Hãy tưởng tượng bạn dạy robot bằng cách chỉ tay vào ảnh: "đặt cái này (ảnh khối đỏ) lên chỗ này (ảnh vị trí mục tiêu)". Không code. Không fine-tune. Chỉ cần thay đổi prompt — robot tự hiểu và làm. Đó là điều VIMA (VisuoMotor Attention, ICML 2023) thực hiện được, và bài này sẽ giải thích tại sao kiến trúc cross-attention là chìa khóa cho khả năng đó — từ code thực tế, không phải lý thuyết chung chung.
VIMA giải quyết một bài toán nền tảng: một model duy nhất xử lý 17 task robot manipulation khác nhau, chỉ bằng cách thay đổi multimodal prompt đầu vào. Bí quyết nằm ở cách kiến trúc được thiết kế để tách biệt thông tin nhiệm vụ (prompt) với thông tin trạng thái hiện tại (observation/action history) — và dùng cross-attention để kết nối chúng một cách có kiểm soát.
Roadmap Series
Bài này là bài 1/5 trong series VIMA: Prompt Đa Phương Thức cho Robot Tay Người:
| Bài | Chủ đề |
|---|---|
| Bài 1 (bạn đang đọc) | Kiến trúc Cross-Attention: XAttn GPT + T5 Encoder |
| Bài 2 → Benchmark 17 Task | Đo lường khả năng tổng quát hóa qua 4 cấp độ |
| Bài 3 → Object Tokenizer | Từ pixel thô đến token đối tượng với Mask R-CNN + ViT |
| Bài 4 → Dataset 650K | Cách thu thập dữ liệu đa nhiệm vụ quy mô lớn |
| Bài 5 → Humanoid Adaptation | Mở rộng VIMA lên robot hình người DoF cao |
Bài Toán Cốt Lõi: Một Model, Mười Bảy Task
Trước VIMA, robotics ML gặp phải "lời nguyền chuyên biệt hóa": mỗi task cần một model riêng. Muốn robot xếp khối theo thứ tự? Train model A. Muốn robot làm theo video mẫu? Model B. Muốn robot tránh vật cản trong khi di chuyển? Model C. Không tái sử dụng được, không tổng quát hóa được.
VIMA đặt câu hỏi khác: Thay vì thay đổi model, tại sao không thay đổi prompt?
Nhưng đây là chỗ khó: prompt của robot không thể chỉ là văn bản. Nhiều task đòi hỏi mô tả trực quan — "đặt vật này (ảnh) vào vị trí này (ảnh khác)", hay "làm theo chuỗi động tác trong video này". VIMA vì thế phát minh ra multimodal prompt — chuỗi token xen kẽ giữa ngôn ngữ và ảnh đối tượng, được encode bằng cùng một pipeline T5.
Nguồn: VIMA project page — vimalabs.github.io
T5 Prompt Encoder: Đọc Hiểu Prompt Hỗn Hợp
File: vima/nn/prompt_encoder/prompt_encoder.py
Vấn đề kỹ thuật đầu tiên: làm sao encode một chuỗi gồm cả text và ảnh thành vector context duy nhất? VIMA dùng T5-base làm encoder — nhưng không theo cách thông thường.
Thay vì truyền input_ids (ID từ vựng cố định), VIMA truyền trực tiếp inputs_embeds — tức là vector embedding đã tính sẵn bên ngoài T5. Trick này cho phép text token và image token (vốn không có trong từ vựng T5) cùng nằm chung một sequence và được T5 xử lý như nhau:
class T5PromptEncoder(nn.Module):
def forward(self, x, *, attention_mask=None, batch_first=False):
# x: (L, B, E) — mixed text+image token embeddings
out = self.t5(
inputs_embeds=x.contiguous(), # không dùng input_ids!
attention_mask=attention_mask,
).last_hidden_state
return out
Cách xen kẽ text và image token
Quá trình lắp ráp (assembly) diễn ra trong VIMAPolicy.forward_prompt_assembly(). Mỗi phần tử trong raw_prompts_token_type là số 0 (text) hoặc 1 (image):
for item in raw_prompt:
if item == 0: # word token
assembled_prompt.append(batch_word_emb[word_ptr])
word_ptr += 1
elif item == 1: # image → n_max_objs object tokens
for q in range(n_max_objs):
assembled_prompt.append(batch_image_emb[img_ptr][q])
img_ptr += 1
Ví dụ với prompt "đặt [ảnh khối đỏ] vào [ảnh vị trí target]", sequence sẽ là:
[emb_"đặt", emb_"vào", obj_red_front, obj_red_top, obj_target_front, obj_target_top]
Sequence hỗn hợp này đi qua T5 encoder. Quan trọng: chỉ 2 layer cuối của T5 được fine-tune — 10 layer đầu giữ nguyên trọng số pretrained. Chiến lược này tận dụng khả năng ngôn ngữ tích lũy của T5 mà không tốn compute fine-tune toàn bộ.
Đầu ra last_hidden_state — tensor (B, L_prompt, 768) — là "bản tóm tắt ngữ cảnh" của toàn bộ prompt. Mỗi position đã được contextualize bi-directional bởi tất cả position xung quanh. Đây sẽ là K (Key) và V (Value) trong bước cross-attention ở decoder.
XAttn GPT: Decoder Tham Chiếu Prompt Ở Mỗi Layer
File: vima/nn/seq_modeling/xattn_gpt/xattn_gpt.py
Đây là trái tim của VIMA. XAttnGPT kế thừa từ OpenAIGPTPreTrainedModel nhưng có một twist quan trọng — hai ModuleList song song thay vì một:
self.h = nn.ModuleList(
[Block(n_positions, cfg, scale=True) for _ in range(n_layer)]
)
self.xattns = nn.ModuleList(
[
XAttention(embd_dim, num_heads=xattn_n_head, ...)
for _ in range(n_layer)
]
)
self.h là các khối causal self-attention của GPT gốc. self.xattns là các khối cross-attention hoàn toàn mới. Và vòng lặp forward trông như thế này:
for self_attn, xattn in zip(self.h, self.xattns):
# Bước 1: cross-attend to prompt (prompt là K, V)
obs_action_tokens = xattn(
q=obs_action_tokens,
kv=prompt_tokens,
attention_mask=prompt_mask,
)
# Bước 2: causal self-attend trong sequence obs/action
obs_action_tokens = self_attn(
obs_action_tokens, attention_mask=obs_action_masks
)[0]
Thứ tự này không phải ngẫu nhiên: cross-attention trước, self-attention sau.
Hãy nghĩ theo kiểu con người: khi làm việc, bạn đọc lại hướng dẫn (cross-attend to prompt), rồi mới nhìn lại những gì mình đã làm (self-attend to history). Nếu tự nhìn lịch sử trước, signal từ hướng dẫn có thể bị "pha loãng" trước khi được bổ sung.
Ở cả 12 layer, robot token đều trực tiếp tham chiếu đến encoded prompt. Model không chỉ nhìn prompt ở layer đầu rồi "quên đi" — nó liên tục được nhắc nhở về nhiệm vụ ở mọi độ sâu của transformer.
Hai bảng position embedding độc lập
self.positions_embed = nn.Embedding(n_positions, embd_dim) # cho obs/action
self.xattn_positions_embed = nn.Embedding(xattn_n_positions, embd_dim) # cho prompt
Tại sao tách hai loại position? Vì đây là hai không gian hoàn toàn khác nhau. "Token thứ 3 trong obs/action history" có ý nghĩa hoàn toàn khác với "token thứ 3 trong prompt". Nếu dùng chung một bảng position, model sẽ bị nhầm lẫn giữa hai luồng thông tin.
So Sánh: Tại Sao Cross-Attention Thắng?
Có ba cách chính để conditioning model trên prompt:
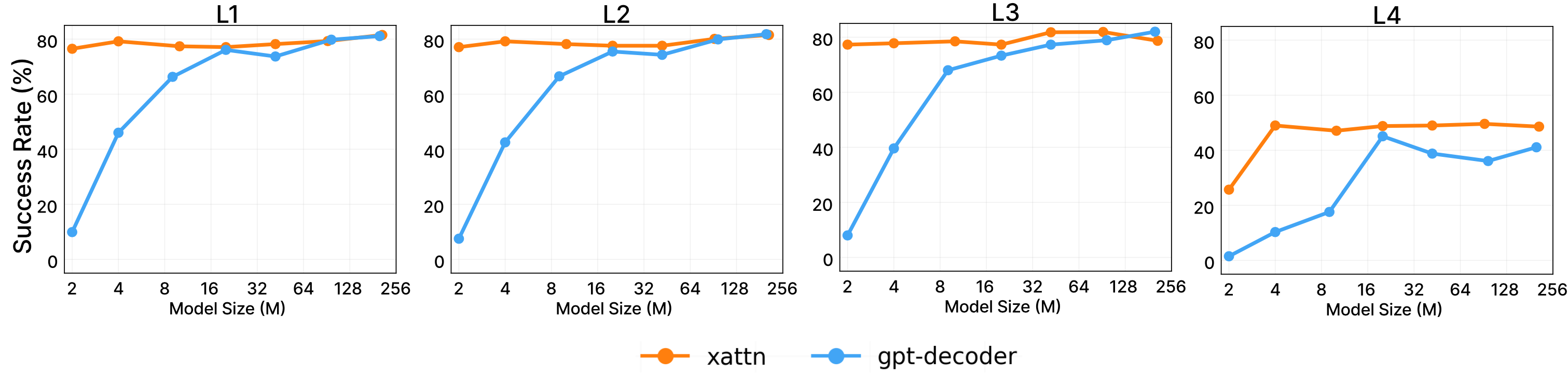
1. GPT-style (prefix concatenation): Nối prompt vào đầu obs/action sequence, dùng causal self-attention trên toàn bộ. Vấn đề: ở layer sâu, signal từ prompt đã "loãng" qua nhiều hop attention. Với sequence dài, gradient cũng khó lan ngược về phần prompt ở đầu.
2. Flamingo-style (sparse cross-attention): Cross-attend xen kẽ — chỉ một số layer nhất định có cross-attention. Nhanh hơn nhưng prompt ít được "tươi mới hóa" so với mỗi layer.
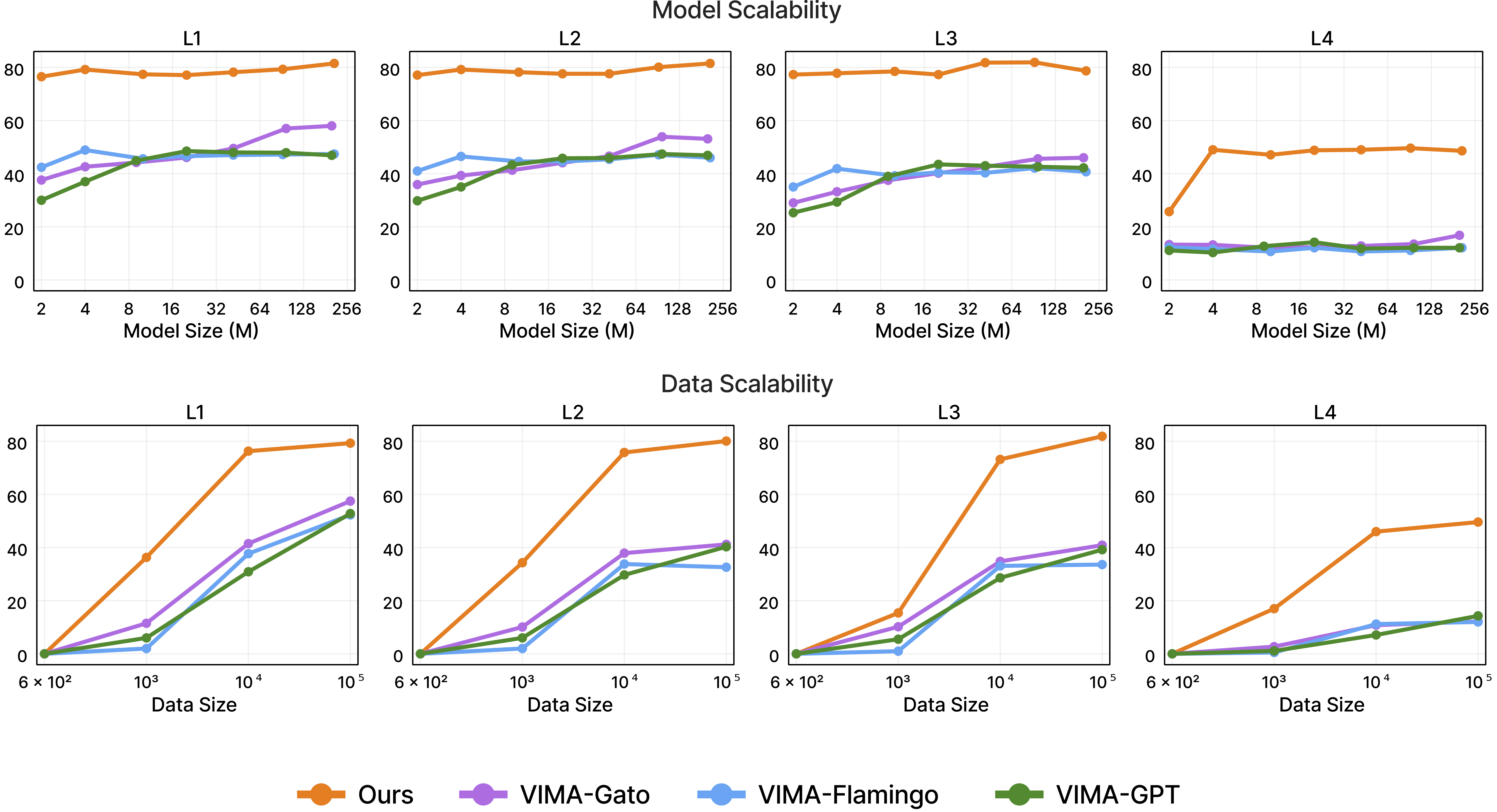
3. VIMA-style (dense cross-attention): Mỗi trong 12 layer đều cross-attend trực tiếp đến encoded prompt. Model có thể "tham khảo lại prompt gốc" ở mọi độ sâu. Ablation trong paper cho thấy đây là phương pháp mạnh nhất — đặc biệt ở model nhỏ và task tổng quát hóa khó, nơi mà GPT-style prefix bị suy giảm hiệu quả rõ rệt.
VIMAPolicy: Pipeline Tổng Thể Từ Đầu Đến Cuối
File: vima/policy/vima_policy.py
VIMAPolicy là "tổng chỉ huy" kết nối tất cả các thành phần. Hãy trace qua một forward pass hoàn chỉnh:
Bước 1 — Encode prompt (một lần duy nhất cho toàn bộ episode)
Text trong prompt → WordEmbedding → word embeddings
Ảnh trong prompt → ObjEncoder (Mask R-CNN + ViT) → image object embeddings
Xen kẽ theo type → [word, word, obj, obj, word, obj, ...]
→ T5PromptEncoder → (B, L_prompt, 768)
→ Linear → (B, L_prompt, embed_dim)
Bước 2 — Encode observation hiện tại (mỗi timestep)
Current scene → ObjEncoder → object features
End-effector → Embedding(dim=2)
Concat + Linear → obs_token (embed_dim)
Bước 3 — Xây dựng sequence obs/action
[obs_t0, act_t0, obs_t1, act_t1, ..., obs_tN] → token sequence (L, B, embed_dim)
Bước 4 — XAttn GPT
obs/action sequence + prompt_tokens → XAttnGPT (12 lớp xattn + sattn)
→ predicted_action_tokens
Token output tại vị trí của obs_tN (cuối sequence) chứa thông tin dự đoán action tiếp theo.
Bước 5 — Decode action
self.action_decoder = vnn.ActionDecoder(
input_dim=embed_dim,
action_dims={
"pose0_position": [50, 100], # 50 bins x, 100 bins y
"pose0_rotation": [50] * 4, # 50 bins cho mỗi quaternion component
"pose1_position": [50, 100],
"pose1_rotation": [50] * 4,
},
...
)
VIMA discretize action space thành bins — 50 bins theo x, 100 bins theo y, 50 bins theo z, 50 bins cho mỗi thành phần quaternion. Đây là lựa chọn kỹ thuật quan trọng: biến regression liên tục thành classification, giúp training ổn định hơn nhiều so với predict số thực trực tiếp.
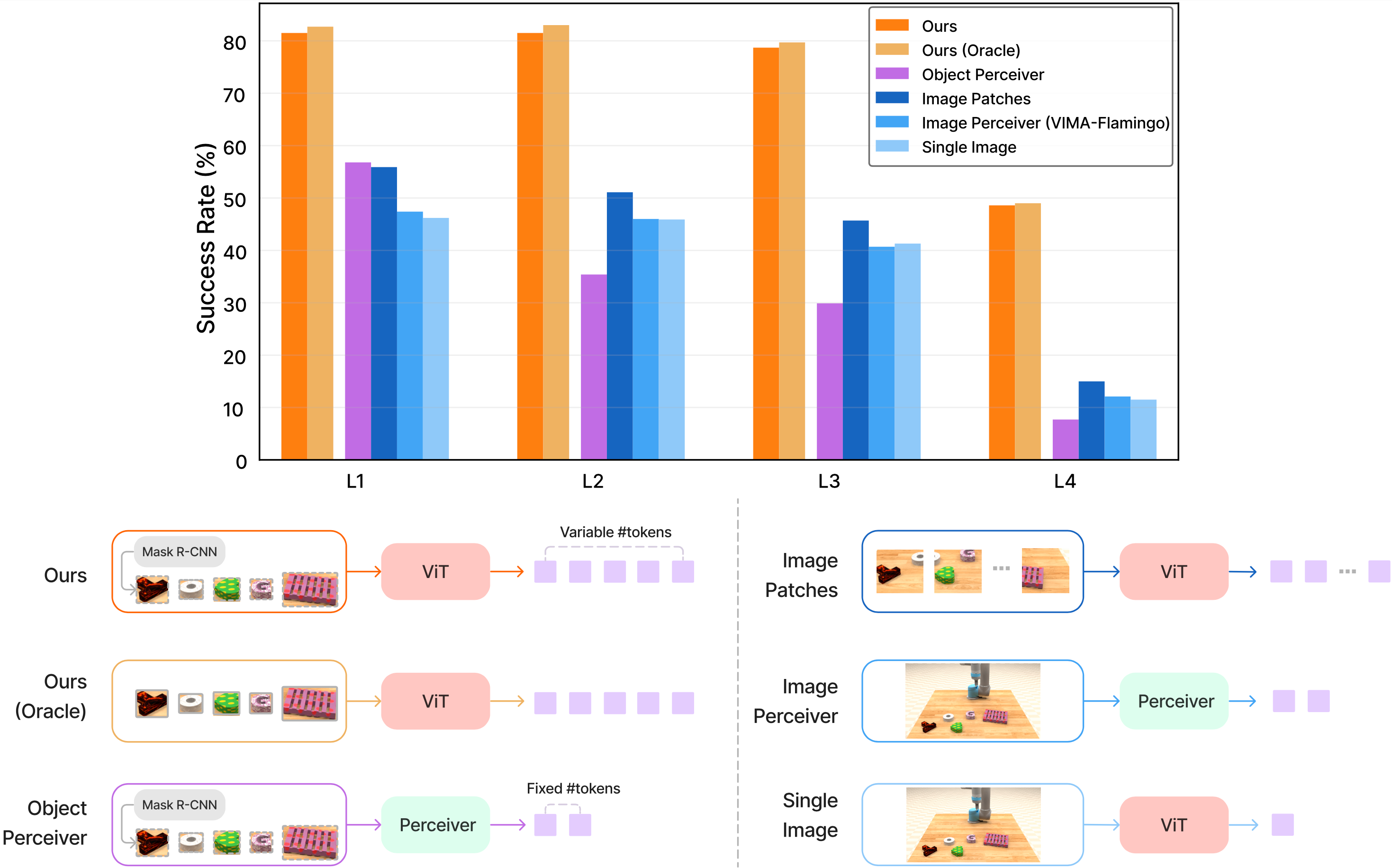
ObjEncoder: Ngôn Ngữ Của Đối Tượng
self.obj_encoder = vnn.ObjEncoder(
transformer_emb_dim=embed_dim,
views=["front", "top"],
vit_resolution=32, # crop 32×32 pixels cho mỗi object
vit_patch_size=16, # → chỉ 4 patch (2×2) mỗi object
vit_width=768,
vit_layers=4,
vit_heads=24,
bbox_mlp_hidden_dim=768,
bbox_mlp_hidden_depth=2,
)
VIMA không xử lý raw pixel toàn cảnh. Thay vào đó:
- Mask R-CNN detect từng đối tượng và trích bounding box
- ViT nhỏ (4 layer, 24 heads) encode từng cropped image 32×32 — chỉ 4 patch mỗi vật
- Bounding box MLP encode tọa độ (x1, y1, x2, y2) thành vector riêng
- Concat ViT output + bbox embedding = một "object token" hoàn chỉnh
Mỗi object được nhìn từ hai góc ("front" và "top") — giúp model hiểu vị trí 3D mà không cần depth camera đắt tiền.
Trong bài Bài 3: Object Tokenizer, chúng ta sẽ đào sâu hơn vào lý do thiết kế này và so sánh với cách patch-based toàn cảnh.
Tại Sao Kiến Trúc Này Phù Hợp Với Humanoid?
Đây là điểm quan trọng nhất khi nhìn về tương lai. Humanoid robot có những đặc thù mà kiến trúc VIMA giải quyết rất khéo:
Một platform, nhiều task. Tay humanoid (10–20 DoF mỗi tay) phải làm từ vặn vít đến nấu ăn. Không thể mỗi task một model — phải có cơ chế task conditioning mạnh. VIMA chứng minh cross-attention là cơ chế đó.
Prompt thay đổi nhiệm vụ tức thì, không cần re-train. Kiến trúc tách biệt prompt (K, V trong cross-attention) với obs/action sequence (Q). Thay prompt = thay task, không thay gì trong model. Với humanoid cần linh hoạt theo lệnh người dùng, đây là kiến trúc lý tưởng.
Data efficiency. Ablation cho thấy VIMA với cross-attention chỉ cần 10% data để đạt performance tương đương GPT-style với 100% data. Dữ liệu tay humanoid cực kỳ tốn kém — data efficiency là lợi thế sống còn.
Multimodal instruction là tự nhiên. Khi hướng dẫn tay humanoid làm việc tinh tế, bạn vừa nói ("cầm chặt hơn") vừa chỉ tay vào vị trí cụ thể. VIMA đã giải quyết bài toán kỹ thuật cho loại prompt hỗn hợp này.
Bài Bài 5: Humanoid Adaptation sẽ đi cụ thể vào cách adapt VIMA policy lên action space của dexterous hand với DoF cao hơn nhiều.
Model Scale: Từ 2M Đến 200M Tham Số
VIMA cung cấp 7 checkpoint sẵn có:
| Kích thước | Tham số |
|---|---|
| VIMA-200M | 200M |
| VIMA-92M | 92M |
| VIMA-43M | 43M |
| VIMA-20M | 20M |
| VIMA-9M | 9M |
| VIMA-4M | 4M |
| VIMA-2M | 2M |
Khoảng cách này cho phép nghiên cứu scaling law một cách có hệ thống. Kết quả thú vị: cross-attention architecture cho phép model nhỏ (9M, 4M) vẫn tổng quát hóa tốt hơn so với kiến trúc prefix-conditioning cùng kích thước — đặc biệt quan trọng cho deployment trên edge hardware của humanoid.
Kết Luận
Kiến trúc VIMA có thể tóm gọn trong một câu: T5 encoder biến prompt đa phương thức thành context bất biến; cross-attention bơm context đó trực tiếp vào decoder ở mỗi trong 12 layer; causal self-attention giữ tính nhân quả trong lịch sử obs/action.
Điều làm VIMA khác biệt không phải từng thành phần riêng lẻ — T5 đã có từ 2019, Transformer từ 2017, cross-attention từ 2018. Mà là cách kết nối chúng: two-stream architecture nơi prompt và obs/action không trộn lẫn trong self-attention, mà chỉ tương tác qua cross-attention có kiểm soát — cho phép model giữ "ký ức về nhiệm vụ" xuyên suốt tất cả các layer.
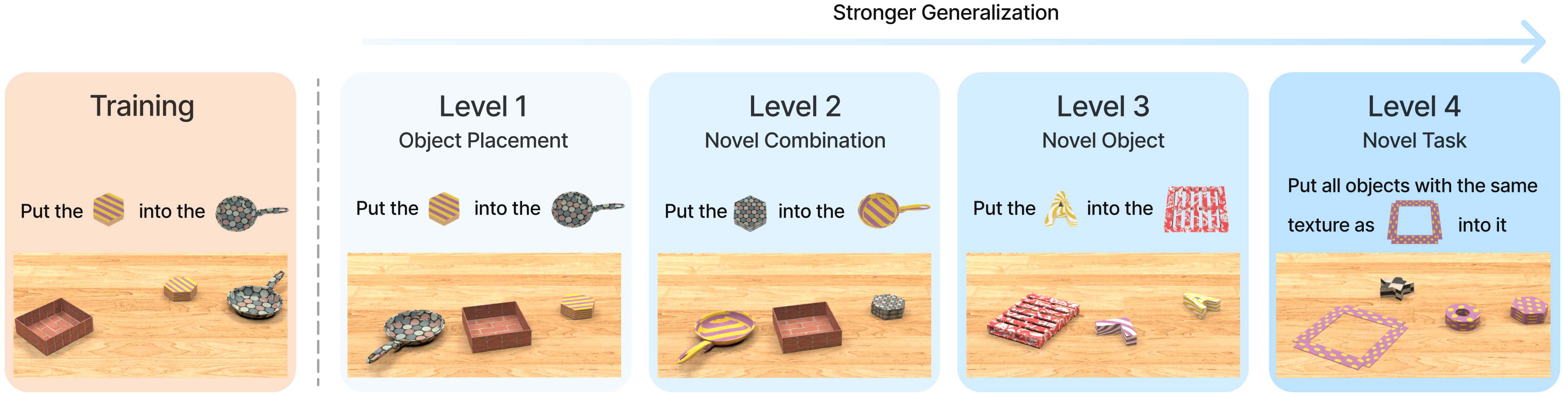
Ở bài tiếp theo, chúng ta sẽ xem VIMA được đo lường như thế nào trên 17 task và 4 cấp độ tổng quát hóa khác nhau — và con số nào mới thật sự đáng quan tâm.