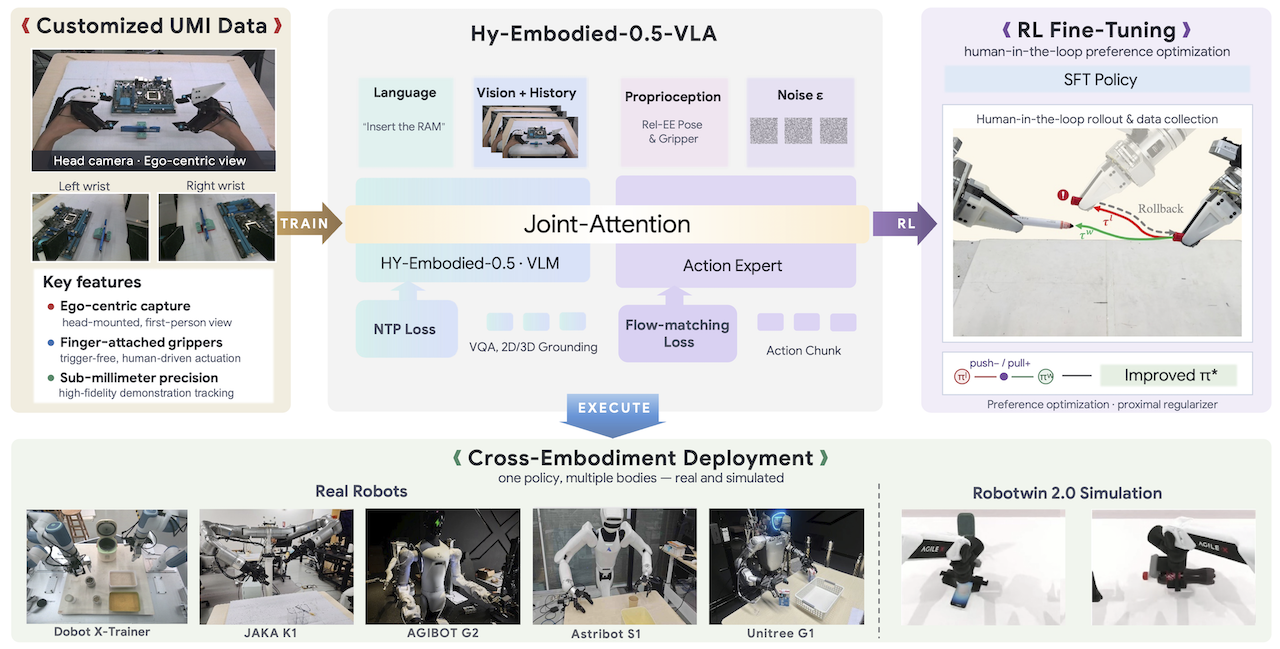
Hy-Embodied-0.5-VLA, shortened to Hy-VLA, is more than a new checkpoint for Vision-Language-Action robot control. Tencent released a nearly complete real-world robot learning stack: code, model checkpoints, a public bimanual UMI dataset, training scripts, RoboTwin 2.0 evaluation adapters, data visualization tools, and deployment recipes for cross-embodiment manipulation. That makes it useful not only as a paper to read, but also as a practical baseline for teams building dual-arm robot policies.
This guide explains what the paper is trying to solve, how the model is structured, how to install the repo, how to run the first inference smoke test, how to inspect the UMI dataset, and how to think about fine-tuning and deployment. If you are new to VLA, read our VLA models introduction and LeRobot ecosystem guide first. This article still keeps the workflow explicit enough for a beginner who has access to a CUDA machine.
Why Hy-Embodied-0.5-VLA matters
Most robot VLA systems face three practical bottlenecks. First, real robot demonstrations are expensive. Second, action spaces are often tied tightly to one robot's kinematics. Third, inference must be fast and smooth enough to control hardware, not just pass an offline benchmark. These problems become harder for bimanual manipulation because the policy must coordinate two end-effectors, multiple camera streams, gripper state, and contact-rich object interactions.
Hy-VLA attacks the problem with scale and representation. The team uses a Universal Manipulation Interface, or UMI, to collect high-fidelity demonstrations from human manipulation rather than requiring every trajectory to be teleoperated directly on the final robot. The public Hugging Face dataset contains 250,304 episodes, 233.6 million frames, 2,163 hours of demonstrations, and about 18.8 TB of data split into 22 Lance tables. The released dataset is roughly one fifth of the full corpus; the paper and repo describe more than 10,000 hours used for pre-training.
The core idea is that a bimanual policy can learn a reusable manipulation prior if its action interface is expressed relative to the current end-effector frame. Instead of predicting joint targets for a specific arm, Hy-VLA predicts future end-effector delta chunks. A platform-specific mapper then converts those chunks into commands for a Dobot X-Trainer, JAKA K1, Astribot S1, humanoid upper body, or another robot. This separation is what makes the cross-embodiment story credible.
The architecture in plain language
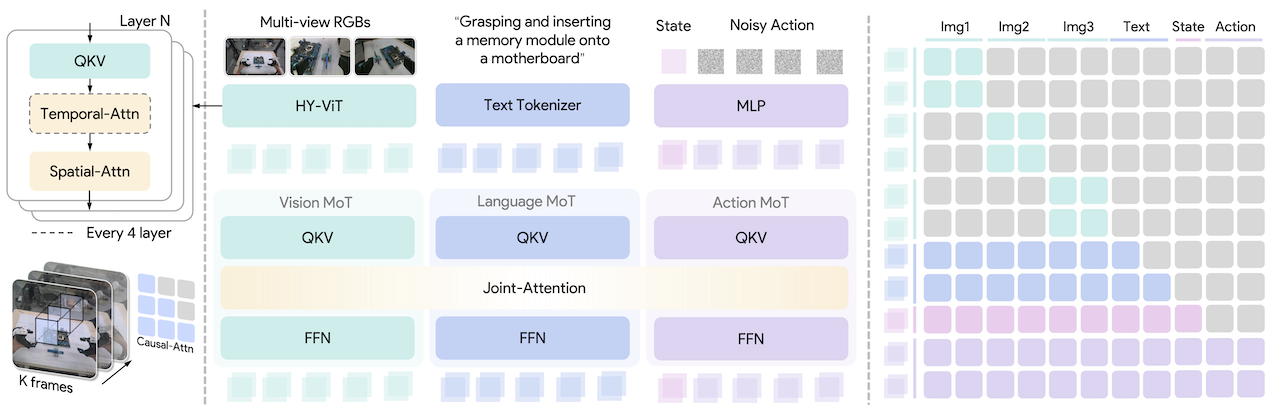
Hy-VLA has three main parts.
The first part is the Hy-Embodied-0.5 MoT backbone. MoT stands for Mixture-of-Transformers. The model does not force visual tokens and text tokens through exactly the same parameters. Visual tokens use vision-specialized computation, text tokens keep language-specialized computation, and cross-modal interaction happens through shared self-attention. This matters because manipulation needs fine spatial perception, not only generic image captioning or instruction following.
The second part is a dual-tower flow-matching action expert. Some VLA models discretize robot actions into tokens and decode them like text. Hy-VLA does not. It adds a dedicated continuous action expert, around 370M parameters according to the repo, and trains it with conditional flow matching. The VLM tower grounds the observation and language instruction; the action tower generates a continuous action chunk by integrating a learned velocity field. At inference time, the released implementation uses a small number of Euler steps and caches observation prefixes.
The third part is a compact memory encoder. A robot should not decide from a single frozen image. When folding glasses, inserting a bottle, pulling a zipper, or cleaning a table, the policy needs short-term temporal context. Hy-VLA interleaves temporal and spatial attention inside the ViT encoder so a K-frame multi-view history can be compressed into the current-frame representation. Past-frame tokens are discarded after temporal mixing, so the VLM token count stays stable instead of growing linearly with history length.
The final design choice is the delta-chunk action representation. The policy predicts an action chunk relative to the end-effector pose at the start of that chunk. Per arm, the action includes 3D translation, 6D rotation, and gripper opening. For two arms, this becomes a bimanual action interface. This is easier to transfer than direct joint commands because the learned policy is less entangled with one robot's exact morphology.
What is inside the public UMI dataset?

The public dataset is tencent/Hy-Embodied-0.5-VLA-Data on Hugging Face. It uses Lance format and follows a LeRobot v3.0-compatible schema. Each table, from table_000 to table_021, is an independent dataset root. Because the full public release is close to 19 TB, you should not download all of it just to test the code. Start with one table or a small subset.
Each frame contains three RGB camera views: a high/head camera, a left wrist camera, and a right wrist camera. The image resolution is 240 x 424 at 30 Hz. The state vector has 16 dimensions: each arm contributes position, quaternion, and gripper information. Metadata includes task index, task text, episode index, frame index, and timestamp. Some original task strings are Chinese, so teams fine-tuning in English or Vietnamese should normalize instruction text instead of mixing several naming styles for the same task.
Lance is a good fit for this release because it supports columnar access, sharding, and random reads better than one giant monolithic file. If you have used smaller imitation-learning datasets before, the main difference is operational: storage, caching, visualization, and sanity checks become part of the training pipeline. The dataset is too large to treat as a folder of casual videos.
Hardware and environment checklist
Use Linux, an NVIDIA GPU, and CUDA 12.x. The README recommends Python 3.12, PyTorch 2.4 or newer, and at least 16 GB of VRAM for basic experimentation. The current pyproject.toml routes PyTorch to a CUDA 12.8 wheel and includes dependencies for training and data loading: accelerate, deepspeed, hydra-core, wandb, pylance, lancedb, pyarrow, opencv-python-headless, and flash-attn.
For a first pass, use this rough sizing:
| Goal | Suggested GPU | Notes |
|---|---|---|
| Quick inference smoke test | 1 GPU, 16-24 GB | Use the released RoboTwin checkpoint |
| Dataset inspection | CPU plus fast SSD | Avoid downloading the full dataset |
| Small fine-tune | 1-4 GPUs, 24-48 GB | Tune batch size and gradient accumulation |
| Full pre-training | Multi-node cluster | The public recipe mentions 64 GPUs |
Disk is the hidden requirement. A single table can be hundreds of gigabytes. Set HF_HOME or local_dir to a large SSD before calling snapshot_download, otherwise your home partition may fill up silently.
Install the repository
Create a clean environment and install with uv:
git clone https://github.com/Tencent-Hunyuan/Hy-Embodied-0.5-VLA
cd Hy-Embodied-0.5-VLA
curl -LsSf https://astral.sh/uv/install.sh | sh
uv sync
If you prefer pip, use a virtual environment:
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
In practice, uv sync is the safer route because the project config pins special sources for PyTorch and FlashAttention. Before blaming the model, confirm CUDA works:
nvidia-smi
python - <<'PY'
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0) if torch.cuda.is_available() else "no cuda")
PY
If CUDA is unavailable, fix your driver, Docker runtime, or PyTorch wheel first. Hy-VLA debugging will be misleading until this basic check passes.
Run the first inference smoke test
The repo includes scripts/quick_start.py. It downloads tencent/Hy-Embodied-0.5-VLA-RoboTwin, loads HyVLAConfig, initializes the policy, enables the video encoder if needed, moves the model to CUDA with bfloat16, and feeds a synthetic batch with three camera streams plus a dual-arm state vector.
Run:
python scripts/quick_start.py
For a minimal manual test, the batch structure looks like this:
import torch
from huggingface_hub import snapshot_download
from hy_vla import HyVLA, HyVLAConfig
ckpt = snapshot_download("tencent/Hy-Embodied-0.5-VLA-RoboTwin")
config = HyVLAConfig.from_pretrained(ckpt)
policy = HyVLA.from_pretrained(ckpt, config=config)
policy.enable_video_encoder_if_needed()
policy = policy.to(device="cuda", dtype=torch.bfloat16).eval()
img = torch.zeros(1, 6, 3, 224, 224, device="cuda", dtype=torch.bfloat16)
state = torch.zeros((1, config.max_state_dim), device="cuda", dtype=torch.bfloat16)
batch = {
"observation.images.top_head": img,
"observation.images.hand_left": img,
"observation.images.hand_right": img,
"observation.state": state,
"task": ["pick up the bottle"],
}
with torch.no_grad():
pred = policy.forward_evaluate(batch)["pred"]
print(pred.shape)
This does not prove the robot can manipulate an object. It proves the environment, checkpoint, model class, CUDA path, and forward pass are working. Once this passes, later failures are usually related to data schema, normalization, camera mapping, or robot adapter code.
Inspect the UMI data
Do not download the entire dataset at first. Use allow_patterns to fetch a specific table:
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="tencent/Hy-Embodied-0.5-VLA-Data",
repo_type="dataset",
allow_patterns="table_000/**",
local_dir="./hy_vla_data",
)
Then read it with the provided Lance reader:
from hy_vla.data.lance_dataset import LanceTableReader
reader = LanceTableReader(root="./hy_vla_data/table_000")
frame = reader[42]
episode = reader.get_episode(3)
print(frame.keys())
print(len(episode))
print(frame["task"])
The reader can also target the Hugging Face Hub:
reader = LanceTableReader(
repo_id="tencent/Hy-Embodied-0.5-VLA-Data",
table_name="table_000",
)
To render an episode:
python scripts/vis_umi_episode.py -t table_000 -e 666
When inspecting data, check four things before training. First, verify camera order; swapping left and right wrist views can destroy a bimanual policy. Second, inspect timestamps and dropped frames. Third, confirm state and action normalization. Released checkpoints include norm_stats.pkl, but custom data requires new statistics. Fourth, normalize task instructions. A model can tolerate visual variation better than inconsistent labels for the same behavior.
Training workflow
Hy-VLA separates training into stages.
Stage 1 is UMI pre-training. The VLM tower starts from tencent/HY-Embodied-0.5, while the action expert starts randomly. The full recipe uses the 10K-hour UMI corpus, a flow-matching objective, history length K=1, action horizon H=50 at 10 Hz, 200K steps, and global batch size 1,024. Most small labs should not try to reproduce this from scratch. Use the released Hy-VLA-UMI checkpoint as the base model.
For a single-table iteration:
export TABLE_NAME=table_001
bash scripts/train_table_vlm.sh
For full pre-training, the repo provides a distributed launcher:
export CHIEF_IP=<chief-ip>
export INDEX=0
bash scripts/train_umi_vlm.sh
Stage 2 is supervised fine-tuning. Starting from the UMI checkpoint, SFT activates the compact memory encoder with K=6 frames and fine-tunes on task-specific demonstrations. For RoboTwin 2.0:
export CHIEF_IP=<chief-ip>
export INDEX=0
bash scripts/train_robotwin_umi.sh
For your own robot, your main task is not writing a new loss. It is matching the policy contract: multi-view images, dual-arm end-effector state, delta-chunk actions, clean task instructions, and correct normalization statistics. Before any long run, build a visualization script that samples random episodes and overlays image, state, action, and task text. Bad data is the most common reason robot policies fail.
Stage 3 is FlowPRO post-training. The paper describes FlowPRO as reward-free preference optimization for continuous action chunks. The workflow is to let the policy run on hardware, intervene when it fails, roll back, and convert the correction into preferred versus dispreferred action chunks. The RPRO loss then improves the policy while a proximal regularizer keeps it close to the base model. At release time, the repo marks FlowPRO code as under review or coming later, so treat this as a method to track rather than a stable API.
Evaluation results
On RoboTwin 2.0, Hy-VLA reports 90.9% success in the clean setting and 90.1% in the randomized setting, averaged over 50 tasks with 100 rollouts per task. The repo compares it against π0, ABot-M0, π0.5, Qwen-VLA, LingBot-VLA, starVLA, Motus, and JoyAI-RA. Hy-VLA is the top entry in both columns, and the small clean-to-randomized gap suggests the model is not merely memorizing fixed visual scenes.
| Method | Clean | Randomized |
|---|---|---|
| π0 | 65.9 | 58.4 |
| π0.5 | 82.7 | 76.8 |
| Qwen-VLA | 86.1 | 87.2 |
| JoyAI-RA | 90.5 | 89.3 |
| Hy-VLA | 90.9 | 90.1 |
The real-world X-Trainer results are also important. Hy-VLA reaches 83% on Set the Table, 94% on Fold & Store Glasses, 73% on Zip Up the Pen Case, and 94% on Insert Bottles. The ablation without UMI pre-training falls behind strongly on precision-heavy tasks such as folding glasses and zipper manipulation. This supports the paper's central argument: large-scale UMI data gives the policy a useful prior for contact-rich bimanual control.
The cross-embodiment track is the most interesting for deployment teams. With UMI-only fine-tuning and no target-robot teleoperation, Hy-VLA reaches 90% on JAKA K1 Organize Accessory and 89% on Astribot S1 Clean Up Table. The no-UMI ablation drops to 38% and 44%. This gap is a strong signal that the representation and data source matter, not only the backbone.
FlowPRO results push the system further. After three post-training rounds on four X-Trainer tasks, the RPRO variant reports 99% success on Bottle, 99% on Cap, 98% on USB, and 94% on Zip, with shorter completion times than DAgger in the same table. These numbers are promising, but you should interpret them as results in the authors' hardware and intervention pipeline. Reproducing them requires safe rollback, consistent failure labeling, and enough clean preference pairs.
What deployment still requires
Hy-VLA does not output low-level joint commands. It outputs end-effector delta chunks. You need a platform mapper that converts those chunks into target poses or joint trajectories for your robot. For an industrial dual-arm cell, this usually means IK, collision checking, workspace limits, gripper scaling, and velocity limits. For a humanoid, the mapper may need a whole-body controller to maintain balance, avoid self-collision, and respect reachability.
Runtime latency also matters. The paper describes asynchronous inference and execution: while the robot executes one chunk, the model predicts the next chunk. If the new prediction arrives late, stale prefixes are removed and a cubic Bezier smoother stitches the old and new chunks. Without this layer, a policy that looks good offline can still produce jerky or delayed motion on hardware.
Use this deployment checklist:
- Calibrate camera intrinsics and extrinsics.
- Verify left/right camera and arm conventions.
- Convert robot state into the expected dual-arm EEF format.
- Use the correct normalization statistics for the checkpoint or fine-tuned data.
- Add safety limits for workspace, velocity, gripper force, and emergency stop.
- Log observation, prediction, command, and failure events.
- Start with slow dry-runs before autonomous execution.
If you are working on humanoid whole-body VLA, compare this mapper problem with our LeRobot G1 π0-FAST whole-body guide. The same VLA output can become very different once it has to pass through a real controller.
Common failure modes
Checkpoint download fails. Check Hugging Face connectivity, rate limits, cache location, and disk space. Set HF_HOME to a large SSD if needed.
CUDA is not detected. Fix the NVIDIA driver, container runtime, or PyTorch wheel before debugging Hy-VLA. A working nvidia-smi is not always enough; verify torch.cuda.is_available().
Quick start runs out of memory. Use bfloat16, reduce batch size, close other GPU processes, and confirm the model is not loaded twice. A 16 GB GPU is a lower bound, not a comfortable training machine.
Lance data reads too slowly. Put data on local NVMe storage and avoid slow network filesystems. For debugging, fetch one table or a small subset instead of the whole dataset.
The robot moves in the wrong direction. Suspect coordinate frames, left/right swap, gripper scale, or action denormalization. Plot and replay actions before sending them to hardware.
Fine-tuning does not converge. Check instruction consistency, camera mapping, action horizon, learning rate, normalization statistics, and demonstration quality. Ten clean episodes can be more useful than fifty noisy ones.
When should you use Hy-VLA?
Hy-VLA is a strong fit if you need bimanual manipulation, multi-view perception, a public large-scale UMI dataset, RoboTwin 2.0 evaluation, or cross-embodiment transfer. It is also useful if you want to start from a UMI-pretrained checkpoint rather than building a VLA from scratch.
It may be overkill if your task is a fixed single-arm pick-and-place cell. In that case, ACT, Diffusion Policy, or a smaller LeRobot pipeline can be easier to debug and cheaper to train. Hy-VLA becomes compelling when the task needs coordinated dual-arm behavior, visual variation, contact-rich precision, or transfer to a different robot.
References
- Paper: Hy-Embodied-0.5-VLA: From Vision-Language-Action Models to a Real-World Robot Learning Stack
- Code: Tencent-Hunyuan/Hy-Embodied-0.5-VLA
- Dataset: tencent/Hy-Embodied-0.5-VLA-Data
- Project page: Tairos Hy-Embodied-0.5-VLA


