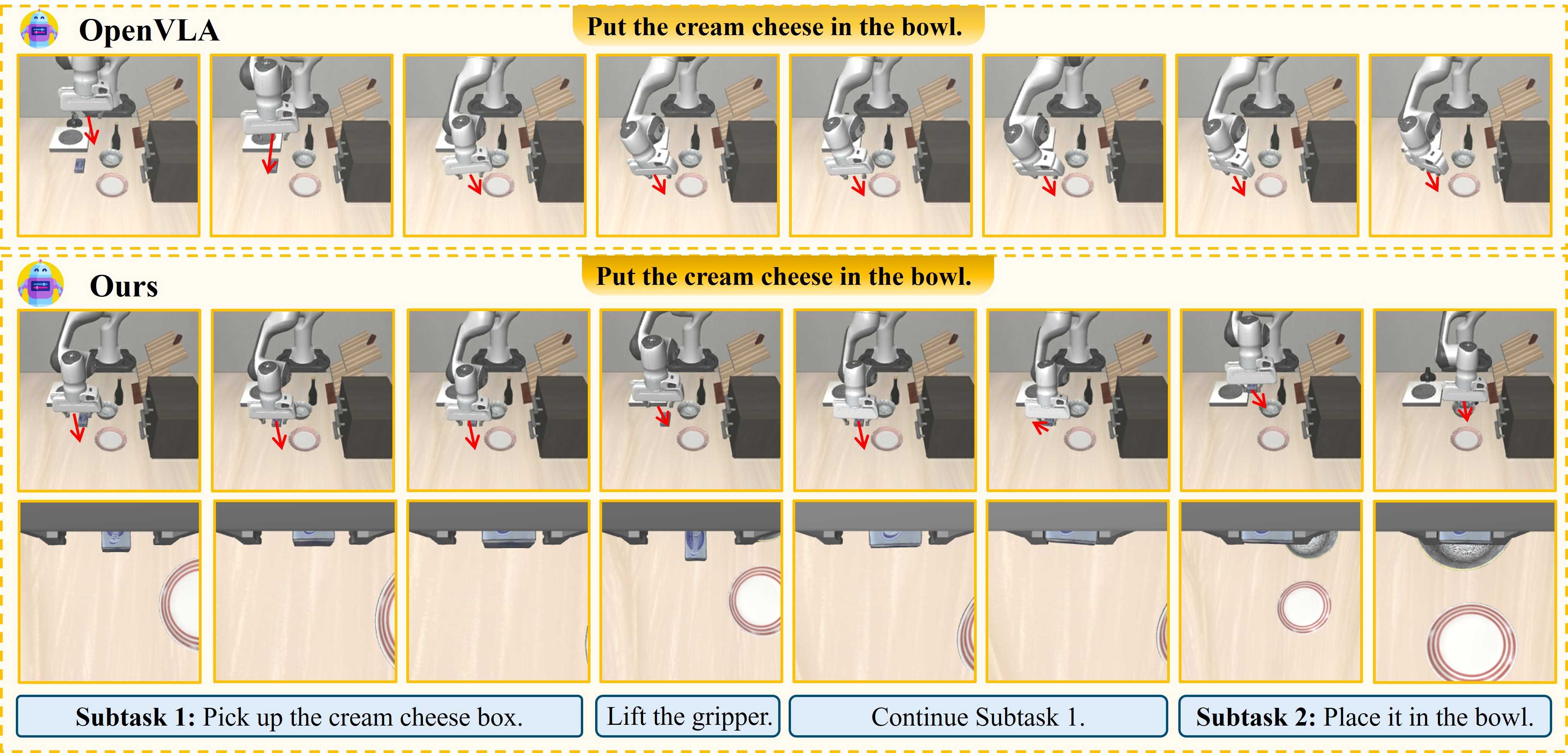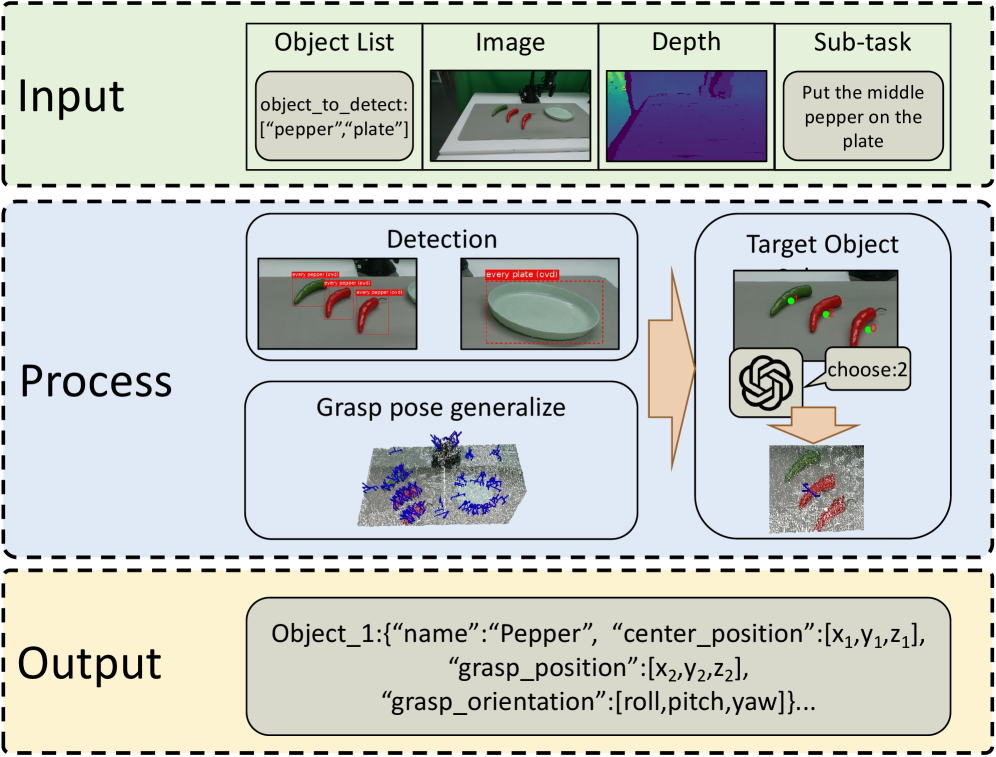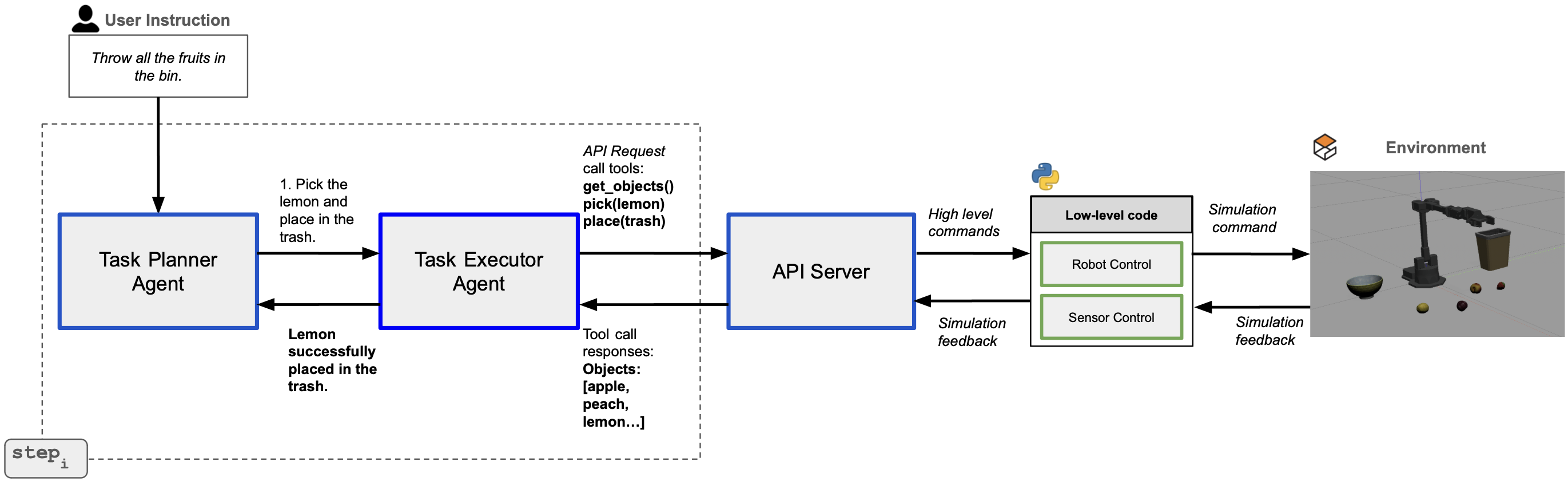
Hãy tưởng tượng bạn là một robot đứng trước bàn bếp. Người dùng bảo: "Cầm cái muỗng lên và đặt vào rổ." Câu hỏi đặt ra: bạn nên viết một đoạn Python script, chạy hết một lần — hay nên hỏi từng câu nhỏ, làm từng bước một, đợi phản hồi rồi mới đi tiếp?
Đây không phải câu hỏi triết học. Đây là hai kiến trúc execution hoàn toàn khác nhau mà paper ALRM: Agentic LLM for Robotic Manipulation (arXiv 2601.19510) của Technology Innovation Institute (TII UAE) đặt ra, so sánh trực tiếp trên 56 task với 10 LLM khác nhau — từ Claude-4.1-Opus đến Falcon-H1-7B — và cho ra kết quả đáng bất ngờ.
Đọc xong bài này, bạn sẽ hiểu tại sao hai mode này tồn tại, khi nào nên chọn cái nào, và con số thực tế là bao nhiêu.
Roadmap series
| # | Bài | Nội dung |
|---|---|---|
| 1 | Tại sao Multi-Agent thắng VLA? | ManiAgent 86.8% vs pi0 55.7% |
| 2 | Perception Agent & Grasp Planning | Florence-v2, AnyGrasp, tọa độ 3D |
| 3 | ALRM: CaP vs TaP trong ReAct ← bạn đang ở đây | Hai execution mode, benchmark 10 LLMs |
| 4 | SAP Verifier: Self-Check trước khi thực hiện | Tránh lỗi execution với verifier agent |
| 5 | Sim-to-Real Deploy Pipeline | Từ Gazebo ra robot thật |
ALRM là gì và nó giải quyết vấn đề gì?
Trước ALRM, hầu hết các hệ thống LLM-for-robotics đều mắc một vấn đề cơ bản: thiếu cơ chế closed-loop. LLM nhận lệnh, sinh ra hành động, robot chạy — xong. Nếu robot cầm nhầm đồ vật, hệ thống không tự biết để sửa. Nó cần người can thiệp thủ công.
ALRM giải quyết điều này bằng kiến trúc 3 tầng:
Tầng 1 — Task Planner Agent: Nhận lệnh tiếng tự nhiên từ người dùng (VD: "dọn bàn ăn sáng"), dùng framework ReAct để phân rã thành các subtask nhỏ có thể thực thi (VD: pick spoon → place bowl → move_to home). Planner liên tục nhận observation từ Executor để điều chỉnh kế hoạch nếu cần.
Tầng 2 — Task Executor Agent: Nhận từng subtask từ Planner và thực thi bằng một trong hai mode: Code-as-Policy (CaP) hoặc Tool-as-Policy (TaP). Đây là điểm khác biệt cốt lõi của ALRM.
Tầng 3 — REST API Server: Cầu nối giữa LLM và robot vật lý. Server cung cấp 8 action chuẩn hóa qua hai module nội bộ:
wx250sRobot: điều khiển robot arm qua MoveIt/ROSSimPerception: phát hiện vật thể qua Gazebo
REST API — Ngôn ngữ chung giữa LLM và Robot
Trước khi đi vào CaP và TaP, cần hiểu ngữ vựng cơ bản. ALRM định nghĩa 8 primitive action chia thành 3 nhóm:
| Nhóm | Action | Mô tả |
|---|---|---|
| Control | pick(object_name) |
Cầm vật thể theo tên |
| Control | place(location) |
Đặt xuống vị trí chỉ định |
| Control | move_to(pose) |
Di chuyển đến tọa độ cụ thể |
| Control | move_to_home_pos() |
Về vị trí home an toàn |
| Perception | get_objects() |
Trả về danh sách vật thể trong scene |
| Perception | get_reference_names() |
Lấy tên các reference point (basket, table, …) |
| Pose | compute_grasp(object) |
Tính pose grasp tối ưu cho vật thể |
| Pose | get_pose(object) |
Lấy pose hiện tại của vật thể |
Tám action này là giao diện bất biến — dù bạn dùng CaP hay TaP, dù LLM là GPT-5 hay Falcon-H1-7B, cuối cùng đều phải gọi qua 8 lệnh này. Đây là thiết kế thông minh: tách biệt reasoning layer (LLM) khỏi execution layer (robot).
Code-as-Policy (CaP) — Viết script, chạy một lần
Cách hoạt động: LLM nhận mô tả subtask + định nghĩa đầy đủ của 8 hàm Python (signature, docstring, một ví dụ pick-and-place mẫu), rồi sinh ra toàn bộ đoạn Python code để xử lý subtask đó trong một lần duy nhất.
Ví dụ, với subtask "pick the spoon and place it in the basket", CaP sẽ sinh ra code tương tự:
# CaP output — toàn bộ logic trong 1 lần gọi LLM
objects = get_objects()
if "spoon" in objects:
grasp_pose = compute_grasp("spoon")
move_to(grasp_pose)
pick("spoon")
basket_pose = get_pose("basket")
move_to(basket_pose)
place("basket")
move_to_home_pos()
Code này được gửi đến REST API server, thực thi từ đầu đến cuối, và trả về kết quả.
Ưu điểm của CaP:
- Nhanh: Chỉ cần 1 lần gọi LLM cho toàn bộ subtask → latency thấp
- Deterministic: Code sinh ra có thể đọc và kiểm tra trước khi chạy
- Dễ debug: Nếu lỗi, bạn thấy ngay dòng code nào sai
Nhược điểm của CaP:
- Không adaptive: Nếu
get_objects()trả về scene khác với dự đoán, code đã sinh ra không tự sửa - Phụ thuộc vào LLM mạnh: Model yếu sinh code lỗi cú pháp hoặc logic sai
- Không xử lý được conditional phức tạp: Task yêu cầu nhiều vòng lặp reasoning khó mã hóa trong 1 đoạn code
Tool-as-Policy (TaP) — Hỏi, làm, nhận phản hồi, lặp lại
Cách hoạt động: LLM được cung cấp các tool definition (schema JSON của 8 action), nhưng thay vì sinh code, nó gọi từng tool một mỗi bước. Kết quả của mỗi tool call được append vào conversation history và gửi lại cho LLM để nó quyết định bước tiếp theo.
Với cùng subtask "pick the spoon and place it in the basket", TaP hoạt động như vòng lặp ReAct sau:
Step 1: LLM → tool_call: get_objects()
Obs: ["spoon", "spatula", "basket", "coke_can"]
Step 2: LLM → tool_call: compute_grasp("spoon")
Obs: {position: [0.3, 0.1, 0.05], orientation: [0, 0, 0.7, 0.7]}
Step 3: LLM → tool_call: move_to({position: [0.3, 0.1, 0.05], ...})
Obs: "Move successful"
Step 4: LLM → tool_call: pick("spoon")
Obs: "Pick successful"
Step 5: LLM → tool_call: get_pose("basket")
Obs: {position: [0.5, -0.2, 0.1], ...}
Step 6: LLM → tool_call: place("basket")
Obs: "Place successful"
Step 7: LLM → tool_call: move_to_home_pos()
Obs: "Home position reached"
→ DONE
Mỗi bước, LLM thấy toàn bộ lịch sử — nó biết robot đang ở đâu, đã làm gì, và phản hồi là gì. Nếu bước 4 (pick) thất bại vì object bị che khuất, LLM có thể điều chỉnh chiến lược ở bước 5 thay vì tiếp tục mù quáng.
Ưu điểm của TaP:
- Adaptive: Phản hồi real-time từ robot ảnh hưởng trực tiếp đến quyết định tiếp theo
- Xử lý tốt task phức tạp: Multi-step conditional logic, error recovery tự nhiên
- Model lớn tận dụng được toàn bộ: GPT-5, Claude-4.1-Opus hiệu quả hơn vì có context đầy đủ
Nhược điểm của TaP:
- Chậm hơn đáng kể: Mỗi tool call = 1 lần round-trip LLM → latency tích lũy nhanh
- Model nhỏ hay thất bại: Yêu cầu LLM hiểu schema tool call chính xác — model 7B thường không đủ reliable
- Token cost cao hơn: Conversation history tăng dần theo mỗi bước
Benchmark — 56 task, 3 môi trường, 10 LLM
Để so sánh khách quan, ALRM xây dựng benchmark với thiết kế rất kỹ:
3 môi trường Gazebo:
- Kitchen Utensils: muỗng, spatula, lon coke, rổ đựng
- Boxes: thùng giấy, thùng gỗ, thùng kim loại, container
- Fruits: dâu tây, mận, chanh, đào, tô, thùng rác
56 task — mỗi task có 6 biến thể ngôn ngữ khác nhau (từ lệnh rõ ràng "pick the red apple" đến mô tả gián tiếp "the round fruit that tastes sweet, put it away") để test khả năng hiểu ngữ cảnh của LLM.
Scoring — 3 judge models (majority voting):
- Score 2: Tất cả subtask hoàn thành đúng với tham số chính xác
- Score 1: Ít nhất 1 subtask đúng, nhưng có lỗi hoặc thiếu sót
- Score 0: Không có subtask nào hoàn thành đúng
Ba judge là GPT-4.1, Claude-Sonnet-4, và Gemini-2.5-Flash — dùng majority voting để tránh bias từ một model duy nhất.
Kết quả — Ai thắng, ai thua?
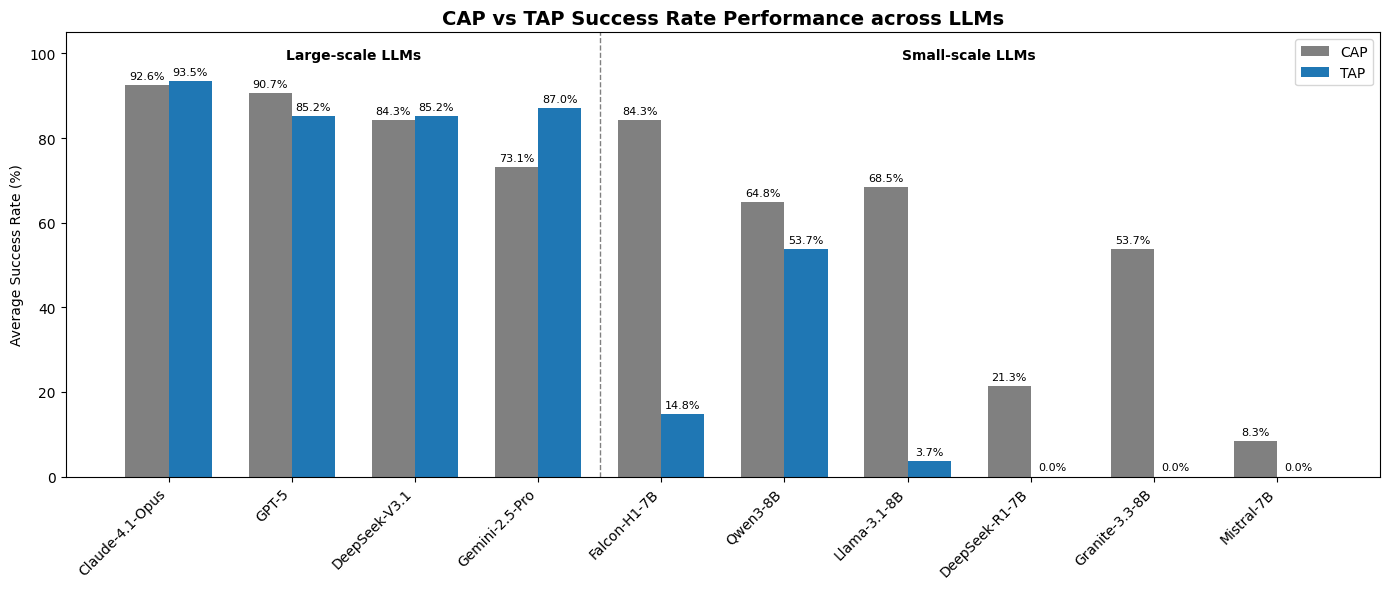
Large-scale models
| Model | CaP Success | CaP Latency | TaP Success | TaP Latency |
|---|---|---|---|---|
| Claude-4.1-Opus | 92.6% | 33.4s | 93.5% | 82.6s |
| GPT-5 | 90.7% | 145.6s | 85.2% | 113.9s |
| DeepSeek-V3.1 | 84.3% | 69.8s | 85.2% | 161.7s |
| Gemini-2.5-Pro | 73.1% | 52.6s | 87.0% | 117.4s |
Quan sát đáng chú ý: Claude-4.1-Opus không chỉ dẫn đầu về accuracy mà còn nhanh nhất trong nhóm large model ở CaP (33.4s so với GPT-5 145.6s — nhanh hơn 4.3 lần). Với TaP, accuracy của Opus tăng nhẹ (93.5% vs 92.6%), nhưng latency tăng gấp 2.5 lần.
Gemini-2.5-Pro có hành vi ngược: CaP 73.1% nhưng TaP 87.0% — model này có khả năng reasoning theo bước tốt hơn nhiều so với việc tổng hợp code một lần.
Small-scale (open-source) models
| Model | CaP Success | CaP Latency | TaP Success |
|---|---|---|---|
| Falcon-H1-7B | 84.3% | 24.9s | Không ổn định |
| Llama-3.1-8B | 68.5% | 20.1s | Thất bại |
| Qwen3-8B | 64.8% | 343.3s | 53.7% |
| Granite-3.3-8B | 53.7% | 24.5s | Thất bại |
| DeepSeek-R1-7B | 21.3% | 53.6s | Thất bại |
| Mistral-7B | 8.3% | 19.0s | Thất bại |
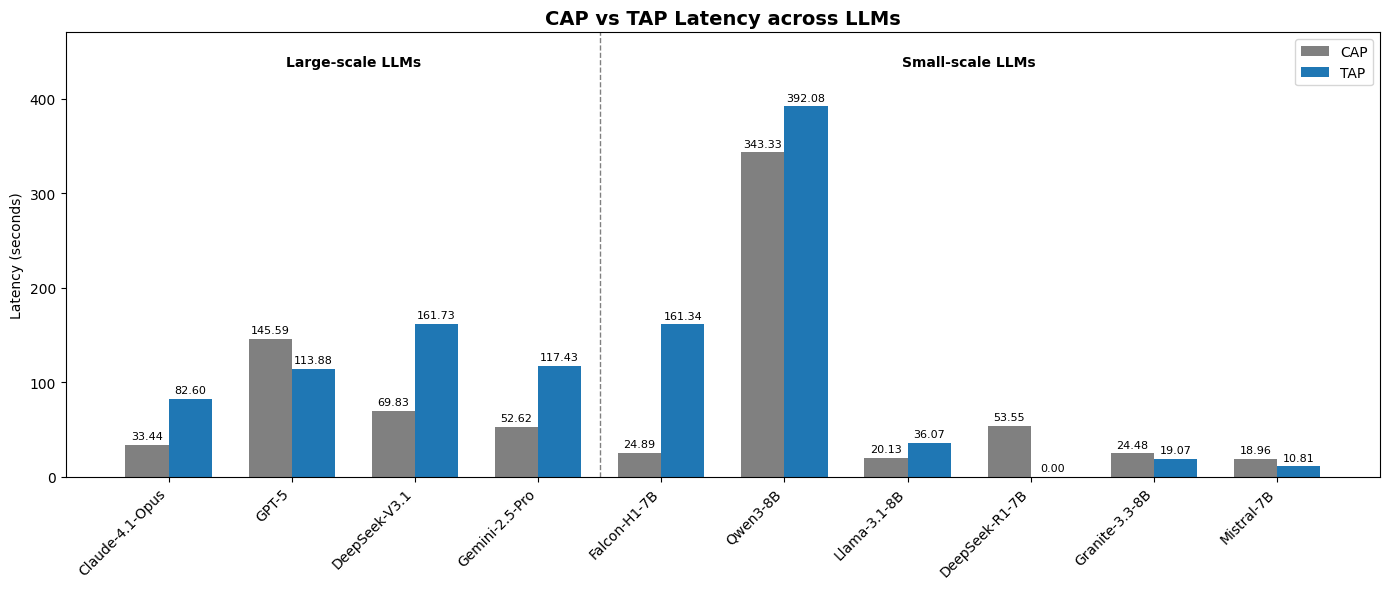
Falcon-H1-7B là bất ngờ lớn nhất của benchmark. Với 84.3% CaP success rate và latency chỉ 24.9s, nó ngang ngửa với DeepSeek-V3.1 (một model lớn gấp nhiều lần) và vượt xa mọi open-source 7-8B khác. Đây là lý do TII UAE phát triển Falcon-H1 với kiến trúc Hybrid SSM-Transformer — tối ưu cho tool-use và code generation.
Qwen3-8B là trường hợp kỳ lạ: CaP latency 343.3s (chậm nhất trong toàn bộ benchmark!) nhưng lại là open-source model duy nhất có TaP hoạt động được (53.7%). Điều này gợi ý Qwen3-8B mạnh về structured reasoning nhưng yếu về code generation tốc độ cao.
Khi nào nên dùng CaP, khi nào dùng TaP?
Đây là câu hỏi thực tế nhất. Dựa trên kết quả benchmark, có thể rút ra nguyên tắc rõ ràng:
Chọn CaP khi:
- Task có cấu trúc rõ ràng, ít conditional branching (pick → place, không cần kiểm tra trung gian)
- Bạn ưu tiên latency thấp (robot warehouse tốc độ cao, số lần gọi/phút cao)
- LLM bạn dùng là open-source model 7-8B (CaP là lựa chọn DUY NHẤT vì TaP quá khó với model nhỏ)
- Bạn muốn code có thể inspect và validate trước khi chạy trên robot thật
Chọn TaP khi:
- Task phức tạp, cần error recovery real-time (VD: nếu object bị che, phải tìm cách khác)
- Bạn dùng large model (GPT-5, Claude-4.1-Opus, Gemini-2.5-Pro) và accuracy quan trọng hơn tốc độ
- Môi trường robot không ổn định, scene thay đổi trong khi thực thi
- Task yêu cầu nhiều vòng perception-action (nhìn → quyết định → làm → nhìn lại → quyết định tiếp)
Bảng quyết định nhanh:
| Điều kiện | Khuyến nghị |
|---|---|
| Open-source model 7-8B | CaP (TaP không reliable) |
| Large model + task đơn giản | CaP (nhanh hơn 2-3x) |
| Large model + task phức tạp | TaP (accuracy cao hơn) |
| Latency < 30s là requirement | CaP (hoặc Claude-4.1-Opus + CaP) |
| Robot thật, môi trường dynamic | TaP (adaptive hơn) |
| Simulation testing/development | Bắt đầu CaP, nâng lên TaP nếu cần |
Tại sao Claude-4.1-Opus thắng cả hai chiều?
Đây là điều thú vị nhất từ benchmark. Thông thường, một model mạnh về code generation (CaP) chưa chắc mạnh về tool-calling iterative (TaP) và ngược lại. Nhưng Opus đạt top 1 ở cả hai.
Lý do theo phân tích của paper: Opus có khả năng instruction following cực kỳ chính xác — khi sinh code Python, nó tuân thủ API contract (signature đúng, type đúng, edge case xử lý đúng). Khi dùng TaP, nó cũng parse tool call schema chính xác và không hallucinate parameter không tồn tại. Cả hai mode đều yêu cầu precision cao — và đây là thế mạnh của Opus.
Điều này cũng giải thích tại sao Mistral-7B chỉ đạt 8.3% CaP: model này thiếu khả năng generate syntactically correct Python với API constraints chặt.
Kết nối với pipeline thực tế
Bài trước về Perception Agent cho thấy Florence-v2 + AnyGrasp sinh ra tọa độ 3D cho vật thể. Output đó chính là input của compute_grasp() và get_pose() trong ALRM API.
Bài tiếp theo về SAP Verifier sẽ giải thích cách thêm một verification layer trước khi Executor thực thi — đặc biệt quan trọng khi dùng CaP vì code sinh ra cần được validate trước khi chạy trên robot thật.
Tóm tắt
- ALRM dùng kiến trúc 3 tầng: Task Planner (ReAct) → Task Executor (CaP/TaP) → REST API Server
- CaP sinh toàn bộ Python code trong 1 lần gọi LLM → nhanh, deterministic, phù hợp model nhỏ
- TaP gọi từng tool một, nhận observation, quyết định bước tiếp → chậm hơn, adaptive hơn, yêu cầu model lớn
- Claude-4.1-Opus dẫn đầu cả hai mode: 92.6% CaP (33.4s) và 93.5% TaP
- Falcon-H1-7B là champion open-source: 84.3% CaP với latency 24.9s — ngang DeepSeek-V3.1
- Nguyên tắc chọn mode: Open-source/latency-critical → CaP. Large model/task phức tạp → TaP.