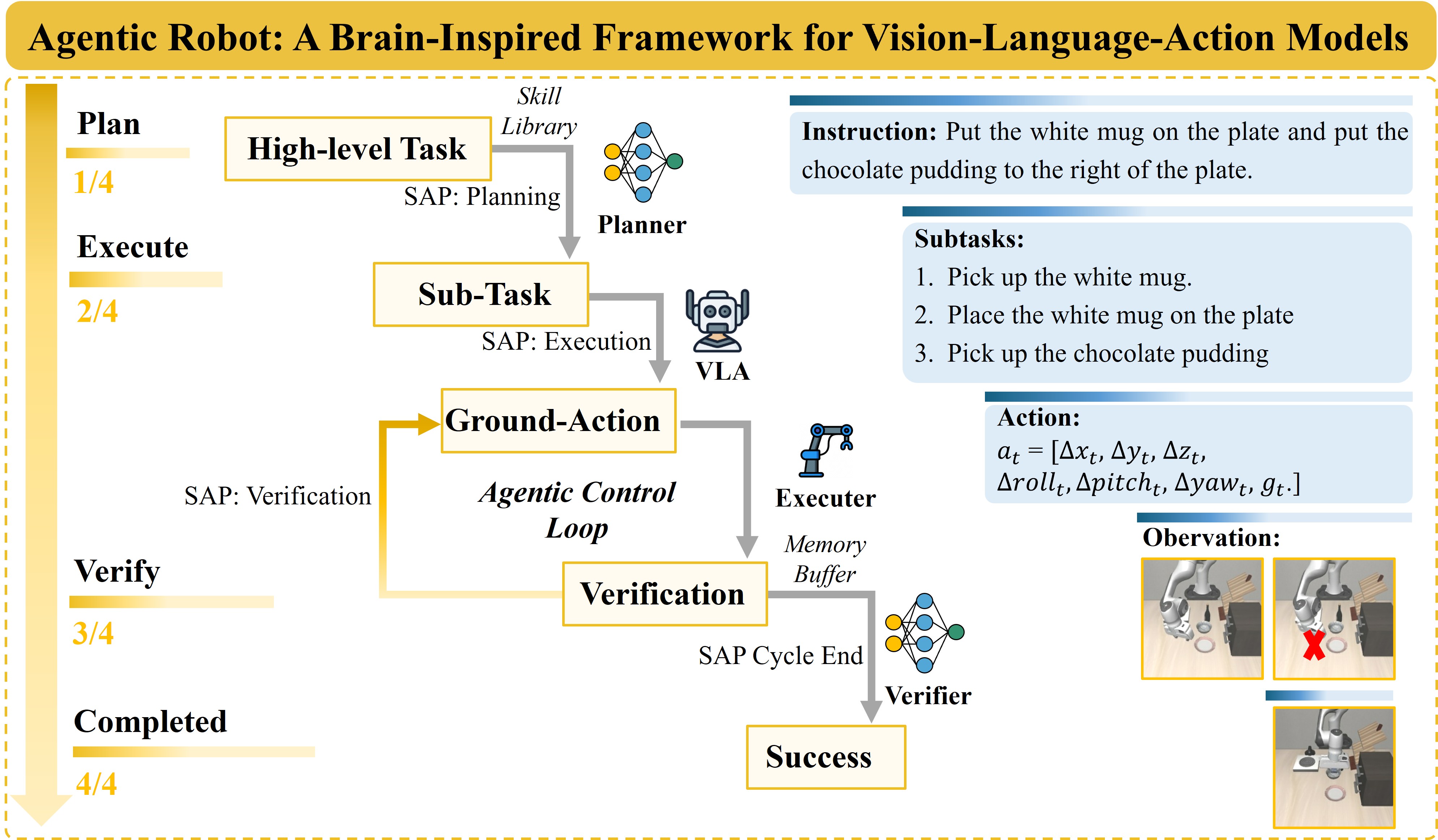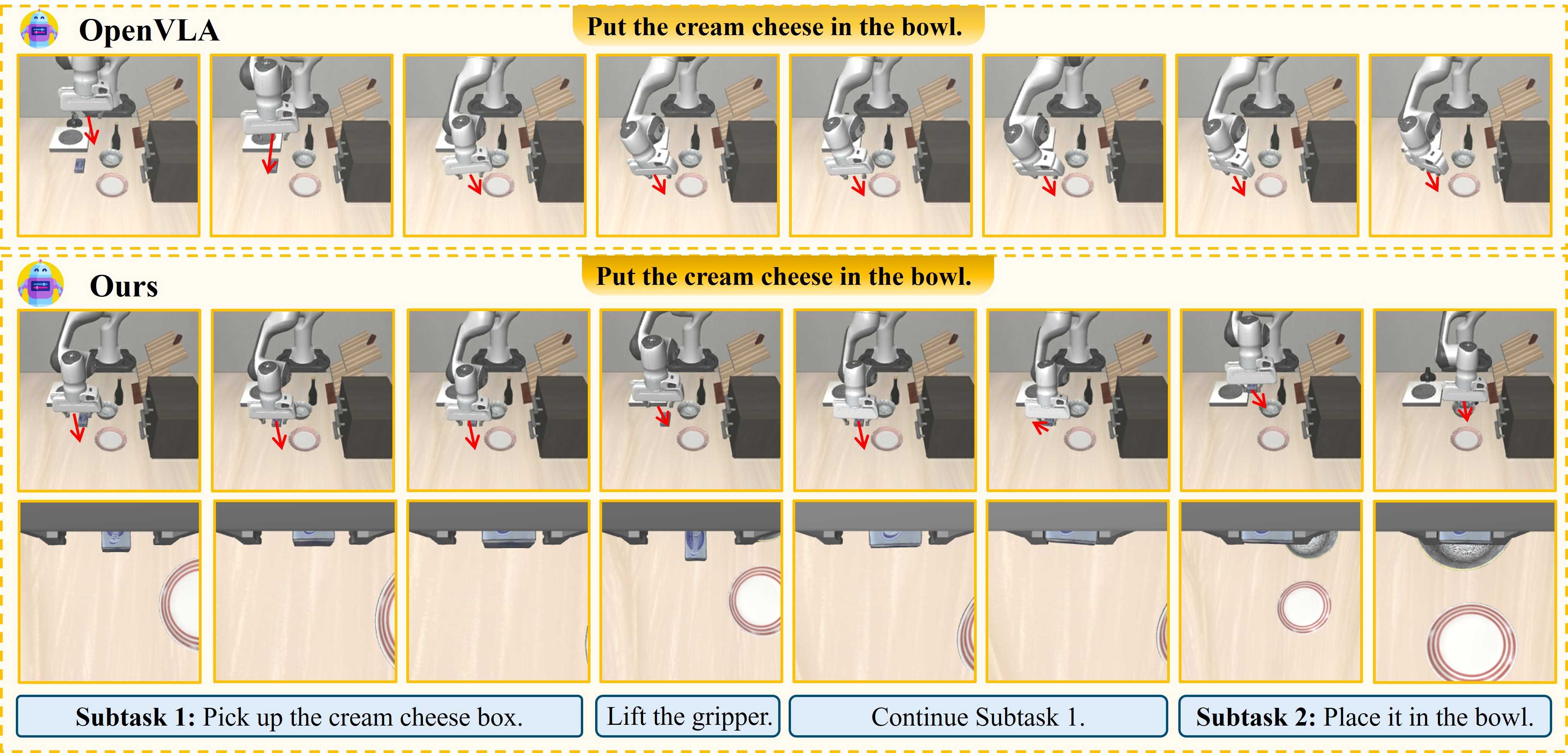
Robot nhìn vào bàn, thấy một chiếc cốc cà phê. Câu hỏi tưởng đơn giản: "cốc đó ở đâu trong không gian 3D, và tôi phải cầm nó như thế nào?" Nhưng để trả lời câu hỏi này một cách chính xác đủ để robot thực sự nhặt được, bạn cần giải quyết hai bài toán phức tạp hoàn toàn khác nhau cùng một lúc: nhận diện ngôn ngữ tự nhiên và hình học không gian 3D.
Đây là lý do bài trước (Tại sao Multi-Agent thắng VLA đơn thuần?) cho thấy rằng tách biệt perception thành một agent riêng là đúng đắn. Bài này đi sâu vào bên trong Perception Agent của ManiAgent — kiến trúc đã đạt 86.8% trên SimplerEnv — xem nó làm gì, làm thế nào, và bạn có thể tự build lại một module tương tự.
Roadmap series: AI Agent Pipeline cho Robot Manipulation
| # | Bài | Trạng thái |
|---|---|---|
| 1 | Tại sao Multi-Agent thắng VLA? | ✅ Đã đăng |
| 2 | Perception Agent: Florence-v2 + AnyGrasp ← bạn đang ở đây | 📍 |
| 3 | ALRM, CAP vs TAP: Ba paradigm lập kế hoạch | 🔜 |
| 4 | SAP Verifier: Self-Verification trong pipeline | 🔜 |
| 5 | Sim-to-Real Deploy | 🔜 |
Perception Agent làm gì?
Hãy nghĩ Perception Agent như một nhân viên tiếp nhận kho hàng: nhận yêu cầu ("lấy cho tôi cái hộp đỏ"), tìm đúng vật trong kho, xác định nó đang ở vị trí nào trên giá, và báo lại vị trí kèm cách tiếp cận tốt nhất. Từ đó người giao hàng (Reasoning Agent + Action Agent) mới biết đường đi.
Về kỹ thuật, Perception Agent của ManiAgent nhận vào:
- Ảnh RGB từ camera (RealSense D435 trong paper gốc)
- Ảnh depth (độ sâu tính bằng mét)
- Danh sách tên vật thể cần tìm (từ Reasoning Agent gửi xuống)
Và trả ra một dictionary spatial_info gồm:
object_label— tên vật thể đã nhận diệnposition— tọa độ 3D tâm vật thể trong hệ tọa độ robot base[x, y, z](đơn vị mét)grasp_pose— tư thế cầm 6-DoF: ma trận quay 3×3 + vector tịnh tiến 3D + điểm chất lượng
Để làm được điều đó, pipeline dùng hai model phối hợp: Florence-v2 cho phần ngôn ngữ → ảnh, AnyGrasp cho phần hình học → pose.
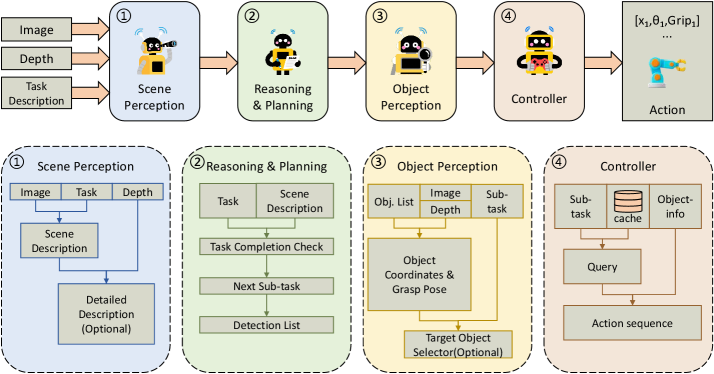
Perception Agent pipeline — nguồn: ManiAgent paper (arXiv:2510.11660)
Florence-v2: Đôi mắt nói được tiếng người
Vấn đề với object detection truyền thống
YOLO, Faster R-CNN, hay Detectron2 — tất cả đều cần bạn định nghĩa trước danh sách class cố định. Muốn detect "cốc cà phê trắng có quai"? Bạn cần dataset với label đó, training loop, rồi mới có model. Với robot manipulation trong môi trường thực tế, bạn không thể train model cho mọi vật thể người dùng có thể yêu cầu.
Open-vocabulary detection giải quyết điều này: model nhận vào ảnh + tên vật thể bất kỳ → khoanh vùng vị trí. Không cần fine-tune, không cần dataset mới.
Kiến trúc Florence-2
Florence-2 (arXiv:2311.06242, Microsoft Research, CVPR 2024) dùng kiến trúc sequence-to-sequence:
- Backbone: DaViT (Dual-attention Vision Transformer) — mã hóa ảnh thành visual token embeddings
- Encoder-decoder: transformer chuẩn, xử lý cả visual embeddings và text prompt
- Training: dataset FLD-5B — 5.4 tỷ annotation trên 126 triệu ảnh, bao gồm bounding boxes, segmentation masks, captions, grounding
Điểm then chốt: Florence-2 không học theo kiểu "nhận dạng class", mà học cách dịch prompt ngôn ngữ thành tọa độ. Khi bạn gửi <OPEN_VOCABULARY_DETECTION>coffee cup, model dịch câu đó thành bounding box. Tương tự như cách một người hiểu "chỉ cho tôi cái ly" mà không cần định nghĩa trước "ly là gì".
Task prompts của Florence-2
Florence-2 dùng hệ thống task prompt để chọn loại output:
| Prompt | Nhiệm vụ |
|---|---|
<OD> |
Detect tất cả vật thể trong ảnh (tự đặt tên) |
<OPEN_VOCABULARY_DETECTION> |
Detect vật thể theo tên bất kỳ bạn chỉ định |
<CAPTION_TO_PHRASE_GROUNDING> |
Grounding — liên kết cụm từ trong caption với vùng ảnh |
<DENSE_REGION_CAPTION> |
Mô tả chi tiết từng vùng trong ảnh |
Với Perception Agent, ta dùng <OPEN_VOCABULARY_DETECTION> vì nó nhận tên vật thể từ Reasoning Agent và tìm đúng vật đó.
Code: Load và chạy Florence-v2
import torch
from PIL import Image
from transformers import AutoProcessor, Florence2ForConditionalGeneration
# Load model (chạy 1 lần lúc khởi động)
MODEL_ID = "microsoft/Florence-2-large"
model = Florence2ForConditionalGeneration.from_pretrained(
MODEL_ID,
torch_dtype=torch.float16,
device_map="cuda"
)
processor = AutoProcessor.from_pretrained(MODEL_ID, trust_remote_code=True)
model.eval()
def detect_object(rgb_image: Image.Image, object_name: str) -> dict:
"""
Phát hiện vật thể theo tên, trả về bounding box và label.
Args:
rgb_image: PIL Image (RGB)
object_name: tên vật thể cần tìm, ví dụ "coffee cup"
Returns:
{'bboxes': [[x1, y1, x2, y2]], 'bboxes_labels': ['coffee cup']}
"""
task_prompt = "<OPEN_VOCABULARY_DETECTION>"
text_input = object_name
inputs = processor(
text=task_prompt,
images=rgb_image,
text_input=text_input,
return_tensors="pt"
).to(model.device, torch.float16)
with torch.no_grad():
generated_ids = model.generate(
**inputs,
max_new_tokens=1024,
num_beams=3,
do_sample=False
)
generated_text = processor.batch_decode(
generated_ids, skip_special_tokens=False
)[0]
parsed = processor.post_process_generation(
generated_text,
task=task_prompt,
image_size=rgb_image.size # (width, height)
)
# Kết quả dạng: {'<OPEN_VOCABULARY_DETECTION>': {'bboxes': [...], 'bboxes_labels': [...]}}
return parsed.get(task_prompt, {})
Kết quả trả về dạng:
{
'bboxes': [[156.2, 203.4, 289.1, 341.7]], # [x1, y1, x2, y2] pixel
'bboxes_labels': ['coffee cup']
}
Từ pixel sang không gian 3D
Florence-v2 cho chúng ta bounding box trong tọa độ pixel — nhưng robot cần biết vật thể đó ở đâu trong không gian thực 3D. Đây là bước projection ngược (back-projection) dùng camera model.
Camera pinhole model
Camera như một lỗ kim — ánh sáng từ điểm 3D (X, Y, Z) đi qua lỗ kim và chiếu lên sensor tại pixel (u, v):
u = fx * (X / Z) + cx
v = fy * (Y / Z) + cy
Trong đó:
fx,fy: focal length tính bằng pixel (thường khoảng 600-900 với RealSense D435)cx,cy: optical center (thường gần giữa ảnh)Z: depth (khoảng cách từ camera đến vật)
Đảo ngược để tìm 3D từ pixel + depth:
X = (u - cx) * Z / fx
Y = (v - cy) * Z / fy
Z = depth[v, u] # lấy từ depth image
Code: Pixel → 3D trong hệ robot base
import numpy as np
def pixel_to_3d(
u: float, v: float,
depth_image: np.ndarray,
camera_intrinsics: dict,
T_base_cam: np.ndarray
) -> np.ndarray:
"""
Chuyển tọa độ pixel sang 3D trong hệ robot base.
Args:
u, v: tọa độ pixel (float, có thể là tâm bounding box)
depth_image: ảnh depth (H, W), đơn vị mét
camera_intrinsics: {'fx': ..., 'fy': ..., 'cx': ..., 'cy': ...}
T_base_cam: ma trận chuyển hệ 4x4 từ camera → robot base
Returns:
Tọa độ 3D [x, y, z] trong hệ robot base (đơn vị mét)
"""
fx = camera_intrinsics['fx']
fy = camera_intrinsics['fy']
cx = camera_intrinsics['cx']
cy = camera_intrinsics['cy']
# Lấy depth tại pixel (u, v) — dùng trung bình vùng 5x5 để giảm noise
v_int, u_int = int(round(v)), int(round(u))
v0, v1 = max(0, v_int - 2), min(depth_image.shape[0], v_int + 3)
u0, u1 = max(0, u_int - 2), min(depth_image.shape[1], u_int + 3)
patch = depth_image[v0:v1, u0:u1]
valid = patch[patch > 0.1] # loại giá trị noise
if len(valid) == 0:
raise ValueError(f"Depth invalid tại pixel ({u}, {v})")
Z = float(np.median(valid))
# Back-projection sang hệ camera
X_cam = (u - cx) * Z / fx
Y_cam = (v - cy) * Z / fy
point_cam = np.array([X_cam, Y_cam, Z, 1.0])
# Chuyển sang hệ robot base
point_base = T_base_cam @ point_cam
return point_base[:3] # [x, y, z]
def get_object_3d_position(detection_result, depth_image, camera_intrinsics, T_base_cam):
"""Lấy 3D position của vật thể từ kết quả Florence-v2."""
if not detection_result.get('bboxes'):
return None
# Dùng bounding box đầu tiên (highest confidence)
bbox = detection_result['bboxes'][0]
x1, y1, x2, y2 = bbox
# Tâm bounding box
u_center = (x1 + x2) / 2.0
v_center = (y1 + y2) / 2.0
return pixel_to_3d(u_center, v_center, depth_image, camera_intrinsics, T_base_cam)
AnyGrasp: Bàn tay thông minh từ point cloud
6-DoF grasp là gì?
Khi bạn cầm một cốc cà phê, bạn không chỉ biết "đặt tay vào đây" — bạn biết cả góc tiếp cận, hướng ngón tay, độ mở của bàn tay. Đó là 6 bậc tự do (6-DoF):
- 3 DoF vị trí: x, y, z — tâm của grasp
- 3 DoF góc quay: pitch, yaw, roll — hướng tiếp cận
Với gripper 2-finger thông thường (như Robotiq 2F-85), grasp pose được biểu diễn bằng:
- Ma trận quay R (3×3): trục của gripper trong không gian
- Vector tịnh tiến t (3D): vị trí tâm giữa hai ngón
- Width: khoảng mở của gripper (tính bằng mét)
- Score: điểm chất lượng (càng cao càng tốt)
AnyGrasp: approach khác với grasp detection truyền thống
Grasp detection cũ (GPD, GQ-CNN) thường dùng sampling — đề xuất nhiều grasp candidate ngẫu nhiên rồi score từng cái. Chậm và bỏ sót nhiều điểm tốt.
AnyGrasp (Fang et al., IEEE T-RO 2023) dùng dense prediction: với mỗi điểm trong point cloud, model dự đoán trực tiếp xác suất nó có thể là điểm grasp tốt (gọi là graspness score). Sau đó, với những điểm có graspness cao, model sinh ra toàn bộ 6-DoF grasp parameters cùng lúc.
Hình ảnh dễ nhớ: AnyGrasp như một thám tử soi toàn bộ hiện trường cùng lúc (dense), không phải đi từng góc một rồi nghi ngờ (sampling).
Kết quả: AnyGrasp có thể xử lý toàn bộ scene với nhiều vật thể, đề xuất hàng trăm grasp candidates, sau đó bạn chọn cái nào phù hợp nhất cho vật thể đang cần gắp.
Code: Gọi AnyGrasp SDK
import numpy as np
import open3d as o3d
from gsnet import AnyGrasp # pip install từ anygrasp_sdk
# Khởi tạo model (chạy 1 lần)
cfgs = {
'checkpoint_path': 'log/checkpoint_detection.tar',
'max_gripper_width': 0.1, # mét — khớp với Robotiq 2F-85
'gripper_height': 0.03,
'top_down_grasp': False, # cho phép grasp từ mọi hướng
'debug': False
}
anygrasp = AnyGrasp(cfgs)
anygrasp.load_net()
def detect_grasps(
rgb_image: np.ndarray, # (H, W, 3) uint8
depth_image: np.ndarray, # (H, W) float32, đơn vị mét
camera_intrinsics: dict,
workspace_lims: list # [xmin, xmax, ymin, ymax, zmin, zmax] trong hệ camera
) -> object:
"""
Sinh grasp candidates từ RGB-D point cloud.
Returns:
GraspGroup đã được NMS và sort by score (best first)
"""
fx = camera_intrinsics['fx']
fy = camera_intrinsics['fy']
cx = camera_intrinsics['cx']
cy = camera_intrinsics['cy']
# Tạo point cloud từ depth image
H, W = depth_image.shape
u_grid, v_grid = np.meshgrid(np.arange(W), np.arange(H))
Z = depth_image.flatten()
X = ((u_grid.flatten() - cx) * Z / fx)
Y = ((v_grid.flatten() - cy) * Z / fy)
# Filter invalid depth (0, inf, nan)
valid_mask = (Z > 0.1) & (Z < 2.0) & np.isfinite(Z)
points = np.stack([X, Y, Z], axis=-1)[valid_mask].astype(np.float32)
colors = (rgb_image.reshape(-1, 3)[valid_mask] / 255.0).astype(np.float32)
# Gọi AnyGrasp
gg, cloud = anygrasp.get_grasp(
points, colors,
lims=workspace_lims,
apply_object_mask=True, # lọc background
dense_grasp=False, # True nếu cần nhiều candidate hơn (chậm hơn)
collision_detection=True # tránh grasp va chạm bàn/shelf
)
if gg is None or len(gg) == 0:
return None
# Non-Maximum Suppression + sort theo score giảm dần
gg = gg.nms().sort_by_score()
return gg
Chọn grasp tốt nhất cho vật thể đã detect
Điểm quan trọng nhất của pipeline: AnyGrasp trả về grasps cho toàn scene — có thể là 50, 100, hay 200 candidates. Bạn cần chọn cái nào liên quan đến vật thể Florence-v2 đã tìm được.
ManiAgent làm điều này bằng cách tìm grasp có điểm grasp gần nhất với tâm 3D của vật thể (trong ngưỡng khoảng cách cho phép):
def select_best_grasp_near_object(
grasp_group,
object_position_3d: np.ndarray, # [x, y, z] trong hệ camera
max_distance: float = 0.05 # 5cm tolerance
):
"""
Chọn grasp có score cao nhất trong vùng lân cận vật thể.
Returns:
Grasp object hoặc None nếu không tìm được
"""
if grasp_group is None:
return None
best_grasp = None
best_score = -1.0
for grasp in grasp_group:
# translation của grasp = tâm giữa hai ngón gripper
grasp_pos = grasp.translation # [x, y, z]
dist = np.linalg.norm(grasp_pos - object_position_3d)
if dist <= max_distance and grasp.score > best_score:
best_score = grasp.score
best_grasp = grasp
return best_grasp
Đóng gói kết quả: spatial_info dict
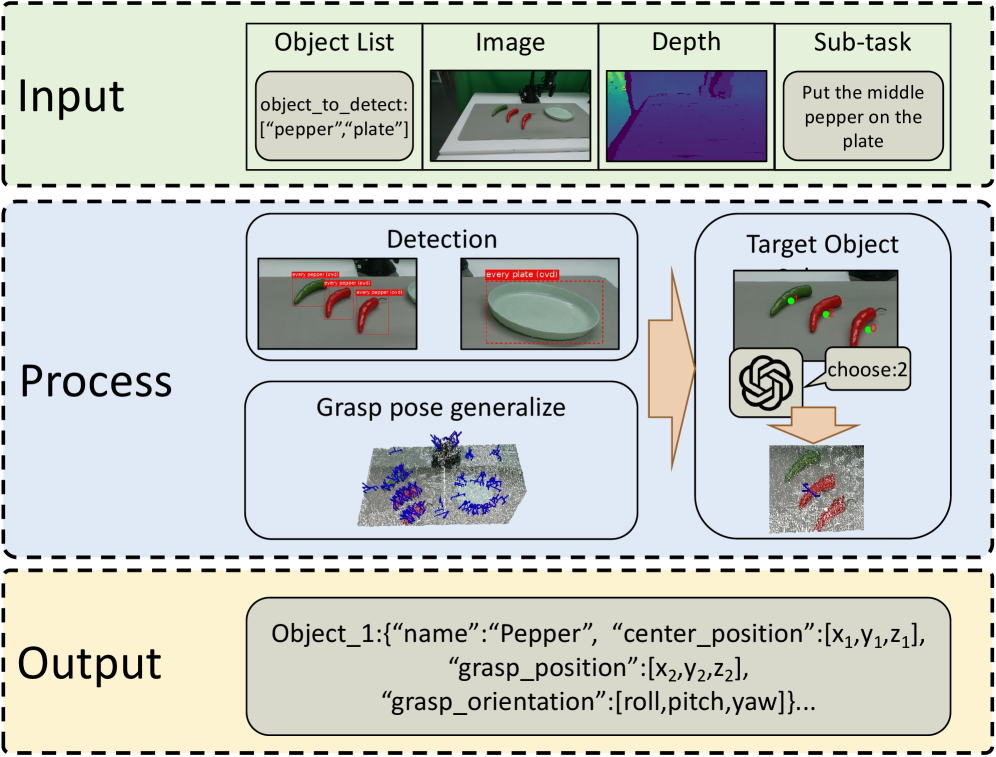
Sau khi có đủ thông tin từ Florence-v2 và AnyGrasp, Perception Agent đóng gói tất cả vào spatial_info và truyền lên Reasoning Agent:
import json
import numpy as np
from PIL import Image
def run_perception_agent(
rgb_image: np.ndarray,
depth_image: np.ndarray,
camera_intrinsics: dict,
T_base_cam: np.ndarray,
object_name: str,
workspace_lims: list
) -> dict:
"""
Perception Agent đầy đủ: nhận RGB-D + tên vật thể → spatial_info.
Args:
rgb_image: numpy array (H, W, 3) uint8
depth_image: numpy array (H, W) float32, đơn vị mét
camera_intrinsics: dict với 'fx', 'fy', 'cx', 'cy'
T_base_cam: ma trận 4x4 float64 (camera → robot base)
object_name: tên vật thể cần tìm, VD: "coffee cup"
workspace_lims: [xmin, xmax, ymin, ymax, zmin, zmax] hệ camera (mét)
Returns:
spatial_info dict hoặc None nếu không tìm được vật thể/grasp
"""
# --- Bước 1: Florence-v2 phát hiện vật thể ---
pil_rgb = Image.fromarray(rgb_image)
detection = detect_object(pil_rgb, object_name)
if not detection.get('bboxes'):
print(f"[Perception] Không tìm thấy '{object_name}' trong ảnh")
return None
# --- Bước 2: Chuyển tâm bounding box sang 3D (hệ camera) ---
bbox = detection['bboxes'][0]
x1, y1, x2, y2 = bbox
u_center = (x1 + x2) / 2.0
v_center = (y1 + y2) / 2.0
# Tọa độ 3D trong hệ camera (cần cho AnyGrasp lookup)
obj_pos_cam = pixel_to_3d(
u_center, v_center, depth_image, camera_intrinsics,
T_base_cam=np.eye(4) # identity → hệ camera
)
# Tọa độ 3D trong hệ robot base (để Reasoning Agent dùng)
obj_pos_base = pixel_to_3d(
u_center, v_center, depth_image, camera_intrinsics, T_base_cam
)
# --- Bước 3: AnyGrasp sinh grasp candidates ---
grasp_group = detect_grasps(
rgb_image, depth_image, camera_intrinsics, workspace_lims
)
# --- Bước 4: Chọn best grasp gần vật thể ---
best_grasp = select_best_grasp_near_object(
grasp_group, obj_pos_cam, max_distance=0.05
)
if best_grasp is None:
print(f"[Perception] Không tìm được grasp phù hợp cho '{object_name}'")
return None
# Chuyển grasp từ hệ camera sang hệ robot base
R_cam = best_grasp.rotation_matrix # 3x3
t_cam = best_grasp.translation # 3D
t_base = (T_base_cam @ np.append(t_cam, 1.0))[:3]
R_base = T_base_cam[:3, :3] @ R_cam
# --- Bước 5: Đóng gói spatial_info ---
spatial_info = {
"object_label": detection['bboxes_labels'][0],
"position": obj_pos_base.tolist(), # [x, y, z] mét, hệ base
"grasp_pose": {
"rotation": R_base.tolist(), # 3x3 list of lists
"translation": t_base.tolist(), # [x, y, z] mét, hệ base
"score": float(best_grasp.score), # 0.0–1.0
"width": float(best_grasp.width) # mét
}
}
print(f"[Perception] Tìm thấy '{object_name}' tại {obj_pos_base.round(3)}")
print(f"[Perception] Grasp score: {best_grasp.score:.3f}, width: {best_grasp.width:.3f}m")
return spatial_info
Ví dụ output thực tế:
{
"object_label": "coffee cup",
"position": [0.312, -0.087, 0.142], # 31.2cm phía trước, 8.7cm trái, 14.2cm cao
"grasp_pose": {
"rotation": [
[0.998, -0.043, 0.042],
[0.041, 0.999, 0.024],
[-0.043, -0.022, 0.999]
],
"translation": [0.308, -0.085, 0.178], # điểm giữa gripper
"score": 0.847,
"width": 0.072 # 7.2cm — phù hợp cầm cốc
}
}
Cài đặt và yêu cầu hệ thống
Dependencies
# Florence-2
pip install transformers>=4.41.0 torch torchvision Pillow
# AnyGrasp SDK (cần license key từ graspnet.net)
# Xem hướng dẫn tại: https://github.com/graspnet/anygrasp_sdk
pip install MinkowskiEngine # build from source cho CUDA phù hợp
# Sau đó clone anygrasp_sdk và cài gsnet wheel
# Point cloud + visualization
pip install open3d numpy
Yêu cầu phần cứng
| Component | Minimum | Recommended |
|---|---|---|
| GPU VRAM | 8 GB (Florence-2-base) | 16 GB (Florence-2-large) |
| CUDA | 11.x | 12.x |
| RAM | 16 GB | 32 GB |
| Camera | Bất kỳ RGB-D | Intel RealSense D435 |
Lưu ý quan trọng: Florence-2 và AnyGrasp có thể chạy trên cùng GPU nếu bạn load và unload tuần tự (không cùng lúc). Trong production, nên chạy trên 2 GPU riêng biệt để giảm latency.
Latency thực tế (RTX 4090)
| Bước | Thời gian |
|---|---|
| Florence-2-large inference | ~180ms |
| Pixel → 3D conversion | <5ms |
| Build point cloud | ~20ms |
| AnyGrasp inference | ~150ms |
| Tổng cộng | ~360ms |
360ms per perception cycle là hoàn toàn chấp nhận được với tốc độ control 3-5Hz của most manipulation tasks.
Những cạm bẫy thường gặp
1. Depth noise tại vùng viền vật thể
RealSense D435 (và hầu hết các depth camera) bị flying pixels tại viền vật thể — các pixel có depth values bất ổn vì họ là ranh giới giữa hai bề mặt có depth khác nhau. Bounding box tâm đôi khi trùng vào vùng này.
Fix: Dùng trung vị (median) của patch 5×5 quanh tâm bounding box thay vì lấy 1 pixel đơn.
2. AnyGrasp không trả về grasp nào
Xảy ra khi vật thể quá nhỏ, quá trong suốt (kính), hoặc workspace_lims quá chật. Kiểm tra:
print(f"Total grasps found: {len(gg) if gg else 0}")
# Nếu 0: nới rộng workspace_lims hoặc tắt collision_detection
3. Florence-v2 nhận diện sai khi có nhiều vật tương tự
Nếu trên bàn có 3 cốc, Florence-v2 có thể trả về nhiều bounding boxes. Dùng bounding box lớn nhất (closest to camera), hoặc thêm thông tin ngữ cảnh vào prompt: "red coffee cup on the left".
4. Ma trận extrinsic sai
Lỗi phổ biến nhất khi deploy: tọa độ 3D trả về đúng relative nhưng sai absolute (offset cố định). Kiểm tra lại T_base_cam bằng cách:
# Đặt vật thể ở vị trí known (VD: 30cm phía trước robot base)
# So sánh output position với thực tế
print(f"Measured: {obj_pos_base}, Expected: [0.30, 0.00, ...]")
Tổng kết
Perception Agent trong ManiAgent là sự kết hợp tinh tế của hai model mạnh:
- Florence-v2 giải quyết bài toán "tên → vị trí" bằng open-vocabulary detection, không cần fine-tune cho object class mới
- AnyGrasp giải quyết bài toán "point cloud → cách cầm" bằng dense prediction cho toàn scene
- Camera unprojection (pixel + depth → 3D) là cầu nối giữa hai world
Dict spatial_info là ngôn ngữ chung mà Perception Agent dùng để nói chuyện với Reasoning Agent và Action Agent. Format chuẩn hóa này là điều khiến pipeline modular: bạn có thể thay Florence-v2 bằng Grounding DINO, hay thay AnyGrasp bằng Contact-GraspNet — miễn là output vẫn là spatial_info với cùng schema.
Bài tiếp theo, chúng ta sẽ xem Reasoning Agent nhận spatial_info này và lập kế hoạch như thế nào — so sánh 3 paradigm ALRM, CAP, và TAP, xem cái nào phù hợp cho manipulation tasks phức tạp.
Nếu bạn muốn hiểu sâu hơn về VLA foundation models mà ManiAgent so sánh với, đọc VLA Models: Từ RT-2 đến Pi0 và Diffusion Policy: Policy Learning từ Demonstrations.