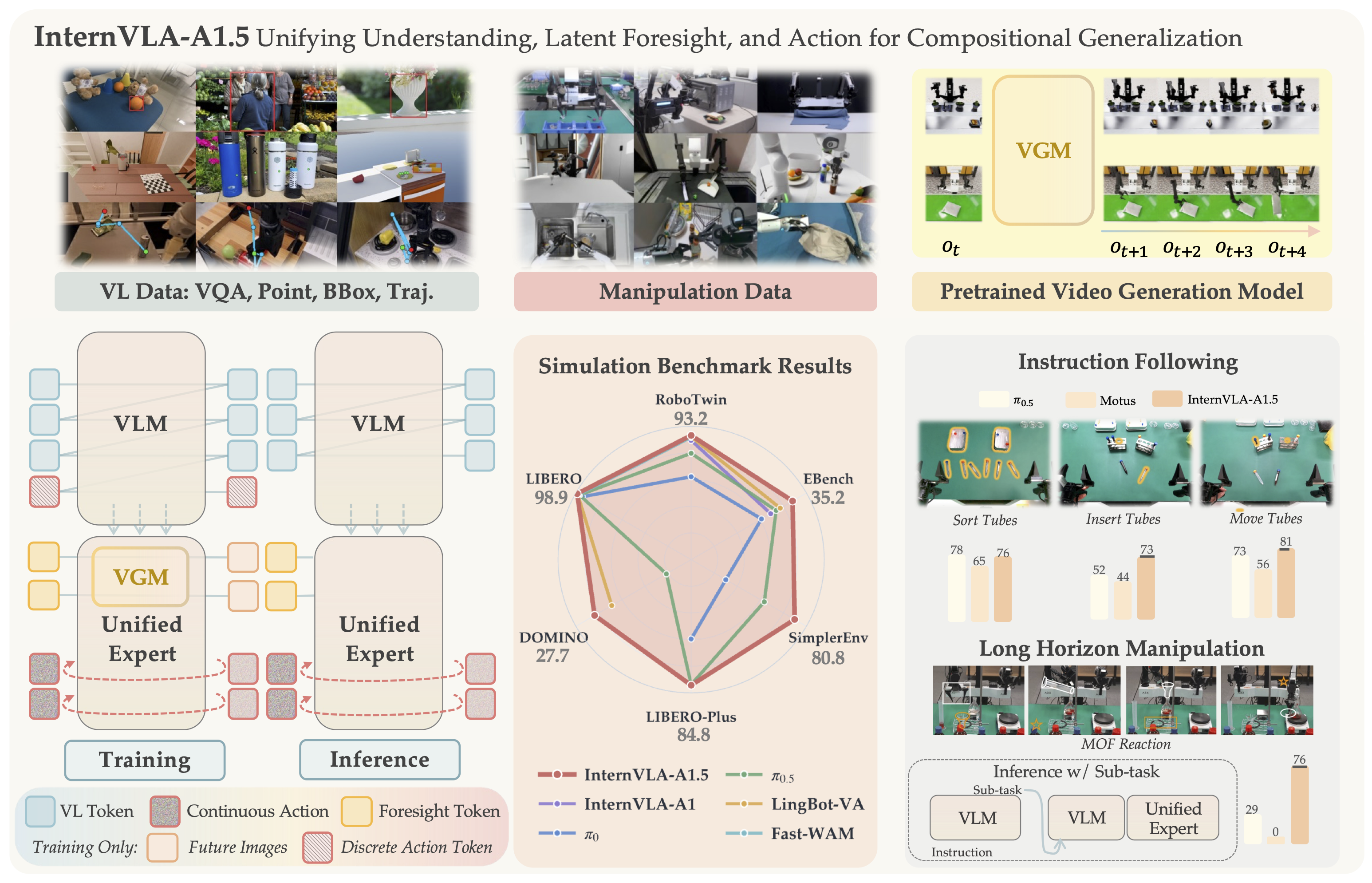
World Pilot is a new framework for steering Vision-Language-Action (VLA) models with World-Action Priors. Instead of asking a VLA policy to infer all physical dynamics from the current image and a language instruction, World Pilot adds two signals from a World-Action Model (WAM): a latent representation of how the scene is expected to evolve, and a coarse trajectory prior suggesting the shape of useful motion. These signals do not replace the policy. They act as a pilot that gives the action generator a better short-horizon sense of the physical future.
This guide explains the paper and the public repository from an implementation perspective. The goal is not to repeat the abstract, but to make the system usable: what problem World Pilot solves, how Latent Steering and Action Steering work, how to install the repo, how training is organized, how inference/evaluation is served, and how to read the zero-shot OOD results. If you are new to VLA work, think of World Pilot as a clean example of the current direction in robot learning: a VLM provides semantic grounding, while a world model provides predicted dynamics.
Primary sources used for this guide:
- Paper: World Pilot: Steering Vision-Language-Action Models with World-Action Priors
- Project page: world-pilot.github.io
- GitHub: ZefuLin/WorldPilot
- Model weights: Chedan86/WorldPilot-LIBERO
- Precomputed cache: Chedan86/WorldPilot-LIBERO-precompute
The Core Idea
Most modern VLA policies follow a pipeline like this:
camera images + language instruction + proprioception
|
v
Vision-Language Model backbone
|
v
action head / diffusion head / flow-matching head
|
v
robot action chunk
This design is strong at semantic grounding. A robot can understand that "stack orange blocks" refers to orange blocks and a stacking task rather than a pushing task. However, semantic grounding from image-text pretraining is mostly learned from static image-caption pairs. Real manipulation is continuous, contact-rich, partially occluded, and sensitive to geometry, timing, and accumulated error.
The gap becomes obvious under zero-shot out-of-distribution shifts:
| Shift | Example | Why a plain VLA may fail |
|---|---|---|
| Camera | a viewpoint not seen during fine-tuning | hidden states recognize objects but do not predict motion well |
| Geometry | taller blocks or a shifted lid pose | action tolerance changes, not just object identity |
| Deformable state | a towel rotated into a new shape | soft-object state evolves continuously |
| Appearance | different background, lighting, or noise | the VLM may see the object, while the action head drifts |
| Layout | object and target move relative to each other | the policy needs a trajectory-level hint |
World Pilot augments the policy with a WAM. The WAM consumes the same observation, instruction, and optional proprioception, then produces:
scene-evolution latent: a compact latent that represents near-future scene changes, including object motion, contact outcomes, and local state transitions.anticipated action trajectory: a rough trajectory hypothesis, used as a motion prior rather than as the final action.
A simplified architecture:
Inputs
multiview images + instruction + proprioception
|
+----------------------------+
| |
v v
VLM semantic path World-Action Model
| / \
| v v
| scene-evolution anticipated
| latent trajectory
| | |
| v v
| Latent Steering Action Steering
| | |
+----------------------+----------------+
|
v
flow-matching action head
|
v
executable action
The important point is that World Pilot does not turn the WAM into the controller. The VLA remains the main policy and is still trained against expert action chunks. The world priors are injected into the decision chain at two carefully chosen points.

Architecture: Two Complementary Steering Paths
The paper defines two steering pathways: Latent Steering at the perception layer and Action Steering at the action-generation layer. They can be ablated independently, but using both gives the strongest result.
Latent Steering
Latent Steering asks: how should the predicted future from a world model enter VLM hidden states without being polluted by pixel-level artifacts?
One naive approach would be to decode a future image from the WAM, then feed that future image into the VLM as another visual input. The paper tests this direction and finds it weaker than latent injection. The reason is practical: decoded future images contain texture, lighting, background details, and generation artifacts that are mostly irrelevant for control. The WAM latent keeps a more compact representation of physical dynamics.
The Latent Steering flow looks like this:
WAM future latent Z_w
|
v
dynamics encoder f_dyn
|
+ temporal future embedding
|
v
future-scene tokens D_w
|
v
cross-attention: VLM hidden states attend to D_w
|
v
dynamics-aware VLM hidden states
Each VLM hidden token can selectively attend to future-scene tokens that are relevant to its spatial region or object. The update is residual, so the original token sequence and hidden-state interface are preserved. That makes the design easier to attach to an existing VLA action head.
Action Steering
Action Steering asks a different question: if the WAM predicts a rough action trajectory, how should that trajectory condition the action generator?
World Pilot does not execute the WAM trajectory directly. It also does not force each output action step to match a corresponding WAM step. Instead, the trajectory is resampled to the VLA horizon K and encoded into one single prior token. This token is inserted as a prefix for the flow-matching action generator.
WAM anticipated trajectory A_w
|
v
align to VLA horizon K
|
v
action encoder f_act
|
v
single trajectory prior token s_w
|
v
self-attention context for flow-matching action head
The single-token design is small but important. Per-step trajectory tokens can over-constrain the generator and propagate WAM noise step by step. Flow initialization from the WAM trajectory ties the final output too strongly to WAM action quality. A single encoded token keeps the WAM as soft guidance: enough to reveal the coarse motion shape, but not enough to prevent the VLA action head from correcting the final chunk.
Training Objective
World Pilot trains like a flow-matching VLA policy with additional conditioning. Each training sample contains observations, a language instruction, optional proprioception, and an expert action chunk A*. The WAM is frozen. Gradients update only the VLA-side modules:
- VLM backbone and adapters, depending on the configuration
- dynamics encoder for the latent prior
- Latent Steering cross-attention
- action encoder for the trajectory prior
- flow-matching action generator
The paper uses a clean-action parameterization. In pseudo-code:
# observation: images, language, optional proprioception
# expert: clean action chunk A_star
with torch.no_grad():
Z_w, A_w = wam(observation) # frozen WAM
H = vlm_encode(observation)
H_bar = latent_steering(H, Z_w)
s_w = action_encoder(align_to_horizon(A_w, K))
eps = torch.randn_like(A_star)
tau = sample_flow_time()
X_tau = tau * A_star + (1 - tau) * eps
A_hat = action_head(
noisy_action=X_tau,
flow_time=tau,
state_token=proprioception,
prior_token=s_w,
cross_attention_context=H_bar,
)
loss = weight(tau) * mse(A_hat, A_star)
loss.backward()
During training, the WAM forward pass can be precomputed and cached, keeping the heavy world model out of the inner loop. During inference and evaluation, the WAM runs online at every decision step so priors are generated from the live observation.
Installing the Public Repo
The public WorldPilot repository currently uses multiple local environments rather than a single Docker-first workflow. This is the part beginners are most likely to trip over. There are four environments:
| Environment | Role |
|---|---|
WorldPilot |
policy training, model server, main code |
cosmos-policy |
Cosmos Policy serving and cache precompute |
libero |
baseline LIBERO tooling if needed |
libero-plus |
public zero-shot OOD evaluation |
The commands below are a practical skeleton. Read the repository docs before a full run because checkpoint paths, dataset roots, and GPU IDs must be adapted to your machine.
sudo apt-get update
sudo apt-get install -y \
build-essential cmake git git-lfs curl wget ffmpeg \
libgl1 libegl1-mesa-dev libgl1-mesa-dri libglib2.0-0 \
libexpat1 libfontconfig1-dev libpython3-stdlib libmagickwand-dev
Create the main environment:
mamba create -n WorldPilot python=3.10 -y
mamba activate WorldPilot
git clone https://github.com/ZefuLin/WorldPilot.git
cd WorldPilot
pip install torch torchvision --index-url <your-pytorch-cuda-wheel-index>
pip install -r requirements.txt
pip install -e .
Install VGGT if your LIBERO configuration requires it:
git clone https://github.com/facebookresearch/vggt.git /path/to/vggt
pip install -e /path/to/vggt
Install Cosmos Policy:
mamba create -n cosmos-policy python=3.10 -y
mamba activate cosmos-policy
git clone https://github.com/NVlabs/cosmos-policy.git
cd /path/to/cosmos-policy
pip install -e ".[cu128]"
pip install -r cosmos_policy/experiments/robot/libero/libero_requirements.txt
pip install websockets msgpack
Install LIBERO-Plus for evaluation:
mamba create -n libero-plus python=3.8 -y
mamba activate libero-plus
git clone https://github.com/sylvestf/LIBERO-plus.git
cd /path/to/LIBERO-plus
pip install -r requirements.txt
pip install -r extra_requirements.txt
pip install -e .
cd /path/to/WorldPilot
pip install -r examples/LIBERO-plus/eval_files/libero_plus_requirements.txt
Create the local LIBERO-Plus config:
mkdir -p ~/.libero-plus
cat > ~/.libero-plus/config.yaml <<'EOF'
assets: /path/to/LIBERO-plus/libero/libero/assets
bddl_files: /path/to/LIBERO-plus/libero/libero/bddl_files
benchmark_root: /path/to/LIBERO-plus/libero/libero
datasets: /path/to/libero_plus_datasets
init_states: /path/to/LIBERO-plus/libero/libero/init_files
EOF
export LIBERO_CONFIG_PATH=~/.libero-plus
export MUJOCO_GL=egl
export PYOPENGL_PLATFORM=egl
Checkpoints and Cache Artifacts
The public release depends on several pretrained assets:
| Asset | Purpose |
|---|---|
nvidia/Cosmos-Policy-LIBERO-Predict2-2B |
WAM/Cosmos Policy priors |
facebook/VGGT-1B |
visual geometry component for the current config |
StarVLA/Qwen3-VL-4B-Instruct-Action |
action-ready Qwen3-VL checkpoint |
amap_cvlab/ABot-M0-Pretrain |
ABot-M0 pretraining checkpoint |
Chedan86/WorldPilot-LIBERO |
released WorldPilot checkpoint |
Chedan86/WorldPilot-LIBERO-precompute |
precomputed LIBERO Cosmos cache |
If your goal is evaluation, the fastest path is to download the released checkpoint and precomputed cache. If your goal is training from scratch on LIBERO, you need to configure examples/LIBERO/train_files/WorldPilot.yaml and a cache directory.
The expected cache layout is roughly:
/path/to/cosmos_cache/
libero_10_no_noops_1.0.0_lerobot/
libero_goal_no_noops_1.0.0_lerobot/
libero_object_no_noops_1.0.0_lerobot/
libero_spatial_no_noops_1.0.0_lerobot/
If you do not use the published cache, run precompute:
cd /path/to/WorldPilot
# edit the variables in cosmos_bridge/run_precompute.sh first
bash cosmos_bridge/run_precompute.sh
The script starts Cosmos servers for dataset splits and writes cache files to your configured output directory. For a beginner, the published cache is usually the better first step because it lets you debug the policy path before debugging WAM precompute.
Training World Pilot
The public training path has five steps:
- Prepare the
WorldPilotandcosmos-policyenvironments. - Prepare pretrained weights and cache artifacts.
- Download or precompute the Cosmos cache.
- Edit the training YAML and launch script.
- Run training.
At minimum, edit these fields in examples/LIBERO/train_files/WorldPilot.yaml:
run_root_dir: /path/to/runs
run_id: worldpilot_libero_debug
framework:
vggt_path: /path/to/VGGT-1B
qwenvl:
base_vlm: /path/to/Qwen3-VL-4B-Instruct-Action
datasets:
vla_data:
data_root_dir: /path/to/libero_lerobot_data
cosmos_cache_dir: /path/to/cosmos_cache
trainer:
pretrained_checkpoint: /path/to/ABot-M0-Pretrain
Then edit the top block of examples/LIBERO/train_files/run_libero_train.sh:
GPU_IDS=0,1,2,3
CONFIG_YAML=examples/LIBERO/train_files/WorldPilot.yaml
Launch:
cd /path/to/WorldPilot
mamba activate WorldPilot
bash examples/LIBERO/train_files/run_libero_train.sh
The paper fine-tunes World Pilot on 8 RTX PRO 6000 GPUs and uses WAM-condition dropout with rate 0.3 so the policy does not over-rely on priors. If you only have one GPU, do not expect to reproduce the full benchmark number. Start with a short run that verifies the data loader, cache path, checkpoint loading, and loss behavior.
A practical smoke-test checklist:
[ ] WorldPilot package imports correctly
[ ] Qwen3-VL action checkpoint loads
[ ] ABot-M0 pretrain loads
[ ] LIBERO LeRobot dataset is readable
[ ] cosmos_cache_dir is readable
[ ] first batch has images, language, proprioception, and actions
[ ] forward pass has no NaNs
[ ] loss decreases during the first few hundred steps
Inference and Evaluation
The public evaluation target is WorldPilot on Libero-Plus. The repository provides two entrypoints:
examples/LIBERO-plus/eval_files/eval_libero_single.shexamples/LIBERO-plus/eval_files/eval_libero_batch.sh
Before evaluation, make sure you have:
| File | Role |
|---|---|
| WorldPilot checkpoint | policy weights |
| Cosmos checkpoint | online WAM server |
| Cosmos dataset statistics JSON | normalization/statistics |
| Cosmos T5 embedding pickle | language instruction embeddings |
~/.libero-plus/config.yaml |
paths to assets, datasets, and init states |
Single-suite evaluation:
cd /path/to/WorldPilot
mamba activate libero-plus
# edit required paths at the top of the script first
bash examples/LIBERO-plus/eval_files/eval_libero_single.sh
Batch evaluation:
cd /path/to/WorldPilot
mamba activate libero-plus
# edit checkpoint paths, Cosmos files, SUITES, GPUS, and ports
bash examples/LIBERO-plus/eval_files/eval_libero_batch.sh
The public evaluation scripts use a server-style setup:
Cosmos server
cosmos_bridge/run_cosmos_server.sh
|
v
policy server
deployment/model_server/server_policy.py
|
v
LIBERO-Plus simulator workers
socket requests -> policy actions
When debugging inference, separate the problem into three layers: whether the Cosmos server returns priors, whether the policy server loads the WorldPilot checkpoint, and whether simulator workers send observations with the expected shape. Debugging all three at once is slow and misleading.
Paper Results
World Pilot is evaluated on LIBERO, LIBERO-Plus, RoboCasa, and real robots. The headline number is 84.7% Total success rate on the LIBERO-Plus zero-shot OOD benchmark, compared with 80.5% for ABot-M0 and 79.7% for Cosmos Policy in the paper table.
Selected simulation results:
| Method | LIBERO | LIBERO-Plus Total | RoboCasa |
|---|---|---|---|
| ABot-M0 | 98.6 | 80.5 | 54.0 |
| Cosmos Policy | 98.5 | 79.7 | 67.1 |
| World Pilot | 98.5 | 84.7 | 65.5 |
World Pilot does not win every single axis. Its strongest gains appear on camera, light, background, and noise perturbations. On the camera axis, the paper reports 82.8%, a 13.2-point gain over the next strongest baseline. This matches the design intuition: a video-pretrained WAM has broader camera-pose experience, and the scene-evolution latent carries that coverage into the policy.
The real-robot setup includes four tasks:
| Task | ID setting | OOD variants |
|---|---|---|
| Stack Blocks | training-like layout | color, height |
| Fold Towel | training-like towel | direction, novel towel |
| Fruit-to-Plate | training-like fruit/layout | novel fruit, layout |
| Container-Lid Alignment | training-like object/lid | novel object, lid pose |
For each task, the authors collect 100 in-distribution teleoperated demonstrations, fine-tune for 10,000 steps, and run 20 trials per setting and method. World Pilot achieves the highest success rate in every setting. Examples: Stack Blocks reaches 70% ID, 55% OOD color, and 50% OOD height; Fold Towel reaches 85% ID, 75% OOD direction, and 70% novel towel; Fruit-to-Plate reaches 90% ID, 75% novel fruit, and 70% layout; Container-Lid Alignment reaches 80% ID, 70% novel object, and 65% lid pose.
The more important signal is the ID-to-OOD drop. World Pilot typically drops by 10-20 absolute points, while baselines often drop by 25-50 points. For manipulation tasks with tight contact tolerances, that difference matters. Failures often come from a slightly wrong pose or contact trajectory, not from misunderstanding the language instruction.
Ablations: Why This Design Matters
The paper includes four useful ablations.
Each Pathway Helps
| Variant | LIBERO-Plus success |
|---|---|
| ABot-M0 baseline | 80.5 |
| Latent Steering only | 83.7 |
| Action Steering only | 83.1 |
| Full World Pilot | 84.7 |
This shows that scene-evolution priors and trajectory priors are not redundant. Latent Steering improves how the perception stack represents the future scene, while Action Steering gives the action head a soft motion hint.
World Priors Help Even Before Action Fine-Tuning
When Cosmos Policy is replaced by Cosmos-Predict, which only provides future-scene latents, Latent Steering still improves ABot-M0 on LIBERO-Plus, RoboCasa, and RoboTwin2.0 clean. This suggests that large-scale video pretraining already contains useful dynamics priors, even before action-side post-training sharpens them.
Latents Beat Decoded Future Images
Future latents at 1, 3, and 5 denoising steps all land around 84.5-84.7%. A decoded future image reaches 83.5%. This is a good robot-learning lesson: a visually plausible future image is not necessarily the best control representation. A latent can be less interpretable to humans while being cleaner for policy conditioning.
A Single Trajectory Token Beats Stepwise Forcing
The best action-prior form is the single encoded token at 84.7%. Per-step encoded tokens reach 83.6%, flow initialization reaches 84.1%, and raw trajectory conditioning reaches 83.0%. This supports the idea of using the WAM as soft guidance rather than as a hard trajectory oracle.
When Should You Try World Pilot?
World Pilot is worth trying if you already have:
- a working VLA backbone, especially with a diffusion or flow-matching action head;
- manipulation data with clear language labels and action chunks;
- zero-shot OOD failures under camera, appearance, geometry, or pose shifts;
- enough GPU capacity to run an additional WAM online or precompute WAM cache;
- a benchmark such as LIBERO/LIBERO-Plus before moving to a physical robot.
World Pilot is not a universal fix. The paper notes that the policy still inherits the WAM's coverage. If your test scenes fall outside the WAM's video pretraining distribution, the priors can degrade. Each decision step also adds a WAM forward pass, which can be a problem for high-frequency reactive control. The WAM and VLA are connected modularly through the action loss, so the current design does not yet explore deep joint prior-policy co-adaptation.
A Practical Lab Roadmap
If you are in a small robotics lab or startup, do not start by trying to reproduce 84.7%. Use a staged path:
- Run the released checkpoint on one small LIBERO-Plus suite.
- Check that Cosmos server, policy server, and simulator communicate correctly.
- Fine-tune a short run from ABot-M0 pretrain with the published cache.
- Compare ABot-M0 and World Pilot on one or two OOD axes.
- Only then consider a physical robot or a custom dataset.
For a custom robot, the hardest part is usually not the steering code. It is data hygiene: camera synchronization, proprioception, action chunk formatting, gripper state, language labels, reset conditions, and evaluation protocol. World Pilot can provide dynamics priors, but it cannot rescue a noisy dataset.