Hãy tưởng tượng bạn vừa train xong một robot manipulation model. Giờ câu hỏi thật sự bắt đầu: model này có thực sự hiểu task, hay chỉ đang nhớ vẹt pattern từ training data? Bạn cần một framework đánh giá đủ khắt khe để phân biệt hai trường hợp đó — không phải chỉ test lại trên training distribution, mà test mức độ tổng quát hóa thực chất.
VimaBench là framework đó. Được xây dựng cùng với VIMA (ICML 2023), VimaBench cung cấp 17 task template — mỗi template có thể instantiate thành hàng nghìn instance khác nhau bằng cách kết hợp nhiều loại vật thể và texture — và định nghĩa một giao thức đánh giá 4 cấp để đo loại tổng quát hóa mà model thực sự đạt được.
Bài này dẫn bạn từ A đến Z: cài đặt VimaBench, chạy demo với checkpoint 200M, hiểu 17 task theo 6 nhóm chức năng, và phân tích 4 cấp eval — từ placement_generalization (dễ nhất) đến novel_task_generalization (khó nhất). Cuối bài, bạn sẽ hiểu tại sao cấp 4 là con số duy nhất đáng quan tâm khi muốn deploy VIMA lên humanoid thực tế.
Roadmap Series
Bài này là bài 2/5 trong series VIMA: Prompt Đa Phương Thức cho Robot Tay Người:
| Bài | Chủ đề |
|---|---|
| Bài 1: Kiến Trúc Cross-Attention | XAttn GPT + T5 Encoder — tại sao cross-attention thắng |
| Bài 2 (bạn đang đọc) | VimaBench: 17 Task và Giao Thức 4 Cấp |
| Bài 3: Object Tokenizer | Từ pixel thô đến token đối tượng với Mask R-CNN + ViT |
| Bài 4: Dataset 650K | Thu thập dữ liệu đa nhiệm vụ quy mô lớn |
| Bài 5: Humanoid Adaptation | Mở rộng VIMA lên robot hình người DoF cao |
Cài Đặt VimaBench
Yêu cầu hệ thống
- Python ≥ 3.9
- Git
- RAM ≥ 4GB (môi trường PyBullet simulation)
- GPU không bắt buộc để chạy demo
Cài đặt
# Bước 1: Clone repo VimaBench
git clone https://github.com/vimalabs/VimaBench
cd VimaBench
# Bước 2: Cài đặt ở chế độ editable (cần thiết để import vima_bench)
pip install -e .
Sau khi cài xong, verify bằng Python:
from vima_bench import make, PARTITION_TO_SPECS
# Kiểm tra: danh sách tất cả partition có sẵn
partitions = list(PARTITION_TO_SPECS["test"].keys())
print(partitions)
# Output: ['placement_generalization', 'combinatorial_generalization',
# 'novel_object_generalization', 'novel_task_generalization']
Import thành công mà không có lỗi — bạn đã sẵn sàng.
Tải Checkpoint
VimaBench không bundled sẵn checkpoint model. Checkpoint nằm trong repo VIMA chính:
# Clone VIMA algorithm repo
git clone https://github.com/vimalabs/VIMA
cd VIMA
# Tạo thư mục chứa checkpoint
mkdir -p ckpts
# Tải checkpoint 200M (performance tốt nhất)
# Xem README trong repo VIMA để lấy link download mới nhất
# wget <checkpoint_url> -O ckpts/200M.ckpt
VimaBench cung cấp 7 checkpoint từ 2M đến 200M tham số. Bài này dùng 200M.ckpt cho tất cả ví dụ. Nếu RAM hạn chế, thử 9M.ckpt hoặc 4M.ckpt — cú pháp lệnh hoàn toàn giống nhau, chỉ đổi path checkpoint.
Chạy Demo Đầu Tiên
VimaBench cung cấp sẵn scripts/example.py để test nhanh bất kỳ policy nào:
python scripts/example.py \
--ckpt=ckpts/200M.ckpt \
--partition=placement_generalization \
--task=follow_order
Ba tham số chính:
| Tham số | Ý nghĩa | Giá trị ví dụ |
|---|---|---|
--ckpt |
Đường dẫn đến file checkpoint | ckpts/200M.ckpt |
--partition |
Cấp đánh giá (1 trong 4) | placement_generalization |
--task |
Task cụ thể (1 trong 17) | follow_order |
Khi chạy, PyBullet mở cửa sổ simulator hiển thị bàn tabletop với các vật thể được đặt ngẫu nhiên. Robot nhận multimodal prompt — gồm cả text mô tả lẫn ảnh vật thể tham chiếu — thực thi action sequence, và bạn quan sát trực tiếp liệu model có hoàn thành task không.
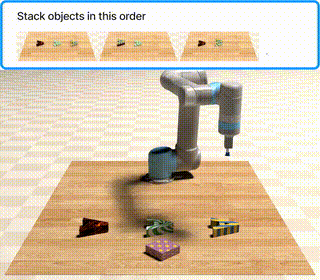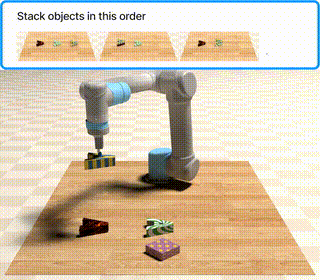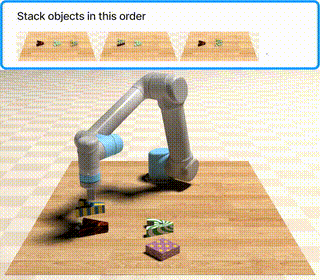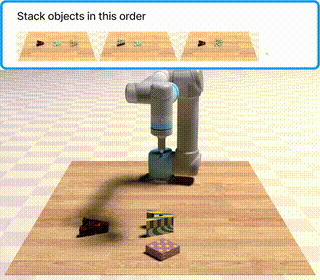
Chuyển lên cấp khó hơn
Chỉ cần đổi --partition và --task để thử các cấp cao hơn:
# Cấp 2: tổ hợp adjective-noun chưa thấy trong training
python scripts/example.py \
--ckpt=ckpts/200M.ckpt \
--partition=combinatorial_generalization \
--task=same_texture
# Cấp 4: task template hoàn toàn mới
python scripts/example.py \
--ckpt=ckpts/200M.ckpt \
--partition=novel_task_generalization \
--task=novel_adj_noun
Sự chênh lệch performance giữa hai lệnh này chính là câu trả lời cho câu hỏi "model này có tổng quát hóa được không?" — và thường chênh nhau 20–40 điểm phần trăm success rate.
17 Task — 6 Nhóm Chức Năng
VimaBench không chọn 17 task ngẫu nhiên. Chúng được thiết kế để bao phủ các năng lực nhận thức khác nhau mà một robot manipulation system cần có, từ thao tác vật thể đơn giản đến suy luận đa bước. Mỗi task thuộc một trong 6 nhóm:
Nhóm 1: Simple Object Manipulation
| Task | Mô tả ngắn |
|---|---|
visual_manipulation |
Nhặt vật A → đặt vào vị trí B theo chỉ dẫn hình ảnh |
scene_understanding |
Phân tích cảnh và chọn đúng đối tượng theo mô tả |
Đây là "hello world" của robot manipulation — nhưng với twist quan trọng: thông tin về vật nào và đặt đâu được truyền qua ảnh trong prompt, không phải text thuần túy. Model phải ground multimodal reference vào không gian vật lý 3D.

Nhóm 2: Visual Goal Reaching
| Task | Mô tả ngắn |
|---|---|
rotate |
Xoay vật thể đến góc được chỉ định trong ảnh goal |
rearrange |
Sắp xếp lại các đối tượng để khớp với cấu hình trong ảnh goal |
rearrange_then_restore |
Sắp xếp theo goal, sau đó phục hồi về trạng thái ban đầu |
Khó hơn nhóm 1 vì model phải hiểu quan hệ không gian tương đối giữa các đối tượng, không chỉ vị trí tuyệt đối. Task rearrange_then_restore đặc biệt thú vị: nó đòi hỏi model duy trì bộ nhớ về trạng thái ban đầu trong suốt quá trình thực thi.
Nhóm 3: Novel Concept Grounding
| Task | Mô tả ngắn |
|---|---|
novel_adj |
Học adjective mới (màu/texture lạ) từ 1–2 ví dụ trong prompt |
novel_noun |
Học noun mới (loại vật thể lạ) từ 1–2 ví dụ |
novel_adj_noun |
Kết hợp cả adjective và noun mới chưa từng thấy |
twist |
Áp dụng khái niệm "xoắn" (twist) theo ngữ cảnh mới |
Đây là bộ task few-shot grounding: prompt cung cấp 1–2 ví dụ về khái niệm mới (như "glassy" hay "mug"), model phải hiểu và tổng quát hóa sang instance chưa từng thấy. Nhóm này trực tiếp test khả năng học từ context, không phải từ training data.
Nhóm 4: One-Shot Video Imitation
| Task | Mô tả ngắn |
|---|---|
follow_motion |
Bắt chước chuỗi chuyển động từ video demo (spatial trajectory) |
follow_order |
Thực hiện các action theo đúng thứ tự xuất hiện trong video |
Prompt là video clip — chuỗi frame thể hiện demo — không phải ảnh tĩnh. Model phải extract temporal structure từ video: đối tượng nào xuất hiện theo thứ tự nào, và hành động nào được thực hiện.
Nhóm 5: Visual Constraint Satisfaction
| Task | Mô tả ngắn |
|---|---|
sweep_without_exceeding |
Quét vật thể vào khu vực mà không vượt quá ngưỡng số lượng |
sweep_without_touching |
Quét vật thể mà không chạm vào đối tượng cụ thể được chỉ định |
Model phải thực hiện task trong khi tuân theo ràng buộc phủ định — không làm X trong khi làm Y. Đây là kỹ năng cực kỳ quan trọng cho an toàn trong môi trường thực: robot hàn không được chạm vào wire hàng xóm, robot pick-and-place không được vượt quá trọng tải kệ.
Nhóm 6: Visual Reasoning
| Task | Mô tả ngắn |
|---|---|
same_texture |
Nhặt vật thể có cùng texture như vật mẫu trong prompt |
same_shape |
Nhặt vật thể có cùng hình dạng như vật mẫu |
manipulate_old_neighbor |
Tương tác với vật thể từng đứng cạnh vật khác (bộ nhớ không gian) |
pick_in_order_then_restore |
Nhặt theo thứ tự xác định, rồi đặt lại theo thứ tự ngược |
Nhóm khó nhất: đòi hỏi suy luận đa bước, bộ nhớ về trạng thái trước đó, và so sánh thuộc tính trực quan. Task manipulate_old_neighbor đặc biệt thú vị — model phải nhớ spatial relationship từ đầu episode để biết "neighbor" của một vật thể là ai.

Giao Thức 4 Cấp — Trái Tim của VimaBench
Đây là phần làm VimaBench khác biệt với benchmark thông thường. Thay vì chỉ test trên distribution giống training, VimaBench định nghĩa 4 partition với mức độ khó tăng dần, mỗi cấp đo một loại tổng quát hóa khác nhau.
Hãy hình dung 4 cấp này như 4 câu hỏi ngày càng khó hơn đặt ra cho model:
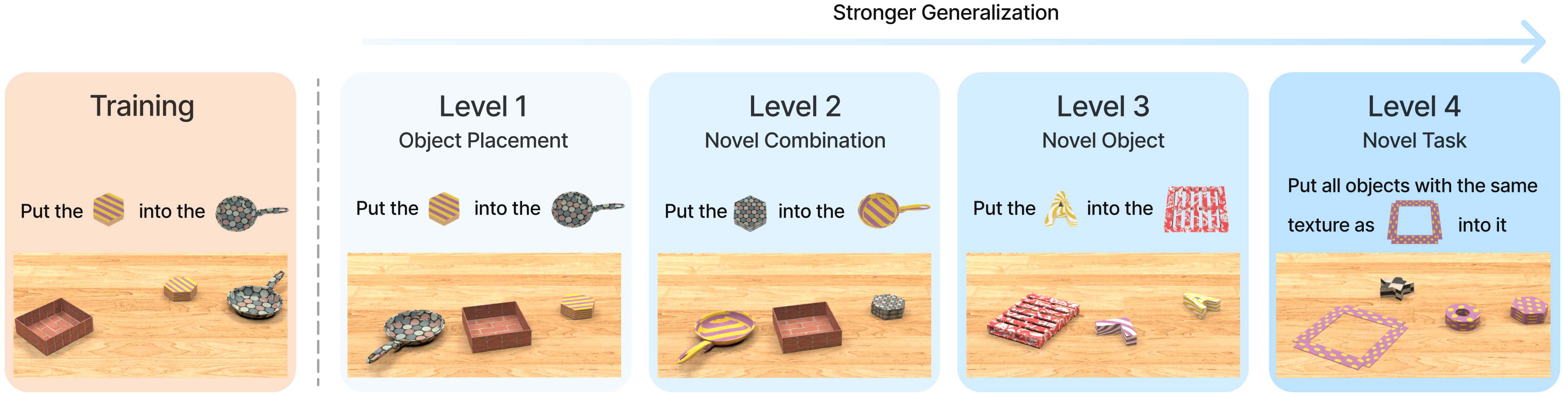
Cấp L1: placement_generalization
Câu hỏi: Model có overfit vào vị trí cụ thể trong training data không?
Thiết lập: Training dùng tập hạn chế các vị trí đặt vật; test đặt vật thể ngẫu nhiên trên toàn bộ bàn.
Đây là test baseline tối thiểu. Nếu model fail ở đây, nó đã overfit hoàn toàn vào pattern không gian cố định — vô dụng trong thực tế vì vật thể trong thế giới thật không bao giờ đứng đúng vị trí như training.
from vima_bench import make, PARTITION_TO_SPECS
task = "follow_order"
partition = "placement_generalization"
env = make(
task,
task_kwargs=PARTITION_TO_SPECS["test"][partition][task],
render_prompt=True, # hiển thị multimodal prompt
display_debug_window=True,
)
obs, prompt, prompt_assets = env.reset()
# prompt: dict với 'prompt_token_type' và 'prompt_tokens'
# prompt_assets: dict chứa ảnh reference cho các placeholder trong prompt
print(f"Prompt tokens: {prompt['prompt_token_type']}")
# Output dạng: [0, 0, 1, 0, 1, 0] — 0=text, 1=image
Tất cả 17 task đều có partition L1 — đây là điểm khởi đầu bắt buộc khi đánh giá bất kỳ model nào.
Cấp L2: combinatorial_generalization
Câu hỏi: Model có học thuộc tính như các khái niệm độc lập, hay chỉ học pattern kết hợp cụ thể?
Thiết lập: Training thấy "red cube" và "blue sphere"; test thấy "red sphere" và "blue cube" — tổ hợp chưa từng xuất hiện nhưng cả hai từ đều quen.
Đây là test systematic compositionality kinh điển trong AI. Nhiều model deep learning fail ở đây vì chúng học "red → cube" như một unit thay vì hiểu "red" và "cube" là hai attribute độc lập có thể kết hợp tự do.
partition = "combinatorial_generalization"
env = make(
task,
task_kwargs=PARTITION_TO_SPECS["test"][partition][task],
)
# Kiểm tra config: xem những tổ hợp nào được test
config = PARTITION_TO_SPECS["test"][partition][task]
print(f"Config keys: {list(config.keys())}")
# Gồm các key như: possible_dragged_obj, possible_dragged_obj_texture,
# possible_base_obj, possible_base_obj_texture, ...
Tại sao quan trọng cho robotics thực tế: Trong nhà máy, công nhân hướng dẫn robot bằng cách kết hợp thuộc tính — "cái này (màu mới) đặt vào vị trí đó". Nếu model không compositional, mỗi tổ hợp mới đều cần fine-tune lại.
Cấp L3: novel_object_generalization
Câu hỏi: Model có xử lý được vật thể hoàn toàn mới (chưa thấy trong training) không?
Thiết lập: Training dùng tập cố định đối tượng và màu sắc; test đưa vào adjective MỚI (màu/texture chưa bao giờ thấy) hoặc noun MỚI (loại vật thể chưa bao giờ thấy).
Đây là zero-shot generalization thực sự về đối tượng. Model không thể dựa vào visual memory về vật thể cụ thể — nó phải hiểu task instruction đủ tốt để thực thi với bất kỳ vật thể mới nào được chỉ ra trong prompt.
partition = "novel_object_generalization"
env = make(
task,
task_kwargs=PARTITION_TO_SPECS["test"][partition][task],
)
obs, prompt, prompt_assets = env.reset()
# prompt_assets sẽ chứa ảnh của vật thể MỚI chưa thấy trong training
# Model phải dùng cross-attention để "đọc" ảnh trong prompt
# thay vì recall từ training memory
Tại sao đây là ranh giới thực tế: Môi trường thực tế luôn có vật thể mới — hộp mới, sản phẩm mới ra mắt, màu theo mùa. Model chỉ pass L1/L2 sẽ fail ngay khi gặp bất kỳ vật thể nào ngoài training vocabulary.
Cấp L4: novel_task_generalization
Câu hỏi: Model có thực hiện được task template hoàn toàn mới chưa từng thấy trong training không?
Thiết lập: Training dùng 16/17 task template; task bị giấu hoàn toàn khỏi training set. Prompt dùng từ quen thuộc và vật thể quen thuộc, nhưng cấu trúc task là hoàn toàn mới.
partition = "novel_task_generalization"
# Ví dụ: test trên task novel_adj_noun — học cả adjective lẫn noun mới
task = "novel_adj_noun"
env = make(
task,
task_kwargs=PARTITION_TO_SPECS["test"][partition][task],
)
obs, prompt, prompt_assets = env.reset()
# Prompt chứa ví dụ "few-shot" về khái niệm mới ngay trong prompt header
# Model phải suy luận task structure từ ví dụ đó
# Không thể pattern-match với training memory
Đây là cấp khó nhất và thú vị nhất từ góc độ nghiên cứu. Model không thể pattern-match với gì đã thấy — nó phải đọc multimodal prompt và suy luận về intent, giống như con người hiểu hướng dẫn mới từ context.
PARTITION_TO_SPECS: Bên Trong Cấu Hình
PARTITION_TO_SPECS là dictionary chứa config cho từng cấp eval, từng task — kiểm soát chính xác những gì được phép xuất hiện khi instantiate task:
from vima_bench import PARTITION_TO_SPECS
# Cấu trúc: test → partition → task → config dict
config = PARTITION_TO_SPECS["test"]["novel_object_generalization"]["same_texture"]
print(config)
# Ví dụ output:
# {
# 'num_dragged_obj': 1,
# 'num_distractor_obj': 3,
# 'possible_dragged_obj_texture': ['new_texture_1', 'new_texture_2', ...],
# 'possible_base_obj_texture': ['familiar_texture_1', ...],
# 'possible_dragged_obj': ['cube', 'sphere', ...],
# ...
# }
Config này đảm bảo:
- L1: object pool và texture là quen thuộc, chỉ vị trí đặt là ngẫu nhiên
- L2: object/texture quen thuộc nhưng tổ hợp adj-noun chưa từng thấy
- L3: có ít nhất một adjective hoặc noun trong
possible_...là hoàn toàn mới - L4: không chỉ object mới mà cả cấu trúc task template là mới
Đây là cơ chế đảm bảo tính công bằng của benchmark — mỗi partition thực sự đo đúng loại tổng quát hóa đã cam kết, không có data leakage.
Cấp Nào Quan Trọng Nhất Cho Humanoid?
Câu trả lời ngắn: L4 là con số duy nhất đáng quan tâm khi mục tiêu là deploy lên humanoid thực tế.
Lý do từng cấp:
L1 là ngưỡng tối thiểu, không phải thành tựu. Nếu model không pass L1 (placement generalization), nó không đáng dùng. Pass L1 chỉ nói "model này không bị broken cơ bản" — như việc xe hơi phải chạy được mới được gọi là xe.
L2 là prerequisite cho production. Humanoid trong nhà máy gặp hàng trăm tổ hợp mới mỗi ngày — sản phẩm mới, màu mới, kích thước mới trong cùng dây chuyền. Model không pass L2 cần re-train thường xuyên, biến deployment thành ác mộng vận hành.
L3 phân biệt "lab demo" với "robot thực sự". Với humanoid làm việc trong môi trường mở có vật thể mới xuất hiện liên tục, L3 là ranh giới giữa "dùng được" và "phải có người giám sát 24/7 để handle exception".
L4 là bài test của kiến trúc, không phải data. Model pass L4 đã chứng minh rằng cơ chế prompt conditioning thực sự hoạt động — model đọc và hiểu task intent từ prompt, không chỉ recall từ training memory. Đây là capability cốt lõi cho humanoid assistant trong gia đình hay văn phòng, nơi người dùng liên tục đưa ra hướng dẫn mới chưa từng có trong training set.
Pattern trong Kết Quả VIMA
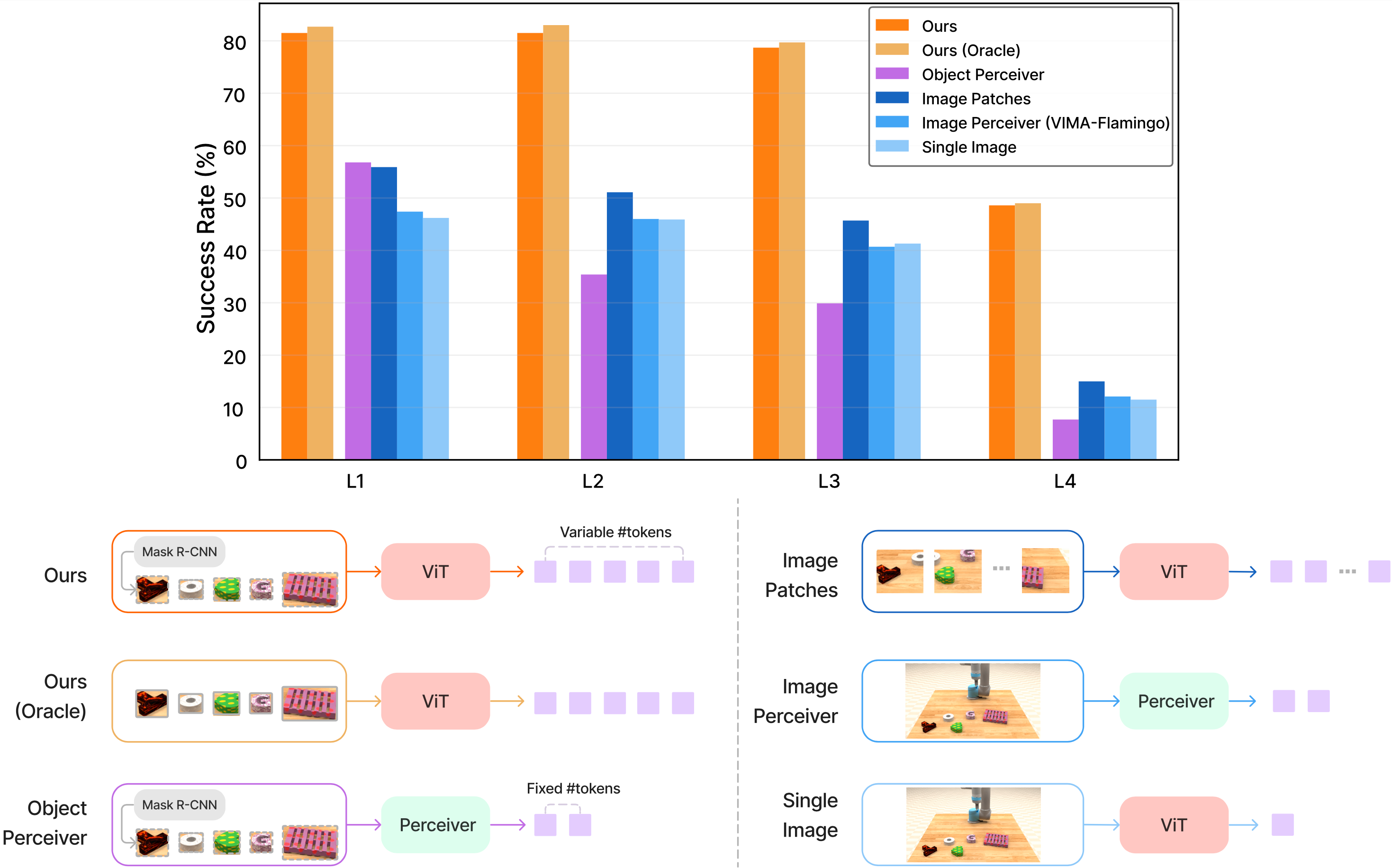
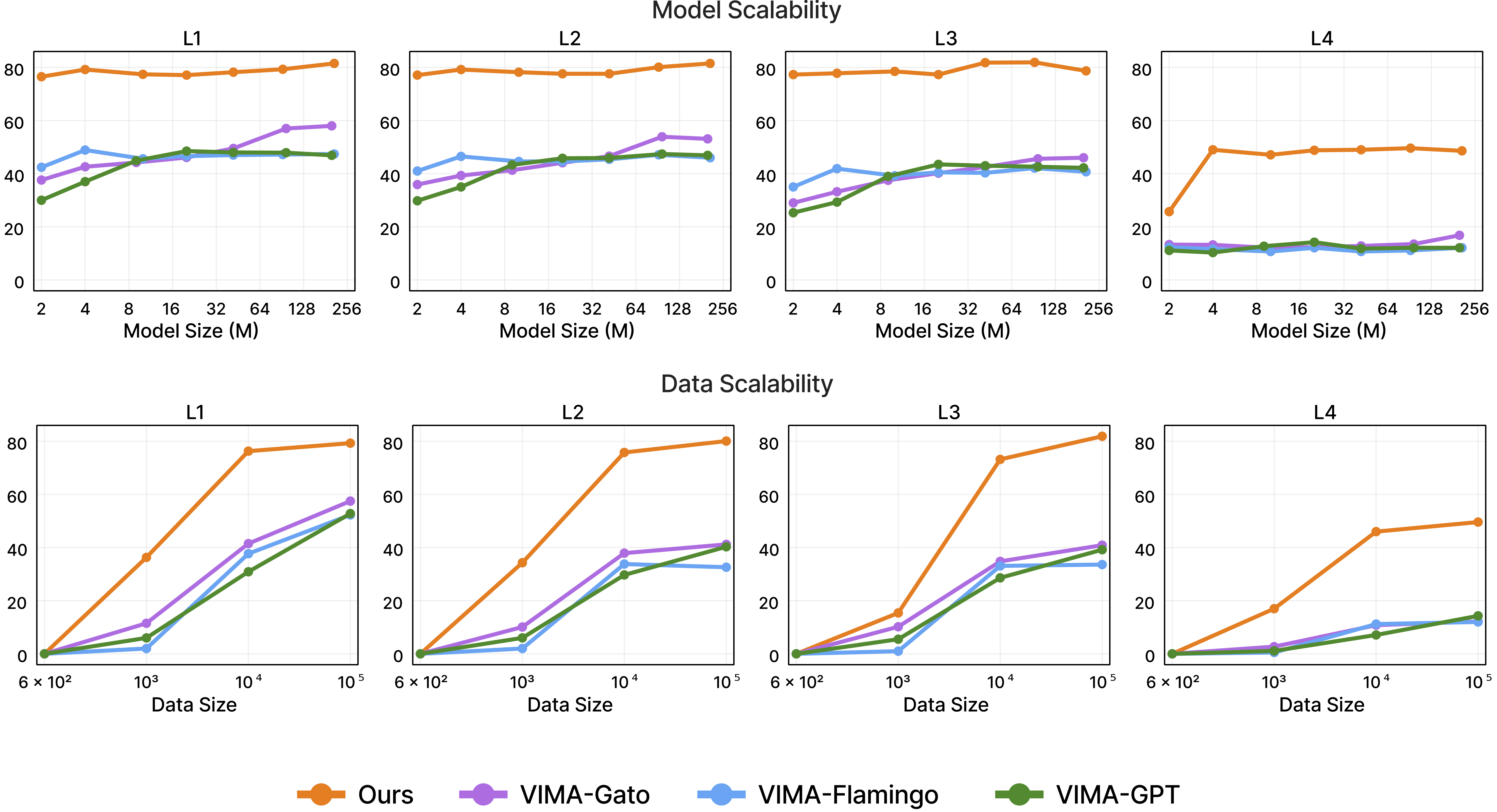
Paper VIMA (ICML 2023) cho thấy một pattern nhất quán: VIMA với dense cross-attention giữ performance tốt hơn hẳn các baseline khi leo từ L1 lên L4 — đặc biệt ở L3 và L4, nơi GPT-style prefix conditioning suy giảm mạnh nhất.
Lý do đã phân tích trong Bài 1: GPT-style prefix đọc prompt một lần rồi dựa vào self-attention để lan truyền — signal bị loãng dần qua các layer. Khi task là hoàn toàn mới (L4), model cần "đọc lại prompt" ở mỗi layer để không bị drift khỏi task intent. Dense cross-attention ở mỗi trong 12 layer làm đúng điều này.
Scaling law cũng thú vị: model nhỏ (9M) suy giảm nhiều hơn khi leo lên L3/L4 so với model lớn (200M) — nhưng ngay cả VIMA-9M vẫn suy giảm ít hơn so với GPT-style prefix 200M ở các cấp cao. Đây là bằng chứng rằng kiến trúc quan trọng hơn kích thước model khi đo khả năng tổng quát hóa.
Đánh Giá Đầy Đủ Theo Code
Để chạy đánh giá hệ thống trên tất cả task trong một partition (thay vì từng task thủ công), dùng pattern sau:
from vima_bench import make, PARTITION_TO_SPECS
import numpy as np
def evaluate_partition(policy, partition: str, n_episodes: int = 50):
"""Đánh giá policy trên toàn bộ task trong một partition."""
results = {}
task_names = list(PARTITION_TO_SPECS["test"][partition].keys())
for task in task_names:
env = make(
task,
task_kwargs=PARTITION_TO_SPECS["test"][partition][task],
)
success_count = 0
for _ in range(n_episodes):
obs, prompt, prompt_assets = env.reset()
done = False
while not done:
# Thay bằng actual policy inference
action = policy.predict(obs, prompt, prompt_assets)
obs, reward, done, info = env.step(action)
if info["success"]:
success_count += 1
results[task] = success_count / n_episodes
print(f" {task}: {results[task]:.1%}")
mean_success = np.mean(list(results.values()))
print(f"\n→ Mean {partition}: {mean_success:.1%}")
return results
# Chạy lần lượt từ L1 đến L4
for partition in PARTITION_TO_SPECS["test"]:
print(f"\n=== {partition} ===")
evaluate_partition(your_policy, partition)
So sánh Checkpoint Sizes
Khi so sánh kích thước model, chỉ cần đổi --ckpt — script không thay đổi:
# So sánh 9M vs 200M trên cấp khó nhất
for size in 9M 200M; do
python scripts/example.py \
--ckpt=ckpts/${size}.ckpt \
--partition=novel_task_generalization \
--task=follow_order
done
Kết quả sẽ thấy rõ: model nhỏ suy giảm nhiều hơn ở L3/L4, nhưng cross-attention architecture vẫn giúp model nhỏ competitive hơn so với baseline lớn hơn — đặc biệt quan trọng khi chọn kích thước model phù hợp với hardware edge của humanoid.
Kết Luận
VimaBench không chỉ là tập hợp 17 task — nó là một ngôn ngữ để nói chính xác về generalization. Khi ai đó nói "model của tôi đạt 70% trên VimaBench", câu hỏi đúng phải là: 70% trên partition nào? L1 hay L4? Chênh lệch đó là ranh giới giữa "lab demo tốt" và "production-ready".
Với humanoid robot, tiêu chuẩn phải là L4. Robot trong gia đình, nhà máy, hay bệnh viện nhận hàng trăm hướng dẫn mới mỗi ngày từ người dùng — và không có cách nào train trước cho tất cả. Model cần chứng minh pass L4 để xác nhận rằng nó thực sự đọc hiểu prompt, không chỉ nhớ pattern.
Ở Bài 3: Object Tokenizer, chúng ta sẽ đi vào chi tiết cách VIMA biến raw pixel thành object token — phần pipeline quan trọng nhất để model có thể xử lý vật thể mới trong L3 mà không cần thấy chúng trong training.