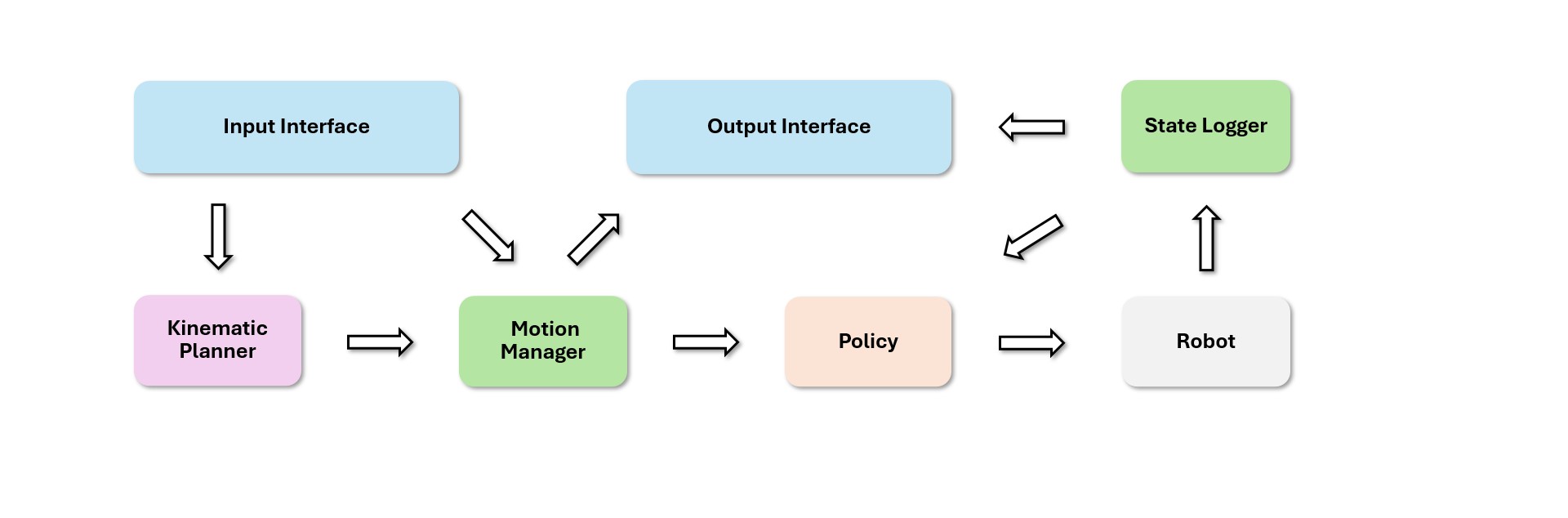
Nếu phải chọn một chủ đề nóng nhất trong VLA cho humanoid whole-body control của NVIDIA ở thời điểm 06/06/2026, mình sẽ chọn combo Isaac GR00T N1.7 + GR00T-WholeBodyControl/SONIC. Đây không chỉ là một model VLA để điều khiển tay robot từ ảnh và câu lệnh. Điểm mới là workflow đã bắt đầu nối được cả chuỗi: dùng teleoperation để lấy demonstration, lưu thành LeRobot dataset, fine-tune GR00T N1.7, rồi chạy inference qua PolicyServer để phát action cho SONIC whole-body controller trên Unitree G1.
Nói ngắn gọn: GR00T là "não VLA" đọc camera + language và sinh action, còn SONIC là "motor foundation model" giúp action đó biến thành chuyển động toàn thân có thăng bằng, chân, tay và bàn tay. Sự kết hợp này là lý do nhiều người gọi đây là bước chuyển từ VLA thao tác tay sang whole-body VLA.
Bài này đi từ nền tảng đến thực hành. Nếu bạn mới với VLA, nên đọc thêm VLA models trong robotics trước. Nếu bạn quan tâm pipeline training robot, bài WholeBodyVLA training pipeline và fine-tune GR00T N1 với Isaac Lab sẽ giúp nối thêm bối cảnh.
Vì sao chủ đề này hot?
Các VLA model đời đầu thường được demo trên arm hoặc bimanual manipulator: nhìn vật, nghe lệnh, sinh trajectory cho end-effector hoặc joint. Với humanoid, vấn đề khó hơn nhiều. Robot không chỉ cần đưa tay tới vật; nó phải giữ thăng bằng, phối hợp chân, thân, cổ, hai tay, bàn tay và đôi khi phải bước, cúi, xoay người hoặc đổi posture giữa chừng.
NVIDIA đang đẩy ba hướng cùng lúc:
| Hướng | Dự án chính | Vai trò |
|---|---|---|
| VLA foundation model | Isaac GR00T N1/N1.5/N1.7 | Hiểu ảnh + ngôn ngữ, sinh action liên tục |
| Synthetic data | GR00T-Mimic, GR00T-Dreams, Cosmos, Isaac Lab | Tăng dữ liệu từ teleop hoặc world model |
| Whole-body controller | HOVER, SONIC, GR00T-WholeBodyControl | Biến command/action thành motion toàn thân ổn định |
GR00T N1 paper giới thiệu model VLA mở cho humanoid với kiến trúc hai hệ thống: System 2 là vision-language module để hiểu scene và instruction; System 1 là diffusion transformer để sinh motor actions. NVIDIA công bố GR00T N1 vượt baseline imitation learning trên benchmark mô phỏng và triển khai được trên Fourier GR-1 cho language-conditioned bimanual manipulation. Blog kỹ thuật của NVIDIA báo cáo GR00T N1 đạt trung bình 76.8% success rate trên real-world tasks với full data, so với 46.4% của Diffusion Policy baseline; với 10% data, GR00T N1 đạt 42.6%, cao hơn baseline 10.2%.
GR00T N1.5 tiếp tục cải thiện bằng FLARE loss, data đa dạng hơn và DreamGen synthetic trajectories. NVIDIA báo cáo N1.5 đạt 38.3% success trên 12 DreamGen tasks mới, trong khi N1 là 13.1%. Khi post-train trên 1K Unitree G1 demonstrations, N1.5 đạt 98.8% với objects đã thấy và 84.2% với novel objects trong setup đặt vật lên đĩa, so với N1 44.0% trên task tương ứng.
Đến GR00T N1.7, repository chính của NVIDIA chuyển trọng tâm sang VLA 3B parameters với VLM backbone mới, relative end-effector action space, human video pretraining 20K giờ EgoScale và hỗ trợ whole-body control qua UNITREE_G1_SONIC. Đây là chi tiết đáng chú ý nhất: VLA không còn chỉ predict arm action trực tiếp, mà có thể predict compact latent action tokens để SONIC decoder biến thành full-body joint commands.
Ý tưởng paper: VLA phải có controller toàn thân bên dưới
Paper GR00T N1 đặt vấn đề: humanoid cần "versatile body" và "intelligent mind". Một foundation model robot phải học từ nhiều nguồn: real robot trajectories, human videos và synthetic datasets. Nhưng chỉ có VLA chưa đủ. Nếu VLA sinh action không tôn trọng dynamics, robot humanoid có thể mất thăng bằng trước khi hoàn thành task.
Đây là nơi HOVER và SONIC xuất hiện.
HOVER, paper ICRA 2025 của NVIDIA, CMU, UC Berkeley, UT Austin và UC San Diego, nhìn whole-body control như bài toán chuyển đổi nhiều command spaces thành một policy chung. Navigation thường cần root velocity tracking. Tabletop manipulation ưu tiên upper-body joint tracking. Motion imitation lại cần theo full-body kinematics. Thay vì train một controller cho từng mode, HOVER dùng full-body kinematic motion imitation làm abstraction chung, rồi distill nhiều control modes vào một policy thống nhất. Điểm beginner cần nhớ: HOVER không phải VLA, nhưng nó giải quyết tầng motor control để humanoid chuyển mode mượt hơn.
SONIC đi xa hơn ở hướng foundation controller. Trong GR00T-WholeBodyControl, NVIDIA mô tả SONIC là humanoid behavior foundation model học core motor skills từ large-scale human motion data. SONIC dùng motion tracking như scalable training task, thay vì viết controller riêng cho từng hành vi như đi, bò, quỳ, chạy hoặc teleop. Repository hiện hỗ trợ GEAR-SONIC, C++ inference stack, teleoperation stack, training code và data collection workflow cho VLA.
Sơ đồ hệ thống nên hiểu như sau:
Language prompt + camera images + robot state
|
v
Isaac GR00T N1.7 VLA
VLM reasoning + DiT action head
|
v
78D UNITREE_G1_SONIC action
64D motion token + 7D left hand + 7D right hand
|
v
SONIC decoder / C++ WBC
|
v
full-body commands: legs, torso, arms, hands
Với cách này, VLA không phải tự học toàn bộ low-level dynamics từ đầu. Nó học chọn latent motion/action phù hợp với task, còn SONIC đảm nhiệm chuyển latent đó thành joint behavior khả thi.
Kiến trúc GR00T N1.7
Theo repository Isaac-GR00T, GR00T N1.7 là open VLA model cho generalized humanoid skills. Model nhận multimodal input gồm language và images, rồi sinh action cho manipulation trong môi trường đa dạng. Kiến trúc gồm:
- Vision-language backbone: trong N1/N1.6 dùng Eagle hoặc Cosmos-family VLM, còn N1.7 chuyển sang Cosmos-Reason2-2B dựa trên Qwen3-VL architecture. Module này mã hóa ảnh camera, text prompt và ngữ cảnh task.
- Diffusion Transformer action head: sinh continuous robot actions bằng denoising. Với robot, action không phải token chữ mà là vector điều khiển theo horizon.
- Embodiment tag: ví dụ
OXE_DROID_RELATIVE_EEF_RELATIVE_JOINT,LIBERO_PANDA,UNITREE_G1_SONIC. Tag này cho model biết state/action layout, normalization và modality config. - GR00T LeRobot format: dataset có
meta/,data/parquet vàvideos/mp4, cộng thêmmeta/modality.jsonđể mô tả cấu trúc state/action/video.
Ví dụ cấu trúc dataset:
my_dataset/
meta/
info.json
episodes.jsonl
tasks.jsonl
modality.json
data/chunk-000/
episode_000000.parquet
videos/chunk-000/
observation.images.ego_view/episode_000000.mp4
observation.images.left_wrist/episode_000000.mp4
observation.images.right_wrist/episode_000000.mp4
Với whole-body workflow trên G1, action space của unitree_g1_sonic là 78 chiều:
| Thành phần | Kích thước | Ý nghĩa |
|---|---|---|
| Motion token | 64 | Latent command cho SONIC whole-body motion |
| Left hand joints | 7 | Điều khiển bàn tay trái |
| Right hand joints | 7 | Điều khiển bàn tay phải |
Điểm này rất quan trọng. Nếu bạn quen train policy cho arm 7-DoF, bạn có thể nghĩ action là joint delta hoặc end-effector delta. Với SONIC, phần lớn action là latent token. Vì thế cần đúng embodiment config, đúng normalization và đúng inference bridge.
Cài đặt môi trường
Bạn cần hai codebase:
NVIDIA/Isaac-GR00T: model, fine-tuning, PolicyServer.NVlabs/GR00T-WholeBodyControl: SONIC, data collection, C++ deploy, inference launcher.
Mức phần cứng phụ thuộc mục tiêu. Inference GR00T N1.7 repo ghi nhận cần GPU 16GB+ VRAM; fine-tuning khuyến nghị 40GB+ VRAM. Với whole-body real robot, bạn còn cần Unitree G1, camera, robot computer, workstation và PICO VR nếu lấy teleop data theo workflow chính thức.
Ví dụ cài Isaac-GR00T trên workstation GPU:
git clone --recurse-submodules https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T
curl -LsSf https://astral.sh/uv/install.sh | sh
sudo apt-get update && sudo apt-get install -y ffmpeg
uv sync --python 3.10
uv run python -c "import gr00t; print('GR00T installed')"
Ví dụ cài GR00T-WholeBodyControl:
git clone https://github.com/NVlabs/GR00T-WholeBodyControl.git
cd GR00T-WholeBodyControl
git lfs pull
python check_environment.py
Các environment trong GR00T-WholeBodyControl được tách theo use case:
| Mục tiêu | Environment | Lệnh |
|---|---|---|
| MuJoCo simulation | .venv_sim |
bash install_scripts/install_mujoco_sim.sh |
| PICO VR teleop | .venv_teleop |
bash install_scripts/install_pico.sh |
| Data collection | .venv_data_collection |
bash install_scripts/install_data_collection.sh |
| VLA inference | .venv_inference |
bash install_scripts/install_inference.sh |
| SONIC training | Isaac Lab env | pip install -e "gear_sonic/[training]" |
Lấy data: teleop thành LeRobot dataset
Workflow data collection của NVIDIA dùng SONIC deployment và VR teleop stack để record demonstrations. Camera server chạy trên robot, thường là Jetson Orin hoặc máy onboard có OAK camera. Workstation chạy C++ deploy, PICO teleop streamer và data exporter. Camera server gửi JPEG frames qua ZMQ.
Sơ đồ data flow:
Robot onboard:
OAK ego/wrist cameras
|
v
camera server :5555
Workstation:
C++ deploy publishes robot state :5557
PICO teleop publishes SMPL pose :5556
|
v
run_data_exporter.py
|
v
LeRobot v2.1 dataset: parquet + mp4 + metadata
Cài data collection:
bash install_scripts/install_data_collection.sh
Setup camera server trên robot:
git clone https://github.com/NVlabs/GR00T-WholeBodyControl.git
cd GR00T-WholeBodyControl
bash install_scripts/install_camera_server.sh
sudo systemctl status composed_camera_server.service
Chạy data collection ở simulation:
python gear_sonic/scripts/launch_data_collection.py --sim
Chạy với robot thật:
python gear_sonic/scripts/launch_data_collection.py \
--camera-host 192.168.123.164 \
--task-prompt "pick up the cup"
Nếu có wrist cameras:
python gear_sonic/scripts/launch_data_collection.py \
--camera-host 192.168.123.164 \
--task-prompt "pick up the cup" \
--record-wrist-cameras
Mỗi frame ghi các kênh chính:
| Feature | Shape | Ý nghĩa |
|---|---|---|
observation.state.joint_position |
(N,) |
Joint positions |
observation.state.joint_velocity |
(N,) |
Joint velocities |
observation.state.body_rotation_6d |
(6,) |
Base orientation |
observation.state.projected_gravity |
(3,) |
Gravity trong body frame |
observation.images.ego_view |
(480, 640, 3) |
Camera đầu |
observation.images.left_wrist |
(480, 640, 3) |
Wrist trái, nếu bật |
observation.images.right_wrist |
(480, 640, 3) |
Wrist phải, nếu bật |
Beginner nên bắt đầu bằng simulation hoặc dataset nhỏ. Đừng vội lấy 1000 episodes nếu camera chưa ổn. Hãy record 5-10 episodes, mở video kiểm tra exposure, latency, prompt, episode boundary và state alignment.
Training: fine-tune GR00T N1.7 cho UNITREE_G1_SONIC
Sau khi có LeRobot dataset, bạn fine-tune GR00T trong repo Isaac-GR00T. Whole-body workflow yêu cầu embodiment tag UNITREE_G1_SONIC và modality config tương ứng.
Ví dụ command:
CUDA_VISIBLE_DEVICES=0 uv run python \
gr00t/experiment/launch_finetune.py \
--base-model-path nvidia/GR00T-N1.7-3B \
--dataset-path /path/to/lerobot_dataset \
--embodiment-tag UNITREE_G1_SONIC \
--modality-config-path examples/UnitreeG1/sonic_config.py \
--num-gpus 1 \
--output-dir /path/to/output \
--max-steps 20000 \
--save-steps 5000 \
--global-batch-size 32 \
--color-jitter-params brightness 0.3 contrast 0.4 saturation 0.5 hue 0.08 \
--dataloader-num-workers 4
Các tham số cần hiểu:
| Flag | Beginner nên hiểu |
|---|---|
--base-model-path |
Checkpoint pretrained, thường là Hugging Face model ID |
--dataset-path |
Dataset LeRobot đã collect |
--embodiment-tag |
Phải khớp robot/action layout |
--modality-config-path |
File Python mô tả state, action, video keys |
--max-steps |
20k là điểm bắt đầu trong doc |
--global-batch-size |
Batch tổng trên mọi GPU |
--color-jitter-params |
Augmentation giúp policy ít overfit màu/ánh sáng |
Output sẽ có các checkpoint:
/path/to/output/
checkpoint-5000/
checkpoint-10000/
checkpoint-15000/
checkpoint-20000/
config.json
processor_config.json
Nếu dùng W&B, theo dõi loss, learning rate, grad norm và validation/open-loop metrics. Với robot thật, loss giảm không đảm bảo task thành công. Bạn cần replay open-loop trên held-out episodes, rồi mới test closed-loop trong sim, sau đó mới đưa lên hardware với safety.
Inference: PolicyServer + SONIC decoder
NVIDIA tách inference thành hai phần. GPU machine chạy Isaac-GR00T PolicyServer. Inference machine hoặc workstation chạy client đọc camera + robot state, gọi PolicyServer qua ZMQ, nhận action 78D và publish cho C++ whole-body controller.
Chạy server:
uv run python gr00t/eval/run_gr00t_server.py \
--model-path /path/to/output/checkpoint-20000 \
--embodiment-tag UNITREE_G1_SONIC \
--device cuda:0 \
--port 5550
Chạy inference launcher:
python gear_sonic/scripts/launch_inference.py \
--policy-host <gpu_machine_ip> \
--policy-port 5550 \
--camera-host 192.168.123.164 \
--prompt "pick up the soda can and place it in the bin"
Pipeline runtime:
Camera server + robot state
|
v
run_vla_inference.py
|
v
Isaac-GR00T PolicyServer
|
v
78D action for UNITREE_G1_SONIC
|
v
gear_sonic_deploy C++ control loop
|
v
Unitree G1 whole-body motion
Trong tmux launcher, các phím quan trọng là:
| Key | Tác dụng |
|---|---|
k |
Start/stop C++ control loop |
i |
Blend về initial pose và chuyển POSE mode |
p |
Pause/resume policy inference |
t <text> |
Đổi prompt khi inference |
c |
Start recording episode |
s |
Stop recording và đánh dấu success |
f |
Stop recording và discard/failure |
Điểm cần cẩn thận là policy inference phải được pause/resume có kiểm soát. Với humanoid thật, luôn có vùng an toàn, E-stop, giới hạn tốc độ, người quan sát và test trong sim trước.
Kết quả và ý nghĩa thực tế
Kết quả công khai cho thấy NVIDIA đang giải quyết data bottleneck. GR00T-Mimic blueprint từng tạo khoảng 780K synthetic trajectories trong 11 giờ, tương đương 6.5K giờ human demonstration, và khi kết hợp synthetic với real data giúp cải thiện GR00T N1 khoảng 40% so với chỉ dùng real data. GR00T-Dreams/N1.5 cho thấy world-model-generated trajectories có thể mở rộng task verbs mà không cần teleop từng task.
Với whole-body, GR00T-WholeBodyControl là bước thực dụng hơn: nó chỉ rõ cần collect data thế nào, lưu ra schema nào, fine-tune command nào, inference qua port nào và action space gồm gì. Đây là thứ beginner có thể học theo từng đoạn, dù để chạy robot thật vẫn cần phần cứng đắt và setup phức tạp.
So sánh nhanh:
| Công nghệ | Giải quyết | Không nên hiểu nhầm |
|---|---|---|
| GR00T N1/N1.7 | VLA reasoning và action generation | Không tự thay thế toàn bộ safety/control stack |
| HOVER | Multi-mode neural whole-body controller | Không phải language VLA |
| SONIC | Latent whole-body motion foundation controller | Cần bridge/action token đúng |
| GR00T-Mimic/Dreams | Synthetic robot data | Không bỏ được real validation |
| LeRobot format | Chuẩn hóa dataset | Không tự sửa data xấu |
Checklist cho người mới
Nếu bạn muốn tự học theo hướng này, đi theo thứ tự sau:
- Chạy open-loop inference với demo dataset của Isaac-GR00T.
- Hiểu
modality.json, embodiment tag và action/state normalization. - Chạy GR00T-WholeBodyControl trong MuJoCo sim.
- Collect vài episode simulation bằng
launch_data_collection.py --sim. - Fine-tune ngắn 1-2k steps để kiểm tra pipeline.
- Chạy PolicyServer +
launch_inference.py --sim. - Chỉ khi sim ổn mới nghĩ tới robot thật.
Sai lầm phổ biến là bắt đầu từ model quá lớn và robot thật. Với VLA, 80% lỗi ban đầu nằm ở data: camera lệch, prompt không nhất quán, episode boundary sai, action/state lag, normalization sai hoặc embodiment tag không khớp.
Nguồn tham khảo
- GR00T N1 paper trên arXiv
- NVIDIA Isaac GR00T N1 technical blog
- GR00T N1.5 project page
- Isaac-GR00T GitHub
- HOVER paper trên arXiv
- GR00T-WholeBodyControl GitHub
- Data Collection for VLA docs
- VLA Workflow docs
- VLA Inference docs