Imagine you've taught a robot to pick up objects. Now you want it to pour water from a bottle — but you have zero demo recordings of that skill. Do you re-record from scratch? Hire a teleoperator? Or can the robot figure it out from what it already knows?
That's exactly the problem Stanford's InSight: Self-Guided Skill Acquisition via Steerable VLAs (arXiv 2606.24884, June 2026) addresses — and it does so elegantly.
The Problem: VLAs Are Capped by Their Training Data
Vision-Language-Action (VLA) models like π0 and π0.5 have proven they can learn manipulation from demonstrations. But they all share a fundamental limitation: you cannot ask the robot to do anything outside its training distribution. Want a new skill? Collect new demos → expensive, time-consuming, operator-dependent.
This is the biggest bottleneck in real-world robotics deployment. The robot's skill inventory is frozen at training time.
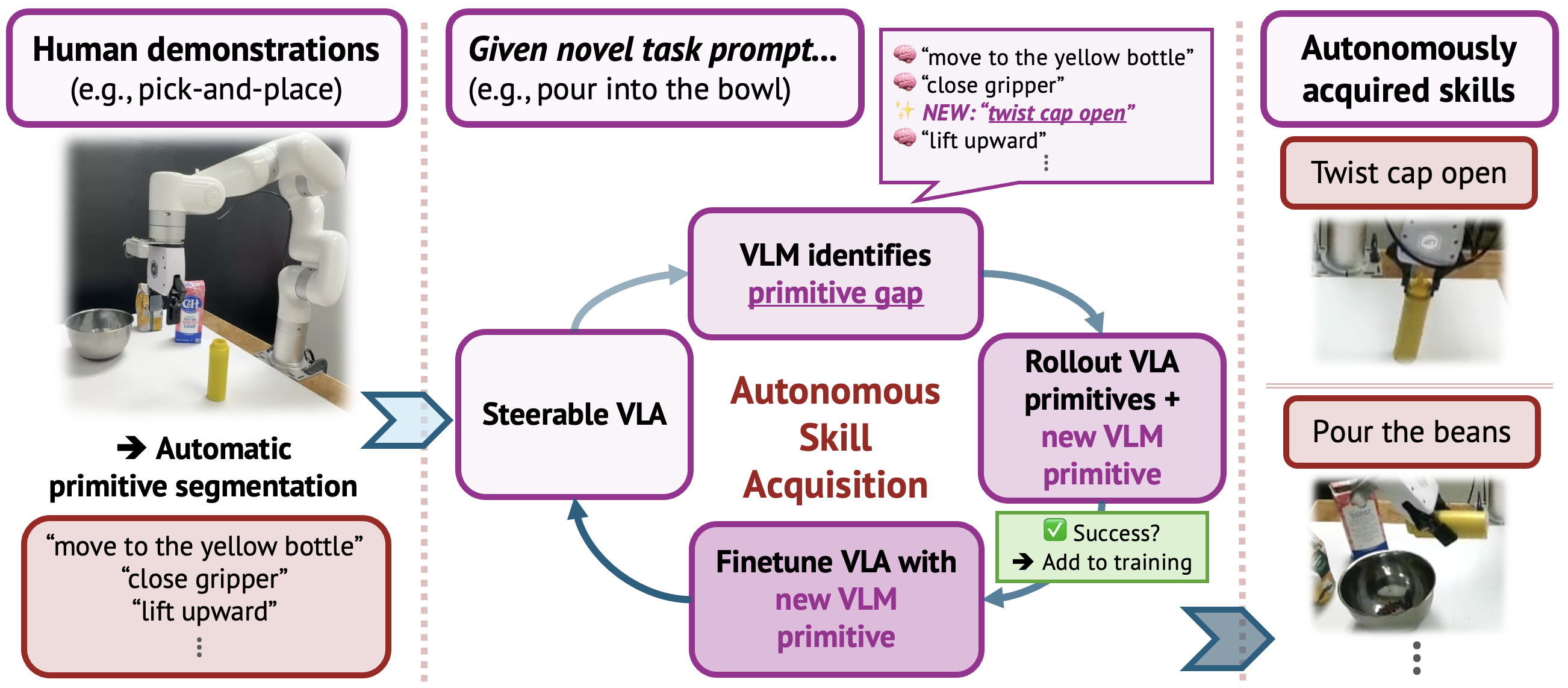
InSight attacks this directly with a key observation: manipulation skills are inherently compositional. "Pouring" isn't an entirely new skill — it's "move gripper to bottle", "grasp bottle", "tilt along Y-axis", "return to upright". If the robot already knows some primitives, it only needs to acquire the missing ones and compose them.
Core Idea: Steerable VLA
InSight doesn't replace the VLA — it makes the VLA controllable at the primitive-action level.
Instead of prompting "grab the bowl and pour it into the cup", you can tell the robot:
"move gripper to bowl"→ robot only executes that move"lift upward"→ robot only lifts"tilt along Y-axis"→ robot only tilts
When the VLA accepts commands at individual primitive granularity, an external VLM (Gemini) can orchestrate entire task chains in natural language — and simultaneously identify which primitives are missing.
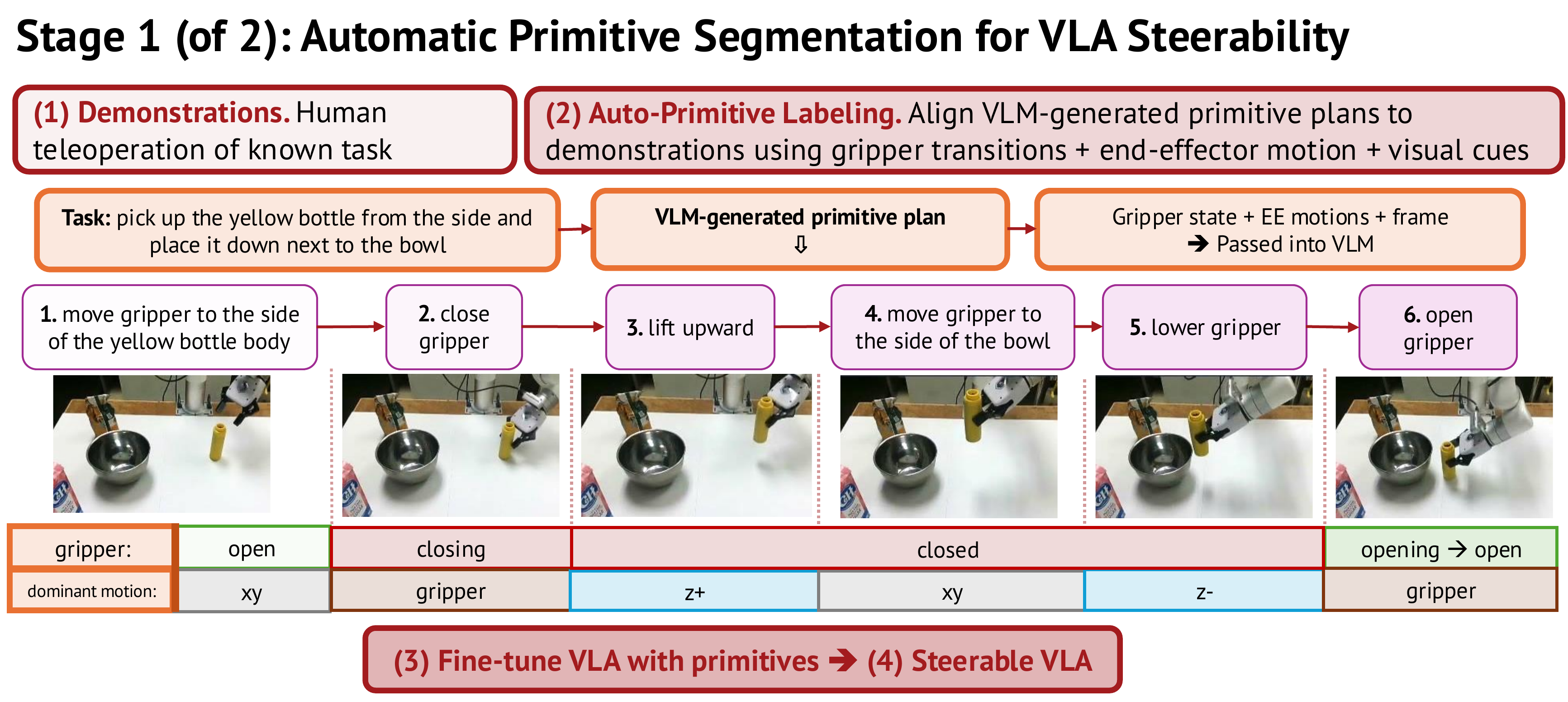
Stage 1: Automatic Primitive Segmentation
To train a steerable VLA, you need demonstration data labeled at the primitive level. But standard demo datasets only label at the task level ("pick and place the apple"). InSight solves this with an automatic segmentation pipeline.
How segmentation works
The pipeline runs in three steps:
Step 1 — VLM decomposition: Given an instruction like "open drawer then grasp object", the VLM (Gemini 3 Flash) decomposes it into a primitive sequence: ["reach to handle", "pull backward", "move to object", "grasp"].
Step 2 — Per-frame end-effector tagging: The system analyzes the end-effector trajectory, computes per-frame delta poses, and assigns a dominant motion axis tag: xy (horizontal movement), z (vertical), rxy (rotation in horizontal plane), rz (rotation around vertical axis). This distinguishes "lift up" from "reach forward" without any manual annotation.
Step 3 — Boundary refinement: Gripper open/close transitions (detected from gripper command velocity) are used to cut segments at visually unambiguous transitions — for example, the exact moment the gripper closes is the boundary between "reach" and "grasp".
Result: each demonstration is sliced into short labeled episodes, one per primitive. These become training data for the steerable VLA.
The progress channel — smart termination
A key technical point: each primitive needs to know when to stop. InSight adds a progress channel to the VLA output — a value in [0, 1) supervised by the normalized timestep within each primitive segment. When progress exceeds 0.95, the primitive is considered complete and the system moves to the next one.
There's also auto-advance based on end-effector motion stillness, and VLM completion checks for more complex primitives.
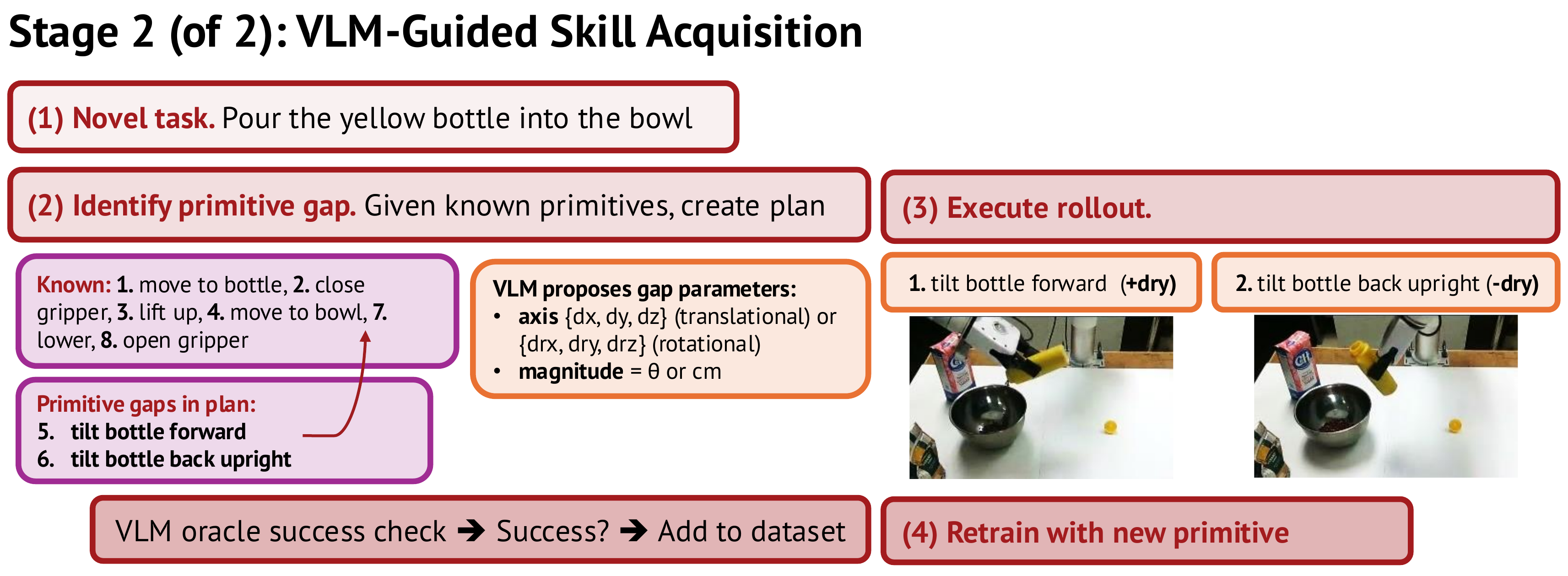
Stage 2: VLM-Guided Skill Acquisition Flywheel
This is where the autonomous learning actually happens.
Identifying primitive gaps
When given a novel task — say "twist the cap then pour the bottle" — the VLM decomposes the task into its required primitive sequence and compares against vocabulary V (the list of primitives the robot already knows). Any primitive not in V is a "primitive gap".
Important design choice: InSight constrains primitive gaps to single-axis motion only (translation along one of dx/dy/dz, or rotation along one of drx/dry/drz). This isn't a limitation — it's a deliberate design that makes the problem tractable. The vast majority of real manipulation primitives decompose naturally into single-axis motions.
Autonomous execution and verification
For each primitive gap, the VLM analyzes the current scene (via camera) and proposes parameters:
- Axis: which direction to move?
- Magnitude: how much, and in which sign?
The robot attempts the primitive with these proposed parameters. Afterward, a VLM oracle compares "before" and "after" images to verify whether the primitive succeeded.
Success → the episode gets added to the training dataset.
Retraining with new data
After accumulating N successful rollouts for a new primitive, the VLA is retrained via LoRA — jointly on existing and new primitives. LoRA (Low-Rank Adaptation) allows fast fine-tuning of a small fraction of weights, preventing catastrophic forgetting of previously learned skills.
Technical Details
| Component | Details |
|---|---|
| Base VLA | π0.5 (architecture-agnostic) |
| Fine-tuning | LoRA on Gemma-2B backbone + Gemma-300M action expert |
| VLM | Gemini 3 Flash (4 roles: segmentation, planning, gap ID, verification) |
| Input | 2x 224×224 RGB cameras (scene + wrist) + end-effector pose + gripper state |
| Output | End-effector deltas + gripper command + progress channel [0,1) |
| Real hardware | xArm 6 + Intel RealSense cameras |
| Stack | Python 3.11 + JAX/Flax + uv package manager |
InSight is VLA-agnostic — in principle, it can be applied to any VLA that supports primitive-level language conditioning, not just π0.5.
Experimental Results
Real robot (xArm 6)
This is the most impressive part. InSight learns entirely new skills from zero human demos:
| New skill acquired | InSight success | Best baseline (CaP-X) |
|---|---|---|
| Twist (cap rotation) | 92% | 32% |
| Pour (bottle tilting) | 96% | 16% |
| Twist-then-pour (14 primitives) | 80% | 4% |
| Sweep (from scooping demos) | 100% (5/5) | — |
Acquisition efficiency:
- Twist: 20 successful primitives in 23 trials (~62s robot time per trial)
- Pour: 20 successful primitives in 31 trials (~96s robot time per trial)
Skill retention: After learning twist and pour, the robot still achieves 100% on the original pick-and-place tasks. Zero catastrophic forgetting.
Speed advantage: InSight completes twisting ~2× faster than CaP-X (55s vs 109s) because it doesn't need to query the VLM at every timestep like a pure planner does.
Simulation results
Block flipping (learned from pick-and-place demos):
- InSight: 75% after 246 successful primitive rollouts / 479 attempts
- SAC (RL baseline): 0% — RL only managed to learn reaching (23%) and grasping (10%) within the same compute budget
Drawer closing (learned from drawer-opening demos, out-of-distribution initial states):
- Collected 70 successful close-drawer primitives across 82 episodes
- Retrained VLA: 100% success on both closing and opening tasks (25 trials)
This last result is notable: the robot learns the "inverse" of a skill it already knows, without any human demos of the inverse.
Installation and Usage
Requirements
# Python 3.11 + uv package manager
pip install uv
# Clone repo
git clone https://github.com/insight-vla/insight
cd insight
git submodule update --init --recursive
# Install dependencies
uv sync
uv sync --group rlds # optional RLDS support
Compute normalization statistics
Before training, compute normalization stats on your dataset:
uv run python training/compute_norm_stats.py --config-name [config_name]
Training the steerable VLA (Stage 1)
uv run python training/train.py [config_name] \
--exp-name=my_run \
--batch-size 32 \
--fsdp-devices 2
Training uses JAX/Flax with FSDP (Fully Sharded Data Parallelism) — minimum 2 GPUs. This fine-tunes π0.5 with LoRA on the auto-segmented primitive dataset.
Serving the policy for inference
uv run python training/serve_policy.py policy:checkpoint \
--policy.config [config_name] \
--policy.dir [checkpoint_path]
The policy is served via API. The Gemini-based VLM pipeline calls this API to control individual primitives during task execution.
Real robot hardware
To run on a physical robot:
- xArm 6 (or compatible) with xArm SDK
- Intel RealSense D435 (scene camera) + wrist camera
- E-stop device (REQUIRED for safety)
- Configure workspace bounds in your config file
Limitations and Open Problems
InSight has a few honest limitations worth noting:
-
Human resets still required: After failed primitive rollouts, a human must reset the environment. The paper acknowledges this and suggests future work via real-to-sim-to-real pipelines or learned world models.
-
Single-axis primitive constraint: While most real manipulation decomposes naturally, highly dexterous in-hand manipulation with simultaneous multi-axis motion is harder to fit this framework.
-
VLM quality dependency: Gemini 3 Flash plays four critical roles. If the VLM plans incorrectly or verifies incorrectly, the flywheel can accumulate low-quality primitives.
-
Acquisition time: Each new primitive requires ~20-30 trials (~1-2 hours of robot time). More complex skills may need more.
Why InSight Matters
InSight lays a practical foundation for continual learning in robotics — more pragmatic than pure RL because it uses natural language as the abstraction layer for defining and verifying skills, rather than requiring carefully designed reward functions.
Comparison to other approaches:
| Approach | Pros | Cons |
|---|---|---|
| Collect new demos | High quality | Expensive, operator-dependent |
| RL from scratch | No demos needed | Sample-inefficient, hard reward design |
| CaP-X (VLM planning) | Flexible | VLM per step → slow, doesn't learn |
| InSight | Self-improving, composable, fast | Needs human resets, single-axis gap |
With its architecture — steerable VLA + VLM orchestration + LoRA retraining — InSight points toward robots that can autonomously expand their skill inventory over time in real deployment environments. That's a meaningful step toward robots that get better at their jobs just by doing them.
For more on fine-tuning VLAs for specific tasks, see Fine-tuning VLA on LIBERO with Embodied-R1.5. For a deep dive on the VLA architecture itself, OpenVLA Deep Dive covers the backbone in detail.
If you're interested in how world models complement VLAs, Weaver: World Models for π0.5 Manipulation is a natural companion read.