Imagine teaching a robot by pointing at photos: "put this (image of red block) on top of here (image of target location)". No code changes. No fine-tuning. Just swap the prompt — and the robot figures out what to do. That is exactly what VIMA (VisuoMotor Attention, ICML 2023) achieves, and this post explains why the cross-attention architecture is the key — from real production code, not high-level diagrams.
VIMA solves a foundational problem: a single model handles 17 different robot manipulation tasks by simply changing the multimodal prompt. The secret lies in how the architecture separates task information (the prompt) from current state information (observation and action history) — and uses cross-attention to connect them in a controlled, layer-by-layer fashion.
Series Roadmap
This is post 1 of 5 in the VIMA: Multimodal Prompts for Humanoid Robot Manipulation series:
| Post | Topic |
|---|---|
| Post 1 (you are here) | Cross-Attention Architecture: XAttn GPT + T5 Encoder |
| Post 2 → Benchmark 17 Tasks | Measuring generalization across 4 difficulty levels |
| Post 3 → Object Tokenizer | From raw pixels to object tokens via Mask R-CNN + ViT |
| Post 4 → Dataset 650K | Multi-task data collection at scale |
| Post 5 → Humanoid Adaptation | Scaling VIMA to high-DoF humanoid hands |
The Core Problem: One Model, Seventeen Tasks
Before VIMA, robotics ML suffered from the "specialization curse": each task required a dedicated model. Stack blocks? Train model A. Follow a video demo? Model B. Avoid obstacles while reaching? Model C. No reuse, no generalization.
VIMA reframes the question: Instead of changing the model, what if we change the prompt?
The technical challenge: robot prompts cannot be pure text. Many tasks require visual descriptions — "place this object (image) at this location (another image)", or "replicate the sequence shown in this video". VIMA therefore introduces multimodal prompts — token sequences that interleave language with visual object representations, all encoded through a single T5 pipeline.
Source: VIMA project page — vimalabs.github.io
T5 Prompt Encoder: Reading Mixed-Modality Prompts
File: vima/nn/prompt_encoder/prompt_encoder.py
The first engineering challenge: how do you encode a sequence of both text and images into a single context vector? VIMA uses T5-base as the encoder — but not in the standard way.
Instead of passing input_ids (fixed vocabulary indices), VIMA passes inputs_embeds directly — pre-computed embedding vectors calculated outside T5. This trick allows text tokens and image tokens (which have no T5 vocabulary entry) to coexist in the same sequence and be processed uniformly:
class T5PromptEncoder(nn.Module):
def forward(self, x, *, attention_mask=None, batch_first=False):
# x: (L, B, E) — mixed text+image token embeddings
out = self.t5(
inputs_embeds=x.contiguous(), # not input_ids!
attention_mask=attention_mask,
).last_hidden_state
return out
How text and image tokens are interleaved
The assembly happens in VIMAPolicy.forward_prompt_assembly(). Each element in raw_prompts_token_type is either 0 (text) or 1 (image):
for item in raw_prompt:
if item == 0: # word token
assembled_prompt.append(batch_word_emb[word_ptr])
word_ptr += 1
elif item == 1: # image → n_max_objs object tokens
for q in range(n_max_objs):
assembled_prompt.append(batch_image_emb[img_ptr][q])
img_ptr += 1
For the prompt "place [image: red block] onto [image: target position]", the resulting sequence looks like:
[emb_"place", emb_"onto", obj_red_front, obj_red_top, obj_target_front, obj_target_top]
This mixed sequence passes through T5 encoder. Crucially, only the last 2 layers of T5 are fine-tuned — the first 10 layers retain their pretrained weights. This leverages T5's accumulated language understanding while keeping compute costs manageable.
The last_hidden_state output — tensor (B, L_prompt, 768) — is a "contextual summary" of the entire prompt. Every position is bi-directionally contextualized by all surrounding positions. This becomes the K (Key) and V (Value) in the cross-attention step of the decoder.
XAttn GPT: Decoder That References Prompt At Every Layer
File: vima/nn/seq_modeling/xattn_gpt/xattn_gpt.py
This is VIMA's core innovation. XAttnGPT inherits from OpenAIGPTPreTrainedModel but has a critical twist — two parallel ModuleLists instead of one:
self.h = nn.ModuleList(
[Block(n_positions, cfg, scale=True) for _ in range(n_layer)]
)
self.xattns = nn.ModuleList(
[
XAttention(embd_dim, num_heads=xattn_n_head, ...)
for _ in range(n_layer)
]
)
self.h contains the original GPT causal self-attention blocks. self.xattns contains the new cross-attention blocks. The forward loop:
for self_attn, xattn in zip(self.h, self.xattns):
# Step 1: cross-attend to prompt (prompt provides K, V)
obs_action_tokens = xattn(
q=obs_action_tokens,
kv=prompt_tokens,
attention_mask=prompt_mask,
)
# Step 2: causal self-attend over obs/action sequence
obs_action_tokens = self_attn(
obs_action_tokens, attention_mask=obs_action_masks
)[0]
This ordering is intentional: cross-attention first, self-attention second.
Think of it like a human worker: you first re-read the task instructions (cross-attend to prompt), then review what you have already done (self-attend to history). If self-attention came first, the historical context might "dilute" the prompt signal before cross-attention could inject fresh task context.
Across all 12 layers, robot tokens directly reference the encoded prompt. The model doesn't just consult the prompt at layer one and "forget it" — it is continuously reminded of the task at every depth of the transformer.
Two independent position embedding tables
self.positions_embed = nn.Embedding(n_positions, embd_dim) # for obs/action
self.xattn_positions_embed = nn.Embedding(xattn_n_positions, embd_dim) # for prompt
Why separate tables? These are fundamentally different position spaces. "The 3rd token in obs/action history" means something completely different from "the 3rd token in the prompt". Sharing a position table would confuse the model about which stream a token belongs to. xattn_n_positions=256 sets the maximum prompt length.
Comparison: Why Cross-Attention Wins
Three main approaches exist for conditioning a policy on a prompt:
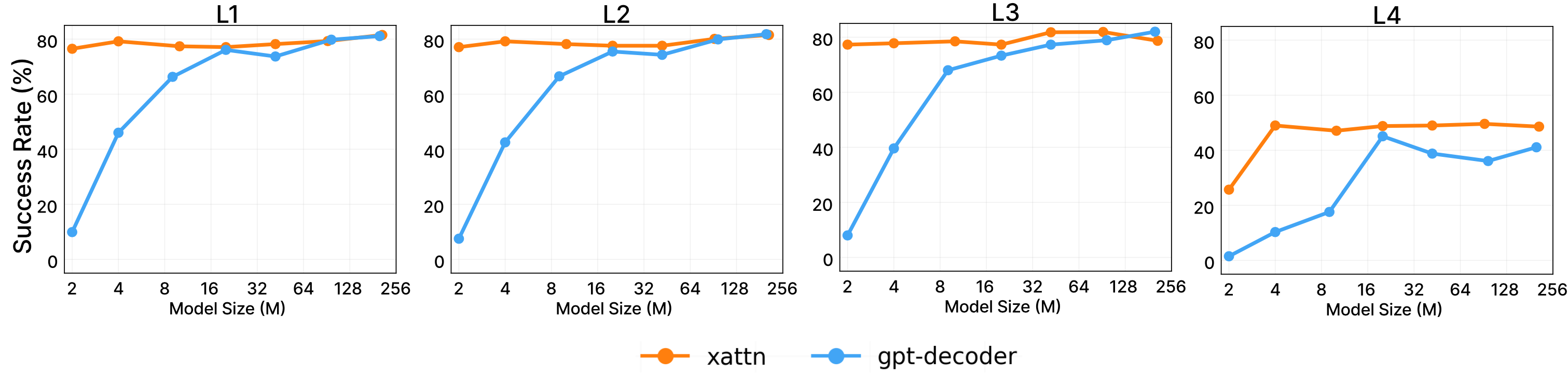
1. GPT-style (prefix concatenation): Prepend the prompt to the obs/action sequence, apply causal self-attention over everything. Problem: in deep layers, prompt signal has been diluted through many attention hops. For long sequences, gradients struggle to flow back to the prompt prefix.
2. Flamingo-style (sparse cross-attention): Cross-attend only in selected layers, not all of them. Faster but the prompt is "refreshed" less frequently.
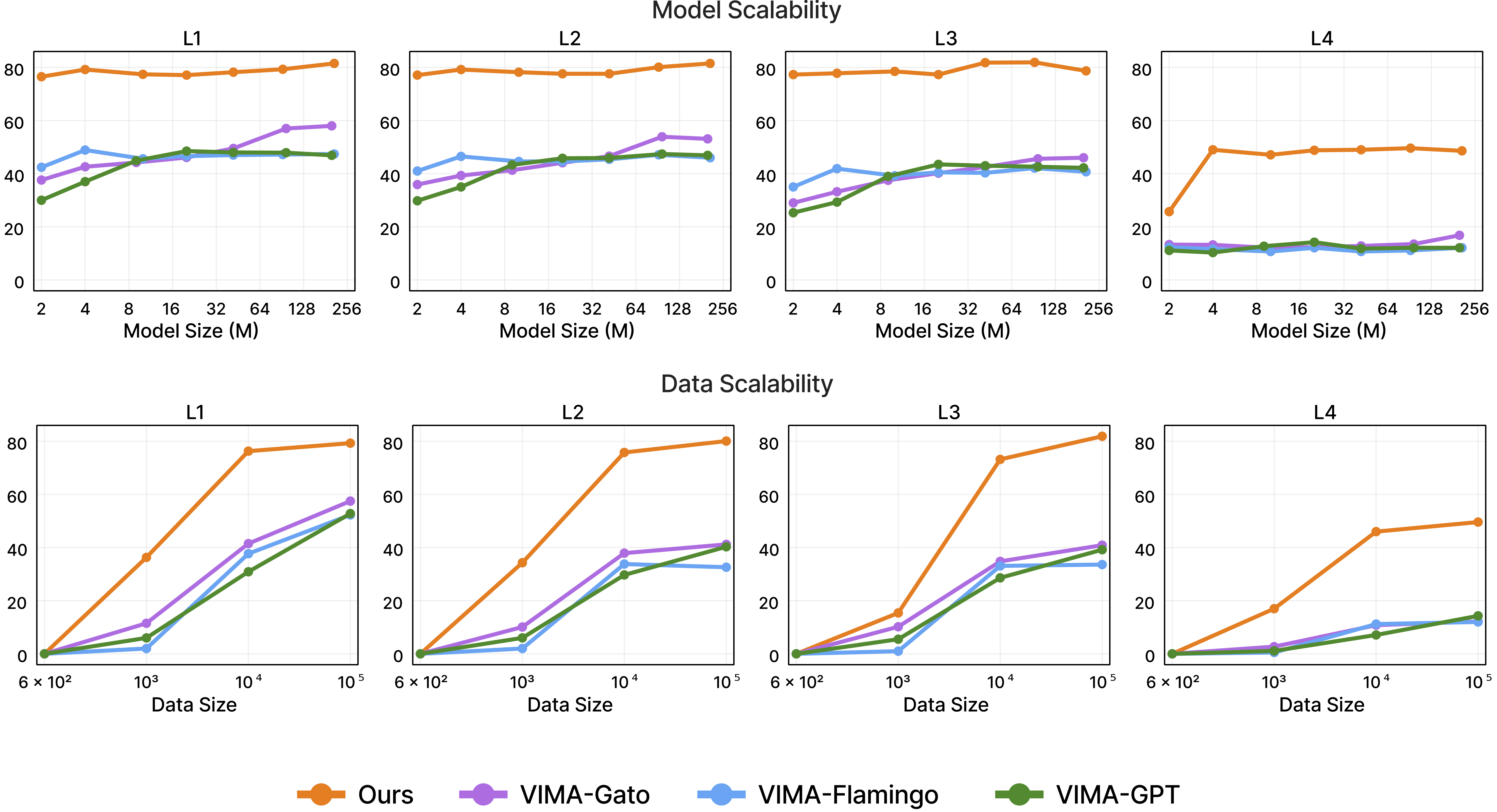
3. VIMA-style (dense cross-attention): Every one of the 12 layers directly cross-attends to the encoded prompt. The model can "consult the original instructions" at every depth. Ablations in the paper show this is the strongest approach — especially for small models and hard generalization tasks, where GPT-style prefix conditioning degrades significantly.
VIMAPolicy: The Complete End-to-End Pipeline
File: vima/policy/vima_policy.py
VIMAPolicy is the orchestrator that wires all components together. A complete forward pass:
Step 1 — Encode prompt (once per episode, never changes)
Prompt text → WordEmbedding → word embeddings
Prompt images → ObjEncoder (Mask R-CNN + ViT) → image object embeddings
Interleave → [word, word, obj, obj, word, obj, ...]
→ T5PromptEncoder → (B, L_prompt, 768)
→ Linear projection → (B, L_prompt, embed_dim)
Step 2 — Encode current observation (every timestep)
Current scene → ObjEncoder → object features
End-effector → Embedding(dim=2)
Concat + Linear → obs_token (embed_dim)
Step 3 — Build obs/action sequence
[obs_t0, act_t0, obs_t1, act_t1, ..., obs_tN] → token sequence (L, B, embed_dim)
Step 4 — XAttn GPT
obs/action sequence + prompt_tokens → XAttnGPT (12× xattn + sattn)
→ predicted_action_tokens
The output token at position obs_tN (end of sequence) carries the predicted next action.
Step 5 — Decode action
self.action_decoder = vnn.ActionDecoder(
input_dim=embed_dim,
action_dims={
"pose0_position": [50, 100], # 50 x-bins, 100 y-bins
"pose0_rotation": [50] * 4, # 50 bins per quaternion component
"pose1_position": [50, 100],
"pose1_rotation": [50] * 4,
},
...
)
VIMA discretizes the action space into bins — 50 bins for x, 100 for y, 50 for z, 50 for each quaternion component. This converts continuous regression into classification, making training significantly more stable than directly predicting real-valued coordinates.
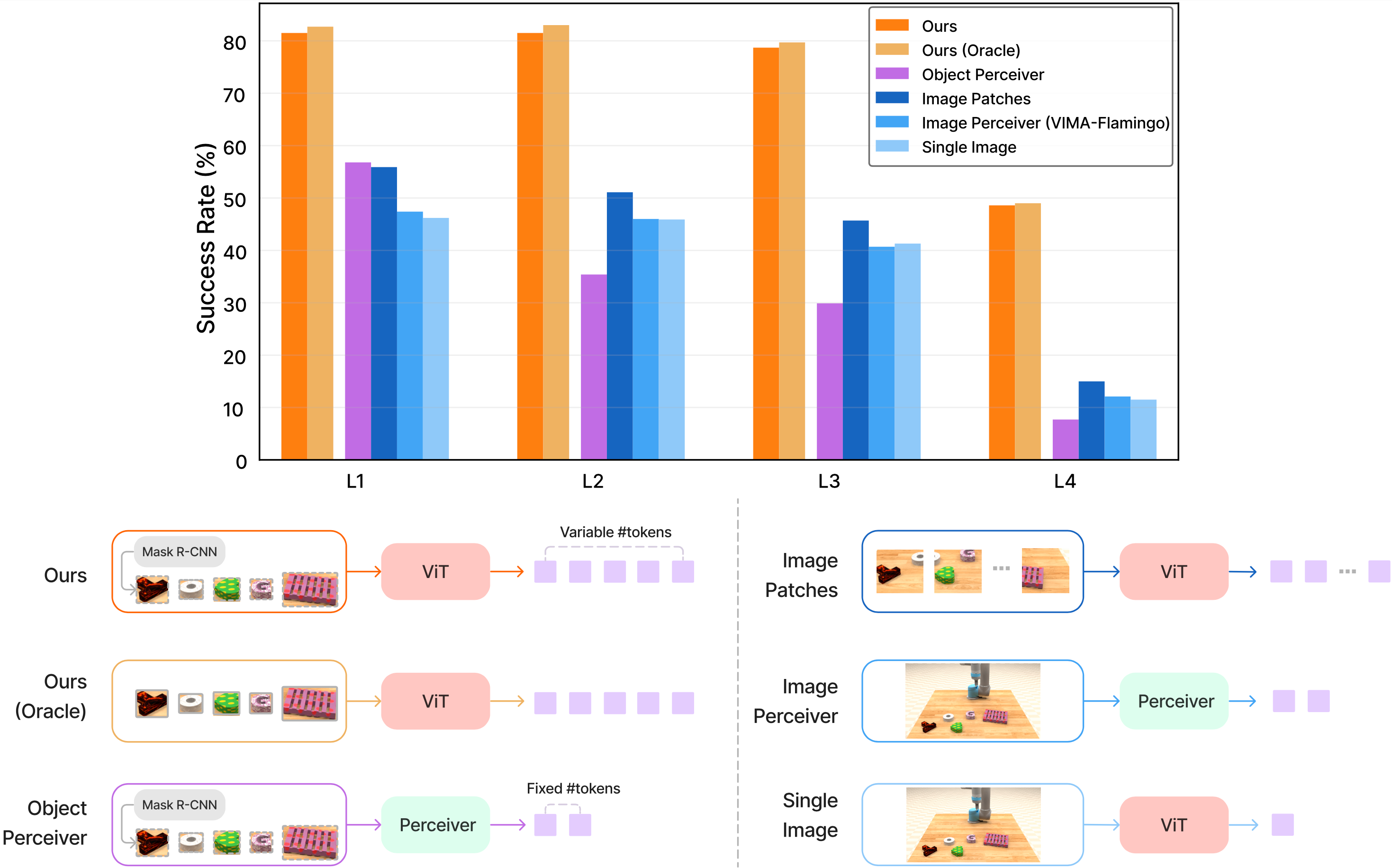
ObjEncoder: The Language of Objects
self.obj_encoder = vnn.ObjEncoder(
transformer_emb_dim=embed_dim,
views=["front", "top"],
vit_resolution=32, # 32×32 pixel crop per object
vit_patch_size=16, # → just 4 patches (2×2) per object
vit_width=768,
vit_layers=4,
vit_heads=24,
bbox_mlp_hidden_dim=768,
bbox_mlp_hidden_depth=2,
)
VIMA doesn't process full-scene raw pixels. Instead:
- Mask R-CNN detects each object and extracts bounding boxes
- Small ViT (4 layers, 24 heads) encodes each cropped 32×32 image — only 4 patches per object
- Bounding box MLP encodes coordinates (x1, y1, x2, y2) separately
- Concatenation: ViT output + bbox embedding = one complete "object token"
Each object is observed from two viewpoints ("front" and "top") — giving the model implicit 3D spatial understanding without an expensive depth camera.
Post 3: Object Tokenizer dives deeper into this design choice and compares it against patch-based whole-scene processing.
Why This Architecture Suits Humanoid Robots
This is the most important point when looking ahead. Humanoid robots have specific characteristics that VIMA's architecture addresses cleanly:
One platform, many tasks. A humanoid hand (10–20 DoF per hand) needs to handle everything from tightening screws to folding clothes. A separate model per task is impractical — a strong task-conditioning mechanism is essential. VIMA demonstrates that cross-attention is that mechanism.
Prompt changes task instantly, no re-training. The architecture isolates the prompt (K, V in cross-attention) from the obs/action sequence (Q). Change the prompt, change the task — the model weights never change. For a humanoid that must respond flexibly to user instructions, this is the ideal design.
Data efficiency. VIMA's ablations show cross-attention conditioning matches the performance of GPT-style prefix with only 10% of the training data. Humanoid manipulation data is expensive to collect — data efficiency is a survival advantage.
Multimodal instruction is natural. When guiding a humanoid hand through a delicate task, you naturally combine language ("grip tighter") with visual demonstrations. VIMA has already solved the engineering challenge of handling such mixed-modality instructions.
Post 5: Humanoid Adaptation goes into specifics on adapting VIMA's policy to the much higher-DoF action space of dexterous humanoid hands.
Model Scale: From 2M to 200M Parameters
VIMA ships seven pretrained checkpoints:
| Size | Parameters |
|---|---|
| VIMA-200M | 200M |
| VIMA-92M | 92M |
| VIMA-43M | 43M |
| VIMA-20M | 20M |
| VIMA-9M | 9M |
| VIMA-4M | 4M |
| VIMA-2M | 2M |
This range allows systematic scaling law studies. A notable finding: the cross-attention architecture allows small models (9M, 4M) to generalize better than same-size prefix-conditioning models — particularly relevant for deployment on edge hardware inside humanoid robots.
Conclusion
VIMA's architecture can be summarized in one sentence: T5 encoder converts multimodal prompts into a fixed context; cross-attention injects that context directly into the decoder at each of 12 layers; causal self-attention maintains temporal causality in the obs/action history.
What makes VIMA distinctive is not any individual component — T5 existed since 2019, Transformers since 2017, cross-attention since 2018. The insight is in how they are connected: a two-stream architecture where prompt and obs/action never mix through self-attention, but interact only through controlled cross-attention — allowing the model to maintain "task memory" across all layers of computation.
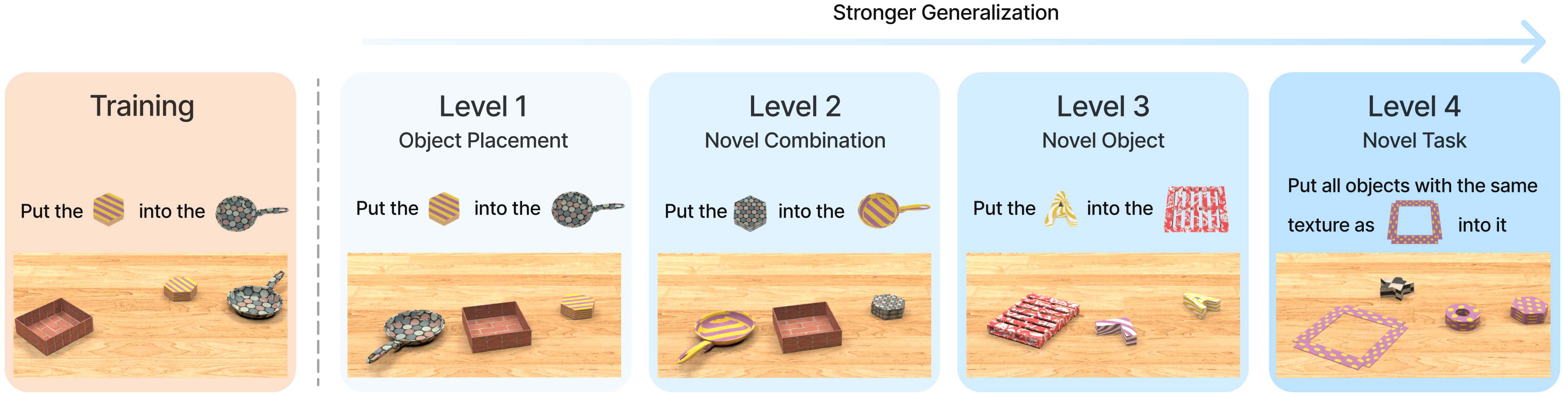
In the next post, we will look at how VIMA is evaluated across 17 tasks and 4 generalization levels — and which numbers actually matter.