Hãy tưởng tượng bạn đã dạy một robot cách nhặt đồ vật. Giờ bạn muốn nó biết cách đổ nước từ chai — nhưng bạn không có một video demo nào cho kỹ năng này. Phải ghi lại từ đầu? Phải thuê người tele-op? Hay robot có thể tự mày mò và học được từ những gì nó đã biết?
Đây chính xác là bài toán mà nhóm nghiên cứu tại Stanford University giải quyết trong paper InSight: Self-Guided Skill Acquisition via Steerable VLAs (arXiv 2606.24884, tháng 6/2026).
Vấn Đề: VLA Bị "Trần" Bởi Training Data
Vision-Language-Action (VLA) models như π0, π0.5 đã chứng minh khả năng học manipulation từ dữ liệu demo. Nhưng tất cả đều có cùng một giới hạn: bạn không thể hỏi robot làm thứ gì đó nằm ngoài training data. Muốn thêm kỹ năng mới → phải thu thập demo mới → tốn thời gian, tốn chi phí, tốn công tele-operation.
Đây là bottleneck lớn nhất trong robotics thực tế. Kho kỹ năng của robot bị đóng băng tại thời điểm training.
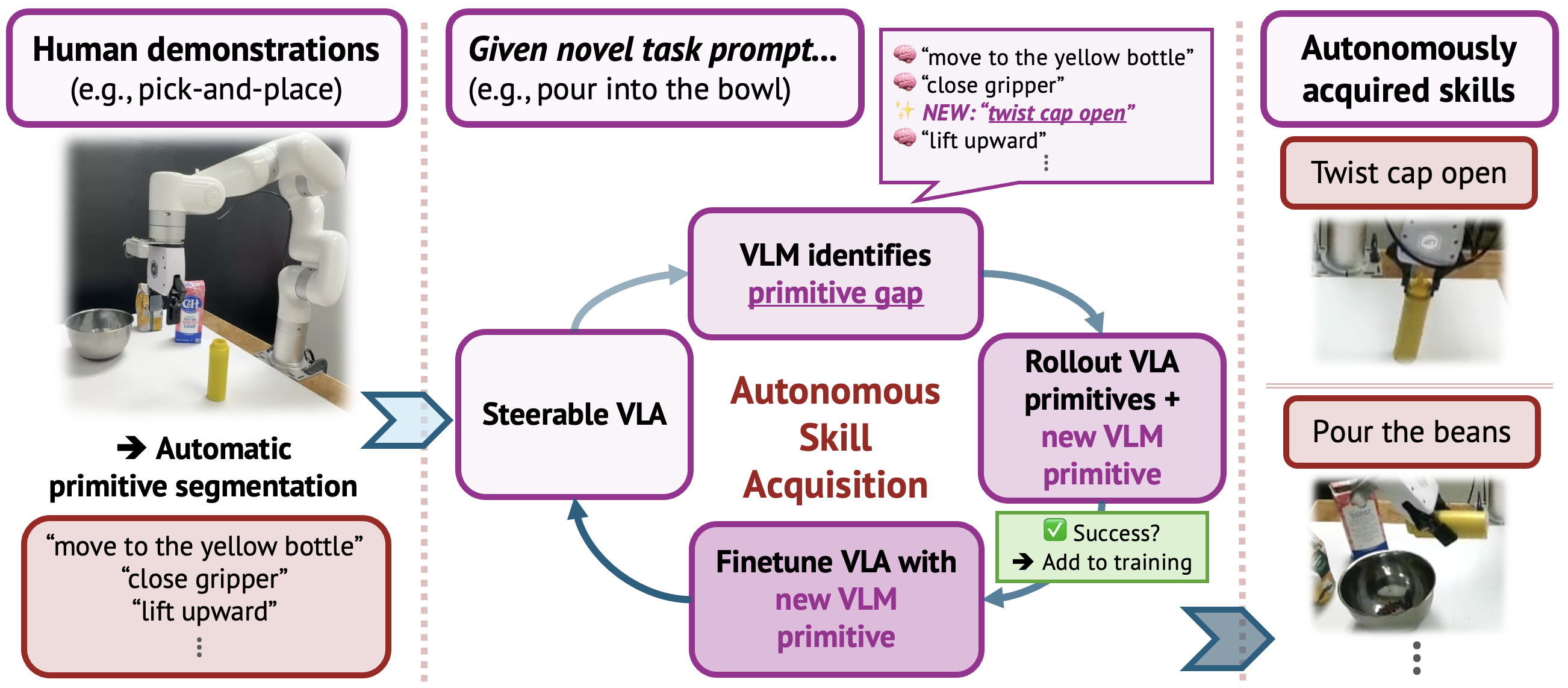
InSight tấn công trực tiếp vào điểm yếu này với một quan sát thực tế: kỹ năng manipulation về bản chất là compositional. "Đổ nước" không hoàn toàn là kỹ năng mới — nó gồm "di chuyển gripper đến chai", "nắm chai", "nghiêng chai theo trục Y", v.v. Nếu robot đã biết một số primitive từ trước, nó chỉ cần học thêm vài primitive còn thiếu rồi ghép lại.
Ý Tưởng Cốt Lõi: Steerable VLA
InSight không thay thế VLA — nó làm cho VLA có thể điều khiển ở cấp độ primitive action.
Thay vì prompt "Grab the bowl and pour it into the cup", bạn có thể nói với robot:
"move gripper to bowl"→ robot chỉ thực hiện bước di chuyển đó"lift upward"→ robot chỉ nâng lên"tilt along Y-axis"→ robot chỉ nghiêng
Khi VLA có thể nhận lệnh ở từng primitive riêng lẻ, một VLM bên ngoài (như Gemini) có thể orchestrate cả chuỗi task bằng ngôn ngữ tự nhiên, và đồng thời nhận dạng primitive nào đang bị thiếu.
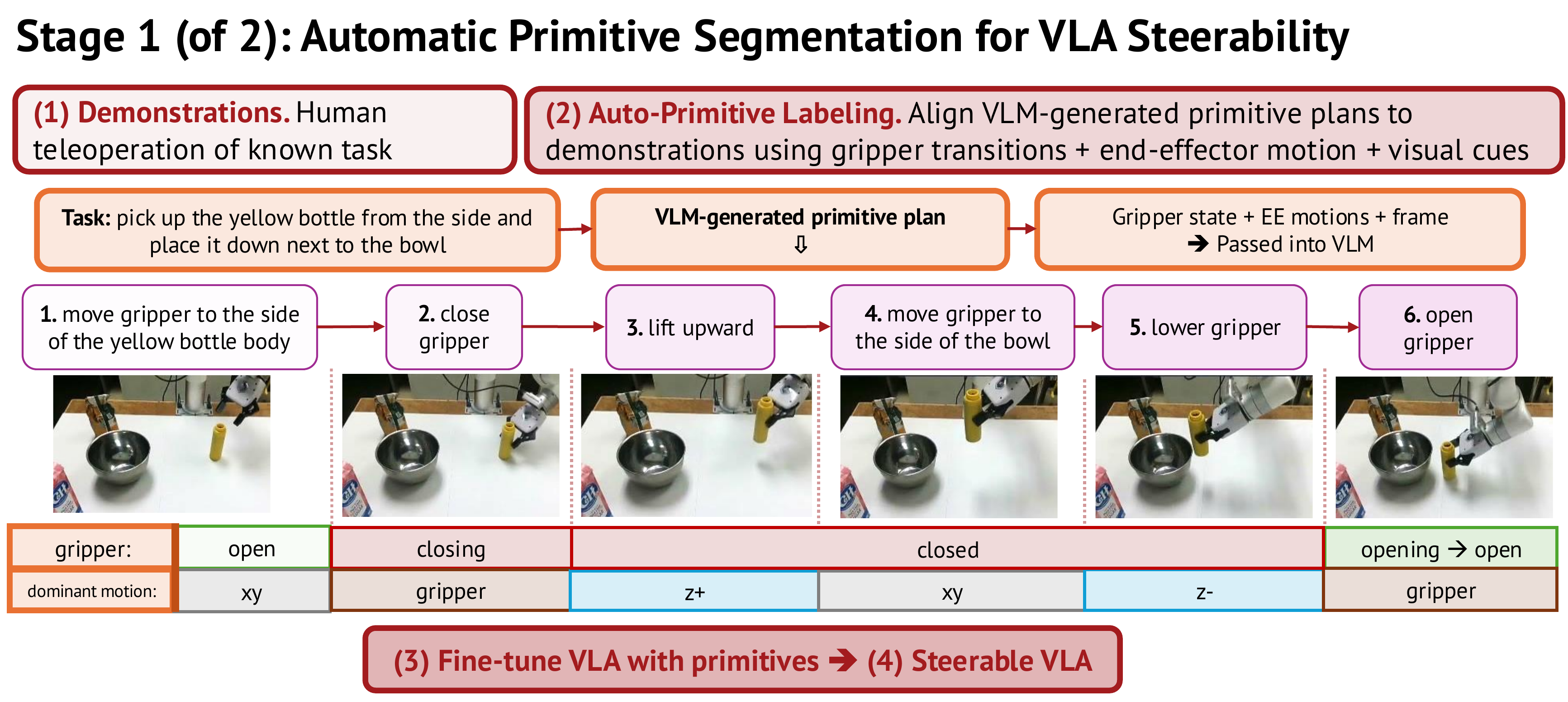
Stage 1: Phân Tích Primitive Tự Động
Để train một "steerable VLA", bạn cần dữ liệu training được gán nhãn theo từng primitive. Nhưng các dataset demo thông thường chỉ có label ở cấp task (ví dụ: "pick and place the apple"). InSight giải quyết bằng một pipeline phân tích tự động.
Cơ chế phân đoạn
Pipeline hoạt động theo 3 bước:
Bước 1 — Decompose bằng VLM: Với một instruction như "open drawer then grasp object", VLM (Gemini 3 Flash) sẽ phân tích thành chuỗi primitive: ["reach to handle", "pull backward", "move to object", "grasp"].
Bước 2 — Gán nhãn per-frame bằng end-effector motion: Hệ thống phân tích trajectory của end-effector, tính toán delta pose mỗi frame, và gán dominant motion axis: xy (di chuyển ngang), z (lên/xuống), rxy (xoay trong mặt phẳng ngang), rz (xoay quanh trục dọc). Đây là cách phân biệt "nâng lên" vs "vươn tới" mà không cần annotation thủ công.
Bước 3 — Tinh chỉnh ranh giới: Gripper open/close transitions (phát hiện từ gripper command velocity) được dùng để cắt segment tại các điểm chuyển tiếp rõ ràng — ví dụ, thời điểm gripper đóng lại để nắm vật chính xác là ranh giới giữa "reach" và "grasp".
Kết quả: mỗi demo bị cắt thành nhiều episode ngắn, mỗi episode được gán label là một primitive. Những episode này trở thành training data cho steerable VLA.
Progress channel — cơ chế dừng thông minh
Một điểm kỹ thuật quan trọng: mỗi primitive cần biết khi nào thì dừng. InSight thêm một progress channel vào output của VLA — một giá trị trong [0, 1) được supervised bằng normalized timestep trong primitive segment. Khi progress vượt ngưỡng 0.95, primitive đó coi là hoàn thành và hệ thống chuyển sang primitive tiếp theo.
Ngoài ra còn có auto-advance dựa trên end-effector motion (nếu gripper không di chuyển nhiều trong N frames, coi primitive đã xong) và VLM completion check cho các primitive phức tạp hơn.
Stage 2: VLM-Guided Skill Acquisition Flywheel
Đây là phần "tự học" thực sự của InSight.
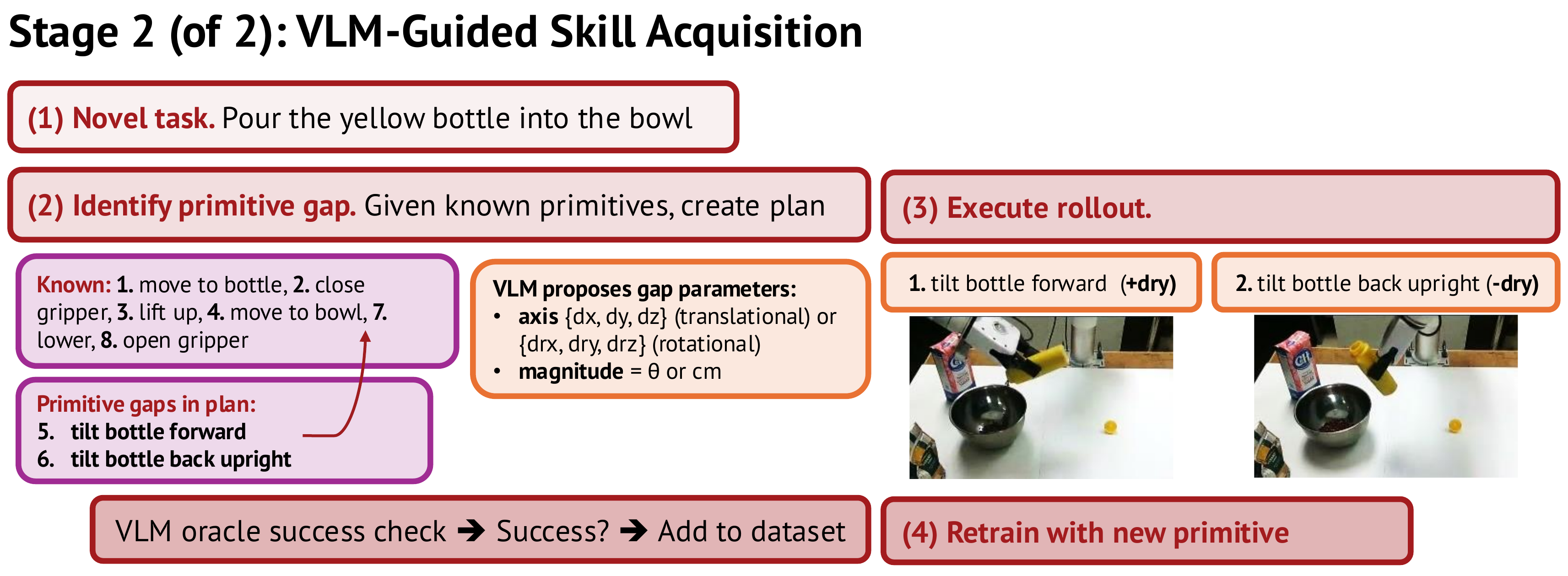
Nhận diện "primitive gap"
Khi giao cho robot một task mới — ví dụ "twist the cap then pour the bottle" — VLM phân tích task này thành chuỗi primitive cần thiết và so sánh với vocabulary V (danh sách primitive robot đã biết). Bất kỳ primitive nào chưa có trong V → đó là "primitive gap".
Quan trọng: InSight giới hạn primitive gap chỉ là single-axis motion (tịnh tiến theo một trục dx/dy/dz, hoặc xoay theo một trục drx/dry/drz). Giới hạn này không phải hạn chế — đây là design choice thông minh để bài toán tractable. Hầu hết primitive manipulation thực tế đều có thể phân tích thành single-axis.
Tự thực hiện và verify
Với mỗi primitive gap, VLM phân tích scene hiện tại (qua camera) và đề xuất tham số:
- Axis: trục nào cần di chuyển?
- Magnitude: bao nhiêu? Chiều nào?
Robot tự thực hiện theo tham số được đề xuất. Sau khi thực hiện xong, một VLM oracle so sánh ảnh "trước" và "sau" để verify xem primitive có thành công không.
Nếu thành công → episode này được thêm vào training dataset.
Retrain với dữ liệu mới
Sau khi tích lũy đủ N rollout thành công cho primitive mới, VLA được retrain bằng LoRA — kết hợp cả primitive cũ và primitive mới. LoRA (Low-Rank Adaptation) cho phép fine-tune nhanh chỉ một phần nhỏ weights, tránh catastrophic forgetting trên kỹ năng đã học.
Chi Tiết Kỹ Thuật
| Component | Chi tiết |
|---|---|
| VLA nền | π0.5 (có thể thay bằng VLA khác) |
| Fine-tuning | LoRA trên Gemma-2B backbone + Gemma-300M action expert |
| VLM | Gemini 3 Flash (4 vai trò: segmentation, planning, gap ID, verification) |
| Input | 2 camera 224×224 RGB (scene + wrist) + end-effector pose + gripper state |
| Output | End-effector deltas + gripper command + progress channel [0,1) |
| Hardware thực tế | xArm 6 + Intel RealSense cameras |
| Language | Python 3.11 + JAX/Flax + uv package manager |
InSight là VLA-agnostic — về lý thuyết có thể áp dụng cho bất kỳ VLA nào hỗ trợ primitive-level conditioning, không bắt buộc phải dùng π0.5.
Kết Quả Thực Nghiệm
Trên robot thực (xArm 6)
Đây là phần ấn tượng nhất. InSight học các kỹ năng hoàn toàn mới từ zero demo của người:
| Kỹ năng mới học | Thành công InSight | Baseline tốt nhất (CaP-X) |
|---|---|---|
| Twist (xoay nắp) | 92% | 32% |
| Pour (đổ nước) | 96% | 16% |
| Twist-then-pour (14 primitives) | 80% | 4% |
| Sweep (quét từ scoop demos) | 100% (5/5) | — |
Hiệu quả thu thập:
- Twist: 20 successful primitives trong 23 trials (62 giây robot time mỗi trial)
- Pour: 20 successful primitives trong 31 trials (96 giây robot time mỗi trial)
Giữ kỹ năng cũ: Sau khi học twist + pour, robot vẫn đạt 100% trên pick-and-place ban đầu. Không có catastrophic forgetting.
Tốc độ: InSight hoàn thành twist nhanh hơn ~2× so với CaP-X (55 giây vs 109 giây) vì không cần query VLM mỗi bước như planner.
Trên simulation
Block flipping (từ pick-and-place demos):
- InSight: 75% sau 246 successful primitives / 479 attempts
- SAC (RL baseline): 0% — RL chỉ học được reaching (23%) và grasping (10%) trong cùng ngân sách
Drawer closing (từ drawer-opening demos, out-of-distribution initial state):
- Thu thập 70 successful close-drawer primitives trong 82 episodes
- VLA retrained: 100% success trên cả close và open drawer (25 trials)
Đây là kết quả đáng chú ý: robot học từ "nghịch đảo" của kỹ năng đã biết. Nếu đã biết mở hộc tủ, InSight giúp nó tự học đóng mà không cần demo đóng.
Cài Đặt và Sử Dụng
Yêu cầu
# Python 3.11, uv package manager
pip install uv
# Clone repo
git clone https://github.com/insight-vla/insight
cd insight
git submodule update --init --recursive
# Cài dependencies
uv sync
uv sync --group rlds # nếu cần RLDS support
Tính toán normalization statistics
Trước khi train, bạn cần tính normalization stats trên dataset của mình:
uv run python training/compute_norm_stats.py --config-name [config_name]
Training steerable VLA (Stage 1)
uv run python training/train.py [config_name] \
--exp-name=my_run \
--batch-size 32 \
--fsdp-devices 2
Training dùng JAX/Flax với FSDP (Fully Sharded Data Parallelism) — cần ít nhất 2 GPU. Về cơ bản đây là fine-tune π0.5 với LoRA trên dataset đã được phân tích primitive.
Deploy policy để inference
uv run python training/serve_policy.py policy:checkpoint \
--policy.config [config_name] \
--policy.dir [checkpoint_path]
Policy được serve qua API, và VLM pipeline (Gemini) sẽ gọi API này để điều khiển từng primitive trong quá trình thực thi task.
Hardware thực tế
Để chạy trên robot thực:
- xArm 6 (hoặc tương tự) với xArm SDK
- Intel RealSense D435 (scene camera) + wrist camera
- E-stop device (BẮT BUỘC cho safety)
- Cấu hình workspace bounds trong config
Hạn Chế và Hướng Phát Triển
InSight có một số hạn chế đáng lưu ý:
-
Human reset vẫn cần thiết: Sau mỗi primitive rollout thất bại, con người phải reset environment. Paper thừa nhận đây là limitation và đề xuất hướng giải quyết qua real-to-sim-to-real pipelines hoặc learned world models.
-
Primitive gap bị giới hạn single-axis: Hầu hết kỹ năng thực tế đều decompose được, nhưng các kỹ năng đòi hỏi multi-axis motion phức tạp (như dexterous in-hand manipulation) vẫn khó.
-
Phụ thuộc VLM quality: Gemini 3 Flash đóng vai trò quan trọng trong cả 4 bước. Nếu VLM plan sai hoặc verify sai, flywheel có thể học primitive kém chất lượng.
-
Tốc độ thu thập: Mỗi primitive mới cần ~20-30 trial (khoảng 1-2 giờ robot time). Với kỹ năng phức tạp hơn, con số này có thể cao hơn.
Tại Sao InSight Quan Trọng?
InSight đặt nền móng cho continual learning trong robotics theo cách thực tế hơn reinforcement learning thuần. Thay vì reward shaping phức tạp, nó dùng ngôn ngữ tự nhiên như abstraction layer để định nghĩa kỹ năng cần học và verify kết quả.
So với các hướng tiếp cận khác:
| Hướng | Ưu điểm | Nhược điểm |
|---|---|---|
| Thu thập demo mới | Chất lượng cao | Tốn người, tốn thời gian |
| RL từ scratch | Không cần demo | Sample inefficient, reward design khó |
| CaP-X (planning) | Linh hoạt | Query VLM mỗi step → chậm, không học được |
| InSight | Tự học, composable, nhanh | Cần human reset, single-axis gap |
Với kiến trúc hiện tại — steerable VLA + VLM orchestration + LoRA retraining — InSight mở ra hướng robot có thể tự mở rộng kho kỹ năng theo thời gian trong môi trường triển khai thực tế.
Bạn có thể theo dõi thêm về cách fine-tune VLA cho task cụ thể trong bài Hướng dẫn fine-tune VLA trên LIBERO với Embodied-R1.5, hoặc hiểu sâu hơn về OpenVLA — kiến trúc và training pipeline.
Đối với những ai quan tâm đến cách world model hỗ trợ VLA, bài Weaver: World Model cho π0.5 VLA Manipulation sẽ là góc nhìn bổ sung thú vị.