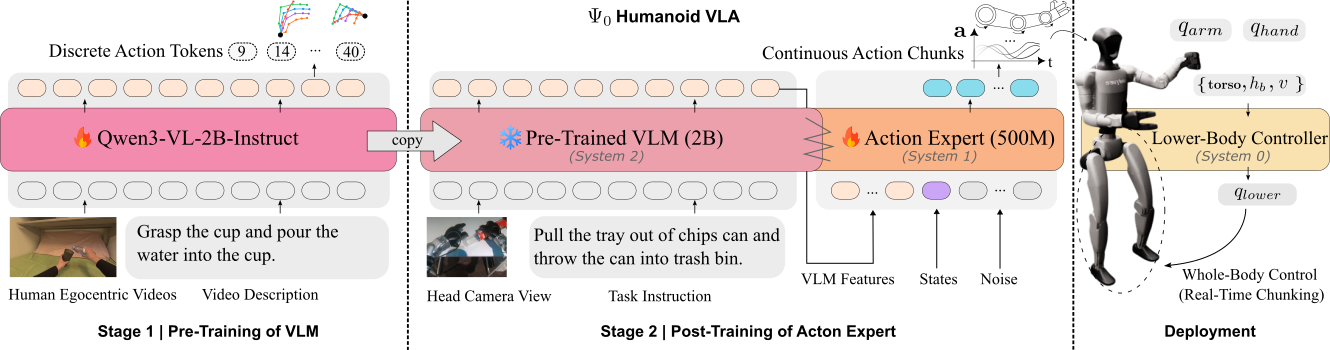
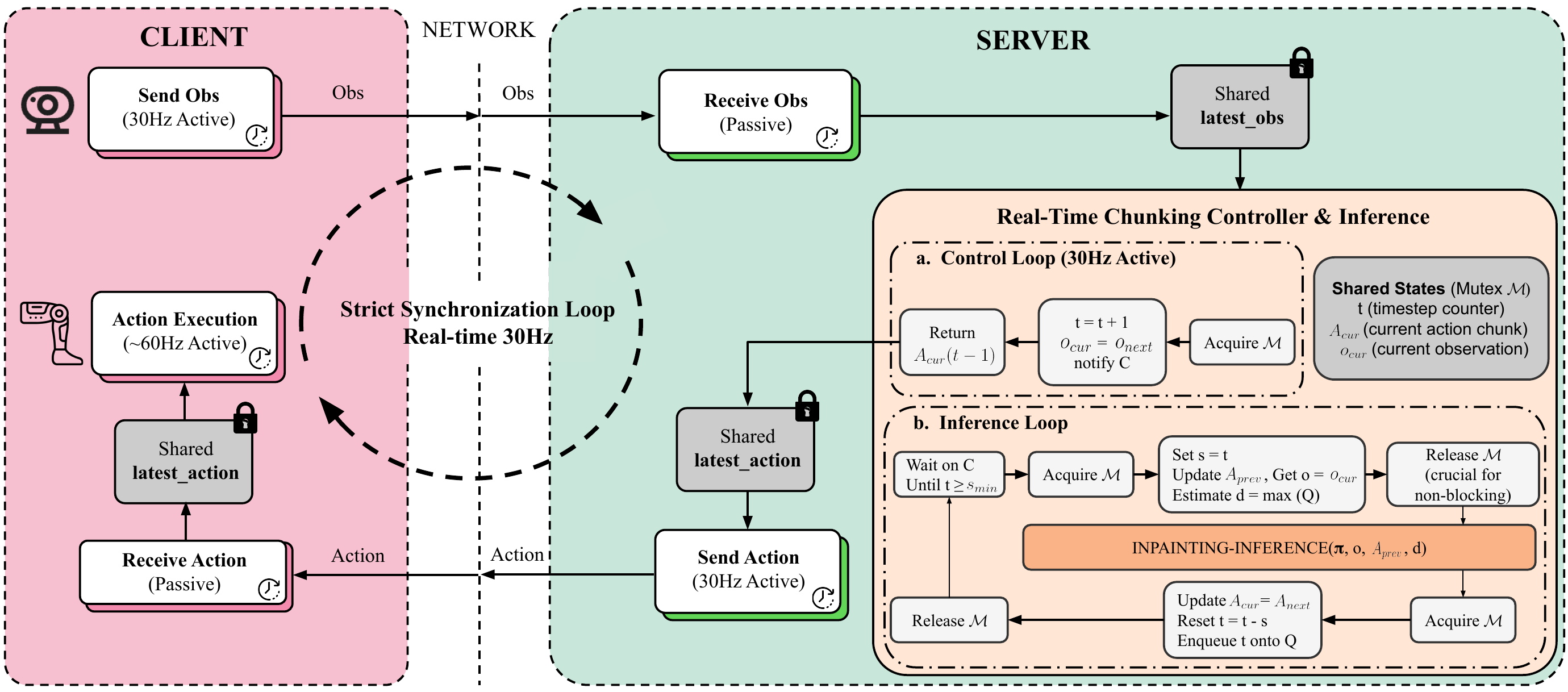
This is the final post in the Psi0 Hands-On series. After 5 posts diving deep into architecture, training, data, and inference — now we step back and ask: what actually matters? Ablation studies are the tool for answering that question. And from the ablation numbers, we'll extract 5 lessons that apply far beyond the Psi0 project.
What is an ablation study? (The supplement analogy)
If you're not familiar with the concept of ablation in machine learning, think of it this way:
You're taking 5 supplements every day and feeling healthier. But you don't know which supplement is actually working. The only way to find out: remove one at a time and see how your health changes. If you drop vitamin D and feel noticeably worse — vitamin D is important. If you drop vitamin B12 and nothing changes — B12 might be unnecessary.
In AI research, ablation studies do exactly this: remove individual components of a system and measure how much performance drops. The component that causes the largest drop when removed = the most important component.
Psi0 has many innovative components: staged training, EgoDex pre-training, MM-DiT architecture, Real-Time Chunking, FAST tokenizer... But which ones actually make the difference? Let's find out.

5 ablation experiments and their results
Ablation 1: No EgoDex pre-training
Removed: The entire Stage 2 — no pre-training on egocentric video data from the EgoDex dataset. The model is trained directly on just 80 robot demonstrations.
Result: Success rate drops dramatically — from an average of 73% down to approximately 25-35% depending on the task. This is the ablation that causes the largest performance drop.
Why? Just 80 demonstrations is far too little for the model to learn good visual-motor representations. EgoDex provides thousands of hours of egocentric video of humans manipulating objects — the model learns "how hands should move when interacting with cups, bottles, and cloths" before it ever sees a robot. Without this foundation, the model is like a new lab student who has never held a tool.
Ablation 2: Only 10% of EgoDex data
Removed: Stage 2 is kept, but only 10% of the EgoDex data is used.
Result: Success rate lands around 50-55% — much better than "no EgoDex," but still 18-20% below the full EgoDex version.
Takeaway: Pre-training data scale matters. Each additional hour of egocentric video improves performance, with no saturation in sight. This suggests that with more EgoDex data, Psi0 could perform even better. This is an encouraging result for the research direction of large-scale egocentric data collection.
Ablation 3: Naive DiT instead of MM-DiT
Removed: The MM-DiT architecture (Multi-Modal DiT with dual-stream attention) is replaced with a simpler Naive DiT — similar to NVIDIA's GR00T N1.6 approach.
Result: Success rate drops by 5-10%. Naive DiT still works, but performs worse on tasks requiring fine-grained coordination between vision and action (e.g., pouring water — needing to continuously watch the water level to adjust the tilt angle).
Why? MM-DiT allows visual tokens and action tokens to "talk to each other" through cross-attention at every layer, rather than just concatenating and self-attending. Think of MM-DiT as a two-lane highway — visual information and action information run in parallel but can "look across" at any time. Naive DiT is like a single-lane road — everything crowds together.
However, the 5-10% improvement shows that architecture is important but not the decisive factor. Data and training methodology matter more.
Ablation 4: No Real-Time Chunking (No RTC)
Removed: RTC is disabled — the robot waits for inference to complete before acting (blocking inference).
Result: Success rate drops by 3-5%, but more importantly: collision rate increases significantly and robot motion becomes jerky and unnatural.
Analysis: RTC doesn't significantly affect "is the model correct" but rather "can the robot actually execute." On slow tasks (handoff), no RTC is still acceptable. But on fast tasks (fill water, pour bottle), the absence of RTC creates 160ms gaps between actions — the robot "freezes" then jumps to the next position, causing oscillation and spills.
Ablation 5: Multi-task training vs single-task
Removed: Instead of fine-tuning 1 separate model per task (8 models), train 1 shared model for all 8 tasks.
Result: The multi-task model performs worse than single-task models by an average of 8-12%. The most difficult tasks (fill_water, pull_tray) show the largest drops.
Why? With only 80 demonstrations per task, each task has just 80 examples — too few for effective multi-task learning. When combining 8 tasks into 1 model (640 demos total), the model suffers from negative transfer: knowledge learned from "wipe bowl" interferes with "pour bottle." Psi0's staged training mitigates negative transfer by pre-training jointly on EgoDex (stage 2) then fine-tuning separately (stage 3), but multi-task fine-tuning still struggles at stage 3.
This is Psi0's biggest trade-off: to achieve high performance, you need 1 separate model per task. This doesn't scale well — 100 tasks = 100 models = 100x compute for fine-tuning.
Ranking each component's contribution
From the 5 ablations above, we can rank contributions:
| Rank | Component | Contribution | When removed |
|---|---|---|---|
| 1 | Staged training (3 stages) | +30-40% | Without stages 2+3 → model is near-random |
| 2 | EgoDex pre-training | +20-30% | No EgoDex → 25-35% success rate |
| 3 | MM-DiT architecture | +5-10% | Naive DiT still works, but weaker on complex tasks |
| 4 | Real-Time Chunking | +3-5% | No RTC → jerky motion, more collisions |
The lesson is clear: data recipe and training strategy matter more than architecture. You can swap MM-DiT for Naive DiT and lose only 5-10%. But if you remove EgoDex pre-training, you lose 30-40%. This conclusion is consistent with much recent research in AI for Robotics.

Detailed comparison with baselines
Psi0 doesn't exist in a vacuum — it competes with numerous other approaches. Let's understand each baseline and why Psi0 comes out ahead.
Comprehensive comparison table
| Model | Architecture | Training data | Avg Success | Strengths | Weaknesses |
|---|---|---|---|---|---|
| Psi0 | VLM + MM-DiT + RL | EgoDex + 80 demos/task | 73% | Staged training, few-shot | Single-task only |
| Pi0.5 | VLM + DiT (co-train) | Cross-embodiment + demos | 65% | Multi-robot support | Negative transfer |
| GR00T N1.6 | Naive DiT | NVIDIA sim data + demos | 58% | Strong sim2real | Naive DiT bottleneck |
| Diffusion Policy | U-Net DDPM | Task-specific demos | 52% | Simple, proven | 100-step inference |
| H-RDT | Transformer | Demos only | 48% | No VLM overhead | Limited perception |
| EgoVLA | VLM + MLP | Ego4D + demos | 45% | Egocentric focus | No flow matching |
| InternVLA-M1 | Large VLM | Internet-scale + demos | 42% | Huge knowledge | Not robot-optimized |
| ACT | VAE + Transformer | Task-specific demos | 38% | Ultra-fast inference | Low capacity |
Why does Psi0 win?
1. Staged training avoids negative transfer. Pi0.5 co-trains the VLM and action expert simultaneously — when VLM gradients update, they inadvertently "break" representations the action expert relies on. Psi0 freezes the VLM at stage 3 and only trains the MM-DiT — much safer.
2. Egocentric video matches the robot camera. EgoVLA also uses egocentric data (Ego4D), but Ego4D contains many activities unrelated to manipulation (cooking, walking, driving). EgoDex is specifically curated for dexterous manipulation — every clip shows a hand interacting with an object. Quality over quantity.
3. MM-DiT — a two-way highway. Compared to Naive DiT (GR00T), MM-DiT enables deeper cross-modal attention. Compared to U-Net (Diffusion Policy), DiT scales better with model size. Compared to MLP heads (EgoVLA), DiT is more expressive for multi-modal action distributions.
4. 80 demonstrations suffice thanks to pre-training. ACT, Diffusion Policy, and H-RDT all need hundreds to thousands of demos per task. Psi0 needs only 80 — because EgoDex pre-training already provides the visual-motor foundation. This is an extremely practical advantage: collecting 80 demos takes a few hours, collecting 1000 demos takes weeks.
5 most important lessons from Psi0
After analyzing ablations and comparing baselines, here are 5 lessons that I believe have value far beyond the Psi0 project.
Lesson 1: Data recipe matters more than data quantity
Psi0 doesn't use the most data — Pi0.5 and InternVLA-M1 have far more. But Psi0 has the right kind of data: egocentric dexterous manipulation video. 1 hour of EgoDex video is worth more than 100 hours of random YouTube robot videos.
Broader application: In any ML project, before collecting more data, ask: "is the new data from the same distribution as deployment?" If you're training a lawn-mowing robot, 10 hours of lawn-mowing video beats 1000 hours of cooking robot video.
Lesson 2: Divide and conquer (3 systems)
Rather than training 1 end-to-end model (pixel → torque), Psi0 divides the problem into 3 specialized systems: VLM for perception, MM-DiT for planning, RL for control. Each system is independently optimized with its own loss function and appropriate data.
Why is this effective? Each system operates at a different frequency: the VLM needs ~160ms/frame (acceptable — humans also see "slowly"), but control needs 16ms/step (reflexes must be fast). Combine them → bottleneck. Separate them → each part runs optimally.
Broader application: When systems are complex, don't try to cram everything into 1 model. Split into modules with clear interfaces, each optimized independently. This is a classic lesson from software engineering that the ML community is re-learning.
Lesson 3: Staged training prevents negative transfer
Training everything simultaneously (joint training/co-training) sounds appealing but often leads to negative transfer — gradients from task A destroy representations for task B. Psi0 solves this with 3 stages: train VLM separately → pre-train MM-DiT on EgoDex → fine-tune MM-DiT on robot data (freeze VLM).
Broader application: If your multi-task model has disappointing performance, try staged training: pre-train jointly → fine-tune separately. Or freeze the backbone → only train the head. Negative transfer is the silent killer of multi-task learning.
Lesson 4: Architecture matters less than you think
MM-DiT improves only 5-10% over Naive DiT. Meanwhile, EgoDex pre-training improves 20-30%. Many researchers spend months designing new architectures for a few percentage points of improvement — when the same time invested in improving the data pipeline could yield far more.
Broader application: Don't get caught in the "architecture lottery" — trying 100 different architectures. Instead: pick a good-enough architecture (Transformer/DiT), then invest your time in data quality, training recipe, and evaluation. This is also the philosophy of modern Imitation Learning.
Lesson 5: Foundation models enable few-shot robotics
80 demonstrations per task — this is an extremely small number in robotics. Previously, 80 demos were only sufficient for the simplest tasks. Psi0 proves that with good foundation model pre-training, 80 demos suffice for complex loco-manipulation on a humanoid robot.
This fundamentally changes the economics of robot learning: collecting 80 demos takes 2-4 hours with teleoperation. Compared to the 1000+ demos previously required (weeks of work), this is a 10-50x improvement. Imagine teaching a robot a new skill in half a day instead of half a month.
Limitations of Psi0: What remains unsolved
Despite being impressive, Psi0 has several limitations that must be acknowledged:
1. Single-task scaling. Each task requires its own model. 100 tasks = 100 models = 100 x 4GB storage + 100 x fine-tuning runs. This is the biggest bottleneck for practical deployment. Pi0.5 handles this better with co-training, though at lower performance.
2. Robot-specific. Psi0 is only demonstrated on the Unitree G1 + Dex3-1. Transferring to a different robot (e.g., Fourier GR-2 or Boston Dynamics Atlas) requires:
- Completely retraining System-0 (RL controller) — because dynamics differ
- Recollecting 80 demos — because camera angle and kinematics differ
- System-1 may partially transfer thanks to EgoDex pre-training, but this hasn't been verified
3. Indoor only. All experiments in the paper take place in a lab with fixed worktables, controlled lighting, and familiar objects. Outdoor deployment (changing light, uneven terrain, novel objects) is an entirely different story.
4. Compute cost. Training the full pipeline (VLM + EgoDex pre-train + fine-tune) requires 8x A100 GPUs for 2-3 days. Inference needs at least 1 A5000 GPU. This is not a system you run on a Raspberry Pi — and that's a major issue for edge deployment in manufacturing.
5. No long-horizon planning. Every task in the paper lasts at most 6 seconds. Real manufacturing tasks (e.g., 20-step assembly) require much longer planning — and Psi0 hasn't demonstrated this capability.

Future research directions
Based on the limitations above, here are research directions I believe have significant potential:
1. More efficient multi-task fine-tuning. Instead of training a separate model per task, use LoRA adapters — each task only adds 1-2% extra parameters. 100 tasks = 1 base model + 100 tiny adapters = a few hundred MB instead of 400GB. This is the direction Pi0 is pursuing.
2. Cross-embodiment transfer. If EgoDex pre-training teaches the model to understand "a hand grasping a cup" from human video, can this knowledge transfer across different robot grippers? Recent research from RT-2 and Octo shows promise.
3. Sim-to-Real with synthetic EgoDex. Instead of collecting real egocentric video, generate it using simulation (Omniverse, SAPIEN) with domain randomization. If successful, pre-training data becomes unlimited.
4. Hierarchical planning + Psi0. Use LLMs (GPT-4, Claude) to decompose long-horizon tasks into short sub-tasks, then call Psi0 for each sub-task. Combine the reasoning power of LLMs with the motor control capabilities of Psi0.
5. On-device inference optimization. Quantize Psi0 to INT4/INT8, prune the model, or use distillation to create a student model that runs on NVIDIA Jetson. This is a mandatory step for deployment in real-world manufacturing.
What have you learned from this series?
If you've followed all 6 posts, you can now:
- Explain the 3-system architecture (System-0/1/2) of Psi0 and why it's more effective than end-to-end
- Understand staged training — why training in 3 phases avoids negative transfer
- Distinguish MM-DiT from Naive DiT and when multi-modal attention matters
- Implement Flow Matching inference — from noise to action via the velocity field
- Configure Real-Time Chunking — 2 asynchronous threads for real-time control
- Evaluate models correctly — closed-loop > open-loop, ablations to understand contribution
- Read and analyze robotics papers — identify strengths, weaknesses, and improvement directions
This isn't just knowledge about Psi0 — it's a critical thinking framework you can apply to any paper in VLA models, Diffusion Policy, or robotics research in general.
Next steps for you
Reproduce the results
# 1. Clone and setup
git clone https://github.com/physical-superintelligence-lab/Psi0.git
cd Psi0 && uv sync
# 2. Download checkpoints
huggingface-cli download psi-lab/psi0-checkpoints --local-dir checkpoints/
# 3. Serve the model
bash scripts/serve_psi0-rtc.sh
# 4. Run SIMPLE eval (requires Docker + GPU)
docker run --gpus all --network host \
psi-lab/simple-eval:latest \
python eval.py --task handoff --num-episodes 10
Start with the handoff task (success rate 9/10) to verify your setup, then try harder tasks like fill_water.
Try your own tasks
If you have access to a Unitree G1 (or any humanoid), the pipeline for adding a new task is:
- Collect 80+ teleoperation demos
- Convert to HDF5 format following the Psi0 standard
- Fine-tune MM-DiT (stage 3) on new demos (~4h on 1x A100)
- Serve and evaluate
Further reading
- Original paper: Psi0: A Foundation Model for Humanoid Loco-Manipulation — USC PSI Lab + NVIDIA
- EgoDex dataset: Check the repository for download links
- SIMPLE simulator: Documentation in the main repo
- Flow Matching theory: Lipman et al., "Flow Matching for Generative Modeling" (ICLR 2023)
- FAST tokenizer: Curtis et al., "FAST: Efficient Action Tokenization for Vision-Language-Action Models" (2024)
Join the community
- GitHub Issues on the Psi0 repo — ask questions, report bugs
- The humanoid robotics community is growing rapidly — follow ICRA, CoRL, and RSS annually
- If you're in Vietnam, connect through the VnRobo community to discuss and share results
Closing thoughts
Psi0 is not a perfect model — it's still single-task, still requires powerful GPUs, and still only works indoors. But it proves something important: the foundation model approach works for humanoid loco-manipulation. With 80 demos and properly staged training, a humanoid robot can learn complex manipulation skills that previously required thousands of demos or hand-crafted controllers.
We are at the early stages of this revolution. Psi0, Pi0, GR00T — each step forward opens new possibilities. And with an open-source codebase, you're not just reading papers — you can run, modify, and improve the work yourself.
See you in the next series.
Related posts
- ACT — Action Chunking with Transformers — A key baseline that Psi0 surpasses
- Dexterous Manipulation — The art of skillful object handling — Context on the dexterous manipulation problem Psi0 addresses
- Embodied AI 2026: The big picture — Where Psi0 fits in the Embodied AI ecosystem