In 2025, Physical Intelligence launched π₀ (pi0) — one of the most capable Vision-Language-Action models ever built, trained on millions of real robot steps across diverse tasks. Its SimplerEnv benchmark score: 55.7% average success rate. Impressive? Yes. Production-ready? Not quite.
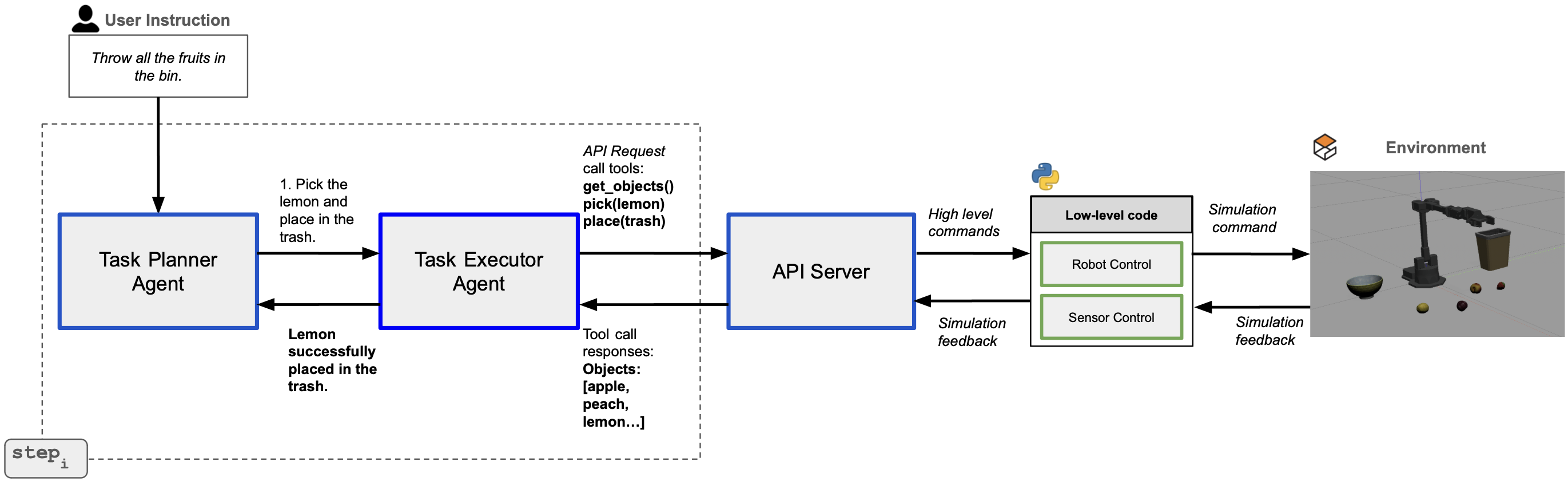
Around the same time, a research group published ManiAgent (arXiv:2510.11660) — a fundamentally different approach. Not one massive model, but three small specialized agents working together. The result: 86.8% success rate. That's a 31-percentage-point gap over pi0, achieved with zero fine-tuning on any robot demonstration data.
This article breaks down exactly why multi-agent decomposition outperforms monolithic VLA models in robot manipulation — and by the end, you'll be able to sketch the ManiAgent architecture from memory.
Series Roadmap: AI Agent Pipeline for Robot Manipulation
This is a 5-part series, each article building on the previous:
| # | Article | What You'll Learn |
|---|---|---|
| 1 | Why Multi-Agent Beats VLA? ← you are here | Benchmark comparison, ManiAgent architecture, information flow |
| 2 | Perception Agent & Grasp Planning | Building the vision layer: detection, depth, 3D coordinates |
| 3 | ALRM, CAP vs TAP | Three action-planning paradigms compared head-to-head |
| 4 | SAP Verifier: Self-Verification | Automated action checking and error recovery |
| 5 | Sim-to-Real Deploy | Deploying the agent pipeline on a real robot |
What VLA Models Are — And Where They Hit a Wall
A Vision-Language-Action model takes images and a natural language instruction as input and outputs robot commands directly — joint angles, end-effector waypoints, or gripper actions. The appeal is clear: one unified brain that sees, understands, and acts.
Major VLA models today include:
- π₀ (pi0) — Physical Intelligence: flow-matching architecture, broad multi-task training
- CogACT — cognitive VLA integrating reasoning into action generation
- OpenVLA, RoboFlamingo, SpatialVLA — different approaches to the same problem
The fundamental problem: manipulation requires three completely distinct capabilities, and optimizing all three simultaneously inside one model is extraordinarily difficult:
- Perception — understanding 3D space, localizing objects to millimeter precision, handling occlusion
- Reasoning — multi-step planning, conditional logic, replanning when sub-tasks fail
- Action execution — converting a plan into a trajectory that respects robot kinematics and workspace limits
Think of it like hiring one person to simultaneously act as surgeon, anesthesiologist, and scrub nurse during an operation. Specialization wins every time.
The Numbers Don't Lie
SimplerEnv is the standard simulation benchmark for robot manipulation. It runs 4 tasks on a Google Robot arm:
- Stack blocks — precise stacking requiring accurate spatial reasoning
- Place carrot on plate — pick-and-place with a deformable target surface
- Put spoon on towel — object placement with texture-defined target
- Move eggplant to basket — cluttered scene with occlusion challenges
Full results (average success rate across all trials):
| Model | Type | Stack | Carrot | Spoon | Eggplant | Avg |
|---|---|---|---|---|---|---|
| CogACT | Single VLA | 15.0% | 50.8% | 71.7% | 67.5% | 51.3% |
| π₀ (pi0) | Single VLA | 21.3% | 58.8% | 63.3% | 79.2% | 55.7% |
| ManiAgent-GPT-4o | 3-agent | 76.4% | 95.8% | 77.8% | 47.2% | 74.3% |
| ManiAgent-Claude Sonnet 4 | 3-agent | 77.8% | 98.6% | 80.6% | 62.5% | 79.9% |
| ManiAgent-GPT-5 | 3-agent | 87.5% | 95.8% | 91.7% | 72.2% | 86.8% |
Key observations from the data:
- Stack blocks is the hardest task: pi0 manages only 21.3%, ManiAgent-GPT-5 hits 87.5% — a 66-point gap. Stacking demands accurate 3D perception, sequenced reasoning, and collision-free trajectories. End-to-end VLA fails at the intersection of all three.
- Move eggplant is where multi-agent shows weakness: ManiAgent-GPT-5 scores 72.2% while pi0 scores 79.2%. Heavy occlusion hurts detection-based pipelines more than trained VLA models.
- Even ManiAgent-GPT-4o (74.3%) beats both VLA baselines — confirming the architecture advantage is structural, not just about raw model power.
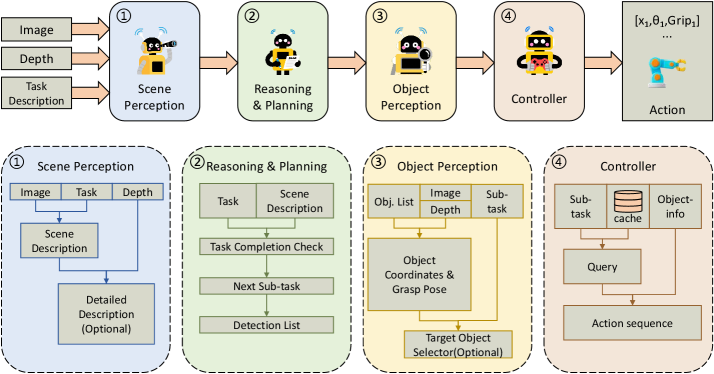
The ManiAgent Architecture: Three Specialists, One Pipeline
ManiAgent (Yi Yang et al., 2025) decomposes manipulation into three agents, each using the best tool for its specific job:
[Scene Images + Depth Maps + Camera Calibration + Task Description]
│
▼
┌────────────────────────┐
│ PERCEPTION AGENT │ ← VLM + Florence-v2 detector
│ • Object detection │
│ • 2D → 3D projection │
│ • Grasp pose gen │
└───────────┬────────────┘
│ textual scene description
│ 3D positions + grasp poses
▼
┌────────────────────────┐
│ REASONING AGENT │ ← LLM (GPT-5 / Claude)
│ • Sub-task decomp │
│ • State evaluation │
│ • History tracking │
└───────────┬────────────┘
│ next sub-task + target object list
▼
┌────────────────────────┐
│ ACTION-EXEC AGENT │ ← LLM + action cache
│ • Keypoint generation │
│ • Trajectory planning │
│ • Action caching │
└───────────┬────────────┘
│
▼
[Robot Commands]
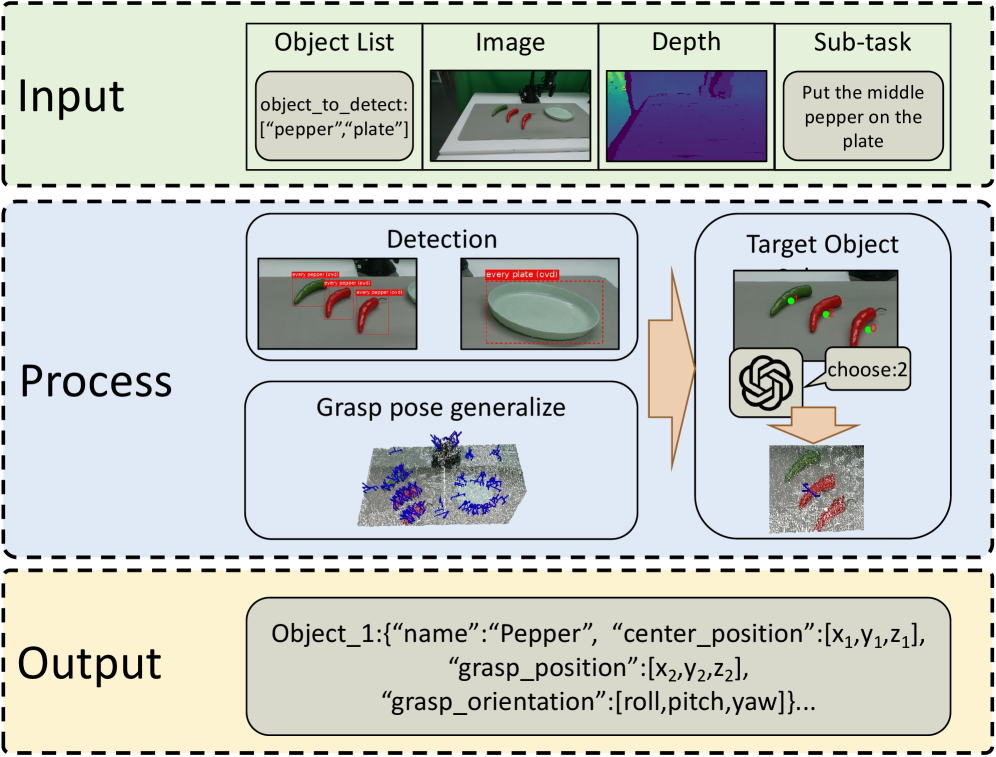
Perception Agent — The Measuring Eye
Inputs: RGB images, depth maps, camera calibration parameters, task description
The Perception Agent performs four steps:
- Scene understanding: Uses a VLM to write a natural-language description of the scene — "there is a white plate on the left, an orange carrot near center, gripper positioned upper-right"
- Object detection: Uses Florence-v2 (Microsoft) to detect individual objects with bounding boxes. Trick: prepend "every" to queries ("every carrot", "every cube") to reduce missed detections when multiple instances exist
- 2D → 3D projection: Combines depth map + camera calibration matrix to convert pixel coordinates (u, v) into real-world 3D coordinates (x, y, z) in meters
- Grasp pose generation: Computes the approach angle and position for the gripper to safely grasp each detected object
Output sent to the Reasoning Agent — plain text:
Red cube: position=[0.23, -0.15, 0.82], grasp_pose=[0.0, 0.0, 0.0, 1.0]
Blue plate: position=[0.18, 0.22, 0.78], flat_surface=True
Reasoning Agent — The Strategic Brain
Inputs: Scene description, task instruction, history of completed sub-tasks
The Reasoning Agent works entirely in natural language — no numbers, no coordinates. Its responsibilities:
- Evaluate current state: what has been accomplished, what remains, did the last sub-task succeed?
- Decompose the overall task into the next concrete sub-task
- Send detection requests back to Perception Agent: "next cycle, focus on detecting [target objects]"
- Use history to avoid repeating failed sub-tasks — preventing infinite loops when the robot gets stuck
Example reasoning chain:
Task: "Place carrot on plate"
State: "Carrot at (0.3, -0.1, 0.85). Plate at (0.1, 0.2, 0.80)."
History: []
Plan:
Step 1: Pick up carrot → approach carrot at (0.3, -0.1, 0.85)
Step 2: Move above plate → target plate center (0.1, 0.2, 0.80)
Step 3: Release carrot → verify success
Current: Execute Step 1
Action-Execution Agent — The Hands
Inputs: Sub-task description, 3D coordinates, grasp poses
This agent converts a concrete sub-task into actual robot trajectories:
- Maps target 3D coordinates to Cartesian keypoints — a sequence of end-effector waypoints
- Checks the action cache — stores one trajectory template per skill type. If a similar action was cached, reuse it rather than regenerating
- On cache miss → uses the LLM to generate an action sequence from scratch
The action cache is an underappreciated detail. Reusing templates dramatically reduces latency and ensures consistent execution — the same "pick" skill always looks the same, reducing gripper variance.
Why Text Is the Right "Common Language"
ManiAgent's most distinctive design choice: all inter-agent communication happens through plain text — not shared embedding spaces, not latent vectors, not function calls with typed schemas.
Perception → Reasoning:
"Blue cup at (0.25, 0.10, 0.92), upright, grasp_pose=[...]"
"Red plate at (0.15, -0.05, 0.81), flat surface"
Reasoning → Perception:
"Detect: blue cup, red plate" ← target list for next detection pass
Perception → Action-Exec:
"object_0 = blue cup: position=[0.25, 0.10, 0.92], grasp_pose=[...]"
Action-Exec → Robot:
waypoints = [(0.25, 0.10, 0.95), (0.25, 0.10, 0.92), ...]
Why text? Three reasons:
- Universal interface: Every LLM/VLM understands text — swap any component without rewriting connectors
- Full debuggability: Read every message between agents; see exactly what each agent "thinks"
- Flexible metadata: Add confidence scores, failure reasons, or uncertainty estimates just by appending to the string
Spatial consistency is maintained through fixed object indices: once Perception Agent assigns object_0 to a specific object, that index is stable throughout the pipeline. The Action Agent requesting "pick object_0" always refers to the same physical thing.
Four Reasons Decomposition Wins
1. Each component optimized for its own task
Training a VLA end-to-end forces the network to simultaneously master perception, planning, and motor control. Gradient signals from action losses must backpropagate through all three capabilities, causing gradient interference — improving one skill often degrades another.
With decomposition, the Perception Agent uses Florence-v2 — a dedicated detector trained specifically for object detection, far more accurate than the vision encoder inside a generic VLA.
2. Metric 3D spatial grounding
VLA models represent spatial information through vision tokens compressed into a latent space. Precise metric distances get lost in this compression. ManiAgent's Perception Agent computes real metric 3D coordinates via depth + calibration, then passes exact numbers: [0.25, 0.10, 0.92] rather than "object is slightly left of center." No information lost through compression.
3. Zero-shot generalization — no robot data needed
ManiAgent requires no fine-tuning on robot demonstrations. Pi0 and CogACT need tens of thousands of robot trajectories. ManiAgent only needs a better LLM — which is why ManiAgent-GPT-5 (86.8%) > ManiAgent-GPT-4o (74.3%): upgrading one component immediately upgrades the whole pipeline.
4. Explicit failure recovery
When the Reasoning Agent receives a post-execution scene description and sees the state hasn't changed (sub-task failed), it can immediately replan. Single VLA models have no explicit state tracking — they just "generate the next action" based on current observation, with no mechanism to recognize "I just failed and need a different approach."
Real-World Limitations
ManiAgent isn't a perfect solution. Documented failure cases from the paper:
| Issue | Example | Root Cause |
|---|---|---|
| Occlusion | Eggplant partially hidden by sink rim → detector grabs wrong coordinates | Florence-v2 struggles with partial occlusion |
| Height ambiguity | Stacked blocks → grasp point computed at wrong height | Depth estimation error on vertical surfaces |
| Object confusion | Green pepper vs red pepper → Reasoning Agent targets wrong one | Visual similarity confuses LLM descriptions |
| Depth-RGB misalignment | SimplerEnv intermittent sync bug → underestimates performance | Simulator sensor synchronization issue |
| IK failures | Arm places object outside reachable workspace | No workspace constraints in trajectory planning |
In the paper's data collection experiment (551 trajectories), there were 15 manual interventions — actual success rate 81.5%, not 100%.
Notably, Move eggplant remains the hardest task for ManiAgent (72.2%) — lower than pi0 (79.2%) precisely because occlusion degrades the detection-based pipeline more than it affects a VLA's holistic visual understanding.
ManiAgent as a Data Generator
A less-discussed but highly practical application: ManiAgent can automatically generate training data for other VLA models.
The authors used ManiAgent to collect 551 trajectories for "Place carrot on plate" — 450 valid (81.5% success). Total time: 19.5 hours (~2 minutes per trajectory). That dataset then trained a CogACT VLA to match performance of models trained on human-teleoperated data.
Implication: instead of hundreds of hours of human teleop, a small team can deploy ManiAgent to autonomously generate specialized VLA training data at scale.
What This Means for Robotics Practitioners
The core lesson from ManiAgent: you don't need a superhuman model to achieve strong manipulation performance. You need:
- Right tool for each job: specialized detector for perception, powerful LLM for reasoning, cached primitives for execution
- Clean interfaces: text-based inter-agent communication makes each component replaceable and debuggable
- Explicit state tracking: know what's done, what remains → natural failure recovery
- Zero-shot generalization: decouple from robot-specific training data dependency
This means a small team can build a strong manipulation system by combining off-the-shelf components — no million-step dataset, no GPU cluster for VLA training.
In the next article, we'll go deep on the Perception Agent: how Florence-v2 achieves zero-shot object detection, how to compute 3D coordinates from depth maps and camera calibration, and how to generate reliable grasp poses for real grippers.
Related Posts
- Part 2: Perception Agent & Grasp Planning — Building the vision layer for manipulation
- Part 3: ALRM, CAP vs TAP — Three Action Planning Paradigms Compared
- Part 5: Sim-to-Real Deploy — Taking the agent pipeline to a real robot
- VLA Models 2025: Overview of Vision-Language-Action Models
- AI for Robotics 2025: Landscape and Trends