VLA + WBC repos from the US: NVIDIA GR00T, openpi, HumanPlus, TeleVision
This is post 2 of the VLA + WBC repos landscape series. This post deep dives into US repositories — NVIDIA, Physical Intelligence, Berkeley, Stanford, and other open-source labs.
What defines this group: a strong focus on generalization (one model works across multiple robots and tasks) and open research culture (most have paper + code + dataset released simultaneously).
NVIDIA: Isaac-GR00T and GR00T-WholeBodyControl
NVIDIA has two separate repos for two different problems — don't confuse them.
Isaac-GR00T (~7.3k stars)
Repo: NVIDIA/Isaac-GR00T
What it is: Foundation model for robots — takes image + language → action. Equivalent to LLaVA but output is robot action instead of text. Model is called GR00T N1 (March 2025).
Architecture:
Observation: [wrist camera RGB] + [head camera RGB] + [text instruction]
Backbone: Eagle2 vision encoder (NVIDIA)
Language: Llama-3 backbone
Action head: flow-matching diffusion
Output: joint positions (delta) or end-effector pose
Strengths: Pretrained on 1000+ tasks across many robots (Franka, UR5, G1, H1, GR1...). Fine-tuning with ~50-100 demos is usually enough for a new task.
Weaknesses: Inference is heavy — needs GPU (recommended A100/H100 for training, RTX 4090 for inference). Not production-ready for real-time deployment (<100ms per step) yet.
Getting started:
git clone https://github.com/NVIDIA/Isaac-GR00T.git
cd Isaac-GR00T
pip install -e ".[dev]"
# Fine-tune with your demo data (LeRobot format)
python scripts/finetune.py \
--model_path nvidia/GR00T-N1-2B \
--dataset_path path/to/your/lerobot_dataset \
--output_dir ./finetuned_model
Data format: LeRobot (HuggingFace). If you already have UMI data, you'll need to convert to LeRobot format first.
Paper: GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
GR00T-WholeBodyControl (~2.2k stars)
Repo: NVlabs/GR00T-WholeBodyControl
What it is: WBC platform for deploying policies on real humanoid robots — not a VLA model. This is the middle layer between VLA output and robot joints.
Decoupled architecture:
VLA policy → [target wrist pose L/R + gripper] (upper body)
↓
GR00T-WBC ← GEAR (upper body RL controller)
↓
SONIC (loco-manipulation controller)
↓
Robot joints (30+ DoF)
Three components:
- N1.5 / N1.6: VLA policy (runs at 6Hz)
- GEAR: upper body controller (50Hz, RL-trained, from joint targets → torques)
- SONIC: whole-body loco controller (200Hz, MPC + RL)
Why decoupled? Because VLA inference (~150ms) and robot control loop (5ms) can't run at the same rate. Decoupled lets each layer run at its own frequency.
Supported robots: GR1, G1, Unitree H1 (and any robot with URDF + sufficient DOF).
Paper: GR00T-WBC: Decoupled Whole-Body Control for Humanoid Locomotion and Manipulation
HOVER (~742 stars)
Repo: NVlabs/HOVER
What it is: A precursor experiment to GR00T-WBC — unified controller for whole-body. Many people use HOVER as a baseline to compare against GR00T-WBC.
Physical Intelligence: openpi (~12.2k stars)
Repo: physical-intelligence/openpi
What it is: Open-source release of π0 and π0.5 — currently the strongest VLA model by many benchmarks (March 2025 release).
π0 architecture:
Base: PaliGemma (vision-language backbone from Google)
Action: flow-matching → continuous action
Frequency: 50Hz (fast enough for real robot)
Parameters: 3B
π0.5 improvement:
- Added reasoning chain (chain-of-thought for robots)
- Long-horizon task execution (multi-step)
- Zero-shot cross-embodiment transfer
Why openpi is appealing:
- Inference speed: 50Hz — usable in real-time
- Cross-embodiment: pretrained on many robots, transfer works
- Largest community: 12k+ stars, many tutorials and examples
Getting started:
git clone https://github.com/physical-intelligence/openpi.git
cd openpi
pip install -e .
# Download pretrained π0 checkpoint
python -c "from openpi.models import pi0; pi0.download_checkpoint('pi0-base')"
# Inference example
python examples/inference_example.py \
--checkpoint pi0-base \
--image path/to/obs.jpg \
--instruction "pick up the red cup"
Fine-tuning: openpi supports fine-tuning with LeRobot format or custom dataset loader.
Papers:
- π0: A Vision-Language-Action Flow Model for General Robot Control (2024)
- π0.5: A VLA with Open-World Generalization (2025)
Berkeley: HumanPlus (~847 stars)
Repo: MarkFzp/HumanPlus
What it is: Whole-body humanoid imitation learning from human motion capture. A person wears a mocap suit (21 markers) → data → train policy for Unitree H1.
What makes it unique: HumanPlus is the "collect data from the human" approach (like UMI) but for the whole body. Instead of teleoperation, you simply... perform the action yourself.
Pipeline:
1. Person wears mocap suit and performs task
2. OptiTrack captures 21-marker body + 6DoF wrist poses
3. Retargeting: human → H1 URDF (via motion retargeting code in repo)
4. Train: ACT (Action Chunking Transformer) on whole-body trajectories
5. Deploy: H1 runs learned policy with head camera + proprioception
Demonstrated tasks: cabinet opening, object manipulation, carrying box, folding shirt (whole body).
Hardware requirements:
- Unitree H1 humanoid robot
- OptiTrack mocap system (or equivalent)
- GPU workstation (training)
Why it matters: HumanPlus proved that complex teleoperation isn't necessary — a mocap suit + retargeting is enough for a working whole-body policy. This approach influenced many labs that followed.
Paper: HumanPlus: Humanoid Shadowing and Imitation from Observations
Stanford + MIT: TeleVision (~1.3k stars)
Repo: OpenTeleVision/TeleVision
What it is: Immersive teleoperation for humanoids using Apple Vision Pro or Meta Quest 3. Operator wears HMD → sees robot perspective → controls with hands.
Architecture:
Apple Vision Pro / Meta Quest 3
↓ (hand tracking + head pose)
Retargeting (human → robot arm)
↓
ROS2 / custom SDK
↓
Humanoid upper body (arms + hands)
Key feature: Binocular video stream from robot head camera → operator gets stereoscopic view — feels like "being inside the robot." Total latency ~80ms (VR rendering + network + robot).
Weakness: Only covers upper body (arms + hands). Legs must run a separate locomotion controller. Apple Vision Pro is expensive ($3,500).
When to use: When you need high-quality manipulation data collection with human-level dexterity and no mocap room. Combine with SONIC/GR00T-WBC to drive legs.
Paper: Open-TeleVision: Teleoperation with Immersive Active Visual Feedback
OpenHelix (~378 stars)
Repo: OpenHelix-Team/OpenHelix
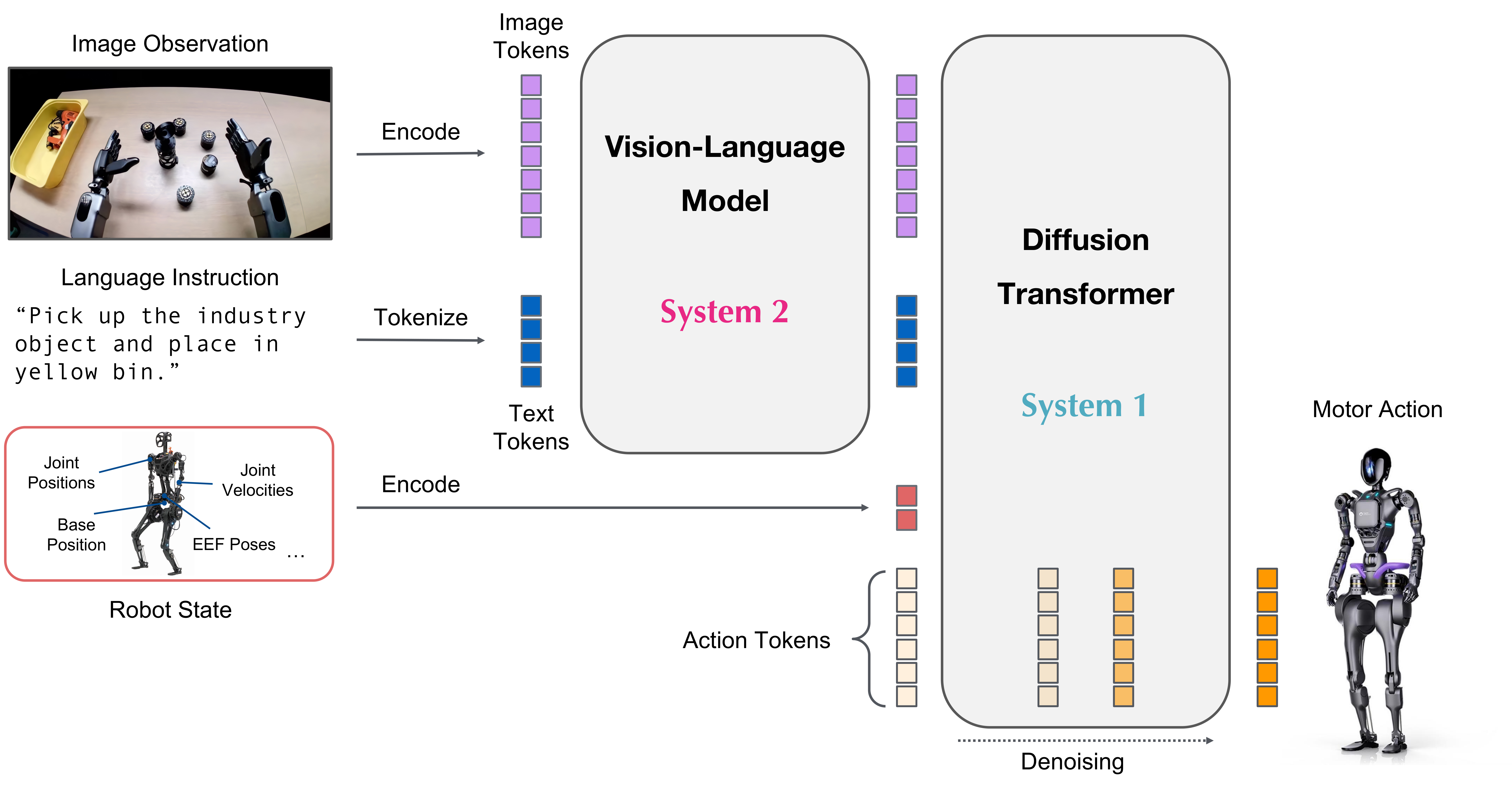
What it is: Dual-system architecture for VLA manipulation — two-module system: "thinking system" (slow, for planning) + "acting system" (fast, for execution). Inspired by System 1/System 2 cognitive science.
What differentiates it from openpi/GR00T:
- Designed explicitly for robot arms (not focused on full humanoid)
- Easier to deploy because no full humanoid hardware needed
- Architecture suited to bimanual manipulation tasks
Supported robots: WidowX, Franka, and any robot with URDF.
When to use: OpenHelix sits at the intersection between manipulation-focused VLA and bimanual systems. Good for studying VLA architecture before scaling to humanoids.
OpenDriveLab: EgoHumanoid (~161 stars)
Repo: OpenDriveLab/EgoHumanoid
What it is: Framework for collecting data and training policies for loco-manipulation (walking + manipulation) from egocentric human demos — person wears a head-mounted camera, performs task, no mocap suit needed.
The most important point about EgoHumanoid: reduces hardware barrier to just a head-mounted camera (ego camera). No mocap room, no VR headset.
Pipeline:
1. Person wears GoPro/RealSense on head and performs task
2. Video + pose estimation (ViTPose, etc.)
3. 3D pose lifting from 2D video
4. Retargeting to humanoid URDF
5. Train: loco-manipulation policy (locomotion + manipulation jointly)
6. Deploy: humanoid with head camera + proprioception
Results from paper (RSS 2026): First demo of whole-body loco-manipulation on a real robot from ego demos — humanoid walks to a table, picks up object, and moves to another location.
Why to watch: If this pipeline works well at scale, the barrier for whole-body data collection will drop significantly — just a head-mounted camera and a person demonstrating.
Paper: EgoHumanoid: Embodied Whole-Body Loco-Manipulation from Egocentric Demonstrations (RSS 2026)
Summary comparison — US group
| Repo | Main problem | Hardware needed | Entry barrier |
|---|---|---|---|
| openpi | VLA inference + fine-tune | GPU workstation | Low |
| Isaac-GR00T | VLA fine-tune + sim | GPU workstation | Medium |
| GR00T-WBC | Deploy WBC to real robot | Humanoid robot | High |
| HumanPlus | WBC data collection | Humanoid + mocap | High |
| TeleVision | Teleoperation data | Humanoid + HMD | Medium |
| OpenHelix | Bimanual VLA | Robot arm | Low |
| EgoHumanoid | Loco-manip data | Humanoid + head cam | Medium |
Observation
The US group stands out for foundation model quality (openpi, GR00T) and research novelty (EgoHumanoid, HumanPlus). NVIDIA is particularly notable because they're building the full stack — from VLA model to WBC controller — and releasing everything under permissive licenses.
Next: Chinese repos — Unitree, THU, and the open community.
References
- GR00T N1 (arxiv:2503.14734)
- GR00T-WBC (arxiv:2506.08000)
- π0 (arxiv:2410.24164)
- HumanPlus (arxiv:2406.10454)
- Open-TeleVision (arxiv:2407.01512)
- EgoHumanoid (RSS 2026)