Tóm tắt nhanh
AffordanceVLA là một paper robotics mới trên arXiv, mã 2606.06155, với project page chính thức tại skywalker-yqz.github.io/AffordanceVLA và code tại github.com/Skywalker-yqz/AffordanceVLA. Nếu bạn đã đọc về VLA models, bạn sẽ thấy AffordanceVLA không chỉ hỏi model "nhìn ảnh + đọc lệnh rồi xuất action". Nó ép model học thêm một lớp trung gian: robot nên tác động vào object nào, tại vùng nào, và với hình học 3D ra sao.
Paper gọi lớp trung gian đó là structured affordance forecasting. Trong robotics, affordance là "khả năng hành động" mà một object hoặc một vùng trên object gợi ra cho robot. Tay cầm của cốc có affordance để grasp. Nút toaster có affordance để press. Mép ngăn kéo có affordance để pull hoặc push. Điểm khác biệt của AffordanceVLA là nó không để VLA tự suy luận affordance một cách ngầm ẩn trong hidden state, mà tách thành ba module rõ ràng:
| Module | Câu hỏi | Tín hiệu học |
|---|---|---|
| Which2Act | Robot nên tập trung vào object nào? | visual latent của crop target |
| Where2Act | Robot nên chạm vào vùng 2D nào? | affordance heatmap |
| How2Act | Robot nên hiểu hình học 3D thế nào? | shape diffusion + 10-DoF layout |
Kết quả chính trên project page: AffordanceVLA đạt 95.8% average success trên LIBERO, 4.33 average length trên CALVIN ABC→D, và 88.3% trên các basic real-world tasks. Điểm đáng chú ý hơn là sample efficiency: project page cho biết model vượt "ceiling" của π0 chỉ với khoảng 40% fine-tuning data trong thí nghiệm data scaling.
Vấn đề: VLM hiểu semantic, robot cần không gian 3D
Các VLA như OpenVLA, π0, SpatialVLA hoặc các hướng LeRobot thường nhận input gồm camera image, language instruction, robot state rồi output action chunk. Cách này rất mạnh vì model tận dụng được pre-trained VLM. Nhưng paper AffordanceVLA chỉ ra một mismatch cơ bản:
VLM pretraining:
image + text -> semantic alignment
"đây là cốc", "đây là ngăn kéo", "bên trái cái bát"
Robot control:
observation + state + instruction -> physical action
dx, dy, dz, rotation, gripper, contact point, timing
Nói cách khác, VLM giỏi "nhìn và gọi tên", còn robot phải "chạm đúng chỗ và di chuyển đúng hướng". Nếu chỉ dùng action loss để fine-tune toàn bộ backbone, action prior có thể lấn át khả năng instruction following. Ví dụ, trong task toaster, π0 có thể vẫn hành xử như đang pick-and-place thay vì press button, vì action pattern phổ biến trong data kéo model về thao tác quen thuộc.
AffordanceVLA giải quyết bằng cách chèn một cầu nối nằm giữa vision-language understanding và action generation. Cầu nối này không phải video prediction dày đặc, vì dự đoán cả tương lai video vừa nặng vừa dư thừa. Nó cũng không phải external detector đơn giản, vì một affordance module đóng băng dễ tạo lỗi dây chuyền. Thay vào đó, affordance được train chung với policy trong một kiến trúc MoT.
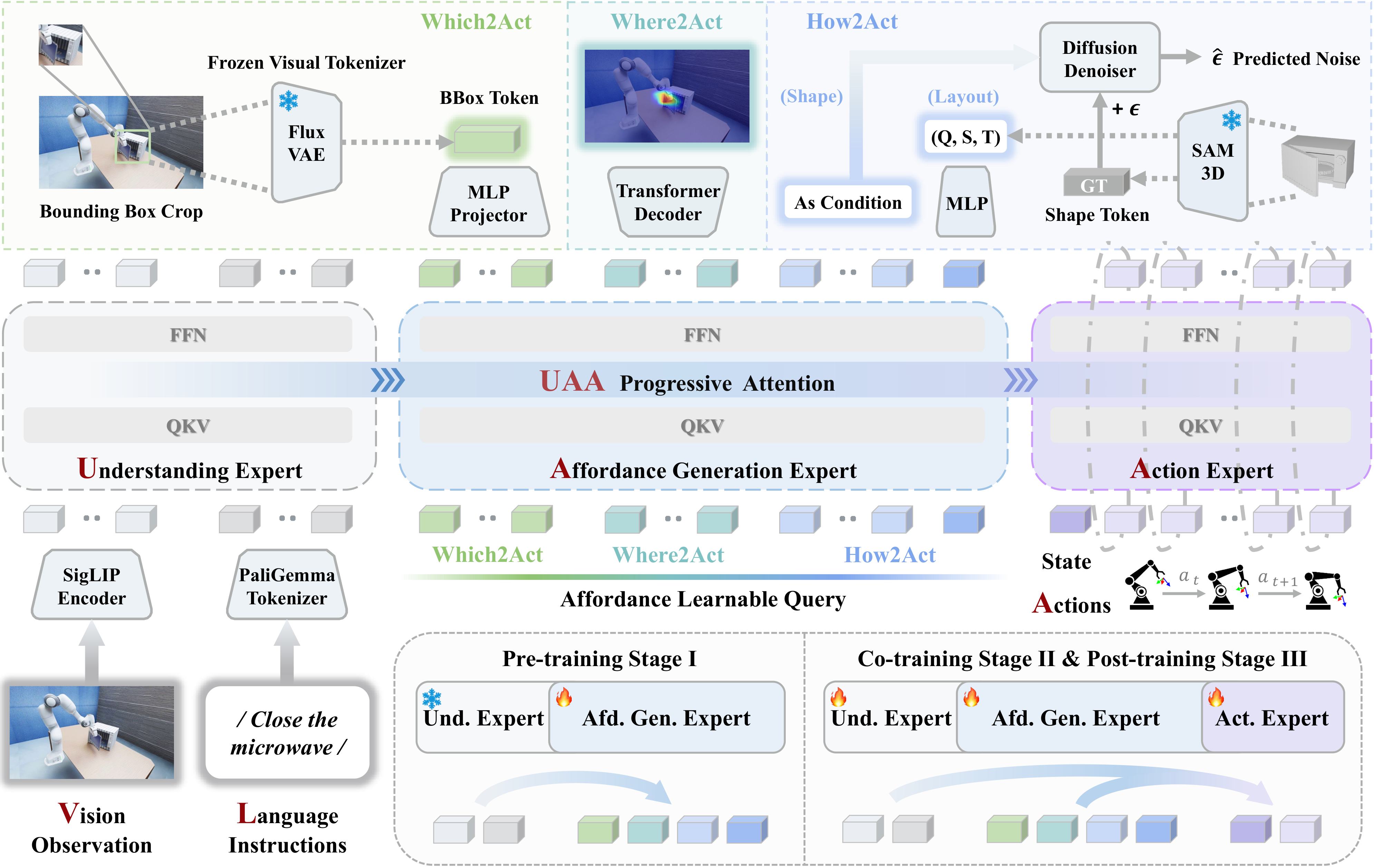
Kiến trúc: Mixture-of-Transformer với UAA attention
Theo README GitHub, AffordanceVLA dùng Mixture-of-Transformer (MoT) gồm ba expert:
RGB observation O_t
Language instruction l
Proprioceptive state s_t
|
v
+----------------------+
| Understanding Expert |
| PaliGemma: SigLIP + |
| Gemma |
+----------------------+
|
v
+--------------------------+
| Affordance Generation |
| Gemma + learnable query |
| Which / Where / How |
+--------------------------+
|
v
+----------------------+
| Action Expert |
| Gemma + flow matching|
| action chunk a_t:t+k |
+----------------------+
Ba expert được nối bằng Understanding-Affordance-Action progressive attention. Attention trong cùng một expert là bidirectional để token trong expert đó fusion ngữ cảnh tốt. Nhưng attention giữa các expert là causal theo một chiều: Affordance Generation chỉ nhìn Understanding; Action nhìn cả Understanding và Affordance. Cách này giúp action information không rò ngược vào affordance prediction stage.
Điểm này quan trọng với người mới: AffordanceVLA không chỉ "thêm một head heatmap". Nó thiết kế luồng thông tin để affordance vẫn là tín hiệu trung gian sạch, gần semantic và spatial grounding, thay vì bị action decoder biến thành shortcut.
Ba affordance head hoạt động ra sao?
Which2Act: chọn object cần thao tác
Which2Act trả lời: "Trong ảnh, object nào thật sự liên quan đến instruction?" Thay vì học bằng class label rời rạc, repo mô tả Which2Act dùng target crop và reconstruct continuous visual latent từ frozen Flux VAE. Loss mặc định là MSE, có tùy chọn Smooth-L1 trong src/models/which2act_decoder.py.
Beginner có thể hiểu như sau: nếu instruction là "pick up the red cup", model không chỉ output token "red cup"; nó phải khôi phục một representation hình ảnh của vùng target. Điều này buộc model bỏ qua background, distractor object, và object không liên quan.
Observation: red cup, blue cup, banana, drawer
Instruction: "pick up the red cup"
Which2Act target:
crop(red cup) -> frozen Flux VAE -> latent z_q
model predicts z_hat
loss = MSE(z_hat, z_q)
Where2Act: định vị vùng tương tác 2D
Where2Act trả lời: "Nên chạm vào pixel/vùng nào?" Nó unfold query tokens thành affordance map 2D qua lightweight Transformer decoder. Supervision là pixel-level Binary Cross Entropy với mask hoặc heatmap affordance.
Ví dụ, với lệnh "close the drawer", vùng affordance có thể nằm ở mặt trước hoặc tay nắm ngăn kéo. Với "toast the bread", vùng quan trọng có thể là button/lever trên toaster. Đây là lý do paper nhấn mạnh instruction sensitivity: cùng một scene nhưng lệnh khác nhau sẽ cần heatmap khác nhau.
How2Act: hiểu hình học 3D
How2Act trả lời: "Vùng đó nằm trong hình học 3D nào và layout object ra sao?" Theo project page, head này gồm hai nhánh:
| Nhánh | Mục tiêu |
|---|---|
| 3D shape generation | diffusion-based 3D shape latent |
| spatial layout regression | 10-DoF layout gồm rotation, scale, translation |
Trong tabletop task đơn giản, How2Act có thể không tạo khác biệt quá lớn so với Which/Where. Nhưng trong thao tác 6-DoF, object nghiêng, cần tiếp cận theo hướng cụ thể, hoặc task real-world có nhiều nhiễu, 3D prior giúp action expert không chỉ "đi tới điểm nóng 2D" mà còn hiểu không gian thao tác.
Training curriculum ba stage
AffordanceVLA không train một phát end-to-end từ đầu. Paper và README mô tả ba stage:
| Stage | Dữ liệu | Train | Freeze |
|---|---|---|---|
| I: Affordance grounding | PRISM, AGD20K, RefSpatial, VQA | Affordance Generation, queries, decoders | Vision encoder, Understanding, Action |
| II: Robotic co-training | InternData-A1 synthetic robot | All experts + decoders, vision encoder LR thấp | Không freeze chính |
| III: Target post-training | LIBERO / CALVIN | Fine-tune theo target benchmark | Không freeze chính |
Stage I dạy model grounding affordance tổng quát, chưa cần action label. Stage II ghép affordance với robot action trên dữ liệu robot lớn. Stage III thích nghi với môi trường đích như LIBERO hoặc CALVIN.
Loss của affordance gồm bốn phần: Which, Where, How-shape, How-layout. README ghi internal ratio cố định là 5 : 5 : 5 : 2. Ở Stage II, tổng affordance loss so với action loss là 0.50 : 1; ở Stage III giảm còn 0.15 : 1. Cách giảm này hợp lý: khi fine-tune task đích, action execution cần được ưu tiên hơn, nhưng affordance vẫn giữ vai trò anchor.
Automated affordance annotation pipeline
Một câu hỏi lớn: robot datasets thường không có dense affordance labels, vậy labels từ đâu ra? Repo có pipeline trong src/datasets/preprocessing/:
Robot trajectory
|
| Step 1: keyframe detection
| rules: Start, Pre-Action, Gripper, Stop, Apex, End
v
Keyframes
|
| Step 2a: text LLM decomposes instruction
v
Per-keyframe sub-instructions
|
| Step 2b: VLM emits detection category + where-to query
v
RexOmni-style query
|
| Step 3: RexOmni + SAM
v
bbox + affordance point + mask-bounded Gaussian heatmap
|
| Optional: SAM-3D
v
shape latent + layout tokens
Theo project page, pipeline này tổng hợp hơn 100K dense affordance annotations. Tuy nhiên, beginner cần chú ý một điểm rất thực tế: prompt templates và LLM/VLM clients không được bundle sẵn. README nói rõ bạn phải tự điền SYSTEM_PROMPT, USER_PROMPT_TEMPLATE, và cung cấp client module hoặc endpoint/token qua environment variables.
Cài đặt từ GitHub
Repo không có một requirements.txt duy nhất vì pipeline gồm nhiều stack nặng: VLA model, LIBERO/CALVIN simulator, RexOmni, SAM-3D. README cung cấp từng environment trong env/. Main training environment:
conda create -n affordancevla python=3.11 -y
conda activate affordancevla
pip install -r env/requirements_AffordanceVLA.txt
Trước khi pip install -r, README cảnh báo có hai entry cần xử lý thủ công: SAM3D editable install dạng -e /mnt/... và local wheel flash-attn dạng file:///mnt/.... Bạn nên xóa hai dòng đó khỏi requirements tương ứng rồi cài thủ công theo máy của mình.
Pretrained weights cần chuẩn bị:
| Weight | Config key |
|---|---|
| π0 base | model.pretrained_path |
| PaliGemma tokenizer | model.language_tokenizer_path |
| Flux VAE cho Which2Act | model.which2act_flux_vae_path |
| VQ-VAE legacy | model.which2act_vae_ckpt |
Compute cũng là điểm cần nói thẳng: README nói code được validate với PyTorch CUDA trên NVIDIA H200, khuyến nghị ít nhất 8x H200 để reproduce batch size trong configs. Nếu bạn chỉ có một GPU consumer, cách thực tế là chạy smoke test/debug, đọc architecture, hoặc fine-tune subset nhỏ chứ không nên kỳ vọng reproduce full paper.
Training: chạy ba stage
Các config nằm trong configs/:
configs/
├── stage1.yaml
├── stage2.yaml
├── stage3 CALVIN.yaml
├── stage3 Libero.yaml
└── debug_flux_vae.yaml
Lệnh train theo README:
# Stage I: affordance grounding pre-training
torchrun --nproc_per_node=8 -m src.train \
--config configs/stage1.yaml \
--mode train \
model.pretrained_path=$PRETRAINED_ROOT/pi0_base \
model.language_tokenizer_path=$PRETRAINED_ROOT/paligemma-3b-pt-224 \
model.which2act_flux_vae_path=$PRETRAINED_ROOT/flux-vae
# Stage II: robotic co-training
torchrun --nproc_per_node=8 -m src.train \
--config configs/stage2.yaml \
--mode train \
model.pretrained_path=$PRETRAINED_ROOT/pi0_base \
model.load_ckpt=outputs/stage1/checkpoint-XXXXX \
model.language_tokenizer_path=$PRETRAINED_ROOT/paligemma-3b-pt-224 \
model.which2act_flux_vae_path=$PRETRAINED_ROOT/flux-vae
# Stage III: target post-training
torchrun --nproc_per_node=8 -m src.train \
--config "configs/stage3 Libero.yaml" \
--mode train \
model.load_ckpt=outputs/stage2/checkpoint-XXXXX
Dataset loaders là phần bạn phải chuẩn bị. README nói các concrete Dataset classes cho PRISM, AGD20K, RefSpatial, VQA, InternData-A1, LIBERO, CALVIN không được bundle, vì format on-disk tùy bản download. Repo cung cấp schema AffordanceSample, LayoutToken, tensor helpers, và constructors trong src/datasets/base_dataset.py; loader của bạn cần yield đúng contract đó.
Một checklist tối thiểu:
[ ] Download datasets theo license từng nguồn
[ ] Viết Dataset loader trả về AffordanceSample
[ ] Chuẩn bị pretrained weights và sửa config path
[ ] Chạy debug_flux_vae.yaml để kiểm tra Flux VAE path
[ ] Chạy Stage I với subset nhỏ
[ ] Kiểm tra heatmap/which latent/layout token trước khi Stage II
[ ] Train Stage II rồi fine-tune Stage III
Inference và evaluation
Repo README tập trung vào training/evaluation setup hơn là một file demo inference một dòng. Về mặt logic, inference của AffordanceVLA chạy theo chuỗi:
# Pseudocode để hiểu luồng inference, không phải API chính thức
obs = get_rgb_observation()
state = get_robot_state()
instruction = "close the drawer"
h = understanding_expert(obs, instruction, state)
affordance_tokens = affordance_generation_expert(h)
action_chunk = action_expert(h, affordance_tokens)
for action in action_chunk:
robot.step(action)
Nếu bạn port checkpoint sang LIBERO, README nhắc ba lỗi dễ gặp:
| Lỗi | Hậu quả |
|---|---|
| Không vertical flip ảnh HDF5 agent-view | perception lệch vì OpenGL convention |
| Sai sign gripper | grasp mở/đóng ngược |
Không unnormalize delta action theo pos_limit/ori_limit |
rotation bị yếu hoặc sai scale |
Với real robot, bạn cần map action chunk sang controller của robot, thường là OSC hoặc end-effector delta control. Đừng bỏ qua safety: giới hạn workspace, velocity, collision zone, và emergency stop. Affordance heatmap giúp debug tốt, nhưng không thay cho safety layer.
Kết quả và ablation
Trên LIBERO, project page báo cáo:
| Method | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| π0 | 98.0 | 96.8 | 94.4 | 88.4 | 94.4 |
| F1-VLA | 98.2 | 97.8 | 95.4 | 91.3 | 95.7 |
| AffordanceVLA full | 98.6 | 98.4 | 96.2 | 89.8 | 95.8 |
Trên CALVIN ABC→D, AffordanceVLA full đạt average length 4.33 và hoàn thành đủ 5 task liên tiếp trong 75.9% rollout. Bản không có Stage II chỉ đạt 3.81, cho thấy co-training robot-affordance là phần quan trọng cho OOD generalization.
Ablation cũng rất đáng đọc. No-Afd, tức dùng kiến trúc π0 trên cùng Stage II data nhưng không có affordance objective, chỉ đạt LIBERO average 92.4% và CALVIN 3.93. Frozen-Afd, tức đóng băng affordance expert sau Stage I, tụt mạnh xuống 67.1% và 2.83. Block-wise Tokens, tức giữ losses/data nhưng cấm cross-attention giữa ba affordance head, đạt 90.3% và 3.89. Kết luận hợp lý là gain không chỉ đến từ nhiều data hơn hoặc nhiều loss hơn, mà đến từ representation có cấu trúc và được co-optimize với policy.
Khi nào nên học AffordanceVLA?
Nếu bạn mới bắt đầu, hãy đọc bài này cùng các nền tảng về Diffusion Policy, SpatialVLA và LeRobot. AffordanceVLA chưa phải repo "clone là train full ngay" cho laptop. Nhưng nó là case study rất tốt về cách robotics research năm 2026 đang đi từ VLA end-to-end sang VLA có intermediate representation.
Điểm cần nhớ:
VLA thường học:
vision + language + state -> action
AffordanceVLA học thêm:
vision + language -> which object
vision + language -> where to interact
vision + language -> how 3D geometry constrains action
all of the above + state -> action chunk
Đó là lý do affordance có thể giúp robot thao tác chính xác hơn: nó biến một bài toán quá rộng thành các bài toán nhỏ hơn, có thể supervise, visualize và debug.
Bài viết liên quan
- VLA Models: RT-2 → Octo → OpenVLA → π0
- SpatialVLA: spatial reasoning cho robot
- LeRobot hands-on: train robot policy