questions
|
+--> RoboFine-VLM
| Qwen3.5-397B-A17B fine-tuned as robotic video annotator
|
+--> FineVLA-Policy
StarVLA-OFT / StarVLA-GR00T policies
trained with Raw, FG, or mixed instructions
Điểm đáng chú ý là FineVLA không claim một architecture hoàn toàn mới. Paper cố tình dùng các policy framework có sẵn trong StarVLA để cô lập ảnh hưởng của instruction supervision. Nói cách khác, câu hỏi nghiên cứu không phải "action head nào tốt nhất?", mà là "cùng một action head, cùng một trajectory, nếu language mô tả chi tiết hơn thì policy có follow tốt hơn không?".
Mười chiều fine-grained instruction
FineVLA-Tool annotate mỗi trajectory theo 10 chiều. Đây là phần quan trọng nhất nếu bạn muốn dùng FineVLA cho robot của mình.
| Dimension | Ý nghĩa trong robot dual-arm | Ví dụ |
|---|---|---|
| Action Sequence | Thứ tự các bước thao tác | reach, grasp, lift, move, place |
| Active Actor | Tay hoặc end-effector nào thực hiện | left arm, right arm, both arms |
| Target Object | Object nào được thao tác | red block on the left |
| Initial Configuration | Trạng thái ban đầu | cup upright near tray |
| Final Configuration | Trạng thái sau thao tác | cup placed upright on target |
| Contact & Approach | Chạm vào đâu, tiếp cận thế nào | grasp upper side, approach from front |
| Trajectory & Orientation | Đường đi và hướng tool | lift vertically, rotate clockwise |
| Body Motion | Chuyển động toàn thân hoặc joint-level | keep torso fixed, move wrist only |
| Object Interaction | Quan hệ giữa các object | stack block on top of another |
| Failure & Recovery | Cách xử lý lỗi | re-grasp if slipping |
Với beginner, hãy hiểu 10 chiều này như một checklist khi bạn viết instruction cho robot. Nếu instruction của bạn chỉ nói mục tiêu cuối, policy có thể hoàn thành task nhưng sai style thực hiện. Nếu instruction nói rõ tay, hướng, contact và pose, bạn đang cung cấp signal gần với action hơn.
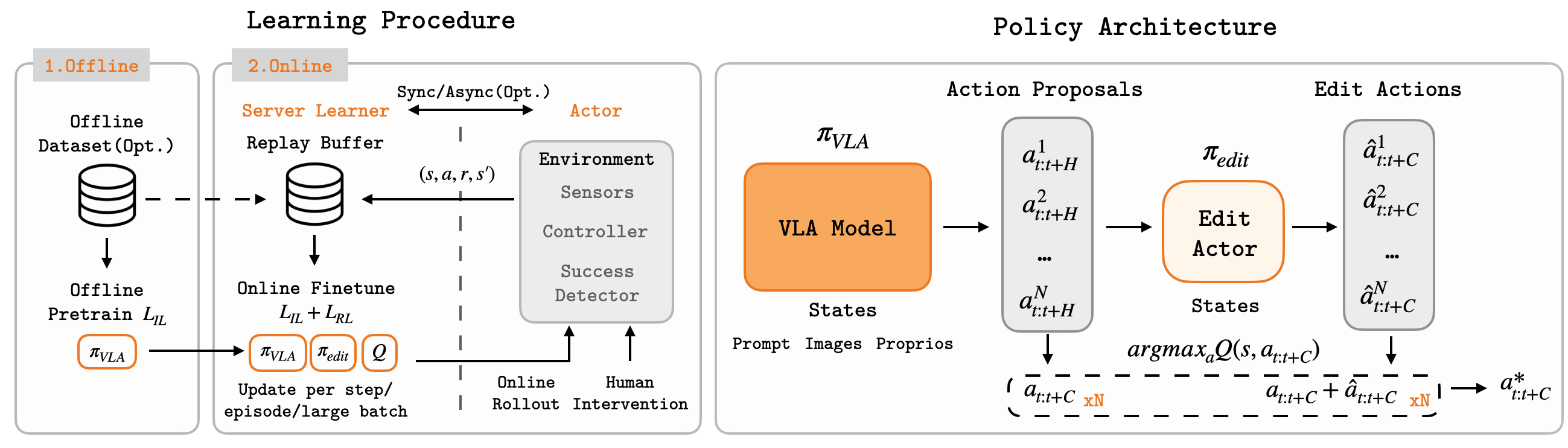
Kiến trúc FineVLA-Policy
FineVLA-Policy hiện hỗ trợ nhiều action-decoding framework trong codebase StarVLA. Trong paper, hai nhánh chính được dùng để kiểm chứng:
| Framework | Backbone | Action head | Ý tưởng |
|---|---|---|---|
| StarVLA-OFT | Qwen3.5-VL-4B | MLP regression | Đọc hidden states của action tokens và dự đoán continuous action chunks |
| StarVLA-GR00T | Qwen3.5-VL-4B | DiT + flow matching | VLM làm System 2 để reasoning, DiT làm System 1 để sinh action liên tục |
Sơ đồ đơn giản:
Camera frames + language instruction
|
v
Qwen3.5-VL-4B backbone
|
+-----------------------------+
| |
v v
StarVLA-OFT StarVLA-GR00T
MLP action regression DiT flow-matching action generator
| |
v v
continuous action chunk continuous action chunk
Điểm "dual-arm" thường nằm ở action representation và dataset. AlohaMix là mixture ALOHA-compatible dual-arm được dựng từ RDT, RoboCOIN, RoboMIND V1/V2. Paper ghi AlohaMix có 86,662 episodes trên 598 tasks, đủ lớn để test tác động của fine-grained language trên embodiment dual-arm tương đối nhất quán.
Cài đặt môi trường
Repo chính thức yêu cầu Python 3.10, PyTorch/CUDA phù hợp và FlashAttention. FineVLA-Policy dùng Accelerate + DeepSpeed cho distributed training, nên bạn nên chuẩn bị máy Linux có NVIDIA GPU. Với beginner, mục tiêu đầu tiên không phải train 100k steps, mà là cài được package và chạy smoke test.
git clone https://github.com/xlang-ai/FineVLA.git
cd FineVLA/FineVLA-Policy
conda create -n finevla python=3.10 -y
conda activate finevla
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
pip install -e .
Kiểm tra CUDA và package quan trọng:
nvcc -V
pip list | grep -E 'torch|transformers|flash-attn|accelerate|deepspeed'
Repo ghi flash-attn==2.7.4.post1 đã được verify với CUDA 12.0 và 12.4. Nếu install FlashAttention lỗi, nguyên nhân thường là PyTorch/CUDA mismatch. Cách xử lý thực tế là cài PyTorch đúng CUDA trước, sau đó mới cài FlashAttention.
Bạn cũng cần tải backbone Qwen3.5-VL-4B-Instruct và đặt đúng vị trí mà script mong đợi:
mkdir -p playground/Pretrained_models
# Tải Qwen/Qwen3.5-VL-4B-Instruct từ Hugging Face bằng huggingface-cli hoặc snapshot_download
# Đặt checkpoint tại:
# ./playground/Pretrained_models/Qwen3.5-VL-4B-Instruct
Smoke test:
python starVLA/model/framework/QwenGR00T.py
Nếu script build model và in architecture, môi trường policy đã chạy được. Nếu lỗi memory, hãy giảm batch size khi training hoặc chạy smoke test trên GPU lớn hơn.
Chuẩn bị data
FineVLA-Tool đọc dataset root qua biến môi trường VLA_DATA_ROOT. Theo README, tool convert dữ liệu robot về format thống nhất, canonicalize state/action, dùng DTW để clustering, rồi annotate.
cd FineVLA/FineVLA-Tool
export VLA_DATA_ROOT="/path/to/your/Lerobot_v21"
Pipeline data có bốn bước:
CanonicalizeAndClean
- convert dataset về LeRobot-style format
- canonicalize absolute coordinates và quaternion rotations
- lọc video invalid, empty task, trajectory corrupted
ClusteringAndSampling
- tính trajectory similarity bằng dynamic time warping
- cluster trajectory trong từng task
- chọn representative episodes để annotate
AnnotationPipeline
- dùng VLM để mô tả từng step
- fill các slot như actor, target, contact, trajectory, state change
RealANNO-Guidance
- human annotator review video và sửa lỗi factual/temporal alignment
Nếu bạn chỉ muốn học cách train policy, chưa cần tự dựng lại toàn bộ FineVLA-Data. Hãy bắt đầu với benchmark/data đã release trên Hugging Face và các example script trong FineVLA-Policy/examples. Nếu bạn muốn dùng robot nội bộ, hãy ưu tiên convert log của bạn sang LeRobot format trước; đây là nền tảng tốt để tái dùng dataloader, visualization và các tool phổ biến trong robot learning.
Training FineVLA-Policy
FineVLA-Policy dùng Accelerate + DeepSpeed. Lệnh tổng quát:
cd FineVLA/FineVLA-Policy
accelerate launch \
--config_file starVLA/config/deepseeds/deepspeed_zero2.yaml \
--num_processes 8 \
starVLA/training/train_starvla.py \
--config_yaml ./starVLA/config/training/your_config.yaml
Repo cung cấp script theo benchmark:
examples/Aloha/ ALOHA dual-arm tasks và FG:Raw mixing ratios
examples/Robotwin/ RoboTwin simulation benchmark
examples/LIBERO/ LIBERO benchmark
examples/Robocasa_tabletop/
examples/SimplerEnv/
Ví dụ train ALOHA với FG:Raw = 1:1:
bash examples/Aloha/run_qwen35_GR00T_aloha_multi_FG1_1_dlc.sh
Ý nghĩa của FG:Raw:
| Setting | Sampling instruction | Khi nào dùng |
|---|---|---|
| Raw-only | Chỉ dùng instruction gốc cấp mục tiêu | Baseline |
| FG-only | Chỉ dùng fine-grained process instruction | Test policy có học "how" không |
| FG:Raw = 1:4 | 20% FG, 80% Raw | Conservative fine-tuning |
| FG:Raw = 1:2 | Khoảng 33% FG, 67% Raw | Thường rất mạnh trong paper |
| FG:Raw = 1:1 | 50% FG, 50% Raw | Best real-world average trong paper |
| FG:Raw = 2:1 hoặc 4:1 | Nghiêng mạnh về FG | Dễ mất cân bằng nếu instruction quá dài |
Điều quan trọng: trong thí nghiệm của FineVLA, trajectory, action và visual observation được giữ nguyên; chỉ instruction thay đổi. Vì vậy improvement không đến từ "nhiều data hơn" theo nghĩa thông thường, mà đến từ language label giàu thông tin hơn.
Inference và evaluation
Tại thời điểm bài viết này, README repo ghi policy checkpoints pretrained/fine-tuned vẫn "coming soon", còn code, benchmark, FineVLA-Tool và RoboFine-VLM đã release. Vì vậy có hai cách chạy:
- Train policy của bạn bằng script trong
examples/, sau đó dùng checkpoint sinh ra. - Khi tác giả release policy checkpoint trên Hugging Face, thay
model_pathtrong config/eval script bằng checkpoint đó.
Với LIBERO, quick start từ repo là chạy policy server rồi chạy evaluator:
cd FineVLA/FineVLA-Policy
bash examples/LIBERO/eval_files/run_policy_server.sh &
bash examples/LIBERO/eval_files/eval_libero.sh
Với custom dual-arm robot, inference loop thường có dạng:
observation = {
"images": {
"cam_high": high_rgb,
"cam_left_wrist": left_wrist_rgb,
"cam_right_wrist": right_wrist_rgb,
},
"state": robot_state,
}
instruction = (
"Use the right arm to grasp the red block from its right side, "
"lift it vertically, then place it on top of the blue block."
)
action_chunk = policy.predict_action(observation, instruction)
robot.execute(action_chunk)
Bạn cần map action output về controller thật của robot: joint position, end-effector delta, gripper command, hoặc action chunk theo format ALOHA. Đây là nơi nhiều lỗi deployment xảy ra. Fine-grained instruction không thay thế calibration, time synchronization, camera extrinsics, action scaling và safety layer.
Chạy RoboFine-Bench
RoboFine-Bench dùng để đánh giá VLM hiểu video manipulation chi tiết đến đâu. Nó không trực tiếp điều khiển robot, nhưng rất hữu ích nếu bạn muốn đánh giá annotator hoặc model video-language trước khi dùng để generate annotation.
cd FineVLA/RoboFine-Bench
git lfs install
git clone https://huggingface.co/datasets/xlangai/RoboFine-bench EvalData/
pip install openai httpx tqdm pydantic Pillow av
export OPENAI_API_KEY="your-api-key"
Chạy VQA:
python RoboFine-Bench/vqa_eval/run_vqa.py \
--model qwen3-vl-plus \
--qa EvalData/QAEvalSets.json \
--input EvalData/EvalSets.json \
--num-workers 16
Chạy caption hard mode, tức không đưa task instruction vào prompt:
python RoboFine-Bench/caption_eval/annotate/run_annotate.py \
--model qwen3.5-plus \
--evalsets EvalData/EvalSets.json \
--frame-index EvalData/frame_index.jsonl \
--output-dir results/CaptionResult/hard/ \
--num-workers 16 \
--no-instruction
Rồi score caption bằng Direct Alignment:
python -m caption_eval.atomic_eval.atomic_eval direct-align \
--gt-facts EvalData/GT_AtomicFacts.jsonl \
--caption results/CaptionResult/qwen3_5-plus_CaptionResult.jsonl \
--output-dir results/AtomicResult/qwen3_5-plus/ \
--num-workers 8 \
--enable-thinking
Các metric chính:
| Metric | Đo điều gì? |
|---|---|
| Consistency | Caption có khớp facts đã nói không |
| Coverage | Caption có cover đủ ground-truth facts không |
| Anti-Hallucination | Caption có bịa thêm action không |
| CaptionScore | Trung bình của ba nhóm trên |
Kết quả cần nhớ
FineVLA-Data được dựng từ 972,247 raw trajectories trên 85K tasks, rồi chọn 47,159 trajectories đã human-verified. Instruction trung bình tăng từ 9.3 lên 96.8 words, tức khoảng 10.4 lần.
Trên RoboTwin simulation, setting tốt nhất đạt:
| Setting | Raw-only | Best mixed |
|---|---|---|
| RDT-OFT Easy/Hard | 61.5 / 60.0 | 74.1 / 72.4 |
| RDT-GR00T Easy/Hard | 55.1 / 53.4 | 69.4 / 68.2 |
| AlohaMix-OFT Easy/Hard | 71.8 / 71.4 | 86.8 / 82.5 |
Trên real-world dual-arm manipulation, Raw-only đạt 49.9/100 ở average ID, còn FG:Raw = 1:1 đạt 62.7/100. Paper cũng báo instruction violations giảm từ 34% xuống 12% ở mixed best. Các gain lớn nhất xuất hiện ở pose, color và approach direction, đúng những yếu tố mà instruction ngắn thường bỏ qua.
RoboFine-VLM cũng là một kết quả đáng chú ý. Model này được fine-tune từ Qwen3.5-397B-A17B trên FineVLA-Data, đạt 71.0% VQA accuracy và khoảng 83.6% captioning score ở hard setting theo project page/paper. Tuy nhiên, chi phí train annotator rất lớn: appendix của paper ghi RoboFine-VLM SFT dùng 256 H200 GPU trong khoảng 40 giờ. Với phần lớn lab, cách hợp lý hơn là dùng model release để annotate, sau đó human review một phần quan trọng.
Checklist triển khai cho lab nhỏ
Nếu bạn đang có một dual-arm robot, đừng bắt đầu bằng training 64 A100. Hãy đi theo thứ tự sau:
1. Chuẩn hóa log robot
camera timestamps, action/state format, gripper state, episode metadata
2. Convert sang LeRobot-style dataset
càng gần format FineVLA/LeRobot càng dễ dùng lại tool
3. Viết raw instruction ngắn cho từng episode
ví dụ: "stack the red block on the blue block"
4. Annotate fine-grained instruction cho 50-200 episodes đầu tiên
ưu tiên active actor, target, contact, approach, final configuration
5. Fine-tune một policy nhỏ hoặc adapter trước
dùng subset để kiểm tra data path, không train full ngay
6. So sánh Raw-only, FG-only, FG:Raw = 1:2, FG:Raw = 1:1
giữ nguyên trajectory/action để isolate language effect
7. Deploy qua safety wrapper
action clipping, workspace limits, emergency stop, gripper force limits
FineVLA có giá trị lớn nhất khi bạn có nhiều cách thực hiện cùng một task. Nếu tất cả episodes đều giống hệt nhau, fine-grained instruction sẽ ít đất để phát huy. Nhưng nếu task có nhiều arm choice, approach direction, object pose, tool orientation hoặc recovery behavior, instruction chi tiết sẽ giúp policy học được các nhánh behavior rõ hơn.