Có một câu hỏi nền tảng trong robotics mà cộng đồng vẫn đang tranh luận: robot nên học hành động từ đâu? Một trường phái nói: học từ ngôn ngữ và hình ảnh (vision-language pretraining). Trường phái kia nói: học từ video của thế giới thật — vì thế giới tuân theo quy luật vật lý, và robot cần hiểu quy luật đó trước khi biết cầm nắm thứ gì.
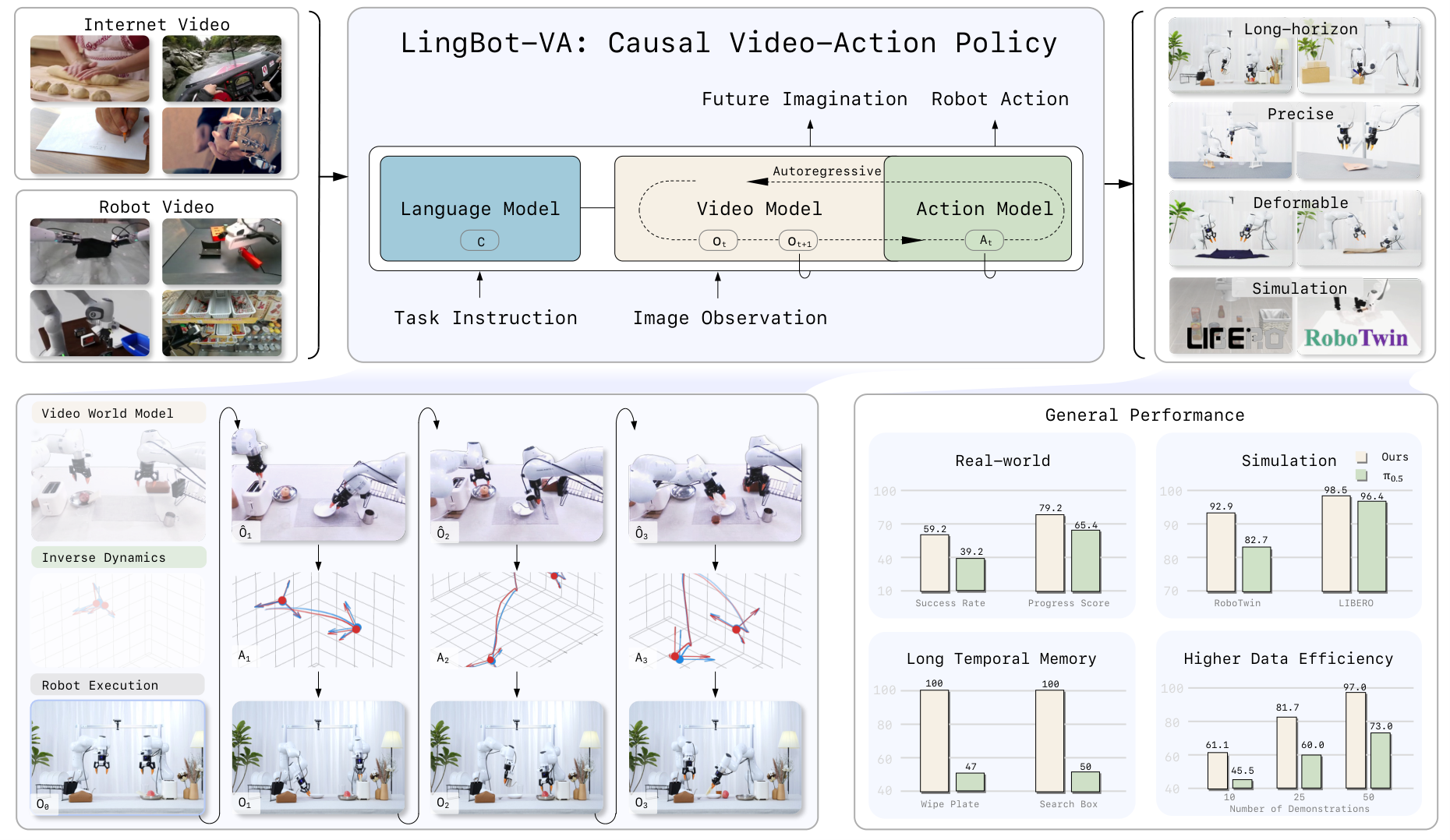
LingBot-VA (RSS 2026, arXiv:2601.21998) chọn con đường thứ hai — và kết quả rất thuyết phục: 98.5% success rate trên LIBERO, 92.9% trên RoboTwin 2.0, và quan trọng hơn là vượt π0.5 trên tất cả 6 tác vụ thực tế bao gồm nấu ăn, gấp quần áo, và lắp ống chính xác cao.
GitHub: robbyant/lingbot-va · License: Apache 2.0
Tại sao video world model lại quan trọng?
Hầu hết các VLA hiện tại (π0, OpenVLA, RoboVLMs) đều pretraining từ vision-language data — thứ mà internet có rất nhiều. Nhưng internet không có video dạy robot cách ứng xử với vật liệu mềm, cách cảm nhận lực khi lắp ráp chính xác, hay cách phục hồi khi vật thể trượt khỏi tay.
Video world model tiếp cận khác: thay vì học "hiểu ngôn ngữ về robot", model học dự đoán những gì xảy ra tiếp theo khi robot thực hiện hành động A trong tình huống S. Giống như bạn học lái xe không phải bằng cách đọc sách lý thuyết, mà bằng cách ngồi ghế phụ và quan sát hàng nghìn giờ.
LingBot-VA gọi đây là "video world modeling như một nền tảng độc lập cho robot learning" — không phải phụ trợ cho VLP, mà là thay thế và bổ sung cùng lúc.
Kiến trúc MoT: Dual-Stream Diffusion Transformer
Trái tim của LingBot-VA là kiến trúc Mixture-of-Transformers (MoT) với hai stream song song:
Pretraining Data (16,000 giờ robot manipulation)
│
▼
┌────────────────────────────────────────┐
│ LingBot-VA Base Model │
│ │
│ ┌─────────────────┐ ┌─────────────┐ │
│ │ Video Stream │ │ Action Stream│ │
│ │ Wan2.2-5B init │ │ 4× nhỏ hơn │ │
│ │ dv = 3072 │ │ da = 768 │ │
│ │ 30 layers │ │ 30 layers │ │
│ └────────┬────────┘ └──────┬──────┘ │
│ │ Cross-Attention │ │
│ └────────┬──────────┘ │
│ │ │
│ Shared Causal Latent Space │
│ [z_t, a_t,1..τ, z_t+1, a_t+1,1..] │
└────────────────────────────────────────┘
│ │
▼ ▼
Video Prediction Action Prediction
(Flow Matching) (Inverse Dynamics)
│ │
└──────┬───────┘
▼
Asynchronous Inference
(KV Cache + Partial Denoising)
▼
Robot Control
Video stream được khởi tạo từ Wan2.2-5B (một video generation model lớn), với chiều không gian dv=3072 và 30 transformer layers. Đây là "bộ não" hiểu thế giới thị giác.
Action stream nhỏ hơn 4 lần (da=768) nhưng có cùng số layer. Lý do thiết kế bất đối xứng này: "phân phối action đơn giản hơn inherently so với dữ liệu thị giác". Không cần capacity lớn để học policy nếu đã có video stream mạnh làm anchor.
Hai stream giao tiếp qua cross-attention tại mỗi layer — video tokens query action tokens và ngược lại. Nhưng mỗi stream giữ không gian riêng (separate QKV projections), không trộn lẫn mà chỉ "tham khảo" nhau.
Đây cũng là điểm khác với kiến trúc single-stream như π0 hay DiT thuần túy: MoT cho phép mỗi modality phát triển representation riêng trong khi vẫn học được sự phụ thuộc lẫn nhau.
Shared Latent Space & Causal Attention
Mã hóa video thành tokens
LingBot-VA dùng causal VAE với tỷ lệ nén 4×16×16: mỗi frame video được nén thành N=192 spatial tokens trong không gian latent. Đây là cùng kỹ thuật với Wan2.2 và các video diffusion model hiện đại.
Các action vector được chiếu vào cùng không gian token thông qua một MLP nhỏ. Kết quả là chuỗi interleaved:
[z_t, a_t,1, a_t,2, ..., a_t,τ, z_t+1, a_t+1,1, ...]
Trong đó τ=4 (4 action timesteps cho mỗi video frame, do video bị downsample theo thời gian).
Causal attention masking
Đây là điểm quan trọng nhất về mặt lý thuyết: model enforce nhân quả qua attention mask. Mỗi token chỉ có thể attend đến các token xuất hiện trước nó trong chuỗi thời gian. Tức là:
- z_t chỉ thấy z_{<t} và a_{<t}
- a_{t,k} thấy z_{≤t} và a_{t,1..k-1}
Điều này đảm bảo nguyên tắc: trạng thái hiện tại chỉ phụ thuộc vào quá khứ, giống như quy luật nhân quả vật lý. Không có "nhìn trộm tương lai" như bidirectional attention.
Trong quá trình training, teacher forcing cung cấp ground-truth tokens làm context — nhưng với causal mask, model không học cách "cheat", chỉ học cách predict forward.
Ba hàm Loss: Dạy Model Hiểu Thế Giới
LingBot-VA optimize 3 objectives đồng thời:
1. Dynamics Loss (Ld) — Dạy model predict video tương lai:
Ld = E[||v_θ(z_{t+1}(s), s, z̃_{≤t}, a_{<t}|c) - ż_{t+1}(s)||²]
Model học: "Nếu robot đang ở trạng thái z_t và thực hiện action a_t, frame tiếp theo trông như thế nào?" Dùng flow matching thay vì DDPM — ổn định hơn, ít bước denoising hơn.
2. Inverse Dynamics Loss (Linv) — Dạy model suy ra action từ video:
Linv = E[||v_ψ(at(s), s, z̃_{≤t+1}, a_{<t}|c) - ȧt(s)||²]
Condition trên predicted visual transitions, không phải ground-truth — buộc model phải học policy dựa vào predictions của chính nó.
3. Forward Dynamics Loss (Lfdm) — Post-training để grounding:
Lfdm = E[||v_ψ(z̃_{t+1}, s, z_t, a_t, z̃_{<t}, â_{<t}|c) - ż_{t+1}(s)||²]
Đây là FDM (Forward Dynamics Model) — học predict trạng thái tiếp theo từ trạng thái và action hiện tại, giúp khử lỗi tích lũy khi inference.
Tổng loss: L = Ld + λ·Linv với λ=1.
Noisy History Augmentation
Một trick training thú vị: với xác suất 50%, video history trong quá trình training bị thêm noise theo công thức:
(1 - s_aug)·ε + s_aug·z_{≤t}, với s_aug ∈ [0.5, 1]
Kết quả: tại inference, model có thể làm "partial denoising" — bắt đầu từ s=0.5 thay vì s=0, giảm một nửa số bước denoising. Đây là điểm quan trọng cho tốc độ inference thực tế.
Asynchronous Inference Pipeline
Đây là điểm kỹ thuật mà nhiều paper world model bỏ qua: làm thế nào để chạy trong real-time?
Video diffusion model chậm hơn nhiều so với policy network thuần túy. LingBot-VA giải quyết bằng pipeline bất đồng bộ:
Bước t: [Execute a_t] ──────────────────────────►
Bước t: [Predict a_{t+1}, z_{t+1}] ────────────►
┌── KV Cache ──┐
Bước t+1: [Execute a_{t+1}] │ │
Bước t+1: [Predict a_{t+2}, z_{t+2}] ◄────────────┘
Trong khi robot đang thực hiện actions của bước hiện tại, model dự đoán actions cho bước tiếp theo — song song hoàn toàn. KV cache tái sử dụng computation từ bước trước.
Forward Dynamics Model (FDM) đóng vai trò grounding: thay vì dùng pure imagination, FDM "căn chỉnh" predictions với observation thực từ sensor. Khi robot gặp tình huống bất ngờ (vật thể trượt, bề mặt khác), FDM hút predictions về phía thực tế.
Kết quả ablation: async pipeline cho throughput tương đương với sync nhưng nhanh gấp 2 lần wall-clock.
Dataset Pretraining: 16,000 Giờ Robot Data
Pretrained model được train trên 16,000 giờ robot manipulation data từ 6 nguồn:
| Nguồn | Mô tả |
|---|---|
| Agibot | Diverse mobile manipulator tasks |
| RoboMind | Multi-embodiment demonstrations |
| InternData-A1 | Large-scale simulation dataset |
| OXE (subset) | OpenVLA cross-embodiment data |
| UMI Data | Human demonstrations (cup in the wild) |
| RoboCOIN | Bimanual cross-embodiment data |
Đây là một trong những pretraining dataset lớn nhất trong cộng đồng open-source robot manipulation. So sánh: π0 dùng ~60,000 giờ nhưng đa số proprietary; OpenVLA dùng OXE ~970K episodes.
Cài Đặt & Chạy
Yêu cầu hệ thống
- Python 3.10.16
- PyTorch 2.9.0
- CUDA 12.6
- VRAM: ~24GB (RoboTwin eval), ~18GB (image-to-video-action)
Cài đặt dependencies
# Core dependencies
pip install torch==2.9.0 torchvision==0.24.0 torchaudio==2.9.0 \
--index-url https://download.pytorch.org/whl/cu126
pip install websockets einops diffusers==0.36.0 transformers==4.55.2 \
accelerate msgpack opencv-python matplotlib ftfy easydict
# Flash attention (cần thiết cho performance)
pip install flash-attn --no-build-isolation
# Cho post-training
pip install lerobot==0.3.3 scipy wandb --no-deps
Cấu hình quan trọng: attn_mode
Đây là điểm dễ nhầm nhất. Trong file transformer/config.json, phải đổi attn_mode tùy theo mode:
// Khi training:
{ "attn_mode": "flex" }
// Khi inference:
{ "attn_mode": "torch" } // hoặc "flashattn" nếu có flash-attn
Dùng sai mode sẽ gây lỗi hoặc chậm hơn nhiều so với cần thiết.
Download checkpoints
# HuggingFace
huggingface-cli download robbyant/lingbot-va-base --local-dir ./checkpoints/base
huggingface-cli download robbyant/lingbot-va-posttrain-robotwin --local-dir ./checkpoints/robotwin
huggingface-cli download robbyant/lingbot-va-posttrain-libero-long --local-dir ./checkpoints/libero
Cũng có sẵn trên ModelScope nếu HuggingFace chậm từ Việt Nam.
Post-Training: Fine-tune với Task Data
Post-training trên RoboTwin hoặc LIBERO chỉ cần số lượng demo nhỏ:
# RoboTwin post-training (8 GPUs)
NGPU=8 CONFIG_NAME='robotwin_train' bash script/run_va_posttrain.sh
# LIBERO post-training (8 GPUs)
NGPU=8 CONFIG_NAME='libero_train' bash script/run_va_posttrain.sh
Hyperparameters mặc định:
- Learning rate: 1×10⁻⁵ (nhỏ — pretrained weights mạnh, không cần đập mạnh)
- Steps: 3,000
- Demo số lượng tối thiểu: 50 episodes
Kết quả ablation: với chỉ 10 demos, LingBot-VA vượt π0.5 trained với cùng lượng data 15.6% về task progress — thể hiện sample efficiency vượt trội của pretraining.
Inference & Evaluation
RoboTwin evaluation
# Khởi động server (GPU, sinh video + action predictions)
bash evaluation/robotwin/launch_server.sh
# Khởi động client (giao tiếp với robot sim)
bash evaluation/robotwin/launch_client.sh ${save_root} ${task_name}
LIBERO evaluation
bash evaluation/libero/launch_server.sh
bash evaluation/libero/launch_client.sh
Image-to-video-action generation
# Generate từ single initial frame (không cần sim)
NGPU=1 CONFIG_NAME='robotwin_i2av' bash script/run_launch_va_server_sync.sh
Mode này hữu ích khi test nhanh: đưa 1 ảnh môi trường → model generate cả video lẫn action sequence.
Kết Quả Benchmark
LIBERO benchmarks
| Task Suite | Success Rate | Std |
|---|---|---|
| LIBERO-Spatial | 98.5% | ±0.3 |
| LIBERO-Object | 99.6% | ±0.3 |
| LIBERO-Goal | 97.2% | ±0.2 |
| LIBERO-Long | 98.5% | ±0.5 |
State-of-the-art trên cả 4 suites. LIBERO-Long là thách thức nhất (long-horizon, cần nhớ context dài) — 98.5% là kết quả ấn tượng.
RoboTwin 2.0 (50 tasks, trung bình)
| Metric | LingBot-VA | Motus | π0.5 |
|---|---|---|---|
| Easy SR | 92.9% | 88.7% | 82.7% |
| Hard SR | 91.6% | 87.0% | - |
Margin +4.2% (Easy) và +4.6% (Hard) so với Motus. So với π0.5: +10.2% trên Easy.
Real-world: 6 tác vụ (50 trials mỗi tác vụ)
| Nhóm | Tác vụ | Điểm nổi bật |
|---|---|---|
| Long-horizon | Make Breakfast, Pick Screws | +20% vs π0.5 |
| Precision | Insert Tube, Unpack Delivery | Fine-grained control tốt hơn |
| Deformable | Fold Clothes, Fold Pants | Physically plausible hơn |
"Make Breakfast" là tác vụ khó nhất — đòi hỏi >10 bước, multi-object, multi-step planning. Đây là nơi world model tỏa sáng nhất vì nó "hình dung" được chuỗi hành động trước khi execute.
Phân Tích Ablation
Nhóm nghiên cứu thực hiện một số ablation studies quan trọng:
1. Pretrained vs không pretrained:
- Với pretrained LingBot-VA base: 92.10% (Easy) trên RoboTwin
- Với WAN (video model gốc, không fine-tune): 80.6%
- Chứng minh: robot-specific pretraining quan trọng, không chỉ dùng generic video model
2. Action stream initialization:
- Scale interpolation từ video weights → convergence mượt mà
- Random initialization → "training không ổn định, converge chậm hơn đáng kể"
- Lesson: khởi tạo action stream từ video weights là critical, không thể random
3. Async vs Sync inference:
- Success rate: tương đương
- Wall-clock time: async nhanh gấp 2×
- Lesson: pipeline song song không làm hỏng chất lượng, chỉ tăng throughput
4. Forward Dynamics Model (FDM):
- Không có FDM: predictions drift xa thực tế sau vài bước
- Có FDM: predictions bám sát observations, ít accumulated error hơn
So Sánh Với Các Phương Pháp Khác
Nếu bạn đã đọc về RISE World Model hay Weaver kết hợp π0.5, điểm khác biệt của LingBot-VA là:
| Điểm | LingBot-VA | RISE | Weaver |
|---|---|---|---|
| Architecture | MoT dual-stream | Single DDPM | Diffusion + MAMBA |
| Video stream | Wan2.2-5B init | From scratch | Partial video |
| Action decode | Inverse dynamics | Direct | Flow matching |
| Async inference | ✅ KV cache | ❌ | Partial |
| License | Apache 2.0 | Varies | Research |
GigaBrain-0 tiếp cận bổ sung qua RL — dùng world model để tạo synthetic rollouts cho reward learning. LingBot-VA tập trung supervised pretraining + fast post-training.
Điểm Yếu Cần Lưu Ý
Không có paper nào hoàn hảo. Một vài điểm cần chú ý khi deploy LingBot-VA:
- VRAM cao: 24GB để eval RoboTwin. Không phù hợp với consumer GPU như RTX 3090 (24GB border-line) hay thấp hơn.
- PyTorch 2.9.0: Version rất mới — có thể có incompatibility với số libraries khác. Nên dùng conda env riêng.
attn_modemanual switch: Không tự động — dễ quên khi chuyển giữa training và inference.- Real-world setup: Paper dùng setup cụ thể (wrist camera, specific robot arm). Transfer sang hardware khác cần re-calibration.
- 16,000 giờ pretraining data: Một số dataset (Agibot, RoboMind) có thể có access restrictions — verify license trước khi dùng commercial.
Kết Luận
LingBot-VA trả lời câu hỏi "video world model có thể thay thế vision-language pretraining không?" bằng một kết quả mạnh: có thể, và trên nhiều benchmark còn tốt hơn.
Ba điểm cốt lõi để nhớ:
- MoT architecture: hai stream riêng biệt nhưng giao tiếp — mỗi modality giữ được identity của mình
- Causal latent space: enforce nhân quả vật lý, không bidirectional
- Async + KV cache: biến world model "chậm về lý thuyết" thành real-time capable
Với license Apache 2.0 và checkpoints công khai, đây là một trong những open-source world model cho robot manipulation đáng dùng nhất hiện tại. Nếu bạn đang build manipulation system và có GPU đủ mạnh (≥24GB VRAM), LingBot-VA là điểm khởi đầu tốt — pretraining mạnh, post-training nhanh, và kết quả thực tế đã validate.