From Image Generation to Robot Control
Diffusion models revolutionized image generation (Stable Diffusion, DALL-E 3). Core idea: start from noise, gradually denoise to produce structured output. But why use it for robots?
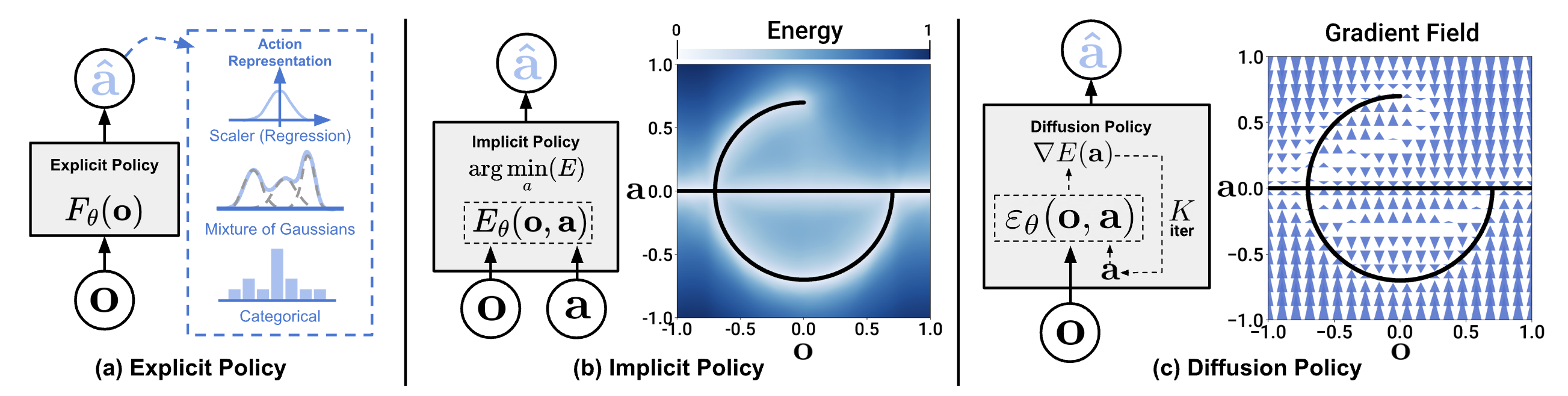
In Part 2, I discussed the multimodal actions problem — when the same observation has multiple correct solutions. Behavioral Cloning with MSE loss averages all modes, producing meaningless "average" actions. ACT uses CVAE to handle this, but Diffusion Policy (Chi et al., 2023) is more powerful: model the entire action distribution using diffusion.
Result? Outperforms all baselines on 12 tasks from 4 benchmarks, with average improvement of 46.9%. This is state-of-the-art for manipulation policy learning.
If you haven't read the Diffusion Policy overview, see Diffusion Policy deep dive in the AI for Robotics series.

DDPM Recap: Denoising Diffusion Probabilistic Models
Forward Process (Adding Noise)
Starting from data x_0, gradually add Gaussian noise over T steps:
q(x_t | x_{t-1}) = N(x_t; sqrt(1-beta_t) * x_{t-1}, beta_t * I)
After T steps, x_T ~ N(0, I) — pure noise. Beta_t is the noise schedule, increasing gradually from ~0.0001 to ~0.02.
Reverse Process (Denoising)
Learn a neural network epsilon_theta to predict noise at each step:
p_theta(x_{t-1} | x_t) = N(x_{t-1}; mu_theta(x_t, t), sigma_t^2 * I)
Training objective: predict the noise that was added:
# DDPM training step (simplified)
def train_step(model, x_0):
# 1. Sample random timestep
t = torch.randint(0, T, (batch_size,))
# 2. Sample noise
epsilon = torch.randn_like(x_0)
# 3. Add noise per schedule
x_t = sqrt_alpha_cumprod[t] * x_0 + sqrt_one_minus_alpha_cumprod[t] * epsilon
# 4. Predict noise
epsilon_pred = model(x_t, t)
# 5. MSE loss
loss = F.mse_loss(epsilon_pred, epsilon)
return loss
From Images to Actions
In image generation, x_0 is pixel values. In Diffusion Policy, x_0 is an action sequence [a_t, a_{t+1}, ..., a_{t+H}] with H as prediction horizon. Conditioning is observations (images + joint positions) instead of text prompts.
Diffusion Policy Architecture
CNN-based (Diffusion Policy - C)
Original architecture uses 1D temporal CNN (like WaveNet) to process action sequences:
Input: noisy action chunk x_t (B, H, action_dim) + timestep t
Condition: observation features (B, obs_dim) from ResNet18
Architecture:
1. FiLM conditioning: inject obs features into each conv layer
2. 1D Conv blocks: [Conv1D -> GroupNorm -> Mish -> Conv1D] x N
3. Residual connections
4. Output: predicted noise epsilon (B, H, action_dim)
Advantages: fast (inference ~10ms), lightweight (~5M parameters), easy to train.
Transformer-based (Diffusion Policy - T)
Replace CNN with Transformer decoder:
Input tokens:
- Noisy action tokens: x_t -> Linear -> (H, d_model)
- Observation tokens: obs -> ResNet18 -> (N_obs, d_model)
- Timestep token: t -> sinusoidal embedding -> (1, d_model)
Transformer Decoder:
- Self-attention on action tokens
- Cross-attention from action to observation tokens
- L layers, d_model=256, 4 heads
Output: predicted noise epsilon (H, action_dim)
Advantages: captures long-range dependencies better, scales well with data.
CNN vs Transformer: When to Use
| Criterion | Diffusion Policy - C | Diffusion Policy - T |
|---|---|---|
| Inference speed | ~10ms | ~50ms |
| Parameters | ~5M | ~20M |
| Data efficiency | Better with < 100 demos | Needs > 200 demos |
| Long-horizon | Limited | Better |
| Training time | Fast (2-4h on 1 GPU) | Slower (6-12h) |
| Recommendation | Default choice | Complex tasks, plenty of data |
Advice: Start with CNN variant. Switch to Transformer only when CNN plateaus and you have enough data.
Diffusion Policy in LeRobot: Hands-on
Setup
# Install LeRobot
pip install lerobot
# Check GPU
python -c "import torch; print(torch.cuda.is_available())"
Train Diffusion Policy on PushT (2D Benchmark)
PushT is a classic benchmark: robot pushes T-shaped object to target pose. Simple but demonstrates Diffusion Policy's power with multimodal actions.
# Download PushT dataset
python -m lerobot.scripts.download_dataset \
--repo-id lerobot/pusht
# Train Diffusion Policy (CNN variant)
python -m lerobot.scripts.train \
--policy.type=diffusion \
--env.type=pusht \
--dataset.repo_id=lerobot/pusht \
--training.num_epochs=5000 \
--training.batch_size=64 \
--policy.n_action_steps=8 \
--policy.n_obs_steps=2 \
--policy.num_inference_steps=100
Important Hyperparameters
# Config explained
policy:
n_obs_steps: 2 # Observation frames as input (2 = current + previous)
n_action_steps: 8 # Actions to execute before replanning (action chunking)
horizon: 16 # Prediction horizon (predict 16, execute 8)
num_inference_steps: 100 # DDPM denoising steps (more = accurate, slower)
# Noise schedule
noise_scheduler:
type: "ddpm" # Or "ddim" (faster, fewer steps)
beta_start: 0.0001
beta_end: 0.02
beta_schedule: "squaredcos_cap_v2" # Cosine schedule (better than linear)
DDIM: Speedup Inference
DDPM needs 100 denoising steps -> too slow for real-time robot control. DDIM (Denoising Diffusion Implicit Models) reduces to 10-20 steps while maintaining quality:
# Switch from DDPM to DDIM in LeRobot config
policy:
noise_scheduler:
type: "ddim"
num_inference_steps: 10 # Reduce from 100 to 10
In practice, DDIM with 10 steps gives ~15ms inference — fast enough for 50Hz control loops.

Benchmark Results
PushT (2D)
| Method | Success Rate |
|---|---|
| BC (MLP) | 58.7% |
| BC (Transformer) | 63.2% |
| IBC (Implicit BC) | 62.4% |
| BET (BeT) | 65.8% |
| Diffusion Policy - C | 88.7% |
| Diffusion Policy - T | 85.3% |
RobomiMic (Simulated Manipulation)
| Task | BC-RNN | IBC | Diffusion-C | Diffusion-T |
|---|---|---|---|---|
| Lift | 100% | 96% | 100% | 100% |
| Can | 92% | 84% | 96% | 95% |
| Square | 82% | 68% | 92% | 92% |
| Transport | 46% | 32% | 78% | 74% |
| Tool Hang | 18% | 12% | 56% | 52% |
Diffusion Policy dominates, especially on hard tasks (Transport, Tool Hang) where multimodal actions matter.
Why is Diffusion Policy Powerful?
1. Handles Multimodal Actions Naturally
When many ways to complete task (push T from left or right), BC averages them -> meaningless action. Diffusion model learns full distribution, samples one specific mode, executes consistently.
2. High Expressiveness
Diffusion process can model any distribution, not limited by parametric assumptions (like Gaussians in VAEs). Important for complex manipulation trajectories.
3. Training Stability
No mode collapse like GANs, no posterior collapse like VAEs. Training objective (predict noise) is simple and stable.
4. Action Chunking Built-in
Predict entire action chunks at once, reduces compounding error like ACT, but with more powerful generation method.
Practical Tips
Training
- Cosine noise schedule better than linear for action sequences
- EMA (Exponential Moving Average) of model weights: mandatory, use decay=0.995
- Gradient clipping: max_norm=1.0, prevents explosion
- Learning rate: 1e-4 with AdamW, cosine decay
Real Robot Inference
- Use DDIM with 10 steps for real-time
- Temporal ensembling (like ACT): average overlapping chunks
- Action clipping: bound actions to safe range before sending to robot
- Latency compensation: predict ahead 1-2 steps to compensate
Debugging
- Visualize denoising: plot action trajectory at each denoising step — should converge
- Check action distribution: histogram predicted vs dataset actions — should match
- Overfit on 1 episode first: if can't overfit, there's a bug
Diffusion Policy vs ACT: Which to Choose?
| Criterion | ACT | Diffusion Policy |
|---|---|---|
| Multimodal | CVAE (limited modes) | Full distribution |
| Speed | Fast (~5ms) | Slower (~15ms DDIM) |
| Data efficiency | Excellent (50 demos) | Good (50-100 demos) |
| Long-horizon | Good | Better |
| Implementation | Complex (CVAE) | Medium |
| Best for | Bimanual, limited data | Complex tasks, more data |
Choose ACT when: limited data (<50 demos), need fast inference, bimanual tasks. Choose Diffusion Policy when: complex task, multimodal, enough data, 50Hz is sufficient.
Next in Series
- Part 4: VLA for Manipulation: RT-2, Octo, pi0 in Practice — Foundation models for manipulation
- Part 5: Dexterous Manipulation: Teaching Robot Hands — When 2 fingers aren't enough
Related Articles
- Imitation Learning for Manipulation: BC, DAgger, ACT — Part 2 of this series
- Diffusion Policy Deep Dive — Detailed theory
- VLA Models: RT-2, Octo, OpenVLA — Foundation models using Diffusion Policy
- Building Manipulation Systems with LeRobot — Deploy Diffusion Policy to real robot


