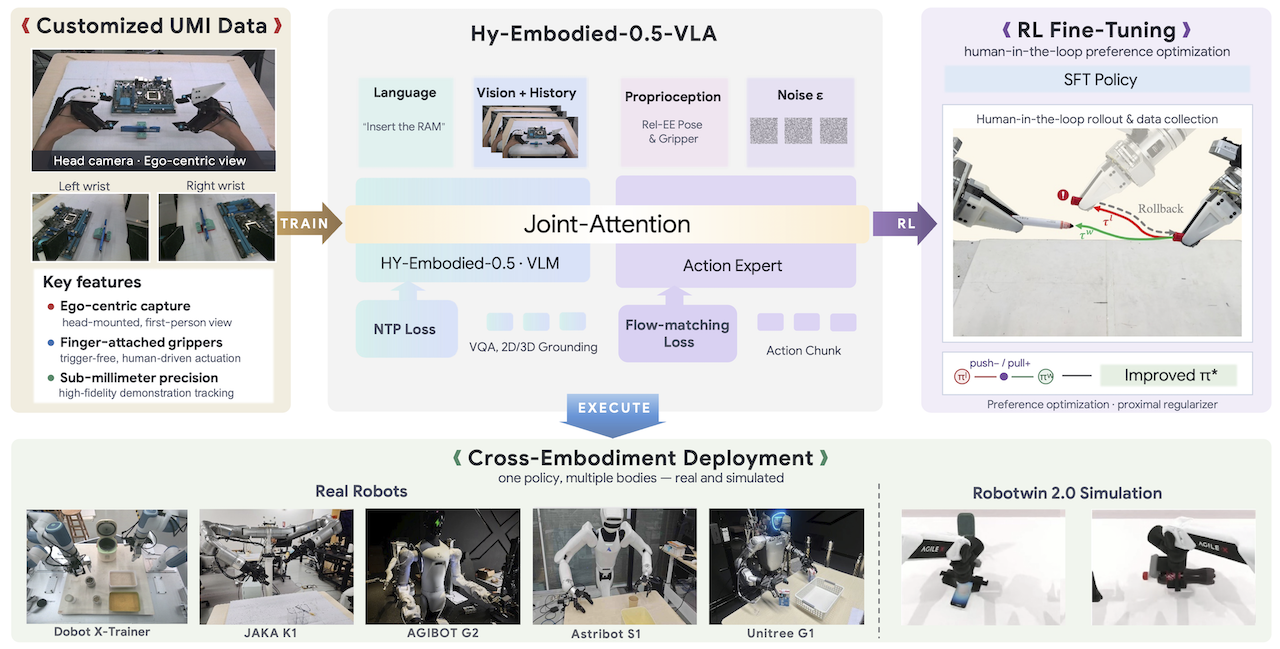
Hy-Embodied-0.5-VLA, hay Hy-VLA, là một trong những release đáng chú ý nhất cho nhóm Vision-Language-Action (VLA) thao tác song thủ trong tháng 6/2026. Điểm hấp dẫn không chỉ nằm ở mô hình, mà ở việc Tencent công bố gần như toàn bộ một stack robot learning: thiết bị thu thập dữ liệu kiểu UMI, dataset song thủ hơn 2.000 giờ được mở ra công khai, checkpoint trên Hugging Face, code training/inference, adapter đánh giá RoboTwin 2.0 và recipe triển khai thật.
Bài này đi theo hướng thực hành. Mục tiêu là giúp bạn hiểu paper đang làm gì, cài repo, chạy smoke test, đọc thử dữ liệu UMI, fine-tune trên RoboTwin hoặc dữ liệu riêng, rồi diễn giải kết quả để biết khi nào nên dùng Hy-VLA thay vì các VLA như π0, π0.5, Qwen-VLA hay các pipeline LeRobot nhỏ hơn. Nếu bạn mới bước vào VLA, nên đọc thêm tổng quan VLA models và hệ sinh thái LeRobot trước, nhưng bài này vẫn cố gắng giữ từng bước đủ cụ thể để beginner có thể follow.
Hy-Embodied-0.5-VLA giải quyết vấn đề gì?
VLA robot thường bị kẹt ở ba điểm: dữ liệu thật ít, action representation quá phụ thuộc vào robot cụ thể, và inference không đủ mượt cho điều khiển thật. Với một robot song thủ, vấn đề còn nặng hơn vì policy phải phối hợp hai end-effector, hai gripper, nhiều camera và trạng thái robot trong thời gian thực. Nếu chỉ học từ vài trăm episode trong lab, policy có thể hoạt động tốt trên một setup nhưng dễ vỡ khi đổi camera, đổi tay máy, đổi workspace hoặc đổi embodiment.
Hy-VLA chọn một hướng khá rõ: dùng dữ liệu Universal Manipulation Interface (UMI) quy mô lớn để học prior thao tác song thủ, sau đó fine-tune hoặc post-train cho robot mục tiêu. Thay vì bắt người vận hành teleop trực tiếp từng robot, team dùng thiết bị UMI dạng fingertip, có optical motion capture, để ghi lại chuyển động thao tác ở góc nhìn egocentric. Dataset public trên Hugging Face gồm 250.304 episode, 233,6 triệu frame, tổng 2.163 giờ, khoảng 18,8 TB chia thành 22 table Lance. Đây mới là khoảng 20% corpus đầy đủ; paper/repo nói corpus nội bộ dùng để pre-train là hơn 10.000 giờ.
Ý tưởng quan trọng là: nếu action được biểu diễn tương đối theo end-effector hiện tại, dữ liệu thao tác của con người qua UMI có thể trở thành supervision robot-agnostic hơn. Khi deploy sang Dobot X-Trainer, JAKA K1, Astribot S1 hoặc humanoid, phần mapping từ delta end-effector sang joint command nằm ngoài policy lõi. Nhờ vậy policy không cần học lại toàn bộ kinematics của từng nền tảng.
Kiến trúc ở mức dễ hiểu
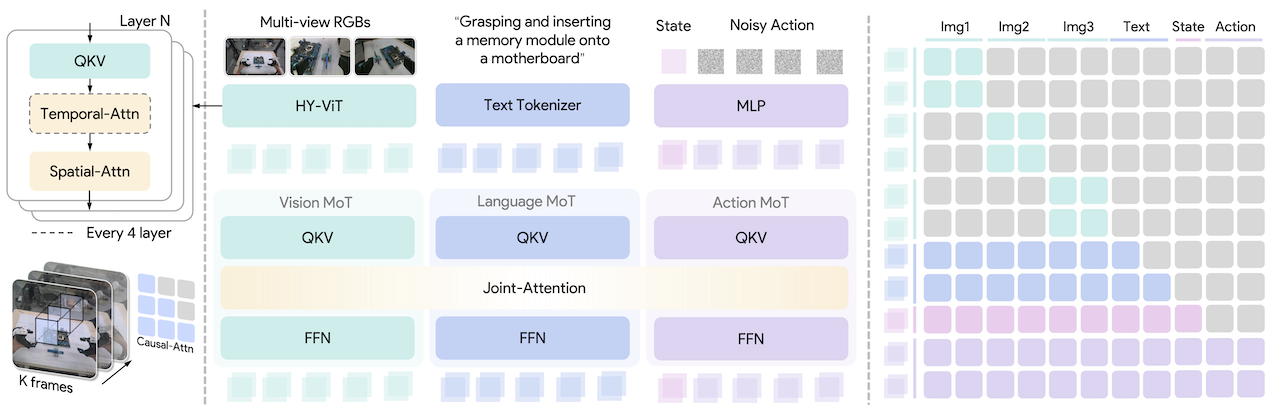
Hy-VLA có ba khối chính.
Thứ nhất là Hy-Embodied-0.5 MoT backbone. MoT là Mixture-of-Transformers: visual token và text token không dùng cùng một bộ tham số hoàn toàn giống nhau. Visual token đi qua nhánh tham số phù hợp với thị giác, text token giữ nhánh ngôn ngữ, còn interaction đa phương thức diễn ra qua self-attention chung. Điều này khác với nhiều VLA dựa trên VLM phổ thông vì backbone đã được tối ưu cho embodied reasoning, spatial understanding và quan sát robot.
Thứ hai là dual-tower flow-matching action expert. Nhiều VLA tokenize action thành chuỗi token rồi autoregressive decode như text. Hy-VLA không đi theo hướng đó. Nó thêm một action expert khoảng 370M tham số để sinh action liên tục bằng conditional flow matching. VLM tower xử lý ảnh, ngôn ngữ và ngữ cảnh; action tower học velocity field để biến noise/action ban đầu thành action chunk hợp lệ. Khi inference, mô hình tích phân qua vài bước Euler để lấy action chunk, thay vì chọn token rời rạc.
Thứ ba là compact memory encoder. Robot không nên quyết định chỉ từ một frame. Ví dụ khi kéo khóa bút, fold kính hoặc đặt chai vào khay, policy cần biết gripper vừa đi từ đâu tới, vật đang trượt hay đã kẹt. Hy-VLA dùng temporal-spatial attention trong ViT encoder để nén lịch sử K frame nhiều camera vào token của frame hiện tại. Điểm thực dụng là token budget của VLM không tăng theo số frame lịch sử, vì past-frame token bị bỏ sau khi đã trộn temporal context.
Ngoài ba khối trên, paper nhấn mạnh delta-chunk action representation. Action được dự đoán là chunk tương lai tương đối so với pose end-effector tại thời điểm bắt đầu chunk. Mỗi tay có translation 3D, rotation 6D và gripper command; hai tay thành action song thủ. Cách biểu diễn này làm không gian tối ưu nhỏ hơn so với joint command trực tiếp, đồng thời giúp policy ít phụ thuộc hơn vào robot cụ thể.
Dataset UMI 2.000 giờ public gồm những gì?

Dataset public tencent/Hy-Embodied-0.5-VLA-Data được phát hành theo format Lance tương thích LeRobot v3.0. Mỗi table là một dataset root độc lập, ví dụ table_000, table_001, tới table_021. Với quy mô gần 19 TB, bạn không nên tải toàn bộ nếu chỉ muốn thử pipeline. Hãy bắt đầu từ một table hoặc một episode.
Schema quan sát gồm ba camera RGB: cam_high cho góc nhìn đầu/overhead, cam_left_wrist cho wrist camera trái và cam_right_wrist cho wrist camera phải. Độ phân giải mỗi ảnh là 240 x 424, tần số 30 Hz. State có 16 chiều: mỗi tay gồm position, quaternion và gripper. Metadata có task text, task index, episode index, frame index và timestamp. Nhiều task text gốc là tiếng Trung, nên khi fine-tune cho lab Việt Nam bạn cần chú ý mapping task instruction sang tiếng Anh hoặc tiếng Việt nhất quán.
Về mặt thực hành, Lance phù hợp cho dữ liệu lớn vì hỗ trợ đọc cột, shard và random access tốt hơn việc nhét mọi thứ vào một file HDF5 khổng lồ. Nếu bạn đã quen với fine-tune VLA song thủ, điểm mới ở đây là data scale lớn hơn rất nhiều, có multi-view wrist/head và có schema LeRobot v3.0 tương đối rõ.
Chuẩn bị máy
Bạn nên dùng Linux, NVIDIA GPU và CUDA 12.x. Repo khuyến nghị Python 3.12, PyTorch từ 2.4 trở lên, nhưng pyproject.toml hiện route torch tới wheel CUDA 12.8 và pin các dependency training như accelerate, deepspeed, hydra-core, wandb, pylance, lancedb, pyarrow, opencv-python-headless, flash-attn. Với inference smoke test, GPU 16 GB VRAM có thể đủ. Với fine-tune thật, đặc biệt multi-view và K=6 history, bạn nên chuẩn bị nhiều GPU hơn hoặc giảm batch size.
Một cấu hình hợp lý để thử:
| Mục tiêu | GPU gợi ý | Ghi chú |
|---|---|---|
| Chạy quick start | 1 GPU 16-24 GB | Dùng checkpoint RoboTwin, batch nhỏ |
| Đọc/visualize dataset | CPU + SSD lớn | Không cần tải toàn bộ 18,8 TB |
| Fine-tune task nhỏ | 1-4 GPU 24-48 GB | Cần chỉnh batch, gradient accumulation |
| Pre-train full corpus | Cụm nhiều GPU | Recipe repo nhắc tới 64 GPU |
Nếu bạn đang ở môi trường cloud, hãy đảm bảo disk đủ lớn. Một table khoảng hàng trăm GB tới gần 1 TB; tải nhầm toàn bộ dataset sẽ tốn thời gian và chi phí rất nhanh.
Cài đặt repo
Bắt đầu bằng một môi trường sạch:
git clone https://github.com/Tencent-Hunyuan/Hy-Embodied-0.5-VLA
cd Hy-Embodied-0.5-VLA
curl -LsSf https://astral.sh/uv/install.sh | sh
uv sync
Nếu không dùng uv, bạn có thể cài qua pip:
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Trong thực tế, uv sync đáng tin hơn vì repo đã cấu hình nguồn wheel cho PyTorch CUDA và FlashAttention. Nếu bạn cài trong container tối giản, lỗi hay gặp là thiếu driver NVIDIA host, CUDA runtime không khớp, hoặc flash-attn rơi về build từ source. Hãy kiểm tra trước:
nvidia-smi
python - <<'PY'
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0) if torch.cuda.is_available() else "no cuda")
PY
Nếu torch.cuda.is_available() trả False, đừng debug Hy-VLA vội. Hãy sửa driver/container trước.
Chạy inference smoke test
Repo có script scripts/quick_start.py. Script này tải checkpoint tencent/Hy-Embodied-0.5-VLA-RoboTwin, load HyVLAConfig, tạo policy, bật video encoder nếu cần, đưa model lên CUDA với bfloat16, rồi feed batch giả gồm ba camera và state song thủ.
Chạy:
python scripts/quick_start.py
Nếu muốn tự viết test ngắn, cấu trúc batch cần giống các key mà policy kỳ vọng:
import torch
from huggingface_hub import snapshot_download
from hy_vla import HyVLA, HyVLAConfig
ckpt = snapshot_download("tencent/Hy-Embodied-0.5-VLA-RoboTwin")
config = HyVLAConfig.from_pretrained(ckpt)
policy = HyVLA.from_pretrained(ckpt, config=config)
policy.enable_video_encoder_if_needed()
policy = policy.to(device="cuda", dtype=torch.bfloat16).eval()
img = torch.zeros(1, 6, 3, 224, 224, device="cuda", dtype=torch.bfloat16)
state = torch.zeros((1, config.max_state_dim), device="cuda", dtype=torch.bfloat16)
batch = {
"observation.images.top_head": img,
"observation.images.hand_left": img,
"observation.images.hand_right": img,
"observation.state": state,
"task": ["pick up the bottle"],
}
with torch.no_grad():
pred = policy.forward_evaluate(batch)["pred"]
print(pred.shape)
Với beginner, mục tiêu của bước này không phải là robot chạy được ngay. Bạn chỉ cần xác nhận ba điều: checkpoint tải được, dependency đúng, model forward được trên GPU. Khi bước này pass, lỗi sau đó thường nằm ở dataset, normalization, camera mapping hoặc adapter robot.
Đọc thử dữ liệu UMI bằng Lance
Vì dataset rất lớn, nên dùng snapshot_download với allow_patterns để tải một table cụ thể:
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="tencent/Hy-Embodied-0.5-VLA-Data",
repo_type="dataset",
allow_patterns="table_000/**",
local_dir="./hy_vla_data",
)
Sau đó đọc bằng LanceTableReader:
from hy_vla.data.lance_dataset import LanceTableReader
reader = LanceTableReader(root="./hy_vla_data/table_000")
frame = reader[42]
episode = reader.get_episode(3)
print(frame.keys())
print(len(episode))
print(frame["task"])
Nếu không muốn tải local, reader cũng hỗ trợ HF Hub:
reader = LanceTableReader(
repo_id="tencent/Hy-Embodied-0.5-VLA-Data",
table_name="table_000",
)
Để render một episode thành video kiểm tra dữ liệu:
python scripts/vis_umi_episode.py -t table_000 -e 666
Khi kiểm tra dữ liệu, hãy nhìn bốn thứ. Một là camera có đúng thứ tự không; wrist trái/phải bị đảo sẽ làm policy học sai. Hai là timestamp có đều không; drop frame nhiều gây nhiễu cho action chunk. Ba là state có được normalize đúng không; checkpoint release đã kèm norm_stats.pkl, còn dữ liệu riêng thì phải compute lại. Bốn là instruction có nhất quán không; cùng một task mà mô tả lúc tiếng Trung, lúc tiếng Anh, lúc viết tắt sẽ làm fine-tune khó hội tụ hơn.
Training: từ pre-training tới fine-tune
Hy-VLA tách recipe thành nhiều giai đoạn.
Stage 1: pre-training trên UMI. VLM tower khởi tạo từ tencent/HY-Embodied-0.5, action expert khởi tạo ngẫu nhiên. Training dùng flow-matching objective, history length K=1, action horizon H=50 ở 10 Hz, global batch size 1.024 và 200K step trong recipe đầy đủ. Đây không phải bước beginner nên tự chạy trên laptop. Nếu bạn không có cụm GPU, hãy dùng checkpoint Hy-VLA-UMI làm starting point.
export TABLE_NAME=table_001
bash scripts/train_table_vlm.sh
Lệnh trên hữu ích để kiểm tra một table nhỏ hoặc debug dataloader. Pre-training đầy đủ dùng launcher riêng:
export CHIEF_IP=<chief-ip>
export INDEX=0
bash scripts/train_umi_vlm.sh
Stage 2: supervised fine-tuning. Từ checkpoint UMI, bật compact memory encoder với K=6 frame và fine-tune trên demonstration task cụ thể. Với RoboTwin 2.0, repo cung cấp script:
export CHIEF_IP=<chief-ip>
export INDEX=0
bash scripts/train_robotwin_umi.sh
Nếu bạn có dữ liệu robot riêng, việc quan trọng nhất là đưa data về cùng contract: ba camera hoặc mapping camera tương đương, state dual-arm EEF, action delta-chunk, task instruction, normalization stats. Đừng nhảy thẳng vào training khi chưa viết được một script visualize 20 episode ngẫu nhiên. Trong robot learning, dữ liệu sai thường tốn nhiều tiền hơn model sai.
Stage 3: FlowPRO post-training. Paper mô tả FlowPRO như một RL hậu huấn luyện không cần reward model. Quy trình là cho policy chạy thật, khi thất bại thì người vận hành can thiệp và rollback, tạo pair preferred/dispreferred action chunk. Sau đó RPRO loss tối ưu preference nhưng có regularizer để tránh policy lệch quá xa năng lực gốc. Tại thời điểm release, repo ghi phần FlowPRO đang under review/code coming soon, nên bạn nên xem đây là hướng triển khai hơn là API ổn định để gọi ngay.
Evaluation và kết quả chính
Trên RoboTwin 2.0, Hy-VLA đạt 90,9% success rate ở clean setting và 90,1% ở randomized setting, trung bình trên 50 task với 100 rollout mỗi task. Bảng repo so sánh với π0, ABot-M0, π0.5, Qwen-VLA, LingBot-VLA, starVLA, Motus và JoyAI-RA; Hy-VLA đứng đầu trong cả hai cột. Điểm đáng chú ý là randomized gần bằng clean, gợi ý policy không chỉ memorize visual appearance.
| Method | Clean | Randomized |
|---|---|---|
| π0 | 65.9 | 58.4 |
| π0.5 | 82.7 | 76.8 |
| Qwen-VLA | 86.1 | 87.2 |
| JoyAI-RA | 90.5 | 89.3 |
| Hy-VLA | 90.9 | 90.1 |
Trên Dobot X-Trainer, Hy-VLA không thắng mọi task tuyệt đối nhưng nổi bật ở các task cần thao tác chính xác. Ví dụ Fold & Store Glasses đạt 94%, Zip Up the Pen Case đạt 73%, Insert Bottles đạt 94%. Ablation không dùng UMI pretrain giảm mạnh ở những task tinh vi như folding và zipper. Điều này khớp với giả thuyết: UMI scale lớn giúp action prior cho contact-rich manipulation.
Track cross-embodiment còn quan trọng hơn. Khi fine-tune chỉ bằng UMI demonstration rồi deploy sang JAKA K1 và Astribot S1, Hy-VLA đạt 90% cho Organize Accessory và 89% cho Clean Up Table. Baseline Hy-Embodied không UMI pretrain tụt xuống 38% và 44%. Với team muốn triển khai trên robot không có nhiều giờ teleop, đây là tín hiệu đáng chú ý: data representation và platform mapping có thể quan trọng ngang model size.
FlowPRO result cũng mạnh: sau ba vòng post-training trên bốn task X-Trainer, RPRO đạt 99% cho Bottle, 99% cho Cap, 98% cho USB và 94% cho Zip, đồng thời giảm thời gian hoàn thành so với DAgger. Tuy vậy, hãy thận trọng: đây là kết quả trong setup của tác giả. Để áp dụng vào lab riêng, bạn cần pipeline intervention/rollback đủ an toàn và log preference đủ sạch.
Triển khai trên robot thật cần thêm gì?
Hy-VLA output không phải joint command. Policy sinh delta end-effector action chunk. Bạn cần một platform mapper chuyển delta EEF thành target pose hoặc joint trajectory cho robot cụ thể. Với tay máy công nghiệp, mapper thường là IK + collision/safety limit + gripper command. Với humanoid, mapper có thể phải kết hợp whole-body controller để giữ balance, tránh self-collision và giữ reachable workspace.
Runtime cũng cần xử lý latency. Paper dùng asynchronous inference-execution: trong khi robot đang execute một chunk, model dự đoán chunk kế tiếp. Khi chunk mới đến muộn hoặc observation đã cũ, hệ thống bỏ prefix stale và dùng cubic Bezier stitching để nối mượt giữa chunk cũ và chunk mới. Nếu bạn chỉ gọi model synchronous rồi gửi toàn bộ chunk xuống robot, chuyển động có thể giật hoặc phản ứng chậm.
Checklist tối thiểu cho deploy:
- Calibrate camera extrinsic/intrinsic và xác nhận frame convention.
- Map state robot sang dual-arm EEF representation đúng thứ tự trái/phải.
- Normalize state/action bằng stats đúng với checkpoint hoặc dữ liệu fine-tune.
- Viết safety layer: workspace limit, velocity limit, force/torque stop.
- Log toàn bộ observation, prediction, command và failure để debug.
- Chạy dry-run trong sim hoặc trên robot ở tốc độ thấp trước.
Nếu bạn đang làm humanoid whole-body, hãy xem thêm LeRobot trên G1 với π0-FAST để so sánh vấn đề mapping giữa upper-body VLA và whole-body controller.
Lỗi thường gặp
Không tải được checkpoint từ Hugging Face. Kiểm tra network, token HF nếu bị rate limit, và dung lượng cache. Có thể đặt HF_HOME sang ổ lớn hơn.
Out of memory ở quick start. Chạy bfloat16, giảm batch, tắt process khác trên GPU. Nếu vẫn OOM trên 16 GB, hãy thử checkpoint khác hoặc kiểm tra model có bị load hai lần không.
Dữ liệu Lance đọc chậm. Đặt dataset trên NVMe local, không đọc qua network filesystem chậm. Nếu chỉ debug, tải một table hoặc vài shard thay vì cả dataset.
Policy output shape đúng nhưng robot làm sai. Đây thường là lỗi frame convention, gripper scale, trái/phải bị đảo, hoặc action denormalization. Hãy plot từng chiều action và replay trong tool visualize trước khi gửi xuống hardware.
Fine-tune không hội tụ. Kiểm tra instruction consistency, camera order, action horizon, learning rate, normalization stats và số lượng episode thành công. Với VLA, 50 episode xấu không bằng 10 episode sạch.
Nên dùng Hy-VLA khi nào?
Hy-VLA phù hợp nếu bạn làm thao tác song thủ, muốn tận dụng UMI/LeRobot data scale lớn, cần baseline mạnh trên RoboTwin 2.0, hoặc đang nghiên cứu cross-embodiment transfer. Nó cũng đáng thử nếu team đã có GPU và muốn bắt đầu từ checkpoint UMI thay vì train VLA từ đầu.
Ngược lại, nếu bạn chỉ cần pick-and-place một tay trong workspace cố định, một policy Diffusion Policy hoặc ACT nhỏ có thể đơn giản hơn, dễ debug hơn và rẻ hơn. Hy-VLA là stack lớn; lợi ích của nó rõ nhất khi task có multi-view, bimanual coordination, nhiều object variation hoặc cần chuyển sang robot khác.
Nguồn tham khảo
- Paper: Hy-Embodied-0.5-VLA: From Vision-Language-Action Models to a Real-World Robot Learning Stack
- Code: Tencent-Hunyuan/Hy-Embodied-0.5-VLA
- Dataset: tencent/Hy-Embodied-0.5-VLA-Data
- Project page: Tairos Hy-Embodied-0.5-VLA


