Quick Summary
AffordanceVLA is a new robotics paper on arXiv, 2606.06155, with an official project page at skywalker-yqz.github.io/AffordanceVLA and code at github.com/Skywalker-yqz/AffordanceVLA. If you already know the basic idea behind Vision-Language-Action models, AffordanceVLA is best understood as a more structured version of that pipeline. It does not ask the model to jump directly from image and instruction to robot actions. It first asks: which object should the robot care about, where should it interact, and what 3D geometry constrains the manipulation?
The paper calls this intermediate layer structured affordance forecasting. In robotics, an affordance is the action possibility suggested by an object or region. A cup handle affords grasping. A toaster button affords pressing. A drawer front affords pushing or pulling. AffordanceVLA turns this idea into three trainable modules:
| Module | Question | Supervision Signal |
|---|---|---|
| Which2Act | Which object should the robot focus on? | visual latent of the target crop |
| Where2Act | Where is the 2D interaction region? | affordance heatmap |
| How2Act | What 3D geometry matters? | shape diffusion + 10-DoF layout |
The headline results reported on the project page are strong: 95.8% average success on LIBERO, 4.33 average length on CALVIN ABC→D, and 88.3% on basic real-world tasks. The data-efficiency claim is also important: in the project page analysis, AffordanceVLA surpasses the π0 ceiling with roughly 40% of the downstream fine-tuning data in the scaling experiment.
The Core Problem: VLM Semantics vs. Physical Control
Modern VLA models such as OpenVLA, π0, SpatialVLA, and many LeRobot-style policies typically take camera images, a language instruction, and robot state, then predict an action chunk. That design is powerful because it reuses pretrained Vision-Language Models. But AffordanceVLA points out a structural mismatch:
VLM pretraining:
image + text -> semantic alignment
"this is a cup", "this is a drawer", "the bowl is on the left"
Robot control:
observation + state + instruction -> physical action
dx, dy, dz, rotation, gripper, contact point, timing
A VLM is good at naming and relating visual concepts. A robot policy must touch the correct place, approach with the correct orientation, and execute at the right scale. If low-level action loss is simply back-propagated through the whole backbone, action priors can dominate instruction-following behavior. The project page gives an intuitive example from toaster manipulation: a baseline may behave like it is still doing pick-and-place instead of pressing the toaster button, because common action patterns pull the policy toward familiar motion.
AffordanceVLA inserts a bridge between vision-language understanding and action generation. This bridge is not dense video prediction, which can be slow and redundant. It is also not a frozen external affordance detector, which can create cascading perception errors. Instead, affordance prediction is trained jointly with the policy inside a Mixture-of-Transformer architecture.
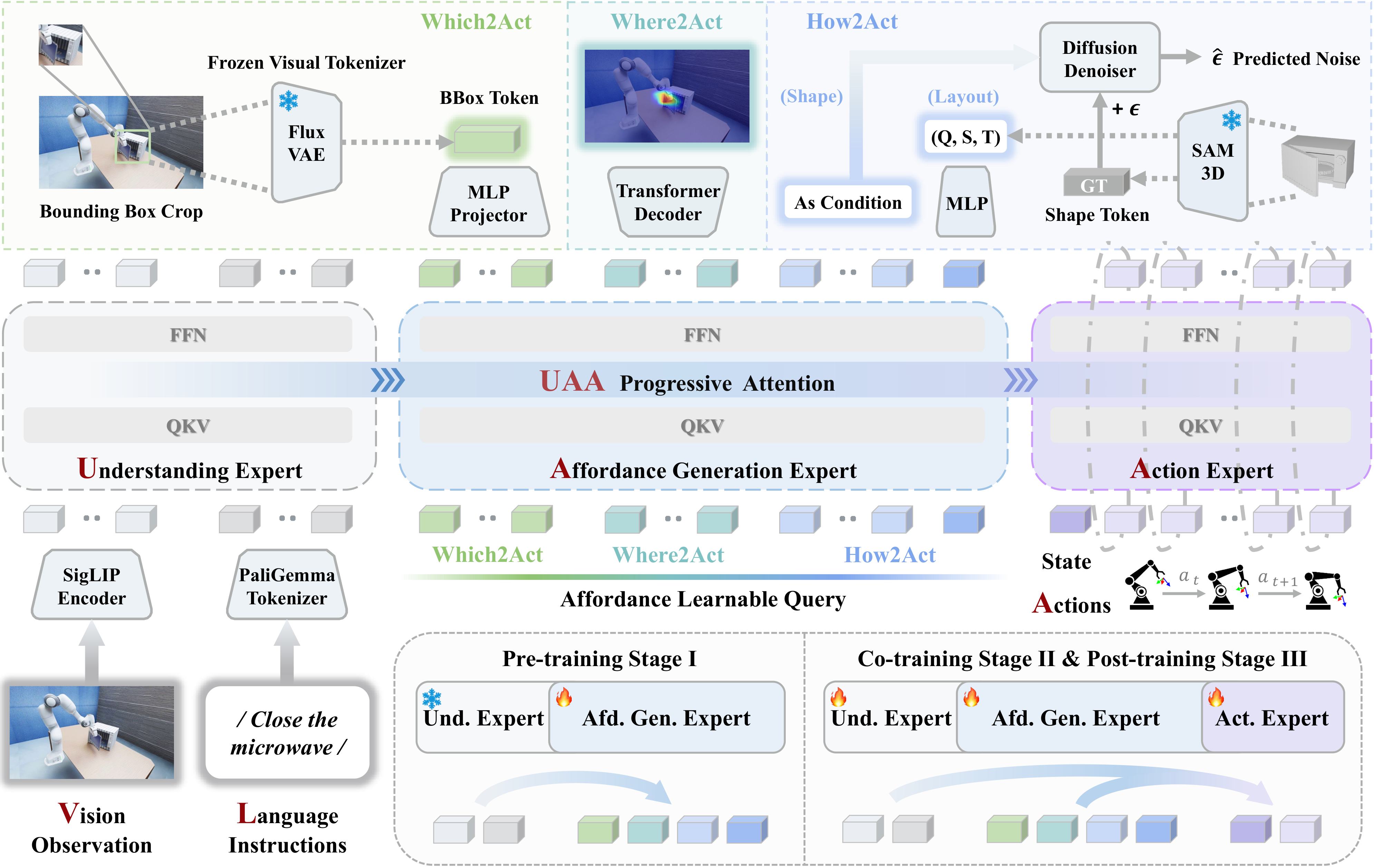
Architecture: Mixture-of-Transformer with UAA Attention
The GitHub README describes AffordanceVLA as a Mixture-of-Transformer (MoT) model with three specialized experts:
RGB observation O_t
Language instruction l
Proprioceptive state s_t
|
v
+----------------------+
| Understanding Expert |
| PaliGemma: SigLIP + |
| Gemma |
+----------------------+
|
v
+--------------------------+
| Affordance Generation |
| Gemma + learnable query |
| Which / Where / How |
+--------------------------+
|
v
+----------------------+
| Action Expert |
| Gemma + flow matching|
| action chunk a_t:t+k |
+----------------------+
These experts are coordinated by Understanding-Affordance-Action progressive attention. Attention inside each expert is bidirectional, so tokens can fuse local context freely. Attention across experts is causal and one-directional: the Affordance Generation expert attends to the Understanding expert, while the Action expert attends to both previous experts. Action information is therefore prevented from leaking backward into the affordance prediction stage.
For a beginner, the key point is this: AffordanceVLA is not just "a VLA plus a heatmap head". The attention design controls information flow so that affordance remains a clean intermediate representation, close to semantic grounding and spatial reasoning, rather than becoming a hidden shortcut for the action decoder.
Which2Act: Object-Centric Grounding
Which2Act answers: "Which object is actually relevant to the instruction?" Instead of supervising this only with a class label, the repository describes a target crop reconstructed through a continuous visual latent from a frozen Flux VAE. The default loss is MSE, with Smooth-L1 available as an option in src/models/which2act_decoder.py.
You can read it as a more visual form of object grounding. If the instruction is "pick up the red cup", the model must not merely produce the phrase "red cup". It must predict a visual representation of the target crop, which forces it to ignore background clutter and irrelevant distractors.
Observation: red cup, blue cup, banana, drawer
Instruction: "pick up the red cup"
Which2Act target:
crop(red cup) -> frozen Flux VAE -> latent z_q
model predicts z_hat
loss = MSE(z_hat, z_q)
This is especially useful in cluttered scenes. A direct VLA may learn a correlation between the action trajectory and the most common object layout in the training data. Which2Act pushes the model to bind the language command to the actual visual target in the current frame.
Where2Act: 2D Interaction Localization
Where2Act answers: "Where should the robot interact in image space?" It unfolds query tokens into a 2D affordance map through a lightweight Transformer decoder. The supervision is pixel-level Binary Cross Entropy over a mask or affordance heatmap.
This matters because object identity is not enough. For a drawer, the whole drawer is not equally useful. The interaction region may be the handle or front edge. For a toaster, the affordance region for "toast the bread" may be a button or lever, while the affordance region for "pick up the bread" is different. The same scene can therefore produce different heatmaps depending on the instruction.
Where2Act also provides a valuable debugging signal. If a trained policy fails, you can inspect whether the heatmap is looking at the right region. If the heatmap is wrong, the failure is likely perception or grounding. If the heatmap is correct but the robot still fails, the issue may be action decoding, calibration, controller limits, or 3D geometry.
How2Act: 3D Geometric Reasoning
How2Act answers: "What 3D shape and spatial layout should constrain the manipulation?" The project page describes two branches:
| Branch | Target |
|---|---|
| 3D shape generation | diffusion-based 3D shape latent |
| spatial layout regression | 10-DoF layout with rotation, scale, and translation |
On simple two-finger tabletop tasks, this head may look less dramatic than the 2D heatmap. But for real 6-DoF manipulation, object pose, approach direction, and spatial layout become central. A hot 2D pixel alone does not tell the robot how to orient the gripper or how the object sits in 3D space. How2Act gives the Action expert geometric priors that are closer to physical execution.
Three-Stage Training Curriculum
AffordanceVLA is not trained in one monolithic step. The paper and README describe a three-stage curriculum:
| Stage | Data | Trainable Components | Frozen Components |
|---|---|---|---|
| I: Affordance grounding | PRISM, AGD20K, RefSpatial, VQA | Affordance Generation, queries, decoders | Vision encoder, Understanding, Action |
| II: Robotic co-training | InternData-A1 synthetic robot data | all experts + decoders, vision encoder at lower LR | none as main default |
| III: Target post-training | LIBERO / CALVIN | fine-tune for target benchmark | none as main default |
Stage I teaches general affordance grounding without requiring robot actions. Stage II aligns affordance reasoning with robot control on large robot data. Stage III adapts the model to the downstream benchmark or target environment.
The affordance loss is decomposed into four parts: Which, Where, How-shape, and How-layout. The README reports a fixed internal ratio of 5 : 5 : 5 : 2. In Stage II, the aggregate affordance loss versus action loss is 0.50 : 1; in Stage III it drops to 0.15 : 1. This makes sense: once the target task is introduced, physical execution becomes more important, but affordance still anchors the representation.
Automated Affordance Annotation Pipeline
A practical question is obvious: most robot datasets do not ship with dense affordance labels. AffordanceVLA addresses this with an automated pipeline under src/datasets/preprocessing/:
Robot trajectory
|
| Step 1: keyframe detection
| rules: Start, Pre-Action, Gripper, Stop, Apex, End
v
Keyframes
|
| Step 2a: text LLM decomposes the instruction
v
Per-keyframe sub-instructions
|
| Step 2b: VLM emits detection category + where-to query
v
RexOmni-style query
|
| Step 3: RexOmni + SAM
v
bbox + affordance point + mask-bounded Gaussian heatmap
|
| Optional: SAM-3D
v
shape latent + layout tokens
The project page says this pipeline synthesizes more than 100K dense affordance annotations. The important implementation caveat is that prompt templates and LLM/VLM clients are not bundled. The README says you must fill SYSTEM_PROMPT, USER_PROMPT_TEMPLATE, and provide a client module or endpoint/token through environment variables. That is not a small detail; it determines whether your annotation pipeline is reproducible in your own lab.
Installing the GitHub Repository
The repository does not provide one universal requirements.txt, because the full system mixes several heavy stacks: the VLA model, LIBERO/CALVIN simulators, RexOmni, and SAM-3D. Instead, the repository ships role-specific environments under env/. The main training environment is:
conda create -n affordancevla python=3.11 -y
conda activate affordancevla
pip install -r env/requirements_AffordanceVLA.txt
Before running pip install -r, the README warns that two entries require manual handling: a SAM3D editable install using a path like -e /mnt/..., and a local flash-attn wheel using a file:///mnt/... path. Remove those machine-specific lines from the requirements file and install them manually for your hardware.
You also need pretrained weights:
| Weight | Config Key |
|---|---|
| π0 base | model.pretrained_path |
| PaliGemma tokenizer | model.language_tokenizer_path |
| Flux VAE for Which2Act | model.which2act_flux_vae_path |
| legacy VQ-VAE | model.which2act_vae_ckpt |
The compute requirement is serious. The README says the code was developed and validated with PyTorch CUDA on NVIDIA H200 GPUs, and recommends at least 8x H200 to reproduce the effective batch size in the configs without gradient accumulation. If you only have a single consumer GPU, treat the repository as a research codebase for smoke tests, architecture reading, dataset-loader development, or small-scale fine-tuning rather than a full reproduction target.
Training: Running the Three Stages
Training is YAML-driven. The important config files are:
configs/
├── stage1.yaml
├── stage2.yaml
├── stage3 CALVIN.yaml
├── stage3 Libero.yaml
└── debug_flux_vae.yaml
The README gives commands in this form:
# Stage I: affordance grounding pre-training
torchrun --nproc_per_node=8 -m src.train \
--config configs/stage1.yaml \
--mode train \
model.pretrained_path=$PRETRAINED_ROOT/pi0_base \
model.language_tokenizer_path=$PRETRAINED_ROOT/paligemma-3b-pt-224 \
model.which2act_flux_vae_path=$PRETRAINED_ROOT/flux-vae
# Stage II: robotic co-training
torchrun --nproc_per_node=8 -m src.train \
--config configs/stage2.yaml \
--mode train \
model.pretrained_path=$PRETRAINED_ROOT/pi0_base \
model.load_ckpt=outputs/stage1/checkpoint-XXXXX \
model.language_tokenizer_path=$PRETRAINED_ROOT/paligemma-3b-pt-224 \
model.which2act_flux_vae_path=$PRETRAINED_ROOT/flux-vae
# Stage III: target post-training
torchrun --nproc_per_node=8 -m src.train \
--config "configs/stage3 Libero.yaml" \
--mode train \
model.load_ckpt=outputs/stage2/checkpoint-XXXXX
The dataset loaders are your responsibility. The README explicitly states that concrete Dataset classes for PRISM, AGD20K, RefSpatial, VQA, InternData-A1, LIBERO, and CALVIN are not bundled, because each dataset's on-disk format depends on the downloaded release or split. The repository provides the schema and reusable building blocks: AffordanceSample, LayoutToken, tensor helpers, and constructors in src/datasets/base_dataset.py. Your loader must yield the expected AffordanceSample contract.
A practical checklist:
[ ] Download datasets under their respective licenses
[ ] Implement Dataset loaders that return AffordanceSample
[ ] Prepare pretrained weights and patch config paths
[ ] Run debug_flux_vae.yaml to validate the Flux VAE path
[ ] Run Stage I on a small subset first
[ ] Inspect Which latent, Where heatmaps, and How layout tokens
[ ] Run Stage II, then Stage III for LIBERO or CALVIN
Inference and Evaluation
The public README focuses more on training and evaluation setup than on a one-line demo inference script. Conceptually, inference follows this chain:
# Conceptual pseudocode, not an official public API
obs = get_rgb_observation()
state = get_robot_state()
instruction = "close the drawer"
h = understanding_expert(obs, instruction, state)
affordance_tokens = affordance_generation_expert(h)
action_chunk = action_expert(h, affordance_tokens)
for action in action_chunk:
robot.step(action)
For LIBERO evaluation, the README highlights several easy-to-miss details:
| Issue | Failure Mode |
|---|---|
| Not vertically flipping agent-view HDF5 frames | perception mismatch from OpenGL convention |
| Wrong gripper sign convention | open/close commands invert |
Not unnormalizing delta actions with pos_limit and ori_limit |
rotations and motion magnitudes are mis-scaled |
For real robots, you must map the predicted action chunk to your controller, usually OSC or end-effector delta control. You also need workspace limits, velocity limits, collision checks, and emergency stop behavior. Affordance heatmaps are useful for debugging, but they are not a substitute for a safety layer.
Results and Ablations
On LIBERO, the project page reports:
| Method | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| π0 | 98.0 | 96.8 | 94.4 | 88.4 | 94.4 |
| F1-VLA | 98.2 | 97.8 | 95.4 | 91.3 | 95.7 |
| AffordanceVLA full | 98.6 | 98.4 | 96.2 | 89.8 | 95.8 |
On CALVIN ABC→D, AffordanceVLA full reaches average length 4.33 and completes all 5 consecutive tasks in 75.9% of rollouts. The variant without Stage II reaches 3.81, which shows why robot-affordance co-training matters for out-of-distribution generalization.
The ablations are even more informative than the headline score. A No-Afd control, using a π0-style architecture on the same Stage II data but without the affordance objective, reaches only 92.4% LIBERO average and 3.93 CALVIN average length. Frozen-Afd, where the affordance expert is frozen after Stage I, collapses to 67.1% and 2.83. Block-wise Tokens, where the losses and data are kept but cross-attention among affordance heads is disabled, reaches 90.3% and 3.89. This supports the paper's claim that the gain is not just more data or denser supervision. The structured, jointly optimized affordance representation is doing real work.
When Should You Study AffordanceVLA?
If you are new to the topic, read this alongside foundations on Diffusion Policy, SpatialVLA, and LeRobot. AffordanceVLA is not a "clone and train full scale on a laptop" repository. It is a serious research codebase with heavy compute, external services, missing dataset-specific loaders, and unbundled prompt/client pieces.
But it is one of the clearest 2026 examples of where VLA research is going: away from purely direct end-to-end action prediction, and toward intermediate representations that are structured, visualizable, and physically meaningful.
Typical VLA learns:
vision + language + state -> action
AffordanceVLA additionally learns:
vision + language -> which object
vision + language -> where to interact
vision + language -> how 3D geometry constrains action
all of the above + state -> action chunk
That is why affordance can make robot manipulation more precise. It breaks a broad perception-to-action problem into smaller supervised questions that can be trained, inspected, and debugged.
Related Posts
- VLA Models: RT-2 → Octo → OpenVLA → π0
- SpatialVLA: spatial reasoning for robots
- LeRobot hands-on: train a robot policy