
SOMA-X v0.2 matters because it addresses a practical bottleneck in modern robotics: how do we use one motion representation, one rig and one simulation pipeline across many human body types? If you work on humanoids, digital humans, pose estimation, motion generation or human-to-robot retargeting, you eventually hit this problem. SMPL, SMPL-X, MHR, Anny and other body models all describe humans, but they do not share the same topology, skeleton hierarchy or pose convention.
The original NVIDIA project is SOMA: Unifying Parametric Human Body Models, with code at NVlabs/SOMA-X, API documentation at SOMA-X docs and the installable package published as py-soma-x. The recommended 0.2 series release is v0.2.1. It adds a corrective-model path for procedural twist-joint rigs, while v0.2.0 introduced the major full-body update: procedural twist joints, SOMA-native bone scale, pose conversion utilities, extra-low LOD, updated USD rig assets and public API documentation.
The short version is simple: SOMA-X does not try to replace SMPL or MHR. It builds a canonical body topology and rig that acts as a shared hub. Identity can come from MHR, SMPL, SMPL-X, Anny, GarmentMeasurements or SOMA-shape. Pose can come from SOMA, SMPL, MHR or motion datasets such as AMASS. The final animation path still goes through one unified layer built from Linear Blend Skinning, pose correctives and NVIDIA Warp acceleration.
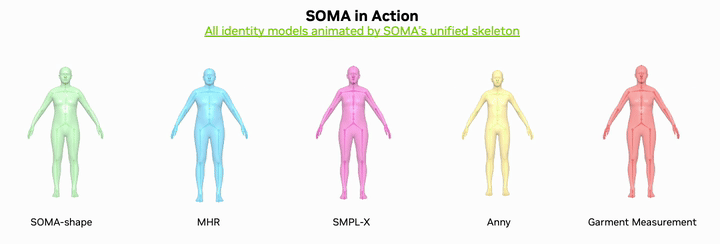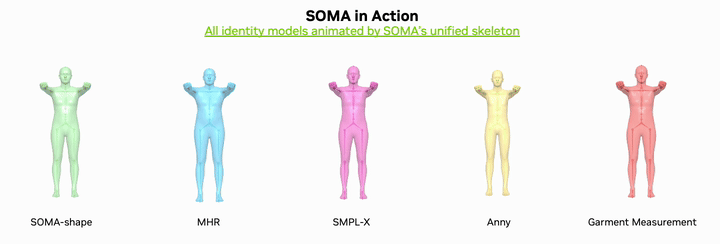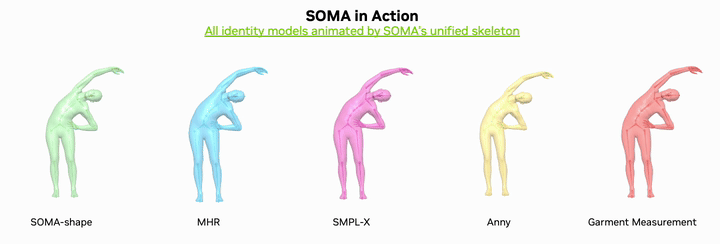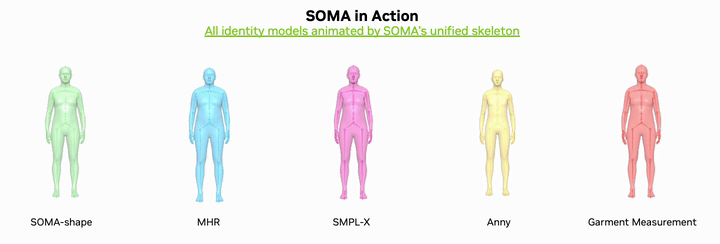
Why SOMA-X matters for robotics
In computer graphics, a body model is often used to render a digital person. In robotics, it can be the bridge between human motion and robot motion. A humanoid policy may learn from human motion capture. A retargeter may map a human skeleton to Unitree G1 joint targets. A simulator may need thousands of body shapes to test stability, collisions, perception viewpoints or contact behavior.
The problem is fragmentation. SMPL has 6,890 vertices and a compact PCA shape space that became a research standard. SMPL-X adds articulated hands and face. MHR emphasizes explicit bone-length parameterization to capture skeletal diversity. Anny is built from anthropometric measurements and is useful when age, height, weight and body composition must span children through older adults. GarmentMeasurements is useful for clothing-aware proportions. If every pair of models needs a custom adapter, interoperability scales as an N x N problem.
SOMA-X changes that into N connectors. Each backend maps into SOMA once. After that, motion conversion, correctives, LODs, pose inversion and downstream robotics code can all work in one SOMA convention. That is why the phrase "One rig, every body" is more than a tagline.
For context from the vnrobo archive, this sits close to our posts on the humanoid software stack with ROS 2, Isaac and LeRobot, real-world GROOT whole-body data and GEAR SONIC whole-body control. SOMA-X lives in the geometry and pose-representation layer before that data is consumed by simulation, retargeting or policy training.
The paper idea: decouple identity from pose
The core idea in the paper is identity-pose decoupling. Identity answers "what body is this": height, limb proportions, shoulder width, surface mesh and bone scale. Pose answers "what is the body doing": standing, walking, sitting, reaching or twisting. In many older pipelines, those two parts are tied to one model convention. If an SMPL motion should drive an Anny identity, the user has to build a custom conversion path.
SOMA-X introduces three abstraction layers:
- Mesh Topology Abstraction transfers the native backend rest shape onto the SOMA topology using pre-computed barycentric correspondence. Runtime identity transfer does not require a neural network or iterative solver.
- Skeletal Abstraction fits the SOMA skeleton to the transferred rest shape. The paper describes an analytical path based on RBF joint regression and Procrustes/Kabsch alignment to recover identity-adapted joint transforms.
- Pose Abstraction recovers SOMA skeleton rotations from posed vertices using inverse-LBS, Newton-Schulz orthogonalization and optional autograd FK refinement.
The full forward path can be differentiable end to end. For robotics, that means SOMA can sit inside optimization or ML loops. Identity coefficients and pose go in, vertices and joints come out, and a downstream loss can backpropagate through geometry when that is useful.
SOMA-X v0.2 architecture
The main runtime entry point is SOMALayer. The docs describe it as a 78-joint parametric human body model. The public pose tensor has 77 joint entries because the root dummy joint is excluded from user pose input. Typical inputs are:
poses: shape(B, 77, 3)for axis-angle or(B, 77, 3, 3)for rotation matricesidentity: shape(B, K), whereKdepends on the backend; SOMA-shape uses 128 PCA coefficientsscale_params: optional native SOMA body-part and bone scale parameterstransl: optional root translation for world placement
The output is a dictionary with vertices, joints, transforms and related metadata. Level of detail is a first-class runtime option. lod="mid" returns 18,056 vertices, lod="low" returns 4,505 vertices and lod="xlo" returns only 612 body vertices. Extra-low LOD is especially practical for robotics. If you only need a silhouette, kinematic proxy, fast fitting or lightweight preview, 612 vertices can cut bandwidth and memory without changing the public SOMA pose convention.
Version 0.2 also reorganizes assets. SOMA_template_rig.usda becomes the source of truth for joint hierarchy, bind/T-pose, bind shape and skinning weights. SOMA_neutral.npz becomes slimmer and stores the PCA shape model, topology, UVs, LOD maps, semantic segments and metadata. SOMA_procedural_transforms.json is the portable sidecar that describes the procedural twist-joint transform.
Procedural twist joints and correctives
Standard LBS often creates artifacts around shoulders, elbows, wrists, hips and knees. When joints rotate aggressively, the mesh can lose volume, crease unnaturally or look rubbery. Models such as SMPL use pose-dependent correctives, but those correctives are usually tied to one topology and one model family. SOMA-X can use a unified topology so a corrective model trained once can serve several identity backends.
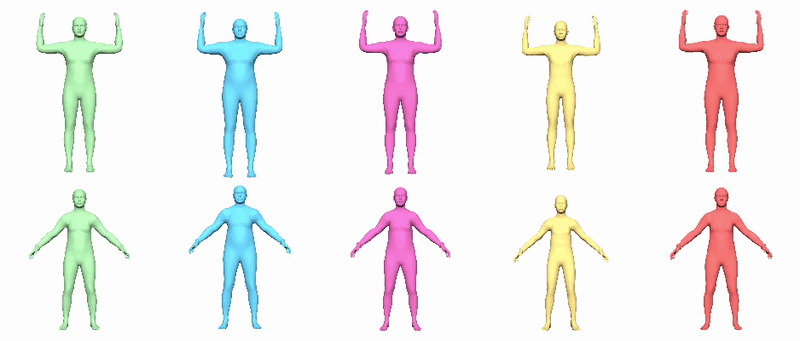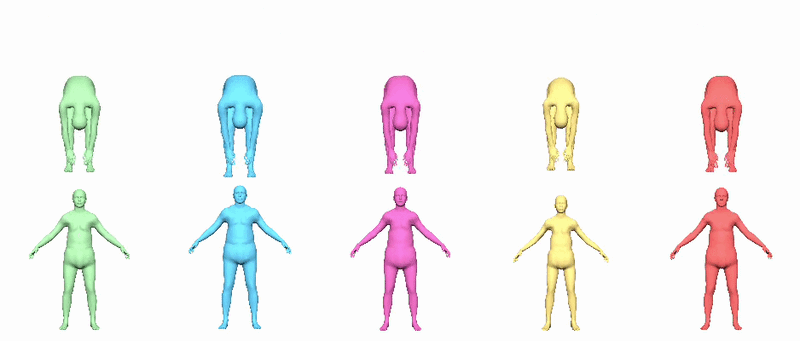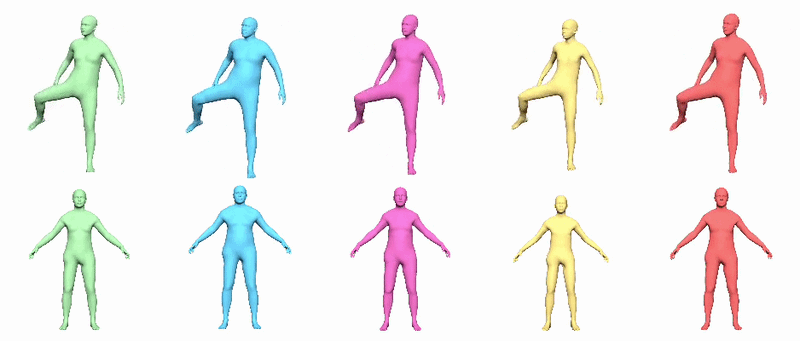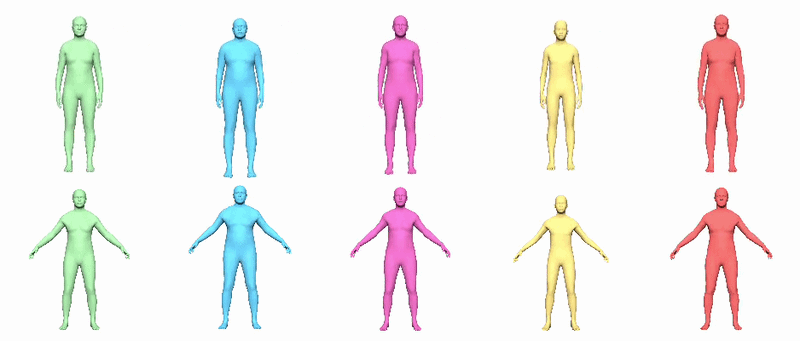
In v0.2, procedural transforms drive twist joints to improve full-body deformations. The JSON sidecar defines how twist should be extracted from public joint rotations. Supported policies include local_x_euler, local_x_swing_twist and aligned_x_swing_twist. The docs state that the current sidecar uses aligned_x_swing_twist globally, deriving segment-aligned virtual orientations and preserving identity stretch rather than trusting independently fitted helper-joint translations.
Version 0.2.1 improves this path by adding corrective-model support that is aware of procedural twist-joint rigs, including corrected bind reposing. That makes the 0.2.1 package the better default if you care about full-body deformation quality.
Installation
For beginners, the easiest path is PyPI:
python -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install py-soma-x
If you need SMPL or SMPL-X support:
pip install "py-soma-x[smpl]"
pip install --no-build-isolation chumpy
There is one important licensing detail. SMPL and SMPL-X model files are not redistributed by SOMA-X. You must download SMPL_NEUTRAL.pkl or SMPLX_NEUTRAL.npz from the official SMPL/SMPL-X sites and pass the path through identity_model_kwargs. SOMA-X assets are automatically downloaded from Hugging Face on first use and cached under ~/.cache/huggingface/hub/.
A minimal forward pass looks like this:
import torch
from soma import SOMALayer
device = "cuda" if torch.cuda.is_available() else "cpu"
soma = SOMALayer(identity_model_type="mhr", device=device, lod="low")
B = 1
poses = torch.zeros(B, 77, 3, device=device)
identity = torch.zeros(B, soma.num_shape_components, device=device)
out = soma(poses, identity)
vertices = out["vertices"]
joints = out["joints"]
print(vertices.shape, joints.shape)
In real projects you usually do not stay at a zero pose. You import motion from SMPL, MHR, AMASS or a pose estimator, convert it to SOMA, then use SOMALayer to render, fit, export .npz files or feed a retargeting pipeline.
Pose inversion: from posed mesh back to SOMA pose
Pose inversion is the feature that makes SOMA-X valuable for legacy data. Suppose you already have posed vertices in SMPL or MHR format, but you want SOMA-compatible rotations. PoseInversion.fit() accepts vertices in a supported topology, transfers them to SOMA topology if required, then fits rotations.

The repository includes conversion tools:
python -m tools.smpl2soma --output-npz out/smpl_soma.npz
python -m tools.mhr2soma --input path/to/parquet_dir --output-npz out/mhr_soma.npz
python -m tools.convert_amass_to_soma --input-dir /data/amass --output-dir out/amass_soma
There are two main solver styles. Analytical is the default: inverse-LBS refinement with Newton-Schulz, designed to be very fast and accurate enough for most conversion. Autograd FK optimizes through FK + LBS, which is slower but lets you emphasize extremities such as hands, feet and head. The two can be combined: analytical solve first, then autograd refinement.

The README benchmarks are useful for setting expectations:
| Conversion | Hardware | Method | Speed | Mean error |
|---|---|---|---|---|
| SMPL to SOMA, 402 frames | RTX 5000 Ada | Analytical | 1279 FPS | 0.65 cm |
| SMPL to SOMA, 402 frames | RTX 5000 Ada | Autograd 100 iters | 18 FPS | 0.49 cm |
| MHR to SOMA, 200 samples | RTX 5000 Ada | Analytical | 342 FPS | 0.61 cm |
| AMASS to SOMA | A100 | Analytical | 17,393 FPS | 0.53 cm |
For robotics teams, this means pose conversion does not have to become the bottleneck when preprocessing large motion datasets. The exported .npz files contain poses, root_translation, joint_names, per_vertex_error, identity_coeffs and scale_params.
Training: what SOMA-X trains and what it does not
A common beginner mistake is to treat SOMA-X as a neural policy. It is not. The core runtime is analytical and parametric; you do not train a new model every time you use a new identity. Still, the project contains learned or fitted components:
- SOMA-shape PCA: the paper reports a shape space fit from 9,326 SizeUSA body scans, 303 Triplegangers scans and samples distilled from GarmentMeasurements with a 40/40/20 mixture. The result is a 128-component identity representation.
- Pose corrective MLP: the corrective model is distilled from MHR posed meshes transferred onto SOMA topology. It predicts per-vertex displacement from pose to reduce LBS artifacts.
- Topology correspondences: barycentric correspondences are precomputed during initialization or asset preparation. This is geometry setup, not a gradient-based training loop at inference time.
- Downstream policy training: if you train a humanoid controller, SOMA-X usually acts as a preprocessing and geometry layer. You convert motion to SOMA, retarget it to a robot, then train motion tracking in a simulator such as Isaac Lab, ProtoMotions or an internal stack.
A practical training workflow looks like this:
AMASS / SAM 3D Body / SMPL motion
-> PoseInversion / pose_converter
-> SOMA pose + identity + scale_params
-> retarget to humanoid skeleton
-> train motion tracking policy in simulation
-> evaluate sim-to-real or deploy to robot
If your dataset starts from human video, our post on SUGAR humanoid loco-manipulation from human videos is a related direction. SOMA-X solves the representation layer so that human data is less locked to one body model convention.
Inference and robotics deployment
At inference time, you usually do one of three things.
The first is forward body modeling: choose an identity backend, choose a pose and get vertices and joints. This is useful for visualization, collision proxies, synthetic data generation, camera rendering and quality checks.
The second is pose conversion or inversion: take posed vertices or motion from another model family and export SOMA pose. This is useful when standardizing datasets before training a controller or motion model.
The third is LOD-aware fitting: use lod="xlo" or lod="low" when speed matters more than render quality. Extra-low LOD with 612 vertices is not a replacement for the mid mesh when you need a polished body render, but it is a good fit for batch inference, skeleton fitting, fast validation and lightweight robot-side previews.
The demo command is direct:
python tools/demo_soma_vis.py --data-root ./assets --output-dir ./out --identity-model-type soma,mhr --lod xlo
For humanoid retargeting, SOMA-X also connects to a broader ecosystem: SOMA Retargeter for SOMA-to-G1 conversion, BONES-SEED in SOMA format, ProtoMotions for simulated humanoids and related projects for video pose and motion generation. That ecosystem matters because robotics needs a chain: data representation, simulation, retargeting and policy learning.
Results and limitations
The paper reports a forward-pass throughput of 7,033 posed meshes per second on an A100 at batch size 128 using the Warp GPU path, with 2.1 ms latency at batch size 1. The CPU PyTorch path reports 12.1 ms at batch size 1. For cross-model shape-space comparison on 33 held-out body scans, SOMA-Shape with 128 components reaches 5.82 mm mean reconstruction error, close to SMPL-X with 300 components at 5.45 mm and much better than SMPL with 10 components at 14.11 mm.
Pose inversion has a clear speed-accuracy tradeoff. The analytical solver is fast. Autograd FK refinement reduces error around extremities. On 200 SAM 3D Body frames, the paper reports hand error dropping from 4.7 mm to 2.0 mm after 100 Adam iterations, foot error from 8.2 mm to 5.8 mm and head error from 6.9 mm to 4.8 mm. Runtime is slower, so this is a refinement option, not the default for every batch job.
The main practical limitations are also clear:
- SMPL and SMPL-X assets still require separate licenses.
- Correctives depend on the right v0.2 assets and procedural-transform path.
- XLO is fast but too sparse for some detailed limb fitting; the docs note that identity-dependent skeleton fitting still uses low-LOD internally for stability.
- SOMA-X standardizes human body representation, but it does not solve robot dynamics, contact planning, torque limits or actuator delay by itself.
Takeaway
SOMA-X v0.2 is infrastructure for physical AI rather than a flashy demo. It solves a boring but expensive problem: too many body models, topologies, skeletons and pose conventions. By mapping them into one rig and one topology, it makes motion data, pose estimation, simulation and humanoid retargeting easier to connect.
For robotics teams, the value is not just prettier digital humans. The value is lower data-conversion cost before training and deployment. With SOMA in the middle, SMPL, MHR, AMASS and other body-shape sources can enter one pipeline, then connect to G1 retargeting, whole-body control or motion policy learning.
Main Sources
- SOMA-X GitHub repo
- SOMA-X stable documentation
- SOMA: Unifying Parametric Human Body Models, arXiv:2603.16858
- py-soma-x on PyPI