Series: AI Agent Pipeline cho Robot Manipulation — Bài 4/5
Khi robot "mắc kẹt" giữa chừng
Hãy tưởng tượng bạn đang dạy robot gắp một hộp kem vào bát. Robot thực hiện được bước đầu — vươn tay, kẹp hộp kem — nhưng khi cố đặt vào bát thì trượt. Hộp kem rơi ra ngoài. Robot... không biết điều đó xảy ra. Nó tiếp tục di chuyển tay không đến vị trí bát, nghĩ rằng nhiệm vụ đã xong.
Đây là vấn đề cốt lõi của các VLA đơn thuần: error accumulation (lỗi tích lũy). Mỗi bước nhỏ thất bại đẩy trajectory xa dần khỏi đường đúng, và không có cơ chế nào để phát hiện hay sửa chữa.
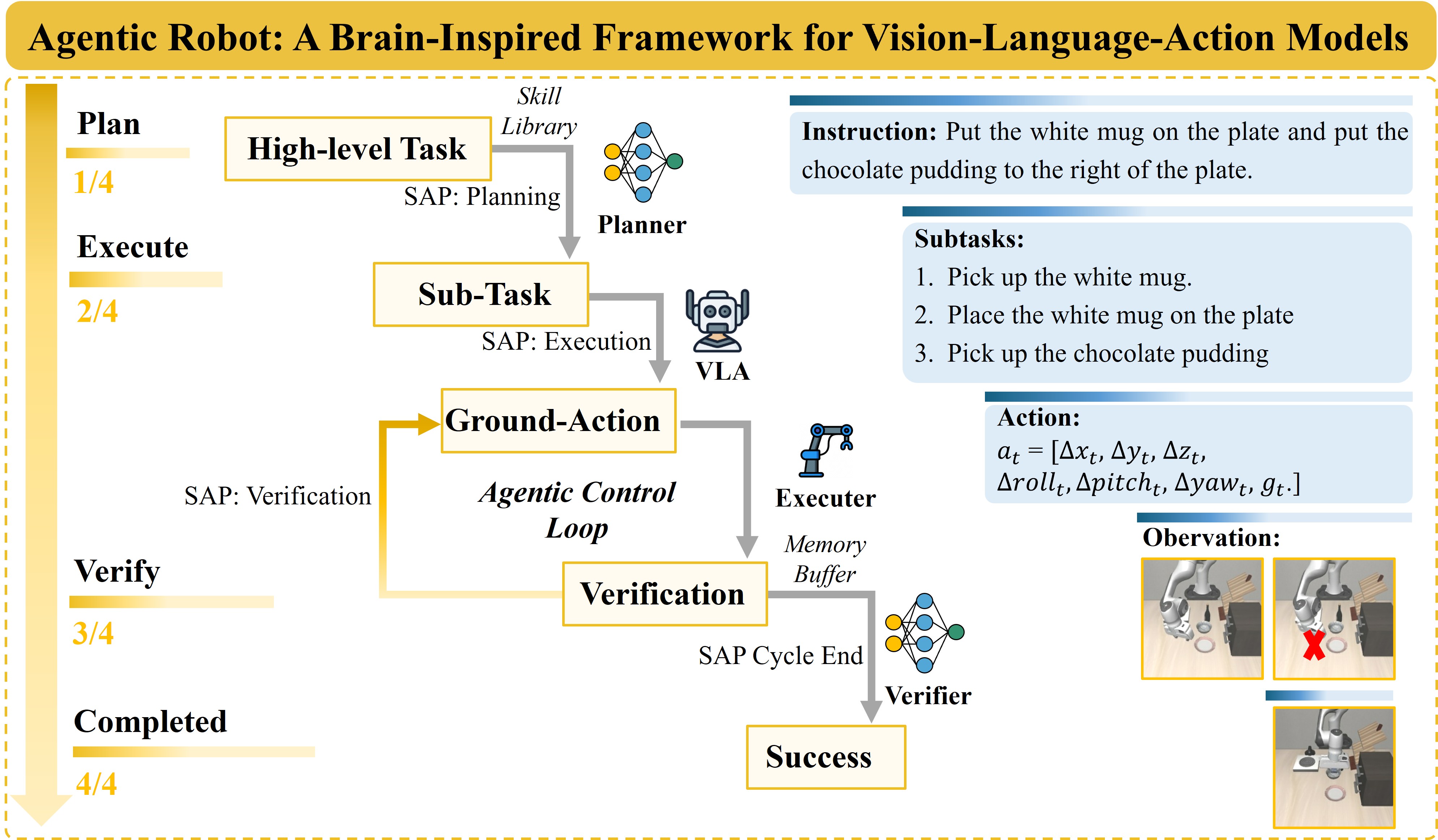
Agentic Robot giải quyết vấn đề này bằng Standardized Action Procedure (SAP) — một giao thức phối hợp chia trách nhiệm ra 3 thành phần chuyên biệt. Bài này hướng dẫn bạn từng bước:
- Cài đặt môi trường từ đầu
- Chạy
ds.py(DeepSeek-V3 decompose task thành subgoals) - Chạy
main.py(OpenVLA executor đánh giá trên LIBERO) - Hiểu cơ chế Temporal Verifier với sliding window
- Tự implement verifier loop cơ bản
Paper gốc: Agentic Robot: A Brain-Inspired Framework for VLA Models in Embodied Agents — arXiv 2505.23450, 2025
Code: github.com/Agentic-Robot/agentic-robot
SAP là gì? Analogy với quy trình bệnh viện
Trong một ca phẫu thuật, bác sĩ không làm mọi thứ theo cảm tính. Họ theo SOP (Standard Operating Procedure) — quy trình chuẩn hóa: chuẩn bị dụng cụ → gây mê → phẫu thuật → kiểm tra → khâu vết thương. Mỗi bước có người thực hiện, có người kiểm tra, và có giao thức xử lý khi xảy ra biến cố.
SAP (Standardized Action Procedure) áp dụng logic tương tự cho robot manipulation. Thay vì để một mô hình làm tất cả (nhìn → nghĩ → hành động), SAP chia trách nhiệm ra 3 vai trò chuyên biệt:
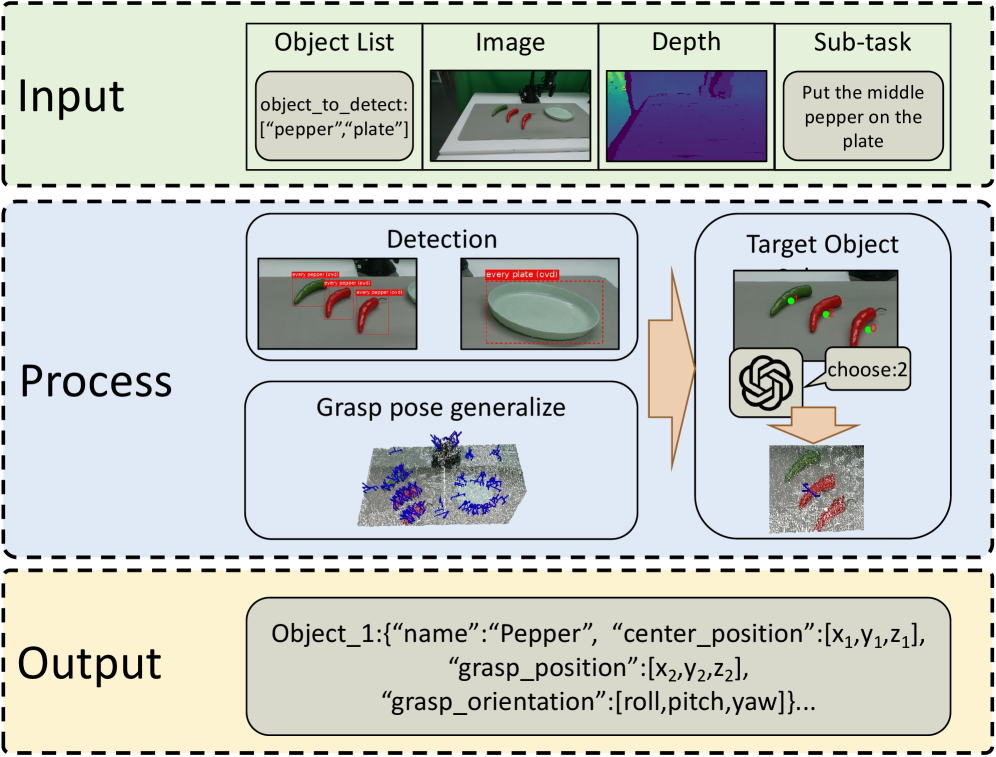
Task instruction: "put the cream cheese in the bowl"
↓
[Planner] DeepSeek-V3
→ subgoals: ["pick up cream cheese", "place cream cheese in bowl"]
↓
[Executor] OpenVLA-7B
→ action_t = [Δx, Δy, Δz, Δroll, Δpitch, Δyaw, gripper] (7-DoF)
↓
[Verifier] Qwen2.5-VL-3B (sliding window K=2)
→ status: "complete" | "continue" | "recover"
Mỗi role chỉ làm đúng một việc — và làm tốt việc đó. Planner không cần biết kinematics. Executor không cần nghĩ đến high-level goal. Verifier chỉ cần trả lời: "Bước này xong chưa?"
4 phase của mỗi vòng lặp SAP
Mỗi SAP cycle gồm 4 phase lặp liên tục:
- Multimodal Perception — Thu thập ảnh từ 2 camera: third-person (góc nhìn toàn cảnh) và wrist-mounted (góc nhìn gripper)
- Formulated Plan — Planner (DeepSeek-V3) nhận task instruction, xuất ra 2-5 atomic subgoals theo skill library chuẩn hóa
- Reactive Execution — Executor (OpenVLA) sinh ra action vector 7-DoF từ ảnh hiện tại + subgoal text
- Temporal Verification — Verifier kiểm tra mỗi Δtv=20 frames, quyết định advance / continue / recover
Cài đặt môi trường
Agentic Robot build on top của OpenVLA và LIBERO. Bạn cần cài cả hai trước.
Bước 1: OpenVLA base environment
# Clone và cài OpenVLA
git clone https://github.com/openvla/openvla.git
cd openvla
conda create -n openvla python=3.10 -y
conda activate openvla
pip install -e .
Bước 2: LIBERO simulation
LIBERO là môi trường simulation cho robot manipulation với 4 task suites:
pip install libero
# Hoặc từ source (nếu cần latest version):
git clone https://github.com/Lifelong-Robot-Learning/LIBERO.git
cd LIBERO && pip install -e .
4 task suites từ dễ đến khó:
| Suite | Flag | Đặc điểm | Số task |
|---|---|---|---|
libero_spatial |
libero_spatial |
Cùng vật thể, khác vị trí | 10 |
libero_object |
libero_object |
Khác vật thể, cùng task | 10 |
libero_goal |
libero_goal |
Cùng vật thể, khác goal | 10 |
libero_10 |
libero_10 |
Long-horizon, 10 bước/task | 10 |
Bước 3: Agentic Robot repo
git clone https://github.com/Agentic-Robot/agentic-robot.git
cd agentic-robot
pip install -e .
Bước 1: Chạy ds.py — DeepSeek-V3 decompose subgoals
File experiments/robot/libero/ds.py là bước Planner trong SAP. Nó gọi DeepSeek-V3 API để nhận task instruction dạng ngôn ngữ tự nhiên và xuất ra danh sách subgoals dạng structured JSON.
cd agentic-robot
python experiments/robot/libero/ds.py
DeepSeek-V3 decompose như thế nào?
Planner được prompt với atomic skill library — tập hợp các action template chuẩn hóa mà executor có thể thực hiện:
SKILL_TEMPLATES = [
"pick up [object]",
"place [object] in [container]",
"place [object] on [surface]",
"open [container]",
"close [container]",
"push [object] to [location]",
]
Khi nhận task "put the cream cheese in the bowl", DeepSeek-V3 được prompt để chỉ dùng các template trên, và trả về:
{
"task": "put the cream cheese in the bowl",
"subgoals": [
"pick up cream cheese",
"place cream cheese in bowl"
],
"num_subgoals": 2
}
Tại sao chỉ 2-5 subgoals? Quá ít → executor phải xử lý task phức tạp trong một step → dễ thất bại. Quá nhiều → verifier overhead lớn, pipeline chậm. 2-5 là sweet spot: đủ granular để verify từng bước, nhưng không quá chi tiết.
Tại sao DeepSeek-V3 chứ không phải GPT-4o? Chi phí API thấp hơn đáng kể cho research iterations. Ablation trong paper cho thấy performance tương đương. DeepSeek-V3 cũng có reasoning khả năng mạnh cho structured output tasks.
Bước 2: Chạy main.py — OpenVLA executor trên LIBERO
python experiments/robot/libero/main.py \
--model_family openvla \
--pretrained_checkpoint path/to/openvla-7b \
--task_suite_name libero_spatial \
--center_crop True
Giải thích từng flag
| Flag | Giá trị mẫu | Ý nghĩa |
|---|---|---|
--model_family |
openvla |
Backbone VLA — hiện chỉ hỗ trợ OpenVLA |
--pretrained_checkpoint |
path/to/openvla-7b |
Path đến checkpoint OpenVLA-7B đã download |
--task_suite_name |
libero_spatial |
Task suite: libero_spatial / libero_object / libero_goal / libero_10 |
--center_crop |
True |
Preprocessing ảnh: crop center 224×224 (khớp với training distribution của OpenVLA) |
OpenVLA sinh action như thế nào?
OpenVLA-7B nhận vào ảnh RGB + subgoal text, xuất ra action vector 7 chiều:
# Bên trong executor loop của main.py
action = openvla.predict_action(
image=obs["agentview_image"], # third-person RGB (224×224)
instruction=current_subgoal, # e.g. "pick up cream cheese"
unnorm_key="libero_spatial" # normalization stats cho dataset cụ thể
)
# action shape: (7,)
# action[0:3] → Cartesian displacement [Δx, Δy, Δz] (mm)
# action[3:6] → Rotation [Δroll, Δpitch, Δyaw] (rad)
# action[6] → Gripper command: 0.0=open, 1.0=close
Robot di chuyển một lượng nhỏ mỗi step (~2-5mm). Một subgoal đơn giản như "pick up cream cheese" cần khoảng 50-120 steps.
Temporal Verifier: Cơ chế sliding window
Đây là phần phân biệt Agentic Robot với các VLA pipeline thông thường.
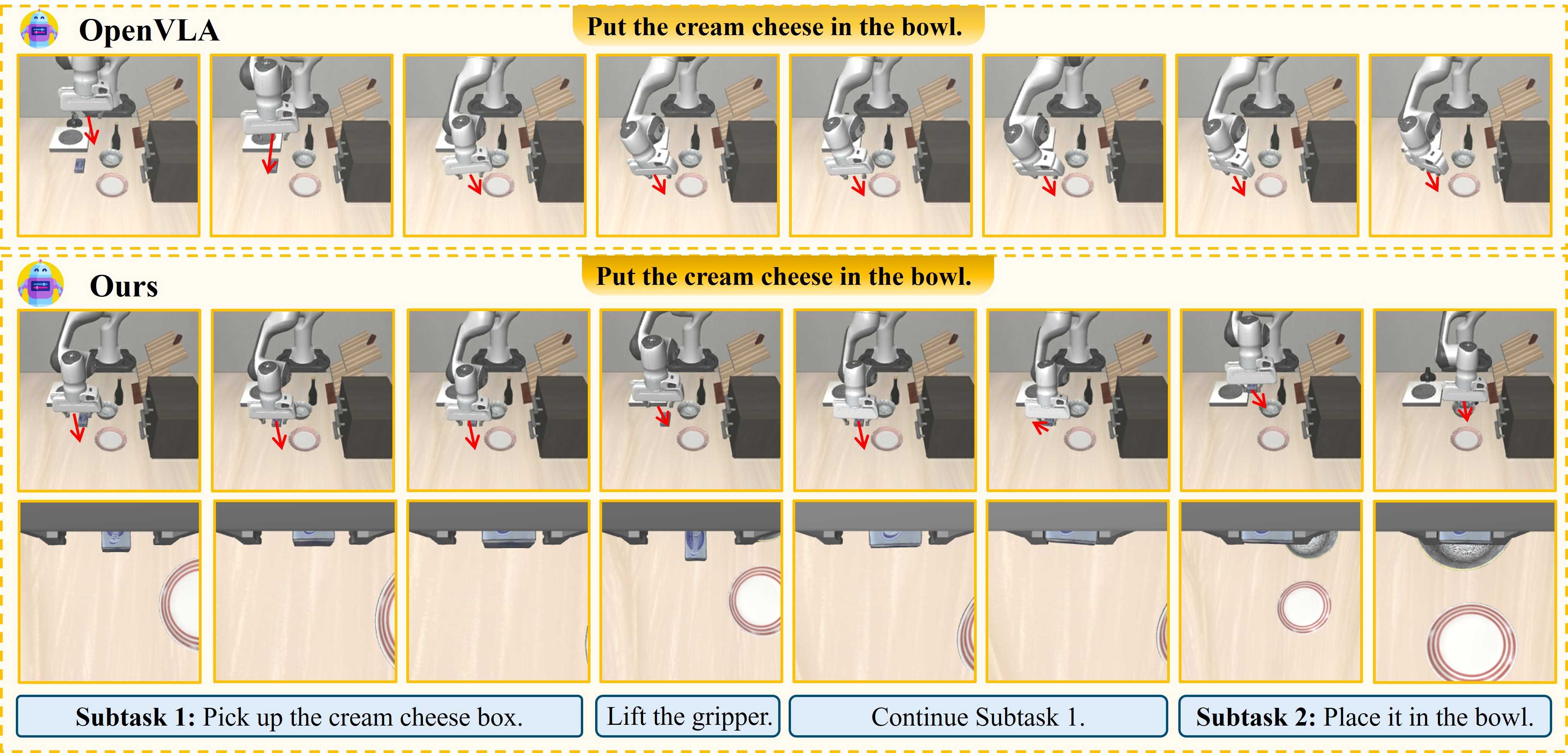
Tại sao single-frame không đủ?
Một ảnh tại một thời điểm không thể phân biệt:
- Robot đang di chuyển chậm (đang tiến triển) vs robot stuck (không di chuyển)
- Gripper đang tiếp cận vật thể vs gripper đã rời khỏi vật thể
Cần chuỗi frames để phát hiện temporal change — sự thay đổi theo thời gian.
Sliding window: K=2, stride=5, Δtv=20
Action steps: 1 2 3 4 5 6 7 8 9 10 ... 20 21 ...
Buffer: [f1] [f2] [f3] [f4] [f5] [f6] ... ← buffer size = K×stride = 10
Tại step 20 (Δtv=20), lấy sliding window:
frame tại index -10 = f10 (5 frames trước)
frame tại index -5 = f15 (hiện tại - 5)
Window = [(tp_10, wrist_10), (tp_15, wrist_15)] ← K=2 cặp ảnh
Verifier nhìn 2 cặp ảnh (third-person + wrist) cách nhau 5 steps, rồi so sánh: vật thể có di chuyển không? Gripper state có thay đổi không?
Qwen2.5-VL-3B: VLM làm verifier
Verifier là Qwen2.5-VL-3B-Instruct được fine-tune trên ~500 annotated triplets:
- Input: K frame pairs + subgoal text
- Output:
COMPLETE=yes/novàSTUCK=yes/no - Fine-tuning data: 500 trajectories với manual annotation cho mỗi subgoal transition
Tại sao Qwen2.5-VL 3B (không phải 7B hay 72B)? Verifier chạy real-time mỗi 20 steps trong inference loop. Model lớn hơn sẽ là bottleneck: 7B mất ~2-3s/query, 3B chỉ mất ~0.5s — vừa đủ để không làm chậm pipeline.
Tần suất Δtv=20 tại sao là optimal?
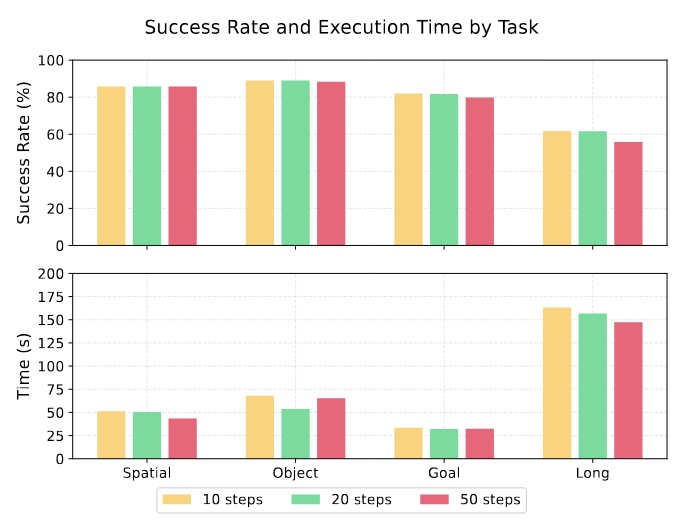
Từ ablation study:
- Δtv=10 (verify thường xuyên hơn): False positives tăng — verifier nhầm "đang di chuyển" thành "complete" và advance sớm
- Δtv=20 (optimal): Cân bằng giữa phát hiện kịp thời và tránh false alarm
- Δtv=40 (verify ít hơn): Bỏ lỡ failure windows — robot stuck quá lâu trước khi recovery
Implement Temporal Verifier Loop cơ bản
Đây là implementation Python đầy đủ để bạn tích hợp vào dự án của mình:
from collections import deque
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
class TemporalVerifier:
"""Sliding-window verifier kiểm tra subgoal completion."""
def __init__(
self,
model_name: str = "Qwen/Qwen2.5-VL-3B-Instruct",
K: int = 2,
stride: int = 5,
delta_tv: int = 20,
):
self.K = K # số frame pairs trong window
self.stride = stride # khoảng cách giữa các frame (steps)
self.delta_tv = delta_tv # verify mỗi delta_tv action steps
self.buffer: deque = deque(maxlen=K * stride)
self.step_count = 0
self.model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_name, torch_dtype="auto", device_map="auto"
)
self.processor = AutoProcessor.from_pretrained(model_name)
def add_observation(self, third_person_img, wrist_img) -> None:
"""Ghi nhận frame pair mỗi action step."""
self.buffer.append((third_person_img, wrist_img))
self.step_count += 1
def should_verify(self) -> bool:
return (self.step_count % self.delta_tv == 0) and len(self.buffer) > 0
def _get_window_frames(self) -> list:
"""Lấy K frame pairs cách nhau stride steps từ buffer."""
buf = list(self.buffer)
indices = range(0, len(buf), self.stride)
return [buf[i] for i in indices][:self.K]
def verify(self, subgoal: str) -> dict:
"""
Kiểm tra subgoal completion từ sliding window.
Returns: {'status': 'complete' | 'continue' | 'recover'}
"""
frames = self._get_window_frames()
# Xây dựng multimodal prompt với frame sequence
content = []
for idx, (tp_img, wrist_img) in enumerate(frames):
content += [
{"type": "text", "text": f"Timestep {idx + 1} — third-person view:"},
{"type": "image", "image": tp_img},
{"type": "text", "text": f"Timestep {idx + 1} — wrist view:"},
{"type": "image", "image": wrist_img},
]
content.append({
"type": "text",
"text": (
f"Current subgoal: '{subgoal}'\n\n"
"Phân tích chuỗi ảnh trên và trả lời:\n"
"1. Subgoal này ĐÃ HOÀN THÀNH chưa? (yes/no)\n"
"2. Robot có đang STUCK (không có chuyển động, vật thể không thay đổi)? (yes/no)\n\n"
"Trả lời theo format: COMPLETE=<yes/no> STUCK=<yes/no>"
),
})
messages = [{"role": "user", "content": content}]
text = self.processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, _ = process_vision_info(messages)
inputs = self.processor(
text=[text], images=image_inputs, return_tensors="pt"
).to("cuda")
with torch.no_grad():
output = self.model.generate(**inputs, max_new_tokens=30)
resp = self.processor.decode(
output[0][inputs.input_ids.shape[1]:], skip_special_tokens=True
).upper()
if "COMPLETE=YES" in resp:
return {"status": "complete"}
if "STUCK=YES" in resp:
return {"status": "recover"}
return {"status": "continue"}
def reset_buffer(self) -> None:
"""Gọi sau mỗi lần advance subgoal — tránh nhiễu context cũ."""
self.buffer.clear()
self.step_count = 0
def run_sap_episode(
env,
planner,
executor,
verifier: TemporalVerifier,
instruction: str,
max_steps: int = 400,
) -> bool:
"""
SAP main loop: Planner → Executor → Verifier (lặp).
Returns True nếu task hoàn thành, False nếu max_steps hết.
"""
# Bước Planner: decompose task thành subgoals (ds.py logic)
subgoals = planner.decompose(instruction)
print(f"[Planner] {len(subgoals)} subgoals: {subgoals}")
obs = env.reset()
subgoal_idx = 0
for step in range(max_steps):
if subgoal_idx >= len(subgoals):
return True # tất cả subgoals hoàn thành
current_sg = subgoals[subgoal_idx]
# Bước Executor: sinh action từ observation + subgoal hiện tại
action = executor.predict(obs, current_sg)
obs, _, done, _ = env.step(action)
# Ghi nhận frame pair vào buffer
verifier.add_observation(
obs["agentview_image"], # third-person
obs["robot0_eye_in_hand_image"] # wrist
)
# Bước Verifier: kiểm tra định kỳ mỗi Δtv steps
if verifier.should_verify():
result = verifier.verify(current_sg)
if result["status"] == "complete":
print(f"✅ [step {step}] Subgoal {subgoal_idx + 1}/{len(subgoals)}: '{current_sg}'")
subgoal_idx += 1
verifier.reset_buffer() # QUAN TRỌNG: clear để tránh nhiễu context
elif result["status"] == "recover":
print(f"⚠️ [step {step}] Stuck! Recovery triggered cho: '{current_sg}'")
# Recovery đơn giản: lift gripper về vị trí an toàn
env.step(executor.get_lift_action())
if done:
break
return subgoal_idx >= len(subgoals)
Những điểm quan trọng trong code trên
verifier.reset_buffer() sau khi advance subgoal là critical. Nếu không clear buffer, frames từ subgoal vừa hoàn thành sẽ xuất hiện trong sliding window của subgoal tiếp theo — verifier có thể nhầm "cream cheese đã ở trong bát" là progress của subgoal mới.
Executor nhận current_sg, không phải full instruction. OpenVLA cần context ngắn, cụ thể. "pick up cream cheese" dễ attend hơn "put the cream cheese in the bowl" — và tránh confusion khi robot đang ở giữa multi-step task.
Recovery action đơn giản nhưng hiệu quả. Ablation cho thấy recovery mechanism chỉ cải thiện 2.1% trên LIBERO-Long — nghe có vẻ nhỏ, nhưng đây là improvement "free" không cần retrain gì. Lift gripper về safe position, retry subgoal từ đầu.
Kết quả: 79.6% LIBERO và những con số đằng sau

| Task Suite | Agentic Robot | SpatialVLA | OpenVLA |
|---|---|---|---|
| LIBERO-Spatial | 85.8% | 82.3% | 79.4% |
| LIBERO-Object | 89.0% | 84.1% | 81.6% |
| LIBERO-Goal | 81.8% | 78.2% | 74.8% |
| LIBERO-Long | 61.6% | 49.4% | 54.2% |
| Average | 79.6% | 73.5% | 72.2% |
LIBERO-Long: Nơi SAP tạo ra khác biệt lớn nhất
Agentic Robot cải thiện +12.2% so với SpatialVLA trên LIBERO-Long — task suite khó nhất, mỗi episode cần 10 bước manipulation liên tiếp. Đây là nơi error accumulation phá hỏng các VLA đơn thuần nhất.
Cụ thể task "put the cream cheese in the bowl": Agentic Robot đạt +24% so với baseline, chủ yếu nhờ Verifier phát hiện kịp thời khi vật thể trượt khỏi gripper và trigger replanning ngay lập tức.
Ablation: Thành phần nào quan trọng nhất?
Thử loại bỏ từng thành phần khỏi LIBERO-Long:
| Cấu hình | Success Rate | So với full |
|---|---|---|
| Full system | 61.6% | — |
| Không có fine-tuned VLM verifier | 35.3% | -26.3% |
| Không có subgoal decomposition | 53.7% | -7.9% |
| Không có recovery mechanism | 59.7% | -1.9% |
Bài học quan trọng: Fine-tuned VLM verifier là thành phần có impact lớn nhất. Dùng verifier "off-the-shelf" (Qwen2.5-VL không fine-tune) làm giảm 26.3% — cho thấy 500 annotated examples là đủ để tạo ra sự khác biệt lớn. Đây là con số rất khả thi cho nghiên cứu với resource hạn chế.
Kết luận
SAP không phải là kiến trúc phức tạp. Ý tưởng cốt lõi rất đơn giản: chia nhỏ trách nhiệm, kiểm tra định kỳ, phục hồi khi thất bại — đúng những gì con người làm một cách tự nhiên, và là điều mà các VLA đơn thuần thiếu.
Những điểm bạn cần nhớ khi implement:
- Sliding window K=2, stride=5, Δtv=20 — hyperparameters được tối ưu từ ablation, dùng làm default khi chưa có domain-specific tuning
- Fine-tune verifier trên domain cụ thể — 500 examples đủ để tạo ra improvement lớn; đừng dùng off-the-shelf
reset_buffer()sau mỗi subgoal advance — tránh context leakage giữa các subgoals- Recovery action đơn giản là đủ — lift gripper về safe position, không cần phức tạp hóa
Bài tiếp theo sẽ đưa toàn bộ pipeline này ra khỏi simulation và vào thế giới thực.