Series: AI Agent Pipeline for Robot Manipulation — Part 4/5
When a Robot Gets Stuck Mid-Task
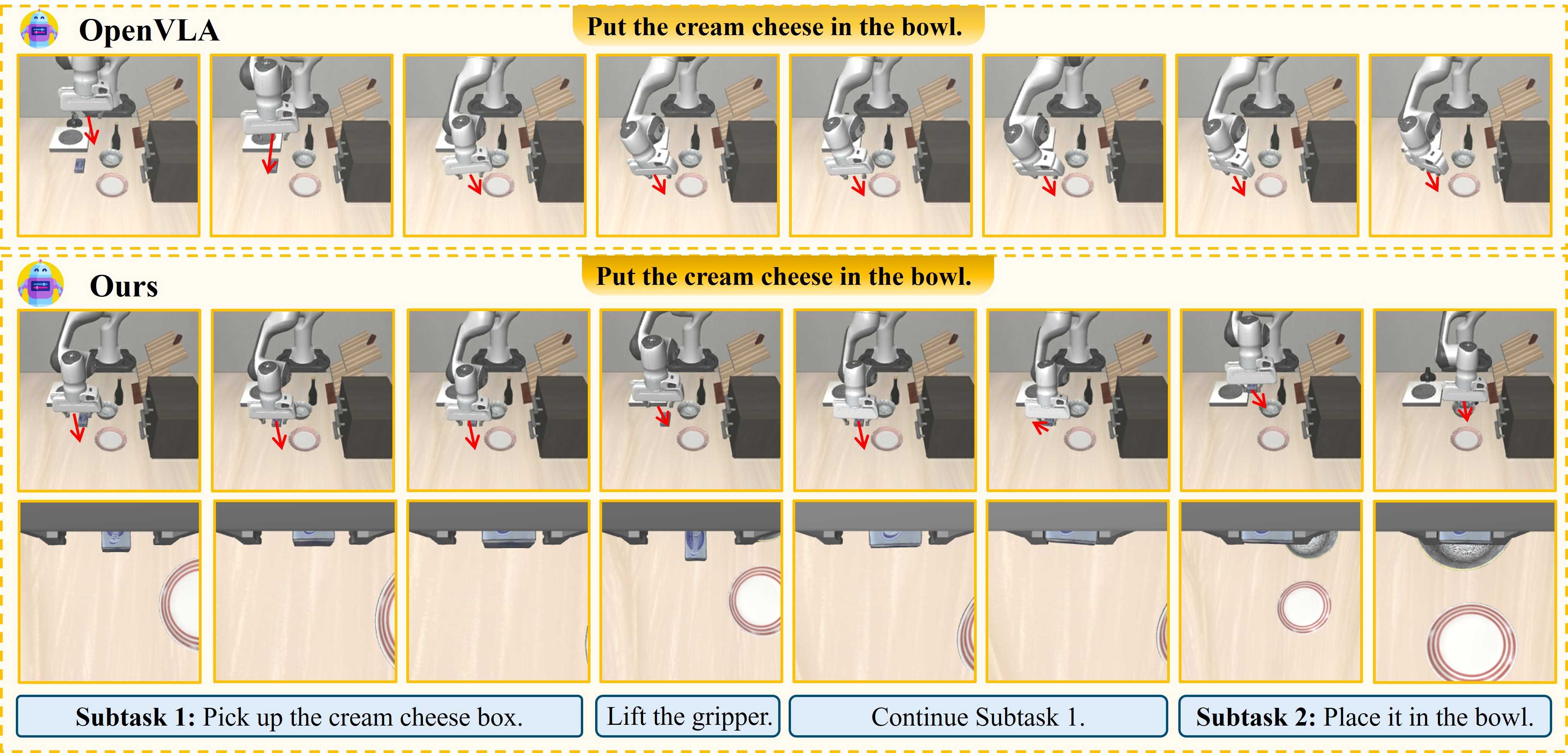
Imagine training a robot to place a block of cream cheese into a bowl. The robot successfully reaches, grasps the cheese — but then it slips during placement. The cheese lands on the table. The robot... doesn't notice. It continues moving its empty gripper toward the bowl, convinced the task is done.
This is the core problem of monolithic VLAs: error accumulation. Each small failure nudges the trajectory further from the correct path, with no mechanism to detect or recover.
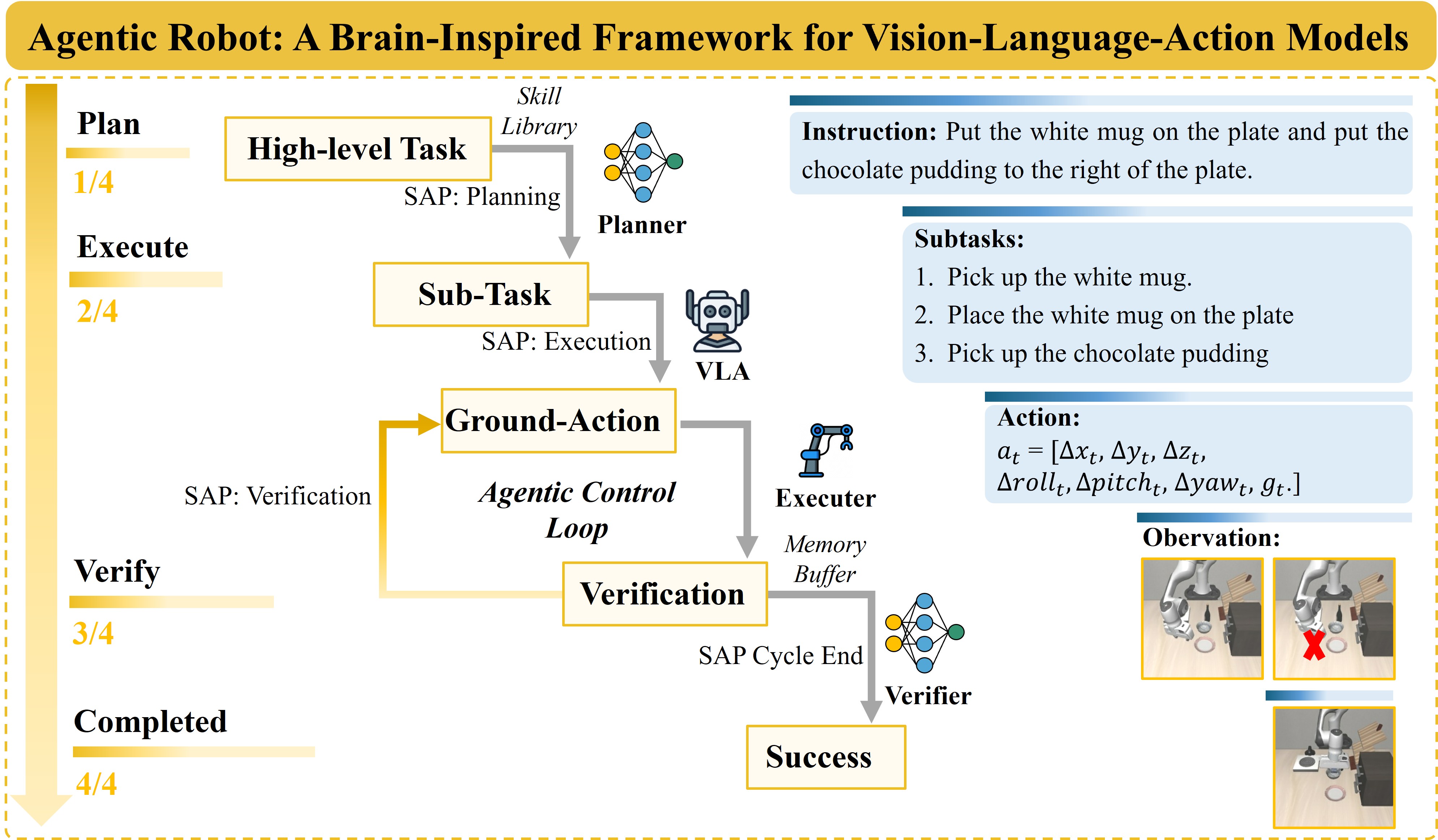
Agentic Robot solves this with the Standardized Action Procedure (SAP) — a coordination protocol that divides responsibilities across three specialized components. This tutorial walks you through:
- Setting up the environment from scratch
- Running
ds.py(DeepSeek-V3 decomposes a task into subgoals) - Running
main.py(OpenVLA executor evaluated on LIBERO) - Understanding the Temporal Verifier with its sliding window mechanism
- Implementing a basic verifier loop yourself
Paper: Agentic Robot: A Brain-Inspired Framework for VLA Models in Embodied Agents — arXiv 2505.23450, 2025
Code: github.com/Agentic-Robot/agentic-robot
What Is SAP? The Hospital Analogy
In surgery, no one operates by gut feeling alone. Surgeons follow SOPs (Standard Operating Procedures) — step-by-step protocols: prepare instruments → anesthesia → operate → verify → suture. Every step has a designated actor, a checker, and a protocol for handling complications.
SAP applies the same logic to robot manipulation. Instead of one model doing everything (perceive → think → act), SAP distributes responsibility across three specialized roles:
Task instruction: "put the cream cheese in the bowl"
↓
[Planner] DeepSeek-V3
→ subgoals: ["pick up cream cheese", "place cream cheese in bowl"]
↓
[Executor] OpenVLA-7B
→ action_t = [Δx, Δy, Δz, Δroll, Δpitch, Δyaw, gripper] (7-DoF)
↓
[Verifier] Qwen2.5-VL-3B (sliding window K=2)
→ status: "complete" | "continue" | "recover"
Each role does exactly one thing — and does it well. The Planner doesn't need to understand kinematics. The Executor doesn't need to reason about high-level goals. The Verifier just needs to answer: "Is this step done?"
The 4 Phases of Every SAP Cycle
Each SAP cycle runs four phases continuously:
- Multimodal Perception — Collect images from two cameras: third-person (scene overview) and wrist-mounted (gripper view)
- Formulated Plan — The Planner (DeepSeek-V3) receives the task instruction and outputs 2–5 atomic subgoals from a standardized skill library
- Reactive Execution — The Executor (OpenVLA) generates a 7-DoF action vector from the current image + subgoal text
- Temporal Verification — The Verifier runs every Δtv=20 frames and decides: advance / continue / recover
Setting Up the Environment
Agentic Robot builds on top of OpenVLA and LIBERO. You need both installed first.
Step 1: OpenVLA Base Environment
git clone https://github.com/openvla/openvla.git
cd openvla
conda create -n openvla python=3.10 -y
conda activate openvla
pip install -e .
Step 2: LIBERO Simulation
LIBERO is a simulation environment for robot manipulation with four task suites:
pip install libero
# Or from source for the latest version:
git clone https://github.com/Lifelong-Robot-Learning/LIBERO.git
cd LIBERO && pip install -e .
The four task suites (easiest to hardest):
| Suite | Flag | Characteristics | Tasks |
|---|---|---|---|
| Spatial | libero_spatial |
Same objects, different positions | 10 |
| Object | libero_object |
Different objects, same task structure | 10 |
| Goal | libero_goal |
Same objects, different goals | 10 |
| Long | libero_10 |
Long-horizon, ~10 steps per task | 10 |
Step 3: Agentic Robot Repo
git clone https://github.com/Agentic-Robot/agentic-robot.git
cd agentic-robot
pip install -e .
Step 1: Running ds.py — DeepSeek-V3 Subgoal Decomposition
The file experiments/robot/libero/ds.py is the Planner step in SAP. It calls the DeepSeek-V3 API to take a natural language task instruction and output a structured JSON list of subgoals.
cd agentic-robot
python experiments/robot/libero/ds.py
How DeepSeek-V3 Decomposes Tasks
The Planner is prompted with an atomic skill library — a set of standardized action templates that the executor can reliably perform:
SKILL_TEMPLATES = [
"pick up [object]",
"place [object] in [container]",
"place [object] on [surface]",
"open [container]",
"close [container]",
"push [object] to [location]",
]
Given the task "put the cream cheese in the bowl", DeepSeek-V3 is prompted to use only these templates and returns:
{
"task": "put the cream cheese in the bowl",
"subgoals": [
"pick up cream cheese",
"place cream cheese in bowl"
],
"num_subgoals": 2
}
Why 2–5 subgoals? Too few → the executor must handle complex tasks in a single segment → higher failure rate. Too many → verifier overhead dominates, pipeline slows down. 2–5 hits the sweet spot: granular enough for per-step verification, but not so fine-grained that it creates bottlenecks.
Why DeepSeek-V3 over GPT-4o? Significantly lower API cost for research iterations. Ablation in the paper shows comparable performance. DeepSeek-V3 also has strong reasoning capability for structured output tasks.
Step 2: Running main.py — OpenVLA Executor on LIBERO
python experiments/robot/libero/main.py \
--model_family openvla \
--pretrained_checkpoint path/to/openvla-7b \
--task_suite_name libero_spatial \
--center_crop True
Flag Breakdown
| Flag | Example Value | Meaning |
|---|---|---|
--model_family |
openvla |
VLA backbone — currently only OpenVLA is supported |
--pretrained_checkpoint |
path/to/openvla-7b |
Path to the downloaded OpenVLA-7B checkpoint |
--task_suite_name |
libero_spatial |
Task suite: libero_spatial / libero_object / libero_goal / libero_10 |
--center_crop |
True |
Image preprocessing: crop center 224×224 (matches OpenVLA training distribution) |
How OpenVLA Generates Actions
OpenVLA-7B takes an RGB image + subgoal text and outputs a 7-dimensional action vector:
# Inside main.py's executor loop
action = openvla.predict_action(
image=obs["agentview_image"], # third-person RGB (224×224)
instruction=current_subgoal, # e.g. "pick up cream cheese"
unnorm_key="libero_spatial" # normalization stats for this dataset
)
# action shape: (7,)
# action[0:3] → Cartesian displacement [Δx, Δy, Δz] (mm)
# action[3:6] → Rotation [Δroll, Δpitch, Δyaw] (rad)
# action[6] → Gripper command: 0.0=open, 1.0=close
The robot moves a small amount per step (~2–5mm). A simple subgoal like "pick up cream cheese" takes approximately 50–120 steps.
Temporal Verifier: The Sliding Window Mechanism
This is what sets Agentic Robot apart from standard VLA pipelines.
Why a Single Frame Isn't Enough
One image at one moment can't distinguish between:
- Robot moving slowly (still making progress) vs robot stuck (no movement)
- Gripper approaching an object vs gripper departing from an object
You need a sequence of frames to detect temporal change — what changed over time.
Sliding Window: K=2, Stride=5, Δtv=20
Action steps: 1 2 3 4 5 6 7 8 9 10 ... 20 ...
Buffer: [f1] [f2] [f3] [f4] [f5] [f6] ... ← buffer size = K×stride = 10
At step 20 (Δtv=20), extract sliding window:
frame at index -10 = f10 (10 steps ago)
frame at index -5 = f15 (5 steps ago)
Window = [(tp_10, wrist_10), (tp_15, wrist_15)] ← K=2 image pairs
The Verifier sees 2 image pairs (third-person + wrist) spaced 5 steps apart, then compares: did the object move? Did gripper state change?
Qwen2.5-VL-3B as the Verifier
The Verifier is Qwen2.5-VL-3B-Instruct fine-tuned on ~500 annotated triplets:
- Input: K frame pairs + subgoal text
- Output:
COMPLETE=yes/noandSTUCK=yes/no - Fine-tuning data: 500 trajectories with manual annotation for each subgoal transition
Why Qwen2.5-VL 3B (not 7B or 72B)? The Verifier runs real-time every 20 steps inside the inference loop. Larger models create a bottleneck: 7B takes ~2–3s per query, while 3B takes ~0.5s — fast enough to not slow down the pipeline.
Why Is Δtv=20 Optimal?
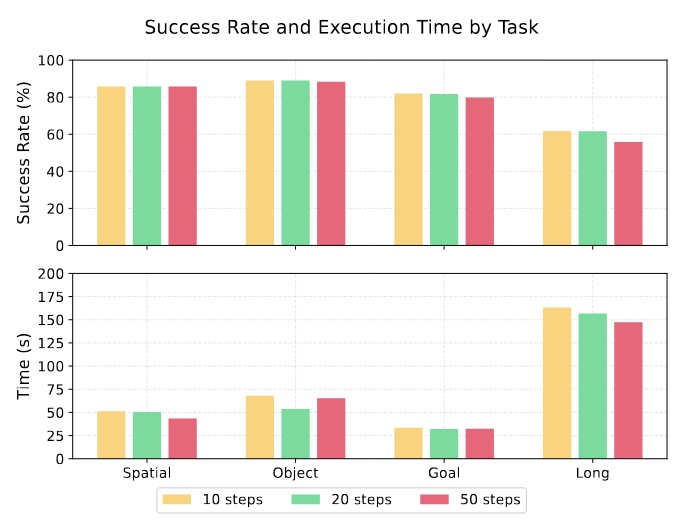
From the ablation study:
- Δtv=10 (verify more often): False positives increase — the Verifier prematurely marks steps as "complete" and advances too early
- Δtv=20 (optimal): Balances timely detection with avoiding false alarms
- Δtv=40 (verify less often): Misses failure windows — the robot stays stuck too long before recovery triggers
Implementing a Basic Verifier Loop
Here's a complete Python implementation you can integrate into your own project:
from collections import deque
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
class TemporalVerifier:
"""Sliding-window verifier for subgoal completion checking."""
def __init__(
self,
model_name: str = "Qwen/Qwen2.5-VL-3B-Instruct",
K: int = 2,
stride: int = 5,
delta_tv: int = 20,
):
self.K = K # number of frame pairs in window
self.stride = stride # steps between frames
self.delta_tv = delta_tv # verify every delta_tv action steps
self.buffer: deque = deque(maxlen=K * stride)
self.step_count = 0
self.model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_name, torch_dtype="auto", device_map="auto"
)
self.processor = AutoProcessor.from_pretrained(model_name)
def add_observation(self, third_person_img, wrist_img) -> None:
"""Record a frame pair for every action step."""
self.buffer.append((third_person_img, wrist_img))
self.step_count += 1
def should_verify(self) -> bool:
return (self.step_count % self.delta_tv == 0) and len(self.buffer) > 0
def _get_window_frames(self) -> list:
"""Extract K frame pairs spaced stride steps apart from the buffer."""
buf = list(self.buffer)
indices = range(0, len(buf), self.stride)
return [buf[i] for i in indices][:self.K]
def verify(self, subgoal: str) -> dict:
"""
Check subgoal completion from the sliding window.
Returns: {'status': 'complete' | 'continue' | 'recover'}
"""
frames = self._get_window_frames()
# Build multimodal prompt with frame sequence
content = []
for idx, (tp_img, wrist_img) in enumerate(frames):
content += [
{"type": "text", "text": f"Timestep {idx + 1} — third-person view:"},
{"type": "image", "image": tp_img},
{"type": "text", "text": f"Timestep {idx + 1} — wrist view:"},
{"type": "image", "image": wrist_img},
]
content.append({
"type": "text",
"text": (
f"Current subgoal: '{subgoal}'\n\n"
"Analyze the image sequence and answer:\n"
"1. Is the subgoal COMPLETE? (yes/no)\n"
"2. Is the robot STUCK (no meaningful movement or object change)? (yes/no)\n\n"
"Reply format: COMPLETE=<yes/no> STUCK=<yes/no>"
),
})
messages = [{"role": "user", "content": content}]
text = self.processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, _ = process_vision_info(messages)
inputs = self.processor(
text=[text], images=image_inputs, return_tensors="pt"
).to("cuda")
with torch.no_grad():
output = self.model.generate(**inputs, max_new_tokens=30)
resp = self.processor.decode(
output[0][inputs.input_ids.shape[1]:], skip_special_tokens=True
).upper()
if "COMPLETE=YES" in resp:
return {"status": "complete"}
if "STUCK=YES" in resp:
return {"status": "recover"}
return {"status": "continue"}
def reset_buffer(self) -> None:
"""Call after each subgoal advance — prevents context leakage."""
self.buffer.clear()
self.step_count = 0
def run_sap_episode(
env,
planner,
executor,
verifier: TemporalVerifier,
instruction: str,
max_steps: int = 400,
) -> bool:
"""
SAP main loop: Planner → Executor → Verifier (repeating).
Returns True if task completes, False if max_steps reached.
"""
# Planner step: decompose task into subgoals (ds.py logic)
subgoals = planner.decompose(instruction)
print(f"[Planner] {len(subgoals)} subgoals: {subgoals}")
obs = env.reset()
subgoal_idx = 0
for step in range(max_steps):
if subgoal_idx >= len(subgoals):
return True # all subgoals complete
current_sg = subgoals[subgoal_idx]
# Executor: generate action from current observation + subgoal
action = executor.predict(obs, current_sg)
obs, _, done, _ = env.step(action)
# Record frame pair into the verifier's buffer
verifier.add_observation(
obs["agentview_image"], # third-person
obs["robot0_eye_in_hand_image"] # wrist
)
# Verifier: check periodically every Δtv steps
if verifier.should_verify():
result = verifier.verify(current_sg)
if result["status"] == "complete":
print(f"✅ [step {step}] Subgoal {subgoal_idx + 1}/{len(subgoals)}: '{current_sg}'")
subgoal_idx += 1
verifier.reset_buffer() # CRITICAL: clear to prevent context leakage
elif result["status"] == "recover":
print(f"⚠️ [step {step}] Stuck! Recovery triggered for: '{current_sg}'")
# Simple recovery: lift gripper to safe position and retry
env.step(executor.get_lift_action())
if done:
break
return subgoal_idx >= len(subgoals)
Key Implementation Notes
verifier.reset_buffer() after advancing a subgoal is critical. Without it, frames from the just-completed subgoal appear in the next subgoal's sliding window — the Verifier may misread "cream cheese already in bowl" as progress on an entirely different subgoal.
Executor receives current_sg, not the full instruction. OpenVLA benefits from short, specific context. "pick up cream cheese" is much easier to attend to than "put the cream cheese in the bowl" — and avoids confusion when the robot is mid-way through a multi-step task.
Simple recovery actions work well. The ablation shows recovery only adds 1.9% on LIBERO-Long — seemingly small, but it's "free" improvement requiring no retraining. Lift the gripper to a safe position, reset, and retry the current subgoal.
Results: 79.6% LIBERO and What the Numbers Mean

| Task Suite | Agentic Robot | SpatialVLA | OpenVLA |
|---|---|---|---|
| LIBERO-Spatial | 85.8% | 82.3% | 79.4% |
| LIBERO-Object | 89.0% | 84.1% | 81.6% |
| LIBERO-Goal | 81.8% | 78.2% | 74.8% |
| LIBERO-Long | 61.6% | 49.4% | 54.2% |
| Average | 79.6% | 73.5% | 72.2% |
LIBERO-Long: Where SAP Makes the Biggest Difference
Agentic Robot improves by +12.2% over SpatialVLA on LIBERO-Long — the hardest suite, requiring ~10 manipulation steps per episode. This is where error accumulation devastates monolithic VLAs the most.
Specifically, on "put the cream cheese in the bowl": Agentic Robot achieves +24% over baseline, primarily because the Verifier detects object slippage immediately and triggers replanning before the error propagates.
Ablation: Which Component Matters Most?
Removing each component from LIBERO-Long:
| Configuration | Success Rate | vs Full System |
|---|---|---|
| Full system | 61.6% | — |
| No fine-tuned VLM verifier | 35.3% | -26.3% |
| No subgoal decomposition | 53.7% | -7.9% |
| No recovery mechanism | 59.7% | -1.9% |
Key insight: The fine-tuned VLM verifier is by far the highest-impact component. Using an off-the-shelf Qwen2.5-VL (without fine-tuning) drops performance by 26.3% — yet fine-tuning only requires ~500 annotated examples. This is entirely achievable with limited resources.
Conclusion
SAP isn't a complex architecture. The core idea is simple: divide responsibility, verify periodically, recover from failures — exactly what humans do naturally, and exactly what monolithic VLAs lack.
Key takeaways when implementing:
- Sliding window K=2, stride=5, Δtv=20 — ablation-validated defaults; use them before domain-specific tuning
- Fine-tune the verifier on your domain — 500 examples is enough for a large performance boost; don't use off-the-shelf
reset_buffer()after each subgoal advance — prevents context leakage between subgoals- Simple recovery actions are sufficient — lift gripper to safe position; no need to overcomplicate
The next post transfers this entire pipeline out of simulation and into the real world.