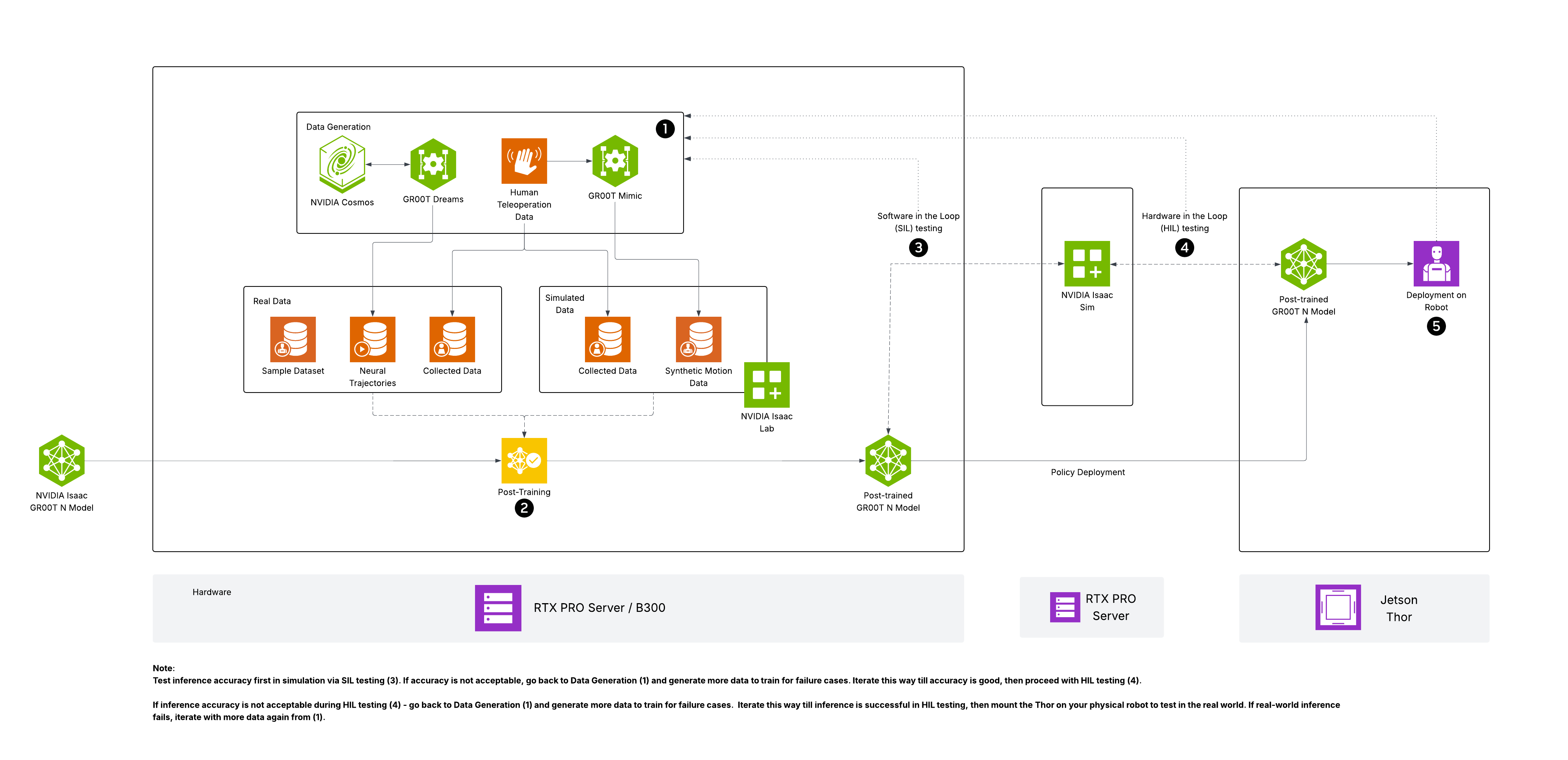
If we have to pick the hottest NVIDIA topic around VLA and humanoid whole-body control as of June 6, 2026, the strongest candidate is Isaac GR00T N1.7 combined with GR00T-WholeBodyControl and SONIC. This is not just another vision-language-action model that moves a robot arm from an image and a text prompt. The important shift is that NVIDIA now documents a practical loop: collect whole-body teleoperation demonstrations, export them as LeRobot datasets, fine-tune GR00T N1.7, then run inference through a PolicyServer that sends actions into the SONIC whole-body controller on a Unitree G1.
In simple terms, GR00T is the VLA brain that reads cameras and language, while SONIC is the motor foundation model that turns compact action tokens into balanced full-body behavior. That pairing is why this topic matters: it moves VLA from tabletop manipulation toward whole-body VLA for humanoids.
This article is written for beginners, but it goes deep enough to be useful when you start reading the original repositories. If VLA is new to you, start with VLA models in robotics. For more training context, see WholeBodyVLA training pipeline and fine-tuning GR00T N1 with Isaac Lab.
Why this topic is hot
Early VLA systems were usually demonstrated on a single arm, a bimanual setup, or a mobile manipulator. The model sees an image, receives a language instruction, and predicts either end-effector actions, joint actions, or a short action chunk. Humanoids are harder. A humanoid must reach, grasp, lean, step, turn, keep balance, coordinate both arms, move the torso, and avoid falling while following the instruction.
NVIDIA is attacking the problem from three directions:
| Direction | Main projects | Role |
|---|---|---|
| VLA foundation model | Isaac GR00T N1/N1.5/N1.7 | Understand vision + language and generate continuous actions |
| Synthetic data | GR00T-Mimic, GR00T-Dreams, Cosmos, Isaac Lab | Scale demonstrations from teleop or generated worlds |
| Whole-body controller | HOVER, SONIC, GR00T-WholeBodyControl | Convert high-level actions into stable full-body motion |
The GR00T N1 paper introduced an open VLA foundation model for humanoid robots. Its core idea is a dual-system architecture: System 2 is a vision-language module that interprets the scene and instruction, and System 1 is a diffusion transformer that produces motor actions. NVIDIA reported that GR00T N1 outperformed imitation learning baselines in simulation and could run on the Fourier GR-1 humanoid for language-conditioned bimanual manipulation. In NVIDIA's technical blog, GR00T N1 reached an average 76.8% success rate on real-world tasks with full data, compared with 46.4% for a Diffusion Policy baseline. With only 10% data, GR00T N1 reached 42.6%, while the baseline reached 10.2%.
GR00T N1.5 improved the recipe with better architecture/data choices, FLARE loss, and DreamGen synthetic trajectories. NVIDIA reported 38.3% success across 12 new DreamGen tasks versus 13.1% for N1. In a Unitree G1 post-training setup using 1K demonstrations, N1.5 reached 98.8% on seen objects and 84.2% on novel objects for a place-one-object-on-plate task, while N1 reached 44.0% on the comparable seen-object task.
GR00T N1.7 is where the whole-body story becomes very concrete. The Isaac-GR00T repository describes N1.7 as a 3B open VLA model with a new VLM backbone, relative end-effector action space, 20K hours of EgoScale human video pretraining, and support for whole-body humanoid control through the UNITREE_G1_SONIC embodiment tag. In that workflow, the VLA predicts compact latent action tokens, and a learned SONIC controller decodes them into full-body joint commands.
The paper idea: VLA needs a full-body controller
The GR00T N1 paper starts from a simple claim: general-purpose robots need both a versatile body and an intelligent mind. A robot foundation model should learn from diverse real robot trajectories, human videos, and synthetic datasets. But a VLA model alone is not enough for a humanoid. If it generates actions that ignore balance and dynamics, the robot can fail before completing the task.
That is where HOVER and SONIC enter the picture.
HOVER, an ICRA 2025 paper from NVIDIA, CMU, UC Berkeley, UT Austin, and UC San Diego, frames whole-body control as a multi-mode control problem. Navigation may need root velocity tracking. Tabletop manipulation may need upper-body joint angle tracking. Motion imitation may need full-body kinematic tracking. Existing methods often train separate policies for each command space. HOVER uses full-body kinematic motion imitation as a common abstraction, then distills multiple control modes into one unified policy. For beginners, the key point is: HOVER is not a language VLA model, but it solves a motor-control layer that a humanoid VLA stack needs.
SONIC pushes this further as a humanoid behavior foundation model. In GR00T-WholeBodyControl, NVIDIA describes SONIC as a model that learns core motor skills from large-scale human motion data. Instead of hand-building separate controllers for walking, crawling, kneeling, running, teleoperation, and multimodal control, SONIC treats motion tracking as a scalable training task. The repository includes training code, deployment code, model checkpoints, teleoperation tools, data collection scripts, and VLA inference workflows.
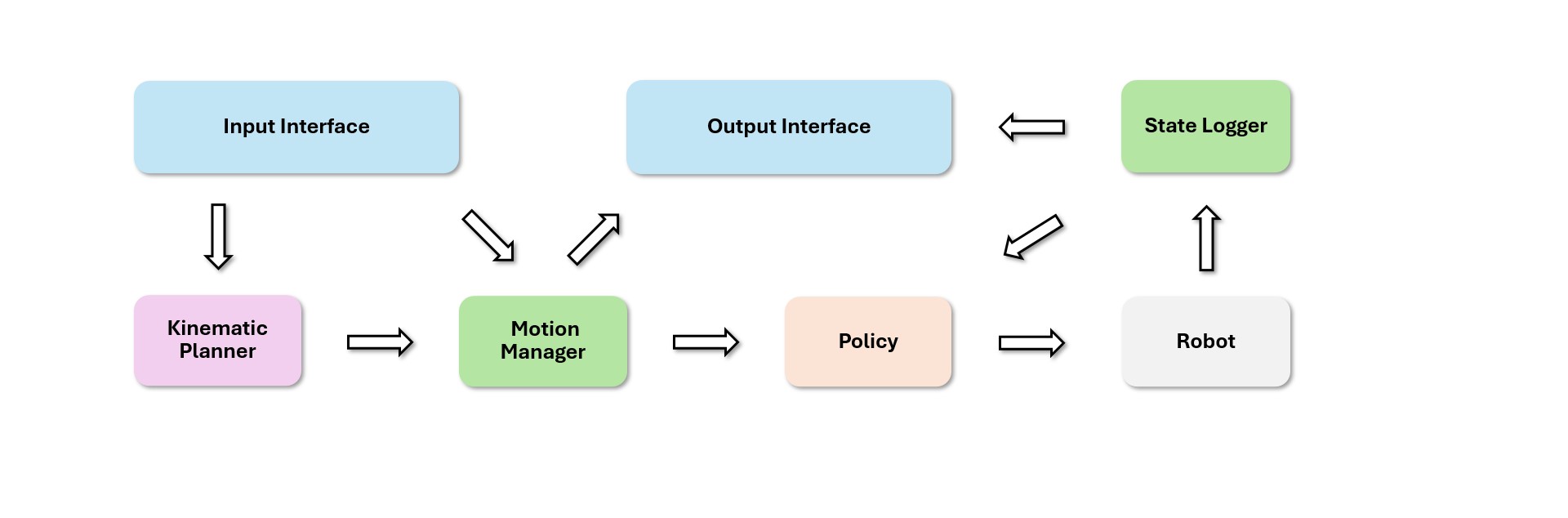
Here is the high-level architecture:
Language prompt + camera images + robot state
|
v
Isaac GR00T N1.7 VLA
VLM reasoning + DiT action head
|
v
78D UNITREE_G1_SONIC action
64D motion token + 7D left hand + 7D right hand
|
v
SONIC decoder / C++ WBC
|
v
full-body commands: legs, torso, arms, hands
This design is practical. The VLA does not need to learn every low-level dynamic behavior from scratch. It learns to choose the right latent motion/action for the task, while SONIC converts that latent action into feasible full-body motion.
GR00T N1.7 architecture
According to the Isaac-GR00T repository, GR00T N1.7 is an open VLA model for generalized humanoid robot skills. It takes multimodal inputs, including language and images, and produces actions for manipulation in diverse environments. The architecture has four concepts beginners should understand:
- Vision-language backbone: N1/N1.6 used an Eagle or Cosmos-family VLM path, while N1.7 moves to a Cosmos-Reason2-2B backbone based on Qwen3-VL. This module encodes camera images, text prompts, and task context.
- Diffusion Transformer action head: the action head denoises and predicts continuous robot actions. Robot actions are not word tokens; they are numeric control vectors over a short horizon.
- Embodiment tag: examples include
OXE_DROID_RELATIVE_EEF_RELATIVE_JOINT,LIBERO_PANDA, andUNITREE_G1_SONIC. The tag tells the model how to interpret state/action layout, normalization, and modality configuration. - GR00T LeRobot format: datasets contain
meta/,data/parquet files, andvideos/mp4 files, plusmeta/modality.jsondescribing state, action, and video keys.
A dataset looks like this:
my_dataset/
meta/
info.json
episodes.jsonl
tasks.jsonl
modality.json
data/chunk-000/
episode_000000.parquet
videos/chunk-000/
observation.images.ego_view/episode_000000.mp4
observation.images.left_wrist/episode_000000.mp4
observation.images.right_wrist/episode_000000.mp4
For the G1 whole-body workflow, the unitree_g1_sonic action space is 78-dimensional:
| Component | Size | Meaning |
|---|---|---|
| Motion token | 64 | Latent command for SONIC full-body motion |
| Left hand joints | 7 | Left hand control |
| Right hand joints | 7 | Right hand control |
This is the detail that many beginners miss. If you have trained 7-DoF arm policies before, you may expect actions to be joint deltas or end-effector deltas. In the SONIC workflow, most of the action vector is a latent token. That means the embodiment configuration, normalization statistics, and inference bridge must all match.
Installation
You need two codebases:
NVIDIA/Isaac-GR00T: model code, fine-tuning scripts, and PolicyServer.NVlabs/GR00T-WholeBodyControl: SONIC, data collection, C++ deployment, and inference launchers.
Hardware requirements depend on the goal. The Isaac-GR00T repository lists 16GB+ VRAM for inference and recommends 40GB+ VRAM for fine-tuning. A real whole-body robot setup also requires a Unitree G1, cameras, an onboard robot computer, a workstation, and PICO VR hardware if you follow NVIDIA's teleoperation data collection workflow.
Install Isaac-GR00T on a GPU workstation:
git clone --recurse-submodules https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T
curl -LsSf https://astral.sh/uv/install.sh | sh
sudo apt-get update && sudo apt-get install -y ffmpeg
uv sync --python 3.10
uv run python -c "import gr00t; print('GR00T installed')"
Install GR00T-WholeBodyControl:
git clone https://github.com/NVlabs/GR00T-WholeBodyControl.git
cd GR00T-WholeBodyControl
git lfs pull
python check_environment.py
GR00T-WholeBodyControl splits environments by task:
| Goal | Environment | Command |
|---|---|---|
| MuJoCo simulation | .venv_sim |
bash install_scripts/install_mujoco_sim.sh |
| PICO VR teleop | .venv_teleop |
bash install_scripts/install_pico.sh |
| Data collection | .venv_data_collection |
bash install_scripts/install_data_collection.sh |
| VLA inference | .venv_inference |
bash install_scripts/install_inference.sh |
| SONIC training | Isaac Lab env | pip install -e "gear_sonic/[training]" |
Data collection: teleop to LeRobot dataset
NVIDIA's VLA data collection workflow records demonstrations while SONIC deployment and VR teleoperation run. The camera server runs onboard the robot, typically on a Jetson Orin or another computer connected to OAK cameras. The workstation runs C++ deploy, the PICO teleop streamer, and the data exporter. The camera server sends JPEG frames through ZMQ.
Data flow:
Robot onboard:
OAK ego/wrist cameras
|
v
camera server :5555
Workstation:
C++ deploy publishes robot state :5557
PICO teleop publishes SMPL pose :5556
|
v
run_data_exporter.py
|
v
LeRobot v2.1 dataset: parquet + mp4 + metadata
Install the data collection environment:
bash install_scripts/install_data_collection.sh
Set up the camera server on the robot:
git clone https://github.com/NVlabs/GR00T-WholeBodyControl.git
cd GR00T-WholeBodyControl
bash install_scripts/install_camera_server.sh
sudo systemctl status composed_camera_server.service
Collect data in simulation:
python gear_sonic/scripts/launch_data_collection.py --sim
Collect data on the real robot:
python gear_sonic/scripts/launch_data_collection.py \
--camera-host 192.168.123.164 \
--task-prompt "pick up the cup"
Enable wrist cameras:
python gear_sonic/scripts/launch_data_collection.py \
--camera-host 192.168.123.164 \
--task-prompt "pick up the cup" \
--record-wrist-cameras
Each recorded frame contains the main channels below:
| Feature | Shape | Meaning |
|---|---|---|
observation.state.joint_position |
(N,) |
Joint positions |
observation.state.joint_velocity |
(N,) |
Joint velocities |
observation.state.body_rotation_6d |
(6,) |
Base orientation |
observation.state.projected_gravity |
(3,) |
Gravity in body frame |
observation.images.ego_view |
(480, 640, 3) |
Head camera |
observation.images.left_wrist |
(480, 640, 3) |
Left wrist camera, optional |
observation.images.right_wrist |
(480, 640, 3) |
Right wrist camera, optional |
Beginners should start with simulation or a tiny real dataset. Do not record 1,000 episodes before checking the camera streams. Record 5-10 episodes first, inspect the videos, verify exposure and latency, check prompt consistency, and confirm that episode boundaries are correct.
Training: fine-tune GR00T N1.7 for UNITREE_G1_SONIC
After collecting a LeRobot dataset, fine-tune GR00T in the Isaac-GR00T repository. The whole-body workflow uses the UNITREE_G1_SONIC embodiment tag and a matching modality configuration.
Example command:
CUDA_VISIBLE_DEVICES=0 uv run python \
gr00t/experiment/launch_finetune.py \
--base-model-path nvidia/GR00T-N1.7-3B \
--dataset-path /path/to/lerobot_dataset \
--embodiment-tag UNITREE_G1_SONIC \
--modality-config-path examples/UnitreeG1/sonic_config.py \
--num-gpus 1 \
--output-dir /path/to/output \
--max-steps 20000 \
--save-steps 5000 \
--global-batch-size 32 \
--color-jitter-params brightness 0.3 contrast 0.4 saturation 0.5 hue 0.08 \
--dataloader-num-workers 4
Key parameters:
| Flag | Beginner meaning |
|---|---|
--base-model-path |
Pretrained checkpoint, often a Hugging Face model ID |
--dataset-path |
Your collected LeRobot dataset |
--embodiment-tag |
Must match the robot/action layout |
--modality-config-path |
Python file describing state, action, and video keys |
--max-steps |
20k is a reasonable starting point in the docs |
--global-batch-size |
Total batch size across GPUs |
--color-jitter-params |
Augmentation to reduce overfitting to lighting and color |
Expected output:
/path/to/output/
checkpoint-5000/
checkpoint-10000/
checkpoint-15000/
checkpoint-20000/
config.json
processor_config.json
If you enable W&B, monitor loss, learning rate, gradient norm, and open-loop metrics. For robotics, a decreasing loss does not guarantee task success. You still need open-loop replay on held-out episodes, closed-loop simulation tests, and finally a cautious hardware test with safety limits.
Inference: PolicyServer plus SONIC decoder
NVIDIA splits inference into two layers. A GPU machine runs the Isaac-GR00T PolicyServer. The inference machine or workstation runs a client that reads camera images and robot state, queries the PolicyServer over ZMQ, receives a 78D action, and publishes it to the C++ whole-body controller.
Start the server:
uv run python gr00t/eval/run_gr00t_server.py \
--model-path /path/to/output/checkpoint-20000 \
--embodiment-tag UNITREE_G1_SONIC \
--device cuda:0 \
--port 5550
Run the inference launcher:
python gear_sonic/scripts/launch_inference.py \
--policy-host <gpu_machine_ip> \
--policy-port 5550 \
--camera-host 192.168.123.164 \
--prompt "pick up the soda can and place it in the bin"
Runtime pipeline:
Camera server + robot state
|
v
run_vla_inference.py
|
v
Isaac-GR00T PolicyServer
|
v
78D action for UNITREE_G1_SONIC
|
v
gear_sonic_deploy C++ control loop
|
v
Unitree G1 whole-body motion
Useful tmux launcher controls:
| Key | Action |
|---|---|
k |
Start/stop C++ control loop |
i |
Blend to initial pose and switch to POSE mode |
p |
Pause/resume policy inference |
t <text> |
Change the inference prompt |
c |
Start recording an episode |
s |
Stop recording and mark success |
f |
Stop recording and mark failure/discard |
Be careful with pause/resume behavior. On real humanoids, always use a safe area, emergency stop, speed limits, a human observer, and simulation validation before hardware tests.
Results and practical meaning
The public results show that NVIDIA is trying to solve the robotics data bottleneck. The GR00T-Mimic blueprint generated about 780K synthetic trajectories in 11 hours, equivalent to 6.5K hours of human demonstration data, and NVIDIA reported a 40% GR00T N1 improvement when combining synthetic and real data compared with real data alone. GR00T-Dreams and N1.5 show another direction: world-model-generated trajectories can expand task verbs without manually teleoperating every task.
For whole-body control, GR00T-WholeBodyControl is important because it is operational. It tells you how to collect data, what schema to save, which fine-tuning command to run, which port to use for inference, and what the action space contains. A beginner can study it piece by piece, even though running the full real-robot stack still requires expensive hardware and careful integration.
Quick comparison:
| Technology | Solves | Do not confuse it with |
|---|---|---|
| GR00T N1/N1.7 | VLA reasoning and action generation | A full safety/control stack |
| HOVER | Multi-mode neural whole-body control | A language VLA model |
| SONIC | Latent whole-body motion foundation control | A simple joint-PD controller |
| GR00T-Mimic/Dreams | Synthetic robot data | A replacement for real validation |
| LeRobot format | Dataset standardization | A fix for bad demonstrations |
Beginner checklist
If you want to learn this stack, use this order:
- Run open-loop inference with Isaac-GR00T demo data.
- Understand
modality.json, embodiment tags, and action/state normalization. - Run GR00T-WholeBodyControl in MuJoCo simulation.
- Collect a few simulation episodes with
launch_data_collection.py --sim. - Fine-tune for a short 1-2k step smoke test.
- Run PolicyServer plus
launch_inference.py --sim. - Move to real hardware only after simulation is stable.
The most common mistake is starting with a large model and a real robot immediately. In VLA work, most early failures are data failures: misaligned cameras, inconsistent prompts, bad episode boundaries, action/state lag, wrong normalization, or a mismatched embodiment tag.
References
- GR00T N1 paper on arXiv
- NVIDIA Isaac GR00T N1 technical blog
- GR00T N1.5 project page
- Isaac-GR00T GitHub
- HOVER paper on arXiv
- GR00T-WholeBodyControl GitHub
- Data Collection for VLA docs
- VLA Workflow docs
- VLA Inference docs