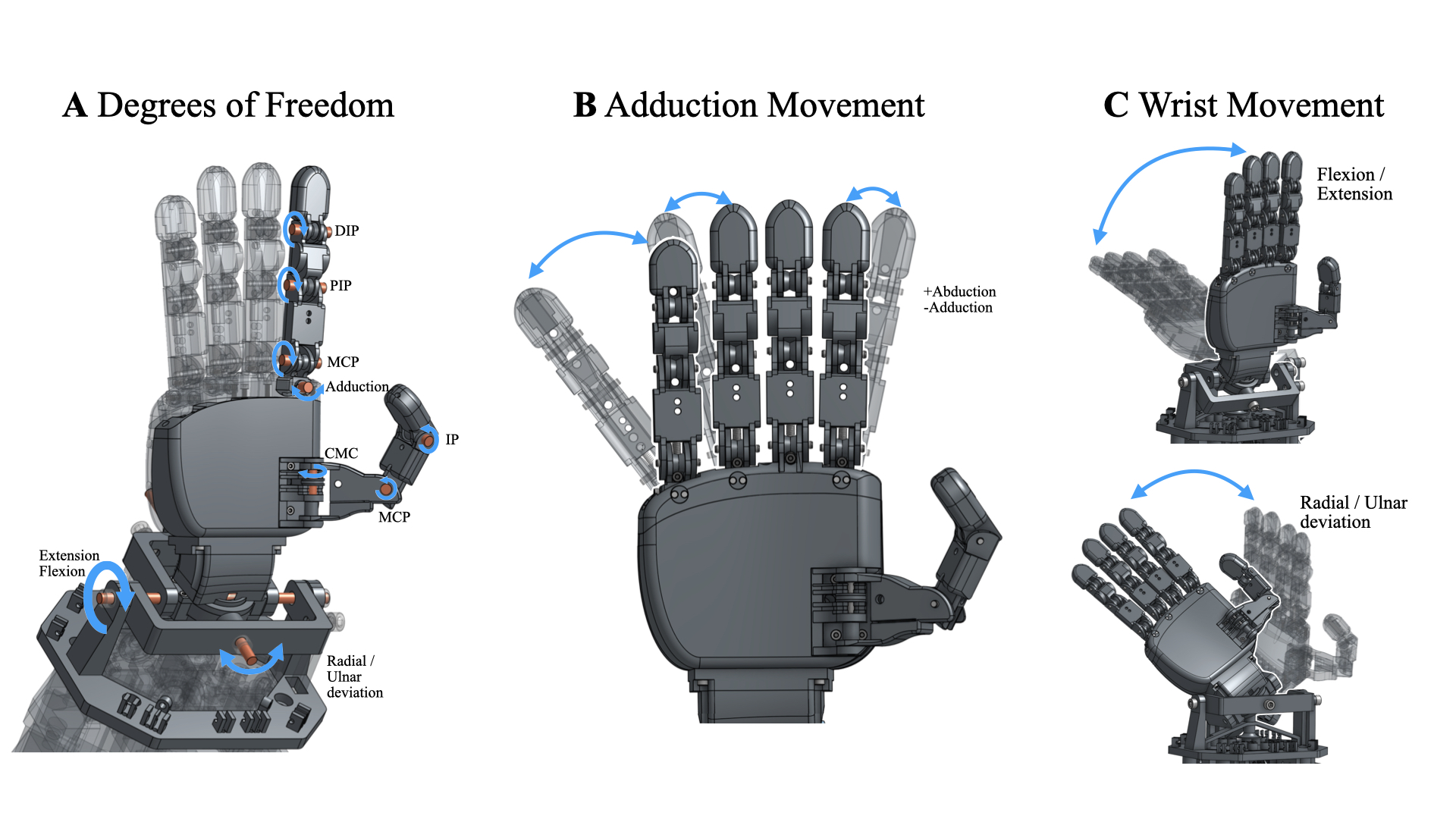
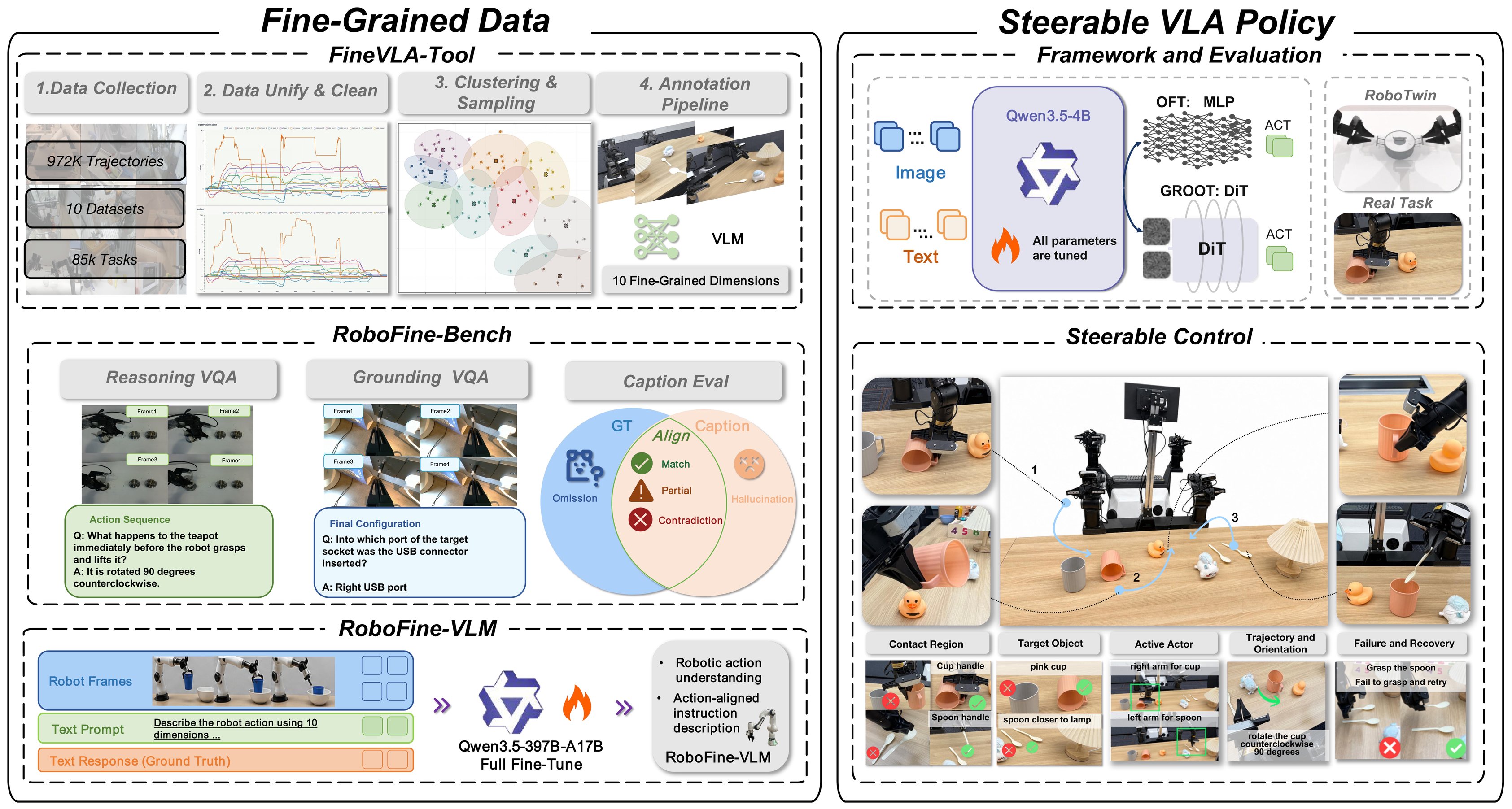
Robot thao tác hai tay khéo léo — hai cánh tay phối hợp nhịp nhàng, mười ngón tay điều khiển độc lập từng khớp — vẫn là một trong những bài toán khó nhất của robotics hiện đại. Trong khi các hệ thống VLA (Vision-Language-Action) thế hệ mới như π0 hay GR00T N1 đã chứng minh tiềm năng lớn, chúng chủ yếu tập trung vào gripper đơn giản hoặc tác vụ không đòi hỏi kỹ năng tay tinh tế.
Dexora — công bố tại ICRA 2026 — lần đầu tiên mang kiến trúc VLA hiện đại đến thế giới của bimanual dexterous manipulation: hai tay robot với 36 bậc tự do, có thể dùng bút viết, xé chuối, mở nắp chai, hay cán bột mì. Quan trọng hơn, toàn bộ hệ thống — mã nguồn, dataset, model weights — được phát hành hoàn toàn mã nguồn mở.
Tại sao Bimanual High-DoF lại khó?
Hãy so sánh hai nhiệm vụ: nhặt một hộp và đặt vào rổ (gripper đơn giản), với việc dùng ngón tay vặn nắp chai trong khi tay kia giữ cố định thân chai. Sự khác biệt không chỉ về phần cứng mà về toàn bộ chuỗi thách thức:
1. Không gian hành động cực kỳ cao chiều: Một robot hai tay có dexterous hand cần điều khiển đồng thời 36 khớp — 6 khớp mỗi cánh tay × 2 + 12 khớp mỗi bàn tay × 2. So với gripper 2-DoF thông thường, không gian hành động này lớn hơn 9 lần.
2. Phối hợp hai tay là tổ hợp cực phức tạp: Hai tay không hoạt động độc lập. Khi tay trái giữ đối tượng, tay phải phải điều chỉnh lực tinh tế theo trạng thái thực tế của tay trái — quan hệ phụ thuộc này khó mô hình hóa.
3. Thu thập dữ liệu là cơn ác mộng: Teleoperation cho gripper thì có thể dùng joystick hay SpaceMouse. Nhưng để dạy robot cách dùng ngón tay cái xoay nắp chai, bạn cần thiết bị ghi lại chuyển động ngón tay người với độ chính xác millimet.
Dexora giải quyết cả ba vấn đề này theo cách thực sự sáng tạo.
Kiến trúc Hệ Thống
Trái tim của Dexora là một Diffusion Transformer với quy mô đáng kể:
- 28 transformer layers
- Hidden size 1024, 16 attention heads
- Tổng tham số: ~300M (ước tính tương đương GR00T N1 scale nhỏ)
Observation Space — Robot thấy gì?
Mỗi bước inference, model nhận vào:
- 4 camera RGB (đa góc nhìn): stereo head camera, left wrist camera, right wrist camera — mỗi camera encode qua SigLIP (vision encoder của Google)
- 36-D proprioception: góc khớp hiện tại của toàn bộ dual-arm + dual-hand, log ở 20 Hz
- Language instruction: mô tả tác vụ ("pick up the pen and write the letter A") encode qua T5
SigLIP được chọn vì nó được pretrain trên dữ liệu image-text scale lớn với contrastive loss, cho visual features mạnh hơn ViT-B/16 thông thường trong các bài toán thao tác.
Action Space — Robot làm gì?
Output là vector 36 chiều liên tục:
- Dual 6-DoF arms: 6 góc khớp × 2 cánh tay
- Dual XHAND 12-DoF hands: 12 khớp ngón tay × 2 bàn tay — bao gồm các khớp lateral ab/adduction của ngón cái và ngón trỏ, không giống các dexterous hand đơn giản hơn
Model không output một action duy nhất mà output action chunk (chuỗi nhiều timestep) theo phong cách ACT/Diffusion Policy, sau đó dùng DPMSolver++ để denoising nhanh hơn DDPM tiêu chuẩn.
Hệ Thống Thu Thập Dữ Liệu: Exoskeleton + Vision Pro
Đây là phần sáng tạo nhất của Dexora. Thay vì một thiết bị teleoperation duy nhất, nhóm tác giả thiết kế hệ thống hybrid tách biệt hai phần:
Phần 1: Exoskeleton Backpack cho Cánh Tay
Người vận hành đeo một bộ exoskeleton backpack tùy chế trên lưng và vai. Exoskeleton này capture chuyển động của vai, khuỷu tay, và cổ tay với mapping trực tiếp sang joint-space của robot — không qua inverse kinematics, nên latency thấp và không có vấn đề singularity.
Ưu điểm so sách với SpaceMouse hay 6-DoF haptic device: exoskeleton cho chuyển động tự nhiên hơn vì người vận hành thực sự dùng cơ thể của mình, không phải học cách điều khiển gián tiếp.
Phần 2: Apple Vision Pro cho Bàn Tay
Trong khi exoskeleton lo phần cánh tay, Apple Vision Pro lo phần ngón tay. Vision Pro có khả năng track markerless 3D skeleton của bàn tay với độ chính xác cao — mà không cần đeo găng tay cảm biến hay dán marker.
Dexora retarget chuyển động bàn tay từ hand skeleton của người sang không gian khớp 12-DoF của XHAND, với joint limit enforcement để đảm bảo robot không vặn ngón tay quá giới hạn.
MuJoCo Digital Twin
Toàn bộ teleoperation session đồng thời drive cả robot thật và MuJoCo simulation y hệt nhau. Điều này cho phép thu thập synthetic data với chi phí cực thấp — sau khi thiết kế task trong sim, có thể tạo 100K episodes mà không cần người vận hành.
Dataset: Quy Mô và Đa Dạng

Dexora phát hành hai tập dữ liệu trên Hugging Face:
Synthetic Dataset (Coming Soon)
- 100,000 episodes trong MuJoCo
- 6.5 triệu frames, 361 giờ
- 200 tác vụ, 297 đối tượng từ Objaverse-XL (auto-processed)
- Tập trung: basic manipulation families — pick-place, assemble/disassemble, articulated objects
Real-World Dataset (Đã Phát Hành)
- 12,200 episodes teleoperation
- 2.92 triệu frames, 40.5 giờ
- 200 tác vụ đa dạng
- 347 đối tượng thuộc 17 semantic categories (từ bút viết, chai nước, đến đồ ăn như chuối và bột mì)
- 20% tác vụ yêu cầu kỹ năng dexterous thực sự (sử dụng ngón tay tinh tế)
Phân phối tác vụ: Pick-and-place 55%, Dexterous manipulation 20%, Assembly 15%, Articulated objects 10%.
Dataset follow LIBERO-2.1 standard format với multi-view RGB observations, proprioception, action commands, và 5 variants ngôn ngữ per task.
Training Pipeline: Ba Giai Đoạn
Đây là điểm kỹ thuật quan trọng nhất — Dexora không chỉ fine-tune trên dữ liệu thô mà có một data-quality-aware training recipe gồm 3 giai đoạn:
Giai Đoạn 1: Pretraining trên Synthetic Data
Train Diffusion Transformer từ đầu trên 100K synthetic trajectories (6.5M frames) trong 100,000 steps, dùng 8×A100 GPUs. Giai đoạn này giúp model học được basic manipulation behaviors — cách tiếp cận đối tượng, cách grip, spatial reasoning cơ bản — mà không cần dữ liệu thật.
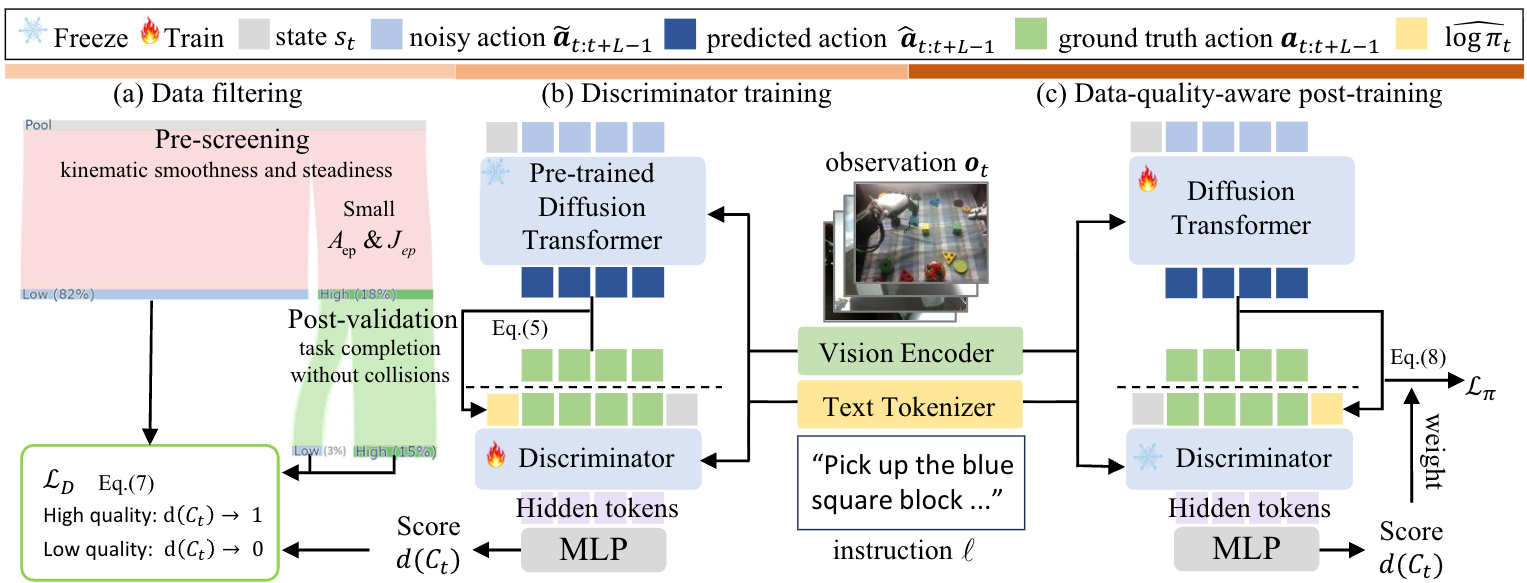
Giai Đoạn 2: Training Offline Quality Discriminator
Vấn đề lớn với dữ liệu teleoperation: không phải episode nào cũng tốt. Người vận hành mệt mỏi, thao tác sai, hoặc đơn giản là episode thất bại. Nếu train trên tất cả dữ liệu thô → model học cả "cách làm sai".
Dexora train một offline discriminator để score chất lượng từng episode:
# Tiêu chí pre-screening
# 1. Kinematic smoothness: RMS acceleration và jerk trên 36 chiều
Aep = rms(acceleration(joints)) # qua tất cả timestep
Jep = rms(jerk(joints))
# 2. Giữ lại episodes xấu nhất (thực ra là tốt nhất — low acc/jerk)
S_pre = {τ: τ ∈ Low-20%(Aep) AND τ ∈ Low-20%(Jep)}
# ~18% episodes pass filter ban đầu
# 3. Validate qua open-loop replay
# Positive set: S_pre episodes được replay thành công
# Unlabeled set: phần còn lại
Discriminator dùng positive-unlabeled (PU) binary cross-entropy với η=0.5, nhận state + observations + language + action chunks + log-π (từ pretrained policy) để output quality score.
Giai Đoạn 3: Post-Training với Quality Weighting
Fine-tune policy pretrained trên 10K real episodes, nhưng mỗi episode được weight theo discriminator score:
ℒπ = Σᵢ wᵢ · ||εθ(oᵢ, aᵢ, t) − ε||²₂
Episodes chất lượng cao → weight cao → model học nhiều hơn từ chúng. Episodes kém chất lượng → weight thấp → ít ảnh hưởng. Kết quả: trajectory mượt mà hơn đáng kể (jerk giảm từ 0.043 xuống 0.032), ít oscillation ở khớp.
Kết Quả: Robot Học Được Gì?

Basic Task Suite (12 tác vụ)
| Model | Avg Success |
|---|---|
| Dexora | 89.6% |
| GR00T N1 | 82.1% |
| π0 | 50.4% |
| Diffusion Policy | 34.2% |
Dexora đạt ≥90% trên 7/12 tác vụ cơ bản, vượt GR00T N1 ~7.5 điểm phần trăm — đáng kể khi GR00T N1 là baseline mạnh nhất hiện tại cho manipulation.
Dexterous Manipulation Suite (6 tác vụ)
Đây là benchmark thực sự thử thách: dùng bút (Use Pen), lấy sách (Fetch Book), thái hành (Cut Leek), xếp đĩa (Place Plates), cán bột (Rough Dough), mở nắp chai (Twist Cap).

| Model | Avg Success |
|---|---|
| Dexora | 66.7% |
| GR00T N1 | 51.7% |
| π0 | 26.7% |
| Diffusion Policy | 6.7% |
Khoảng cách với GR00T N1 trên dexterous tasks (+15 điểm) lớn hơn nhiều so với basic tasks (+7.5 điểm) — chứng minh rằng training recipe của Dexora đặc biệt hiệu quả cho các tác vụ đòi hỏi finger dexterity.
Ablation: Data Quality Discriminator có Thật Sự Cần Thiết?
| Cấu hình | Success Rate | Jerk RMS |
|---|---|---|
| Không có discriminator | 85% | 0.043 |
| Có discriminator | 95% | 0.032 |
+10 điểm thành công và trajectory mượt mà hơn hẳn — chứng minh discriminator không chỉ là "nice to have" mà là thành phần cốt lõi.
Cross-Embodiment Generalization
Một trong những ưu điểm lớn nhất của Dexora là khả năng transfer sang các embodiment khác bằng simple action dimension projection — không cần retrain từ đầu:
- Franka Panda (single-arm gripper): Project 36D action xuống 7D arm joints
- ALOHA (dual-arm gripper): Project sang 2 × 6D arm
- Unitree G1 + Inspire Hand (single-arm dexterous): Project sang 6D arm + 12D hand
Trên 3 embodiment này, Dexora duy trì >85% performance so với khi train native — đây là kết quả ấn tượng so với các VLA thế hệ trước vốn rất cứng nhắc về embodiment.
Nếu bạn quan tâm cross-embodiment transfer cho bimanual setup, hãy đọc thêm RDT2 và khả năng zero-shot cross-embodiment bimanual.
Cài Đặt và Sử Dụng Dexora
Yêu Cầu Phần Cứng
- Minimum: 1× GPU A100 40GB (hoặc 2× A6000 48GB) cho inference
- Training: 8× A100 80GB (pretraining stage)
- Robot: Dual-arm platform với XHAND (hoặc embodiment tương thích)
Cài Đặt
# Clone repo
git clone https://github.com/ZZongzheng0918/Dexora.git
cd Dexora
# Cài đặt dependencies
conda create -n dexora python=3.10
conda activate dexora
pip install -r requirements.txt
# Download pretrained model weights
# (Xem hướng dẫn chi tiết trên dexoravla.github.io)
Download Dataset
Dataset thật (12.2K episodes) đã phát hành trên Hugging Face:
pip install huggingface_hub
python -c "
from huggingface_hub import snapshot_download
snapshot_download(
repo_id='Dexora/real-world-dataset',
repo_type='dataset',
local_dir='./data/real'
)
"
Dataset follow LIBERO-2.1 format, mỗi episode chứa:
- Multi-view RGB frames (4 cameras, H5 format)
- Proprioception logs (36-D joint angles, 20Hz)
- Language annotation (5 variants)
- Action sequences
Inference Demo
from dexora import DexoraPolicy
# Load model
policy = DexoraPolicy.from_pretrained("Dexora/dexora-base")
policy.eval()
# Inference loop
obs = {
"images": camera_frames, # dict of 4 camera views
"proprioception": joint_angles, # (36,) float32
"language": "pick up the pen and write the letter A"
}
with torch.no_grad():
actions = policy.predict(obs) # (T, 36) action chunk
Xem thêm cách thiết lập training pipeline VLA từ đầu trong hướng dẫn FineVLA cho dual-arm robot.
So Sánh với Các VLA Bimanual Khác
Nếu bạn đang xây dựng hệ thống bimanual dexterous, đây là bức tranh tổng quan:
| Hệ thống | DoF | Open Source | Dataset | Dexterous Score |
|---|---|---|---|---|
| Dexora | 36 | ✅ Full | 12.2K real + 100K sim | 66.7% |
| GR00T N1 | Variable | ⚠️ Weights only | Proprietary | 51.7% |
| π0 | Up to 52 | ✅ | ~5K | 26.7% |
| Diffusion Policy | Varies | ✅ | Task-specific | 6.7% |
| RDT-2 | Varies | ✅ | Diverse bimanual | N/A |
Dexora nổi bật ở sự kết hợp: cao DoF + mã nguồn mở hoàn toàn + dataset quy mô lớn + kết quả SOTA.
Đọc thêm về series thao tác hai tay trong Bimanual Manipulation: Từ Kinh Điển Đến VLA và so sánh chi tiết các dexterous hand trong hướng dẫn RUKA V2.
Tổng Kết
Dexora đánh dấu một bước ngoặt quan trọng: lần đầu tiên cộng đồng robotics có một VLA mã nguồn mở, có dataset thật quy mô lớn, và kết quả benchmark đáng tin cậy cho bài toán bimanual dexterous manipulation. Ba đóng góp chính đáng nhớ:
- Hybrid teleoperation (exoskeleton + Vision Pro): Giải pháp thực tế nhất hiện tại để thu thập dữ liệu dexterous chất lượng cao
- Quality discriminator: Không phải mọi data đều bằng nhau — lọc và weight dữ liệu theo chất lượng là chìa khóa
- Cross-embodiment projection: Một model, nhiều robot — giá trị thực tế cao
Với dataset, weights, và code đã phát hành, Dexora là điểm khởi đầu lý tưởng cho bất kỳ ai muốn nghiên cứu hoặc deploy bimanual dexterous manipulation trong năm 2026.
Paper: Dexora: Open-source VLA for High-DoF Bimanual Dexterity — ICRA 2026 GitHub: github.com/ZZongzheng0918/Dexora Project: dexoravla.github.io Dataset: huggingface.co/Dexora