Năm 2025, Physical Intelligence ra mắt π₀ (pi0) — một trong những VLA (Vision-Language-Action) model mạnh nhất thế giới, được huấn luyện trên hàng triệu bước robot thực tế. Kết quả benchmark SimplerEnv: 55.7% success rate. Ấn tượng? Có. Đủ để deploy sản xuất? Chưa.
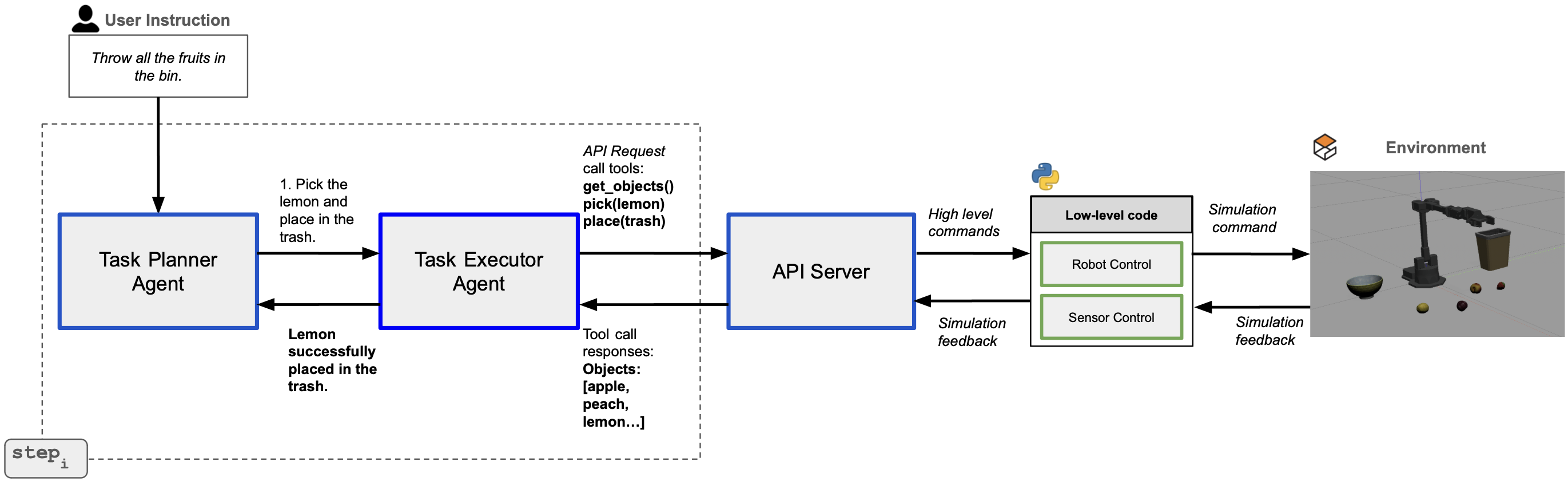
Cùng lúc đó, một nhóm nghiên cứu (Yi Yang et al.) publish paper ManiAgent — arXiv:2510.11660 với kiến trúc hoàn toàn khác: không phải một model khổng lồ, mà là 3 agent nhỏ phối hợp với nhau. Kết quả? 86.8% — chênh lệch 31 điểm phần trăm so với pi0, và quan trọng hơn: zero fine-tuning trên bất kỳ dữ liệu robot nào.
Bài này sẽ mổ xẻ tại sao kiến trúc multi-agent lại đánh bại VLA end-to-end trong bài toán manipulation. Đọc xong, bạn có thể tự vẽ lại kiến trúc ManiAgent từ đầu và giải thích cho đồng nghiệp nghe.
Roadmap series: AI Agent Pipeline cho Robot Manipulation
Series 5 bài, mỗi bài xây trên kiến thức bài trước:
| # | Bài | Nội dung |
|---|---|---|
| 1 | Tại sao Multi-Agent thắng VLA? ← bạn đang ở đây | So sánh benchmark, kiến trúc ManiAgent, luồng thông tin |
| 2 | Perception Agent & Grasp Planning | Thiết kế Perception Agent: detection, depth, tọa độ 3D |
| 3 | ALRM, CAP vs TAP | Ba paradigm lập kế hoạch hành động so sánh trực tiếp |
| 4 | SAP Verifier: Self-Verification | Kiểm tra và sửa lỗi hành động tự động |
| 5 | Sim-to-Real Deploy | Triển khai pipeline agent lên robot thực |
VLA là gì và tại sao nó chưa đủ?
VLA (Vision-Language-Action) model là kiến trúc end-to-end: nhận vào hình ảnh + câu lệnh ngôn ngữ, xuất ra trực tiếp joint angles hoặc cartesian waypoints cho robot. Ý tưởng hấp dẫn — như một bộ não duy nhất biết "nhìn" + "hiểu" + "hành động" cùng lúc.
Các đại diện tiêu biểu hiện tại:
- π₀ (pi0) — Physical Intelligence: flow-matching VLA, huấn luyện trên dữ liệu robot đa dạng
- CogACT — VLA tích hợp cognitive reasoning vào action generation
- OpenVLA, RoboFlamingo, SpatialVLA — các biến thể với cách tiếp cận khác nhau
Vấn đề cốt lõi: manipulation là bài toán đòi hỏi 3 năng lực hoàn toàn khác nhau, và tối ưu hóa đồng thời 3 thứ trong 1 model là cực kỳ khó:
- Perception — hiểu không gian 3D, xác định vị trí chính xác đến mm, phân biệt object bị che khuất
- Reasoning — lập kế hoạch multi-step, xử lý điều kiện, recover khi sub-task thất bại
- Action execution — chuyển kế hoạch thành trajectory khớp với cơ học và workspace của robot
Hình ảnh dễ nhớ: thuê một người vừa làm phẫu thuật viên, vừa gây mê, vừa điều dưỡng trong cùng một ca mổ — không ai có thể làm tốt cả 3 việc cùng lúc. Chuyên môn hóa luôn thắng.
Những con số không nói dối
SimplerEnv là benchmark chuẩn cho robot manipulation trong simulation, gồm 4 task trên nền Google Robot:
- Stack blocks — xếp các khối lên nhau (đòi hỏi precision cao)
- Place carrot on plate — đặt cà rốt lên đĩa
- Put spoon on towel — đặt thìa lên khăn
- Move eggplant to basket — di chuyển cà tím vào rổ (có occlusion challenges)
Kết quả đầy đủ (success rate trung bình):
| Model | Loại | Stack | Carrot | Spoon | Eggplant | TB |
|---|---|---|---|---|---|---|
| CogACT | VLA đơn | 15.0% | 50.8% | 71.7% | 67.5% | 51.3% |
| π₀ (pi0) | VLA đơn | 21.3% | 58.8% | 63.3% | 79.2% | 55.7% |
| ManiAgent-GPT-4o | 3-agent | 76.4% | 95.8% | 77.8% | 47.2% | 74.3% |
| ManiAgent-Claude Sonnet 4 | 3-agent | 77.8% | 98.6% | 80.6% | 62.5% | 79.9% |
| ManiAgent-GPT-5 | 3-agent | 87.5% | 95.8% | 91.7% | 72.2% | 86.8% |
Một số quan sát đáng chú ý:
- Stack blocks là task khó nhất: pi0 chỉ đạt 21.3%, ManiAgent-GPT-5 đạt 87.5% — chênh lệch 66 điểm. Vì sao? Stacking đòi hỏi perception chính xác (tọa độ 3D từng khối), reasoning (thứ tự xếp an toàn), và execution (trajectory không va chạm) — VLA phải làm cả 3 cùng lúc và fail.
- Move eggplant là task khó cho tất cả vì occlusion. ManiAgent-GPT-5 chỉ đạt 72.2% — thấp hơn pi0 (79.2%). Điểm yếu của multi-agent khi object bị che khuất.
- Ngay cả ManiAgent-GPT-4o (74.3%) cũng vượt cả 2 VLA baseline — chứng tỏ lợi thế đến từ kiến trúc, không phải sức mạnh model.
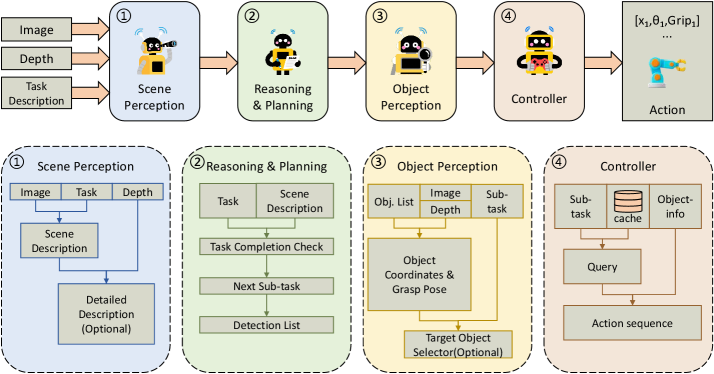
Kiến trúc ManiAgent: 3 chuyên gia thay vì 1 generalist
ManiAgent tách pipeline thành 3 agent chuyên biệt, mỗi agent dùng model phù hợp nhất cho nhiệm vụ của nó:
[Scene Images + Depth Maps + Camera Calibration + Task Description]
│
▼
┌────────────────────────┐
│ PERCEPTION AGENT │ ← VLM + Florence-v2 detector
│ • Object detection │
│ • 2D → 3D projection │
│ • Grasp pose gen │
└───────────┬────────────┘
│ scene description (text)
│ object positions + grasp poses
▼
┌────────────────────────┐
│ REASONING AGENT │ ← LLM (GPT-5 / Claude)
│ • Sub-task decomp │
│ • State evaluation │
│ • History tracking │
└───────────┬────────────┘
│ sub-task + target object list
▼
┌────────────────────────┐
│ ACTION-EXEC AGENT │ ← LLM + action cache
│ • Keypoint generation │
│ • Trajectory planning │
│ • Action caching │
└───────────┬────────────┘
│
▼
[Robot Commands]
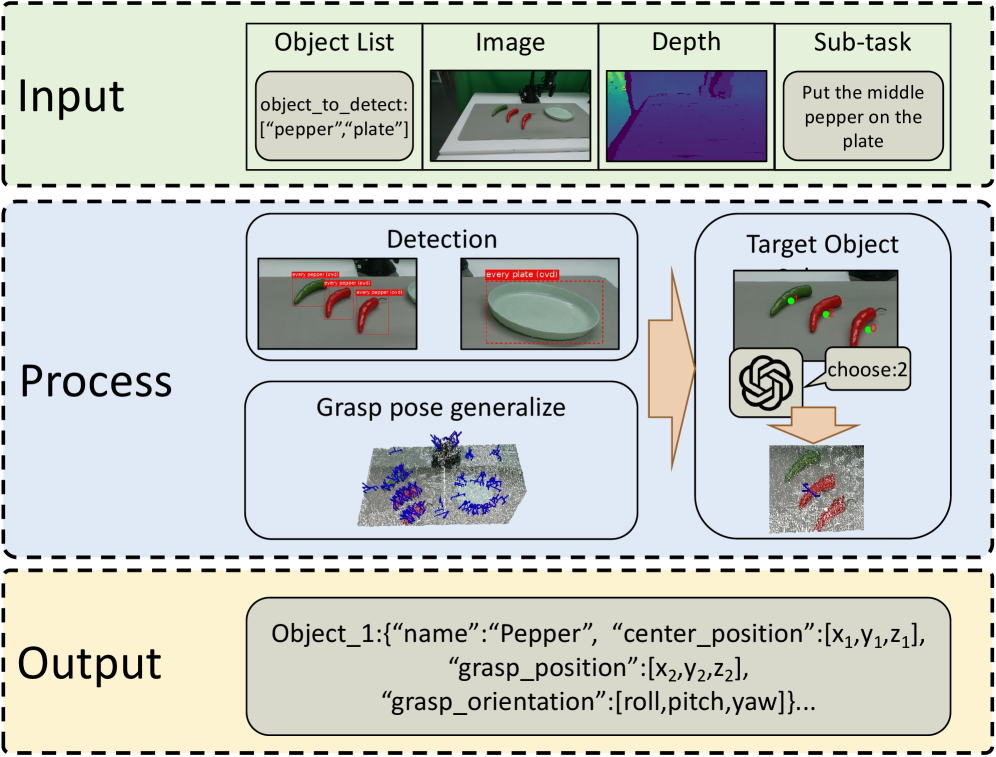
Perception Agent — "Đôi mắt đo đạc"
Inputs: RGB images, depth maps, camera calibration parameters, task description
Perception Agent thực hiện 4 bước chính:
- Scene understanding: Dùng VLM để viết description tổng quan về scene — "trên bàn có 1 cái đĩa trắng, 1 củ cà rốt cam, gripper đang ở góc trên phải"
- Object detection: Dùng Florence-v2 (Microsoft) để detect từng object với bounding box. Trick: dùng prefix "every" khi query ("every carrot", "every cube") để giảm tỷ lệ bỏ sót khi có nhiều object cùng loại
- 2D → 3D projection: Dùng depth map + camera calibration matrix để chuyển tọa độ pixel (u, v) → tọa độ 3D thực (x, y, z) tính bằng meter
- Grasp pose generation: Tính góc và vị trí để gripper tiếp cận object an toàn
Output gửi cho Reasoning Agent là text hoàn toàn:
Red cube: position=[0.23, -0.15, 0.82], grasp_pose=[0.0, 0.0, 0.0, 1.0]
Blue plate: position=[0.18, 0.22, 0.78], flat_surface=True
Reasoning Agent — "Bộ não chiến lược"
Inputs: Scene description, task instruction, lịch sử sub-tasks đã thực hiện
Reasoning Agent không làm việc với số — nó suy nghĩ bằng ngôn ngữ tự nhiên. Nhiệm vụ:
- Đánh giá trạng thái hiện tại: đã làm được gì, còn thiếu gì, có sub-task nào fail không?
- Decompose task thành sub-task tiếp theo cần làm
- Gửi yêu cầu lại cho Perception Agent: "lần detect tiếp theo hãy tập trung vào [danh sách object]"
- Dùng lịch sử để không lặp lại sub-task đã fail — tránh infinite loop khi robot gặp khó khăn
Ví dụ reasoning chain điển hình:
Task: "Place carrot on plate"
Current state: "Carrot at (0.3, -0.1, 0.85). Plate at (0.1, 0.2, 0.80)."
History: [] ← chưa làm gì
Sub-task plan:
Step 1: Pick up carrot → target: carrot at (0.3, -0.1, 0.85)
Step 2: Move to above plate → target: plate center (0.1, 0.2, 0.80)
Step 3: Release carrot → check success condition
Next action: Execute Step 1
Action-Execution Agent — "Tay thực thi"
Inputs: Sub-task description, 3D coordinates, grasp poses
Agent này nhận nhiệm vụ cụ thể từ Reasoning Agent và generate trajectory thực tế:
- Chuyển tọa độ 3D target → Cartesian keypoints (chuỗi điểm đích cho end-effector)
- Dùng action cache — lưu "1 trajectory template per skill". Nếu đã từng pick object, lấy template từ cache thay vì generate mới
- Cache miss → dùng LLM generate action sequence từ đầu
Action cache là chi tiết kỹ thuật quan trọng. Nó giảm latency đáng kể và tăng consistency — cùng 1 skill (pick, place, rotate) được thực hiện theo cách nhất quán.
Luồng thông tin: Vì sao text là "ngôn ngữ chung"?
Điểm thiết kế đặc biệt của ManiAgent: tất cả inter-agent communication đều qua text thuần túy, không phải vector embedding hay latent space chia sẻ.
Perception → Reasoning:
"Blue cup tại (0.25, 0.10, 0.92), đứng thẳng, grasp_pose=[...] "
"Red plate tại (0.15, -0.05, 0.81), nằm ngang, bề mặt phẳng"
Reasoning → Perception:
"Detect: blue cup, red plate" ← danh sách object cần detect lần tiếp
Perception → Action-Exec:
"Object_0 = blue cup: position=[0.25, 0.10, 0.92], grasp_pose=[...] "
Action-Exec → Robot:
waypoints = [(0.25, 0.10, 0.95), (0.25, 0.10, 0.92), ...]
Tại sao chọn text? Vì:
- Universal interface: Mọi LLM/VLM đều hiểu text — dễ swap model mà không cần viết lại connector
- Debug dễ: Bạn đọc được từng message giữa agents, biết chính xác mỗi agent đang "nghĩ" gì
- Flexible: Thêm metadata (confidence score, failure reason) chỉ cần thêm vào string
Spatial consistency được đảm bảo bằng fixed object indices: Perception Agent gán index cố định cho mỗi object (object_0, object_1...) và giữ nguyên xuyên suốt pipeline. Action Agent nhận "pick object_0" và biết chính xác object đó ở đâu, không bị nhầm lẫn.
Tại sao decomposition thắng end-to-end? 4 lý do chính
1. Mỗi agent tối ưu cho một việc
VLA phải học đồng thời: "đây là cái gì?" (perception) + "làm gì tiếp?" (planning) + "di chuyển tay thế nào?" (execution). Gradient flow từ action loss phải travel ngược qua toàn bộ network, thường gây gradient interference — cải thiện perception đôi khi làm xấu action generation và ngược lại.
Khi tách ra, mỗi agent có thể dùng công cụ chuyên biệt: Perception Agent dùng Florence-v2 — detector được train riêng cho object detection, tốt hơn nhiều so với vision encoder trong VLA generic.
2. Spatial grounding chính xác theo metric
VLA đơn xử lý ảnh qua vision tokens — thông tin vị trí 3D bị nén vào latent space và mất đi precision. Perception Agent của ManiAgent tính tọa độ 3D metric thực từ depth + camera calibration, truyền số cụ thể cho Action Agent: [0.25, 0.10, 0.92] thay vì "object ở bên trái, gần lại". Không mất thông tin qua compression.
3. Zero-shot, không cần dữ liệu robot
ManiAgent không cần fine-tune trên demonstration data. Pi0 và CogACT cần hàng chục nghìn robot trajectories để train. ManiAgent chỉ cần swap LLM model — đó là lý do ManiAgent-GPT-5 (86.8%) > ManiAgent-GPT-4o (74.3%): chỉ upgrade 1 component là performance tăng ngay.
4. Failure recovery explicit
Khi Reasoning Agent nhận scene description sau một sub-task và thấy state chưa thay đổi (sub-task fail), nó có thể re-plan ngay lập tức. VLA đơn không có explicit state tracking — nó chỉ "generate action tiếp theo" dựa trên observation hiện tại, không có cơ chế nhận biết "tôi vừa fail và cần làm gì khác".
Giới hạn và thách thức thực tế
ManiAgent không phải giải pháp hoàn hảo. Các failure cases được ghi nhận trong paper:
| Vấn đề | Ví dụ cụ thể | Tại sao xảy ra |
|---|---|---|
| Occlusion | Cà tím bị che bởi viền sink → detect nhầm vị trí | Florence-v2 không handle partial occlusion tốt |
| Height ambiguity | Khối xếp lên nhau → grasp point tính sai độ cao | Depth estimation error ở vertical surfaces |
| Object confusion | Ớt xanh + ớt đỏ → Reasoning Agent nhầm target | Appearance similarity trong scene description |
| Depth-RGB misalign | SimplerEnv bug intermittent → underestimate performance | Sensor synchronization issue trong simulator |
| IK failures | Arm đặt object ngoài workspace → dừng | Thiếu constraint về robot reach trong trajectory planning |
Trong data collection thực tế (551 trajectories), có 15 lần can thiệp thủ công — success rate thực là 81.5%, không phải 100%.
Đặc biệt, task "Move eggplant" là điểm yếu nhất: ManiAgent-GPT-5 chỉ đạt 72.2%, thấp hơn pi0 (79.2%). Occlusion vẫn là bài toán chưa được giải quyết tốt ở mọi kiến trúc.
ManiAgent như máy tạo dữ liệu
Một ứng dụng ít được chú ý nhưng rất thực tiễn: ManiAgent có thể tự động thu thập dữ liệu training cho VLA models khác.
Nhóm tác giả đã dùng ManiAgent để collect 551 trajectories cho task "Place carrot on plate" — 450 valid trajectories (81.5% success). Tổng thời gian: 19.5 giờ (~2 phút/trajectory). Dataset này sau đó được dùng để train CogACT VLA, cho kết quả tương đương với dataset thu thập bằng tay của con người.
Điều này mở ra khả năng: thay vì hàng nghìn giờ teleop của kỹ sư, một nhóm nhỏ có thể deploy ManiAgent để tự động generate dữ liệu training cho specialized VLA models.
Ý nghĩa với người làm robotics
Bài học lớn nhất từ ManiAgent: bạn không cần một siêu model để làm manipulation tốt. Bạn cần:
- Đúng tool cho đúng việc: detector tốt cho perception, LLM mạnh cho reasoning, action cache cho execution
- Interface rõ ràng: text-based communication giữa agents = dễ debug, dễ thay thế từng component
- State tracking explicit: biết đã làm gì, còn lại gì → recovery khi fail
- Zero-shot generalization: không phụ thuộc vào robot-specific training data
Điều này có nghĩa là một nhóm nhỏ có thể build hệ thống manipulation mạnh bằng cách kết hợp off-the-shelf components — không cần dataset triệu bước, không cần GPU cluster để train VLA.
Trong bài tiếp theo, chúng ta sẽ đi sâu vào Perception Agent: cách Florence-v2 detect objects với zero-shot, cách tính tọa độ 3D từ depth map, và cách generate grasp pose cho gripper thực tế.
Bài viết liên quan
- Bài 2: Perception Agent & Grasp Planning — Thiết kế bộ mắt cho robot manipulation
- Bài 3: ALRM, CAP vs TAP — Ba paradigm lập kế hoạch hành động so sánh trực tiếp
- Bài 5: Sim-to-Real Deploy — Đưa SAP Pipeline ra Robot Thật
- VLA Models 2025: Tổng quan các mô hình hành động ngôn ngữ thị giác
- AI cho Robotics 2025: Landscape và xu hướng