SUGAR: Train Humanoid từ Video Người, Không Cần Reward Engineering
Tháng 5/2026, nhóm nghiên cứu tại Đại học Bắc Kinh (Peking University) cùng cộng sự công bố một paper rất đáng chú ý trên arXiv: SUGAR — A Scalable Human-Video-Driven Generalizable Humanoid Loco-Manipulation Learning Framework (arXiv:2605.20373). Tác giả chính là Tianshu Wu cùng các đồng nghiệp Xiangqi Kong, Yue Chen, Qize Yu, Hang Ye, Jia Li, Yizhou Wang, Hao Dong.
Vì sao paper này quan trọng với cộng đồng robotics Việt Nam? Bởi vì SUGAR giải quyết được hai bài toán đau đầu nhất khi train humanoid: (1) reward engineering — thường mỗi task phải ngồi thiết kế hàm reward riêng cực kỳ tricky — và (2) data scarcity — teleoperation đắt, motion capture đắt, mà SUGAR chỉ cần video người bình thường quay được bằng điện thoại.
Trong bài này, mình sẽ đi từ A đến Z: ý tưởng cốt lõi, kiến trúc 3 stage, cách cài đặt từ GitHub, train 6 task có sẵn (CarryBox, KickBox, PushBox, SitChair, StandBottle, PickBottle), và inference trên robot thật.

1. Vì sao SUGAR ra đời? Vấn đề cũ và lời giải mới
Trong Humanoid Series 5 — Loco-Manipulation mình đã giải thích kỹ vì sao loco-manipulation (vừa đi vừa thao tác bằng tay) là Holy Grail của humanoid robot. Khó vì bạn phải đồng thời:
- Giữ thăng bằng toàn thân (whole-body balance)
- Lập kế hoạch tay cầm vật (manipulation planning)
- Tránh va chạm với chính cơ thể robot và môi trường
- Phản ứng với nhiễu loạn bên ngoài (ai đẩy robot, vật trượt khỏi tay)
Cách tiếp cận truyền thống: RL với reward được thiết kế thủ công cho từng task. Reward phải có nhiều term: tracking, energy, smoothness, collision penalty, contact… và hệ số (weight) của mỗi term phải tune mất hàng tuần. Tệ hơn, mỗi task mới — kick bóng, ngồi ghế, mở tủ — phải làm lại từ đầu.
Cách của SUGAR: Quên reward engineering đi. Lấy video người đang làm task đó (transport box, kick, sit, pick bottle…), trích xuất chuyển động và contact, rồi chưng cất thành policy chạy được trên robot thật.
Điểm gây sốc của paper: không hề cần reference motion conditioning lúc inference. Nghĩa là sau khi train xong, robot tự sinh action — không phải mimic từng frame của video. Đây là điểm khác biệt cực lớn so với nhiều paper trước (như H1-2 motion tracking hay OmniH2O).
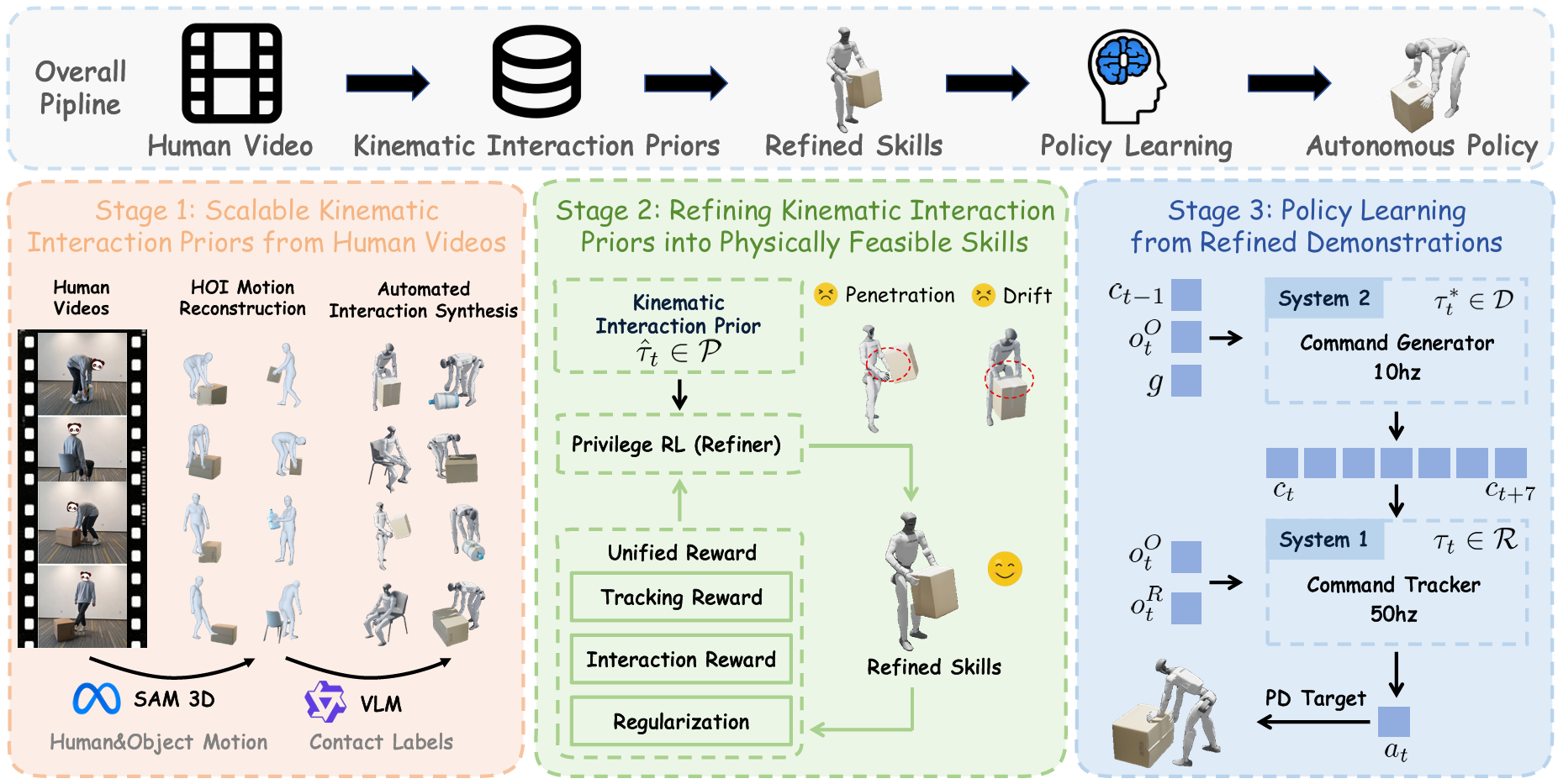
2. Kiến trúc 3 Stage — Pipeline tổng quan
SUGAR hoạt động theo 3 giai đoạn nối tiếp. Hiểu được kiến trúc này là hiểu được 80% paper.
Stage 1 — Kinematic Extraction (Trích xuất chuyển động từ video)
Input: video người thực hiện task (third-person view, unstructured — quay tự do bằng điện thoại, không cần studio).
Pipeline tự động làm các bước:
- Human pose estimation — Trích xương người frame-by-frame.
- Object detection & tracking — Phát hiện vật (box, chai, ghế) và track quỹ đạo qua các frame.
- Contact label extraction — Phát hiện thời điểm tay tiếp xúc vật, chân chạm sàn, mông ngồi ghế.
- Retargeting to humanoid kinematics — Chuyển skeleton người sang skeleton robot (humanoid 29-DoF). Đây là bước khó vì tỉ lệ chi và ràng buộc khớp khác nhau.
Output Stage 1 gọi là kinematic interaction priors: quỹ đạo robot-object + nhãn contact. Lưu ý từ "priors" — đây là gợi ý, không phải ground truth, vì retargeting hay sinh artifact (clipping, contact bị thủng).
Stage 2 — Physics-based Refinement (Tinh chỉnh bằng vật lý)
Lấy priors ở Stage 1 (vốn không feasible về vật lý — tay xuyên hộp, chân lún sàn), Stage 2 dùng RL trong simulation (IsaacSim) để tinh chỉnh thành chuyển động khả thi.
Hai trick quan trọng:
- Unified mimic reward — Một reward duy nhất theo dõi sai số giữa state robot và prior. KHÔNG có reward task-specific. Đây là chìa khóa "no reward engineering".
- Progressive state pool — Robot bắt đầu train ở state dễ (gần cuối task), dần lan ra state khó (đầu task). Giống curriculum learning nhưng tự động.
Stage 2 còn ở chế độ privileged: policy có quyền truy cập thông tin "ăn gian" như object pose chính xác, contact force chính xác — những thứ robot thật không có. Mục đích là để train nhanh và ổn định.
Stage 3 — Hierarchical Policy Distillation (Chưng cất thành policy autonomous)
Lấy policy "ăn gian" ở Stage 2, chưng cất thành 2 module có thể deploy real-world:
- Command Generator (high-level) — Nhận observation (RGB-D, proprioception) và sinh ra "lệnh" abstract (kiểu "move base 0.5m forward, lift left hand"). Train bằng behavior cloning từ rollouts của Stage 2.
- Command Tracker (low-level) — Whole-body control policy, nhận lệnh từ generator và sinh joint target. Train bằng RL trong sim với lệnh được sampled từ rollouts.
Tách 2 module thế này giống NaviGo / NaVid của navigation: tách hoạch định và điều khiển ra để mỗi module nhỏ hơn, ổn định hơn, dễ debug hơn.

3. Cài đặt SUGAR — Step by Step
Repo: github.com/tianshuwu/SUGAR. Yêu cầu phần cứng: GPU NVIDIA (RTX 4090/5090 ideal, A100 cũng OK, tối thiểu RTX 3090 24GB VRAM cho task nhẹ).
3.1 Clone repo và tạo môi trường
git clone https://github.com/tianshuwu/SUGAR.git
cd SUGAR
conda create -n sugar python=3.11 -y
conda activate sugar
3.2 Cài IsaacSim 5.1 và IsaacLab 2.3
SUGAR build trên IsaacLab manager-based framework, nên phải có Isaac Sim. Lưu ý: IsaacSim 5.1 yêu cầu Linux Ubuntu 22.04 LTS (đừng cài trên WSL2 — driver GPU sẽ rối).
# IsaacSim 5.1 từ pip (cách nhanh nhất, không cần Omniverse Launcher)
pip install isaacsim[all,extscache]==5.1.0 --extra-index-url https://pypi.nvidia.com
# IsaacLab 2.3 với RSL_RL support
git clone https://github.com/isaac-sim/IsaacLab.git
cd IsaacLab
git checkout v2.3.0
./isaaclab.sh -i rsl_rl
cd ..
Nếu bạn chưa quen Isaac Lab, đọc Genie Sim 3 — Train Humanoid trên Isaac hoặc GR00T N1 — Fine-tune với Isaac Lab trước, sẽ dễ follow hơn.
3.3 Cài PyTorch tương thích GPU
Cho RTX 5090 / Blackwell GPU (CUDA 12.8):
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 \
--index-url https://download.pytorch.org/whl/cu128
Cho RTX 30/40-series (CUDA 12.1):
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0
3.4 Cài SUGAR packages
pip install -e source/sugar_rl
pip install -e source/sugar_il
Hai package này tách RL backbone (Stage 2) và IL distillation (Stage 3) ra cho dễ maintain.
3.5 Tải dataset và checkpoint
Repo cung cấp 3 archive qua gdown:
pip install gdown
# Data archive (kinematic priors đã extract sẵn, ~400MB)
gdown <DATA_LINK> -O data.zip && unzip data.zip -d data/
# Task descriptions (~50MB)
gdown <DESC_LINK> -O descriptions.zip && unzip descriptions.zip -d descriptions/
# Demo checkpoints (~250MB) — để chạy inference ngay không cần train
gdown <CKPT_LINK> -O checkpoints.zip && unzip checkpoints.zip -d checkpoints/
Link gdown chính xác xem trong README repo (thay đổi theo phiên bản). Tổng cộng ~700MB — tải nhanh.
4. Training — 6 Task có sẵn
SUGAR ship sẵn 6 task tiêu biểu, đủ bao quát các kỹ năng loco-manipulation cơ bản:
| Task | Mô tả | Skill chính |
|---|---|---|
CarryBox |
Bê hộp đi từ A đến B | Whole-body carry + bipedal walk |
KickBox |
Đá hộp về phía trước | Single-leg balance + dynamic motion |
PushBox |
Đẩy hộp trên sàn | Pushing with feedback |
SitChair |
Đi tới ghế và ngồi xuống | Bipedal walk + sit + balance |
StandBottle |
Đặt chai đứng thẳng (chai nằm ngang) | Bimanual fine-grained manipulation |
PickBottle |
Cúi xuống nhặt chai | Squat + grasp + recover |
Train một task:
bash train.sh CarryBox
Thời gian train ước tính (RTX 4090): ~6–10 giờ cho mỗi task tới hội tụ. Trên RTX 3090 sẽ chậm hơn ~50%.
Script train.sh thực ra là wrapper gọi 2 stage:
# Pseudo-code bên trong train.sh
# Stage 2: privileged RL refinement
python -m sugar_rl.train --task CarryBox --num_envs 4096
# Stage 3: hierarchical distillation
python -m sugar_il.distill --task CarryBox --rl_ckpt <stage2_ckpt>
Bạn có thể chạy từng bước nếu muốn debug. Theo dõi training bằng TensorBoard:
tensorboard --logdir logs/ --port 6006
Reward curve sẽ tăng đều rồi plateau — khi plateau khoảng 1k steps mà không lên nữa là OK để stop.
5. Inference — Chạy thử checkpoint
Sau khi train xong (hoặc tải demo checkpoint), inference cực đơn giản:
bash inference.sh CarryBox
Script này load model từ checkpoints/CarryBox/, spawn 1 robot trong IsaacSim và chạy rollout. Bạn sẽ thấy robot tự bước tới, cúi xuống, bê hộp, đi tới đích.
Inference với checkpoint custom:
bash inference.sh CarryBox \
--tracker_ckpt path/to/your/tracker.pt \
--generator_ckpt path/to/your/generator.pt
Tham số --tracker_ckpt và --generator_ckpt cho phép trộn module — ví dụ thử generator mới với tracker cũ.

6. Sim-to-Real — Deploy lên Robot thật
Paper báo cáo deploy thành công trên humanoid hardware thật (không nêu tên brand cụ thể trong abstract, nhưng các đặc tính khớp với Unitree H1-2 hoặc Booster T1). Pipeline sim-to-real:
- Domain randomization trong Stage 2 — Randomize mass, friction, motor delay, sensor noise. Đây là kỹ thuật chuẩn (xem Booster Gym ICRA 2026 — sim2real T1 để hiểu chi tiết).
- Privileged-to-non-privileged distillation — Tracker Stage 3 chỉ thấy observation robot thật có (joint pos/vel, IMU, RGB-D), không thấy ground-truth pose như Stage 2.
- Closed-loop execution — Robot deploy thì re-plan liên tục, không follow blindly trajectory đã sinh. Nếu bị đẩy lệch hay vật trượt, generator sinh lệnh mới ngay.
Để chạy trên robot bạn, cần:
- ROS 2 bridge (đa số humanoid commercial đều có)
- Mapping observation từ robot real sang observation space của Stage 3
- Mapping action output sang joint command robot thật (joint order có thể khác)
Mục này paper chưa public detail full — nên fork repo và đợi tác giả release hardware integration code.
7. Kết quả paper báo cáo
Bảng kết quả (rút gọn từ paper):
- 6/6 task thành công zero-shot generalize sang object mới cùng category (box khác kích thước, chai khác hình dạng).
- Failure recovery — Khi robot bị đẩy, ngã, rớt vật, autonomous policy resume task mà không cần reset thủ công.
- Data scaling — Performance scaling rõ rệt với số lượng video người (10 → 100 → 1000 video). Càng nhiều video, càng robust.
- Closed-loop stable — Long-horizon task (CarryBox đi 5m) ổn định.
So với baselines (motion tracking + manual reward), SUGAR vượt đáng kể ở task generalization, đặc biệt khi gặp object/scene chưa thấy trong training.
8. Pitfalls — Mình đã thấy gì khi thử cài
Một số bẫy thường gặp khi reproduce paper open-source robotics:
- CUDA version mismatch — PyTorch 2.8 cho CU128 chỉ chạy đúng trên Blackwell. RTX 4090/3090 phải dùng CU121. Nhầm là crash IsaacSim luôn.
- IsaacSim 5.1 trên Ubuntu 24.04 chưa stable — Khuyến nghị Ubuntu 22.04 LTS với kernel 5.15.
- GPU memory —
num_envs=4096đòi ~22GB VRAM. Nếu chỉ 12GB (RTX 3060), giảm xuống 1024 hoặc 2048. - Headless mode bắt buộc khi train trên server — Thêm flag
--headlessvào lệnh train, không thì IsaacSim sẽ cố mở GUI và crash. - Manager-based config khá rườm rà — IsaacLab manager-based ép bạn config qua YAML/Python files. Đọc tutorial IsaacLab trước, đừng nhảy vào SUGAR luôn.
9. Khi nào nên dùng SUGAR? Khi nào không?
Dùng SUGAR khi:
- Bạn muốn train task mới mà không muốn ngồi tune reward.
- Bạn có (hoặc có thể quay) video người làm task đó. Quay vài chục clip 30 giây bằng iPhone là OK.
- Bạn có hardware humanoid thật hoặc sim accurate.
KHÔNG dùng SUGAR khi:
- Task quá khác xa con người (robot công nghiệp 6-DoF arm gắn cố định không phù hợp).
- Bạn cần độ chính xác sub-millimeter (precision assembly) — SUGAR ưu tiên general, không precision.
- Bạn không có GPU mạnh (tối thiểu RTX 3090 / A6000).
Có thể đối chiếu với Gear Sonic Whole-Body Control — Gear Sonic dùng motion priors + MPC, còn SUGAR dùng video người + RL distillation. Hai hướng bổ sung nhau, không loại trừ.
10. Tài nguyên & Tham khảo
- Paper: SUGAR — arXiv:2605.20373 — Tianshu Wu et al., 2026
- Project website: tianshuwu.github.io/sugar-humanoid
- Code: github.com/tianshuwu/SUGAR
- IsaacLab docs: isaac-sim.github.io/IsaacLab
Tổng kết
SUGAR đại diện cho một thay đổi tư duy: thay vì coi humanoid là robot công nghiệp cần programming chính xác, coi nó như sinh viên có thể học bằng cách xem video. Cách tiếp cận này scale được với data (càng nhiều video càng tốt), không cần expert tune reward, và sống tốt với object/scene mới.
Nếu bạn đang xây dựng humanoid stack tại Việt Nam, SUGAR đáng để fork về thử ngay. Hardware tối thiểu là Unitree G1 hoặc tương đương + 1 GPU 24GB. Cộng đồng vnrobo sẽ theo dõi và update khi có hardware integration cụ thể.

