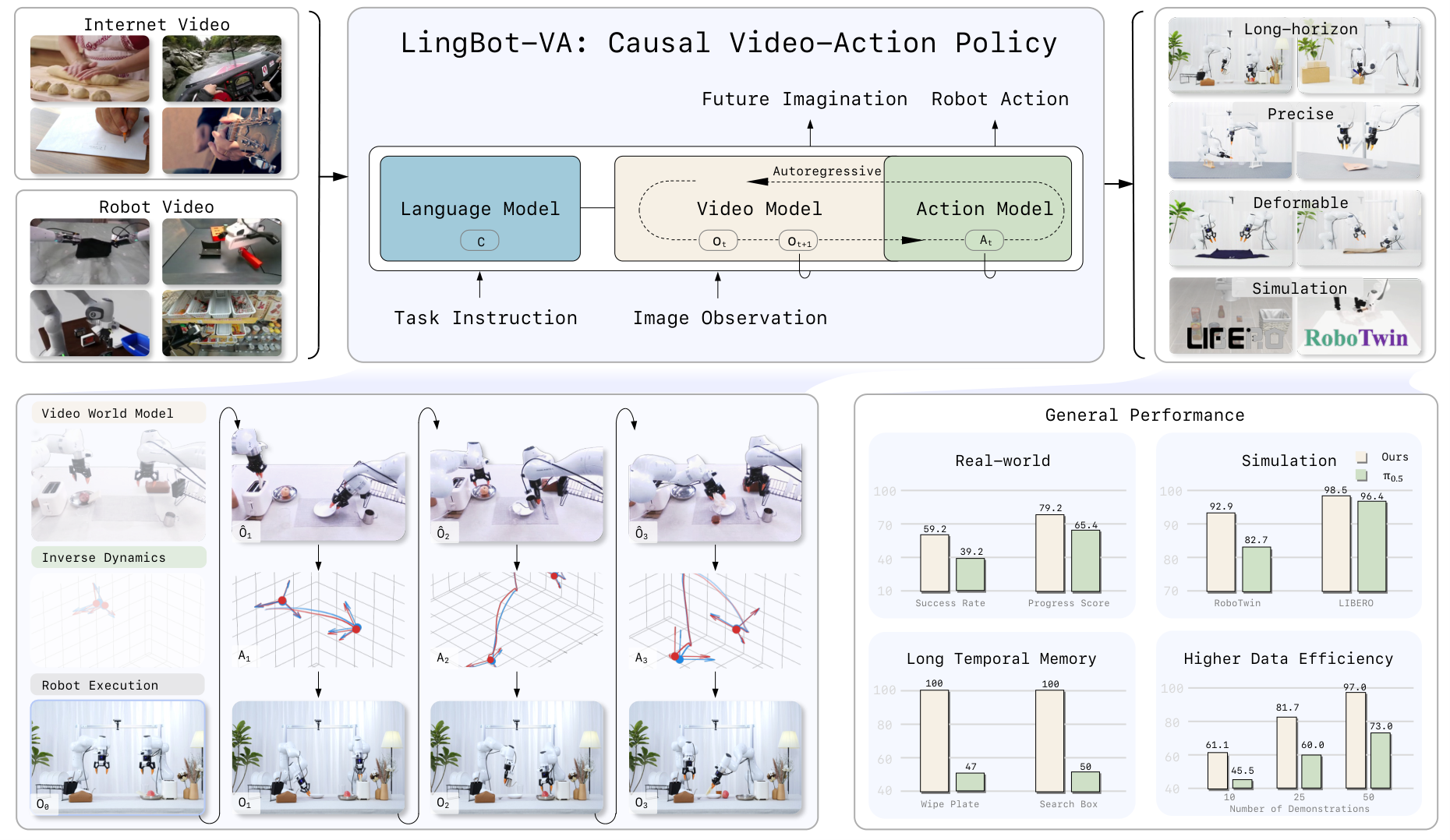
There's a fundamental debate in robot learning: where should robots learn to act from? One camp says from language and images — internet-scale vision-language pretraining. The other says from video of the physical world itself — because the world follows physical laws, and robots need to internalize those laws before they can reliably grasp, fold, or assemble anything.
LingBot-VA (RSS 2026, arXiv:2601.21998) takes the second path — and delivers compelling evidence: 98.5% success rate on LIBERO, 92.9% on RoboTwin 2.0, and decisive wins over π0.5 across all six real-world tasks including breakfast preparation, clothes folding, and precision tube insertion.
GitHub: robbyant/lingbot-va · License: Apache 2.0
Why Video World Models Matter
Most current VLAs (π0, OpenVLA, RoboVLMs) pretrain on vision-language data — abundant on the internet. But the internet contains little video that teaches a robot how to handle deformable materials, feel insertion force, or recover when an object slips.
Video world models take a different approach: instead of learning "language understanding about robots," the model learns to predict what happens next when robot performs action A in state S. This is analogous to learning to drive not from a textbook, but from thousands of hours in the passenger seat watching the road unfold.
LingBot-VA calls this "video world modeling as an independent foundation for robot learning" — not a supplement to VLP, but a parallel and complementary foundation.
MoT Architecture: Dual-Stream Diffusion Transformer
The core of LingBot-VA is a Mixture-of-Transformers (MoT) architecture running two parallel streams:
Pretraining Data (16,000 hours of robot manipulation)
│
▼
┌────────────────────────────────────────┐
│ LingBot-VA Base Model │
│ │
│ ┌─────────────────┐ ┌─────────────┐ │
│ │ Video Stream │ │ Action Stream│ │
│ │ Wan2.2-5B init │ │ 4× smaller │ │
│ │ dv = 3072 │ │ da = 768 │ │
│ │ 30 layers │ │ 30 layers │ │
│ └────────┬────────┘ └──────┬──────┘ │
│ │ Cross-Attention │ │
│ └────────┬──────────┘ │
│ │ │
│ Shared Causal Latent Space │
│ [z_t, a_t,1..τ, z_t+1, a_t+1,1..] │
└────────────────────────────────────────┘
│ │
▼ ▼
Video Prediction Action Prediction
(Flow Matching) (Inverse Dynamics)
│ │
└──────┬───────┘
▼
Asynchronous Inference
(KV Cache + Partial Denoising)
▼
Robot Control
The video stream is initialized from Wan2.2-5B (a large video generation model), with feature dimension dv=3072 and 30 transformer layers. This is the "world understanding" component.
The action stream is 4× smaller (da=768) but shares the same depth. This asymmetric design reflects a key insight: "action distributions are inherently simpler than visual data." High capacity is needed to model the visual world; the policy can be leaner if it can lean on strong visual representations.
The two streams communicate via cross-attention at every layer — video tokens query action tokens and vice versa. Each stream maintains its own feature space (separate QKV projections), referencing rather than merging.
This differs fundamentally from single-stream architectures like π0 or standard DiT: MoT allows each modality to develop specialized representations while still learning cross-modal dependencies.
Shared Latent Space & Causal Attention
Encoding observations as tokens
LingBot-VA uses a causal VAE with 4×16×16 compression: each video frame becomes N=192 spatial tokens in latent space. This is the same technique used by Wan2.2 and modern video diffusion models.
Action vectors are projected into the same token space via a lightweight MLP. The result is an interleaved sequence:
[z_t, a_t,1, a_t,2, ..., a_t,τ, z_t+1, a_t+1,1, ...]
Where τ=4 (four action timesteps per video frame, due to temporal downsampling at rate τ=4).
Causal attention masking
This is the most important theoretical contribution: the model enforces causality through attention masking. Each token can only attend to tokens appearing earlier in the temporal sequence:
- z_t only sees z_{<t} and a_{<t}
- a_{t,k} sees z_{≤t} and a_{t,1..k-1}
This enforces the principle: the present state depends only on the past — mirroring physical causality. There is no "future peeking" as in bidirectional attention.
During training, teacher forcing provides ground-truth tokens as context. But with causal masking, the model cannot exploit shortcuts — it learns genuine forward prediction.
Three Training Objectives
LingBot-VA optimizes three objectives simultaneously:
1. Dynamics Loss (Ld) — Teaching the model to predict future video:
Ld = E[||v_θ(z_{t+1}(s), s, z̃_{≤t}, a_{<t}|c) - ż_{t+1}(s)||²]
The model learns: "Given current state z_t and action a_t, what does the next frame look like?" Flow matching is used instead of DDPM — more stable, fewer denoising steps.
2. Inverse Dynamics Loss (Linv) — Teaching the model to infer actions from video:
Linv = E[||v_ψ(at(s), s, z̃_{≤t+1}, a_{<t}|c) - ȧt(s)||²]
Conditioned on predicted visual transitions, not ground-truth — forcing the model to learn a policy grounded in its own predictions.
3. Forward Dynamics Loss (Lfdm) — Post-training grounding:
Lfdm = E[||v_ψ(z̃_{t+1}, s, z_t, a_t, z̃_{<t}, â_{<t}|c) - ż_{t+1}(s)||²]
The FDM (Forward Dynamics Model) learns to predict the next state from the current state and action, reducing accumulated error during inference.
Total loss: L = Ld + λ·Linv with λ=1.
Noisy History Augmentation
A key training trick: with 50% probability, video history during training is corrupted with noise:
(1 - s_aug)·ε + s_aug·z_{≤t}, s_aug ∈ [0.5, 1]
Effect: at inference, the model can perform partial denoising — starting from s=0.5 instead of s=0, halving the number of denoising steps. This is critical for real-time inference.
Asynchronous Inference Pipeline
This is the engineering challenge that many world model papers skip: how do you run fast enough for real-time robot control?
Video diffusion models are inherently slower than direct policy networks. LingBot-VA solves this with a fully asynchronous pipeline:
Step t: [Execute a_t] ──────────────────────────►
Step t: [Predict a_{t+1}, z_{t+1}] ────────────►
┌── KV Cache ──┐
Step t+1: [Execute a_{t+1}] │ │
Step t+1: [Predict a_{t+2}, z_{t+2}] ◄────────────┘
While the robot executes current actions, the model predicts the next sequence — fully parallel. KV cache reuses attention computation from the previous step.
The Forward Dynamics Model (FDM) provides grounding: rather than pure imagination, FDM "anchors" predictions to real sensor observations. When the robot encounters unexpected situations (object slips, different surface friction), FDM pulls predictions toward reality.
Ablation result: async pipeline achieves the same success rate as synchronous, but 2× faster wall-clock time.
Pretraining Dataset: 16,000 Hours
The base model is pretrained on 16,000 hours of robot manipulation data from six sources:
| Source | Description |
|---|---|
| Agibot | Diverse mobile manipulator tasks |
| RoboMind | Multi-embodiment demonstrations |
| InternData-A1 | Large-scale simulation dataset |
| OXE (subset) | OpenVLA cross-embodiment data |
| UMI Data | Human demonstrations (in-the-wild) |
| RoboCOIN | Bimanual cross-embodiment data |
This is among the largest open-source pretraining datasets for robot manipulation. For comparison: π0 uses ~60,000 hours but mostly proprietary; OpenVLA uses OXE with ~970K episodes.
Installation & Setup
System requirements
- Python 3.10.16
- PyTorch 2.9.0
- CUDA 12.6
- VRAM: ~24GB (RoboTwin eval), ~18GB (image-to-video-action)
Install dependencies
# Core dependencies
pip install torch==2.9.0 torchvision==0.24.0 torchaudio==2.9.0 \
--index-url https://download.pytorch.org/whl/cu126
pip install websockets einops diffusers==0.36.0 transformers==4.55.2 \
accelerate msgpack opencv-python matplotlib ftfy easydict
# Flash attention (required for performance)
pip install flash-attn --no-build-isolation
# For post-training
pip install lerobot==0.3.3 scipy wandb --no-deps
Critical config: attn_mode
The most common mistake: forgetting to switch attn_mode in transformer/config.json between training and inference:
// Training:
{ "attn_mode": "flex" }
// Inference:
{ "attn_mode": "torch" } // or "flashattn" if flash-attn is installed
Using the wrong mode will cause either errors or significantly slower inference.
Download checkpoints
# Via HuggingFace CLI
huggingface-cli download robbyant/lingbot-va-base --local-dir ./checkpoints/base
huggingface-cli download robbyant/lingbot-va-posttrain-robotwin --local-dir ./checkpoints/robotwin
huggingface-cli download robbyant/lingbot-va-posttrain-libero-long --local-dir ./checkpoints/libero
Also available on ModelScope if HuggingFace bandwidth is limited in your region.
Post-Training on Task Data
Post-training on RoboTwin or LIBERO requires surprisingly few demonstrations:
# RoboTwin post-training (8 GPUs)
NGPU=8 CONFIG_NAME='robotwin_train' bash script/run_va_posttrain.sh
# LIBERO post-training (8 GPUs)
NGPU=8 CONFIG_NAME='libero_train' bash script/run_va_posttrain.sh
Default hyperparameters:
- Learning rate: 1×10⁻⁵ (conservative — pretrained weights are strong)
- Steps: 3,000
- Minimum demos: 50 episodes
Sample efficiency ablation: with only 10 demos, LingBot-VA outperforms π0.5 trained on the same data by 15.6% on task progress — the pretrained world model representation transfers extremely well.
Running Inference & Evaluation
RoboTwin evaluation
# Start server (GPU: video + action prediction)
bash evaluation/robotwin/launch_server.sh
# Start client (sim interface)
bash evaluation/robotwin/launch_client.sh ${save_root} ${task_name}
LIBERO evaluation
bash evaluation/libero/launch_server.sh
bash evaluation/libero/launch_client.sh
Image-to-video-action generation
# Generate from a single initial frame (no sim needed)
NGPU=1 CONFIG_NAME='robotwin_i2av' bash script/run_launch_va_server_sync.sh
This mode is useful for quick testing: provide a single observation image → the model generates both a predicted video trajectory and the corresponding action sequence.
Benchmark Results
LIBERO benchmarks
| Task Suite | Success Rate | Std |
|---|---|---|
| LIBERO-Spatial | 98.5% | ±0.3 |
| LIBERO-Object | 99.6% | ±0.3 |
| LIBERO-Goal | 97.2% | ±0.2 |
| LIBERO-Long | 98.5% | ±0.5 |
State-of-the-art across all four suites. LIBERO-Long is the hardest (requires long-horizon planning and context retention) — 98.5% is a strong result.
RoboTwin 2.0 (average over 50 tasks)
| Metric | LingBot-VA | Motus | π0.5 |
|---|---|---|---|
| Easy SR | 92.9% | 88.7% | 82.7% |
| Hard SR | 91.6% | 87.0% | — |
+4.2% margin (Easy) and +4.6% (Hard) over Motus. Versus π0.5: +10.2% on Easy tasks.
Real-world: 6 tasks (50 trials each)
| Category | Tasks | Key Advantage |
|---|---|---|
| Long-horizon | Make Breakfast, Pick Screws | +20% vs π0.5 |
| Precision | Insert Tube, Unpack Delivery | Superior fine-grained control |
| Deformable | Fold Clothes, Fold Pants | More physically plausible |
"Make Breakfast" is the hardest task — requiring 10+ steps, multi-object manipulation, and multi-step planning. This is where world models shine brightest: the model can "imagine" the entire action sequence before committing.
Ablation Analysis
The research team conducted several informative ablations:
1. Pretrained base vs. no pretraining:
- With pretrained LingBot-VA base: 92.10% (Easy) on RoboTwin
- With Wan2.2 (generic video model, no robot fine-tuning): 80.6%
- Conclusion: robot-specific pretraining provides a ~12% absolute lift
2. Action stream initialization strategy:
- Scaled interpolation from video stream weights → smooth convergence
- Random initialization → "volatile training dynamics, significantly slower convergence"
- Lesson: initializing the action stream from video weights is critical
3. Async vs. sync inference:
- Success rate: equivalent
- Wall-clock time: async is 2× faster
- Lesson: pipelining does not hurt quality, only increases throughput
4. Forward Dynamics Model (FDM):
- Without FDM: predictions drift from reality after a few steps
- With FDM: predictions track observations, accumulated error is suppressed
Comparison With Related Work
If you've read about the RISE World Model or Weaver's π0.5 integration, LingBot-VA differs in several key ways:
| Dimension | LingBot-VA | RISE | Weaver |
|---|---|---|---|
| Architecture | MoT dual-stream | Single DDPM | Diffusion + MAMBA |
| Video stream init | Wan2.2-5B | From scratch | Partial |
| Action decoding | Inverse dynamics | Direct | Flow matching |
| Async inference | ✅ KV cache | ❌ | Partial |
| License | Apache 2.0 | Varies | Research |
GigaBrain-0 explores a complementary angle — using the world model to generate synthetic rollouts for RL reward learning. LingBot-VA focuses on strong supervised pretraining with fast post-training adaptation.
Known Limitations
No paper is without caveats. Key considerations for deploying LingBot-VA:
- High VRAM: 24GB for RoboTwin eval. RTX 3090 (24GB) is borderline; anything lower won't work.
- PyTorch 2.9.0: Very recent — potential incompatibilities with other libraries. Recommend an isolated conda environment.
- Manual
attn_modeswitch: Not automatic — easy to forget when switching between training and inference runs. - Real-world setup specifics: The paper uses a specific robot arm and wrist camera configuration. Transferring to different hardware requires re-calibration.
- Pretraining data access: Some sources (Agibot, RoboMind) may have access restrictions. Verify licenses before commercial use.
Conclusion
LingBot-VA answers the question "can video world models replace vision-language pretraining?" with strong empirical evidence: yes, and on several benchmarks they do it better.
Three core takeaways:
- MoT architecture: two separate streams that communicate — each modality retains its own identity while learning cross-modal dependencies
- Causal latent space: physical causality enforced through attention masking, not bidirectional shortcuts
- Async + KV cache: turns a theoretically "slow" world model into a real-time capable controller
With Apache 2.0 licensing and public checkpoints, LingBot-VA is among the most practically useful open-source world models for robot manipulation today. If you're building a manipulation system with sufficient GPU resources (≥24GB VRAM), this is a strong starting point — powerful pretraining, fast post-training, and real-world validated results.