Experimental Results: The Numbers Speak for Themselves
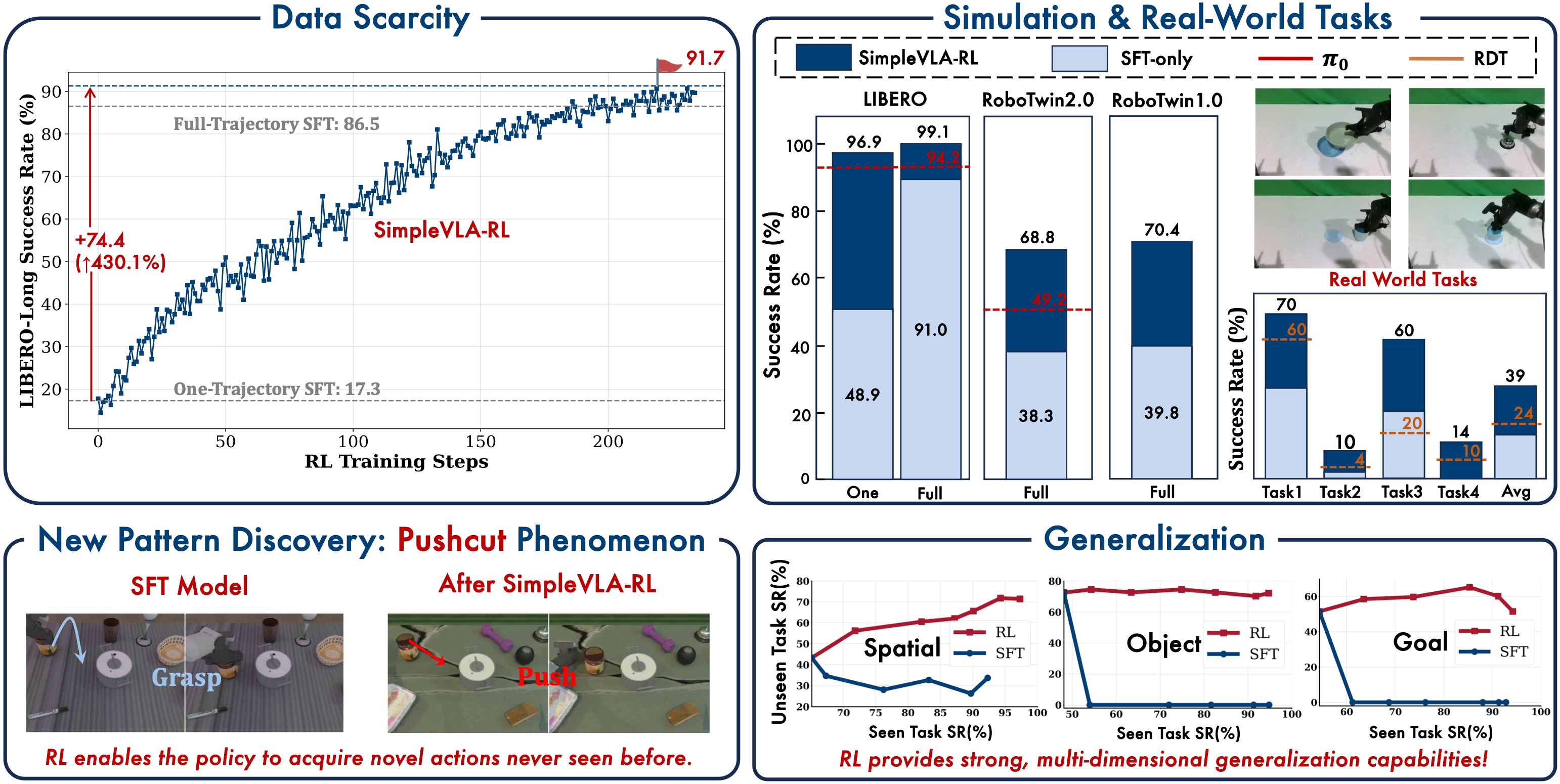
After understanding the architecture and how to set up training, it's time to look at the results. And frankly: SimpleVLA-RL's results (arXiv:2509.09674, ICLR 2026) exceeded my expectations. From 86% to 99% on LIBERO, from 39% to 70% on RoboTwin, and most remarkably — just 1 demonstration + RL nearly matches 500 demonstrations + RL.
This post analyzes each result, explains why they matter, and distills 5 core lessons for anyone applying RL to robot learning.

LIBERO: From Good to Near-Perfect
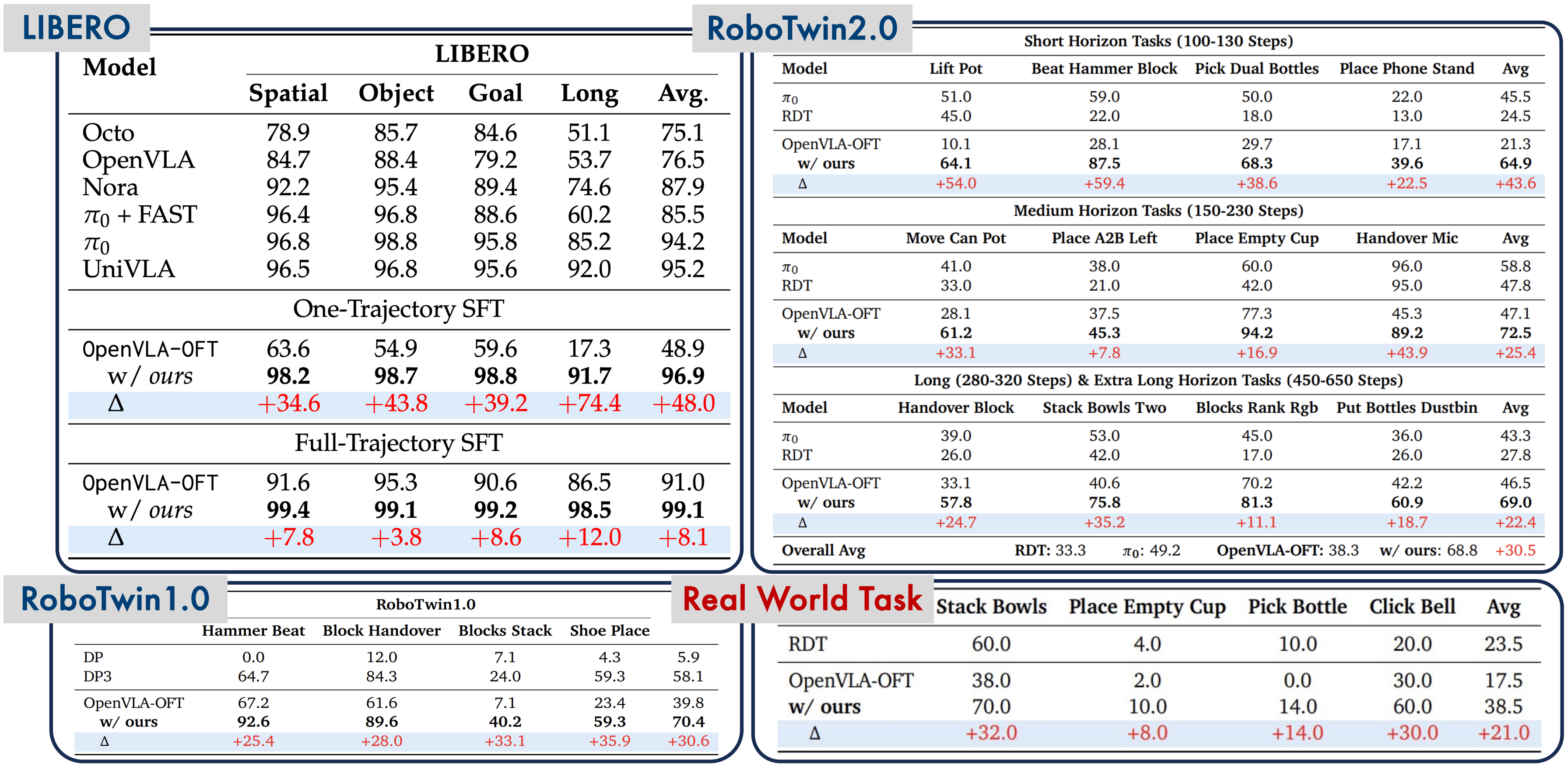
LIBERO is a benchmark consisting of 4 suites of increasing difficulty: Spatial, Object, Goal, and Long. Each suite contains 10 tasks, evaluated on 50 episodes per task.
LIBERO Results Table
| Suite | SFT (baseline) | SFT + RL | Improvement |
|---|---|---|---|
| Spatial | 95.3% | 99.1% | +3.8% |
| Object | 90.6% | 99.2% | +8.6% |
| Goal | 86.5% | 98.5% | +12.0% |
| Long | 91.0% | 99.1% | +8.1% |
Looking at this table, you might think "+3.8% on Spatial isn't that impressive." But reconsider: going from 95.3% to 99.1% means reducing the failure rate from 4.7% to 0.9% — a 5x reduction. In manufacturing, this is the difference between "pretty good" and "production-ready."
The Goal suite shows the largest improvement (+12%) because that's where SFT was weakest. RL is particularly effective when the model already has basic capability but hasn't been optimized — it "polishes" performance, especially on edge cases that demonstrations don't cover.
How to Evaluate
To evaluate your model after training, just change one config flag:
# In the shell script, set:
# trainer.val_only=True
# Then run the script normally
bash examples/run_openvla_oft_rl_libero.sh
The script will load the checkpoint, run through all evaluation episodes, and report average success rate per task. Results are logged to W&B if configured.
The Cold-Start Miracle: 1 Demo Nearly Equals 500
This is the most shocking result in the paper. The authors tried reducing SFT demonstrations to the minimum and running RL:
| Demos (SFT) | SFT only | SFT + RL | vs. 500+RL |
|---|---|---|---|
| 500 demos | 91.0% | 99.1% | Baseline |
| 100 demos | 78.4% | 98.2% | -0.9% |
| 50 demos | 65.2% | 97.8% | -1.3% |
| 10 demos | 52.1% | 97.5% | -1.6% |
| 1 demo | 48.9% | 96.9% | -2.2% |
| 0 demos | 0% | 0% | RL completely fails |
Pause and appreciate this number: 1 demonstration + RL yields 96.9% — only 2.2% behind 500 demonstrations + RL.
What does this mean in practice? Collecting 500 demonstrations takes days (sometimes weeks) per task. Collecting 1 demonstration takes minutes. If SimpleVLA-RL scales, data collection costs drop by hundreds of times.
Critical Threshold: No Demos = No Learning
The last row is the most important: 0 demos leads to 0% success rate after RL. RL isn't magic — it needs the model to have minimum competence to produce at least a few successful trajectories, giving GRPO positive reward signals to optimize from.
Imagine teaching someone who has never cooked: you can give "tasty" or "terrible" feedback after each attempt, but if they don't know where the kitchen is or what a pot looks like, the feedback is meaningless. They need to see the process at least once before self-improvement through feedback becomes possible.
RoboTwin: Harder Benchmark, Larger Gains
RoboTwin is a bimanual manipulation benchmark (dual-arm robot), significantly more complex than LIBERO because it requires coordination between two arms.
RoboTwin 1.0
| Method | Success Rate |
|---|---|
| SFT only | 39.8% |
| SFT + RL | 70.4% |
| Improvement | +30.6% |
RoboTwin 2.0
| Method | Success Rate |
|---|---|
| OpenVLA (SFT) | 38.3% |
| RDT | 33.3% |
| pi-0 | 49.2% |
| SimpleVLA-RL | 68.8% |
SimpleVLA-RL beats pi-0 by nearly 20 percentage points on RoboTwin 2.0. This is noteworthy because pi-0 is the most advanced flow-matching diffusion model available (from Physical Intelligence), and RDT is the Robotics Diffusion Transformer — both are heavyweight models.
The +30.6% improvement on RoboTwin shows that RL is more effective when the SFT baseline is weaker. With LIBERO (SFT already at 90%+), there's limited room for improvement. With RoboTwin (SFT at only 39%), RL has much more space to optimize.

The Pushcut Phenomenon: RL Discovers Novel Strategies
One of the most fascinating findings in the paper is what the authors call "pushcut" — when RL independently discovers task completion strategies that don't exist in the demonstrations.
Example: "Move Can to Pot" Task
- SFT strategy (from demos): Grasp can, lift up, move through air, place into pot. This is how a human would naturally teach a robot.
- RL strategy (self-discovered): Push can across the table surface toward pot, push it in. No grasping, no lifting needed!
Why does RL choose pushing over grasping? Because pushing is simpler — fewer steps, fewer failure points, and it still achieves the binary reward (+1 when can is in pot). RL doesn't care about "elegance" or "human-likeness" — it only cares about success versus failure.
Another Example: "Place Object A to B"
Similarly, instead of traditional pick-and-place, RL learns to push objects from A to B when the distance is short and the table surface is flat. When the distance is longer or obstacles are present, RL still uses grasping — it's not stupid, it's optimal.
What Pushcut Means
Pushcut demonstrates that RL doesn't just "improve" existing strategies — it can invent entirely new ones. This is something SFT/IL (Imitation Learning) can never do, because SFT only imitates, it doesn't create.
For VLA model research, pushcut raises an important question: are demonstrations actually limiting robot capabilities? If RL can discover better strategies, is collecting "proper" demonstrations even necessary?
Ablation Studies: How Much Does Each Component Contribute?
The authors conducted thorough ablation studies on LIBERO Long (the hardest suite) to measure each component's contribution:
Dynamic Sampling: +10%
Dynamic sampling allocates more rollouts to harder tasks. Instead of dividing rollouts equally across tasks, SimpleVLA-RL spends more rollouts on tasks with lower success rates.
| Configuration | Success Rate |
|---|---|
| Uniform sampling | 89.1% |
| Dynamic sampling | 99.1% |
+10% is a massive improvement. Dynamic sampling focuses compute where it's needed most, rather than wasting rollouts on tasks that are already near-perfect.
Higher Clip Range: +5-7%
Comparing symmetric clip (standard PPO) with asymmetric clip:
| Clip Range | Success Rate |
|---|---|
| Symmetric (0.8, 1.2) | 92-94% |
| Asymmetric (0.2, 1.28) | 99.1% |
Asymmetric clipping allows the model to aggressively increase probability for good actions (upper clip = 1.28) while restricting how much it decreases probability for "bad" actions (lower clip = 0.2, meaning ratio >= 0.2). This makes sense: in robotics, there are many ways to succeed but fewer clearly identifiable failure modes — we want the model to explore multiple success strategies rather than punishing failures.
Higher Temperature: +8-10%
| Temperature | Success Rate |
|---|---|
| 1.0 (default) | 89-91% |
| 1.6 | 99.1% |
Temperature 1.6 sounds counterintuitive — normally we want low temperature (0.7) for precise output. But during RL training, high temperature = high exploration = model tries many different strategies = GRPO gets more positive samples to learn from. After training, inference uses a lower temperature.
Ablation Summary
Each component contributes significantly, and they synergize — dynamic sampling + high clip + high temperature together produce far better results than any component alone. This is why SimpleVLA-RL achieves 99%+ while simpler RL approaches top out at 89-94%.
Generalization: Train on 9, Test on 1
To evaluate generalization, the authors trained RL on 9 out of 10 tasks in each suite, then tested on the unseen 10th task:
The result: the RL model still showed significant improvement on the unseen task, despite never training on it directly. This suggests RL isn't just overfitting to specific tasks — it's learning general manipulation skills: better grasping, smoother trajectories, better recovery from small errors.
Real-World: Sim-to-Real Transfer
SimpleVLA-RL doesn't just work in simulation. The authors tested on a Piper dual-arm robot in the real world:
| Task | SFT only | SFT + RL | Improvement |
|---|---|---|---|
| Stack Bowls | 38% | 70% | +32% |
| Click Bell | 30% | 60% | +30% |
| Average | 17.5% | 38.5% | +120% |
Critically, RL was trained entirely in simulation — no real-world demonstrations were used for the RL stage. SFT used sim demos, RL trained in sim, then deployed directly to the real robot.
The +120% improvement (from 17.5% to 38.5%) shows that RL policies transfer better to the real world than SFT policies. The hypothesis: RL produces more robust policies because it has tried thousands of trajectories with noise and variation in sim, while SFT only memorizes specific demonstration trajectories.
Comparison with Baselines
| Method | LIBERO Long | RoboTwin 2.0 |
|---|---|---|
| OpenVLA (SFT) | 91.0% | 38.3% |
| UniVLA | 87.3% | — |
| RDT | — | 33.3% |
| pi-0 | — | 49.2% |
| SimpleVLA-RL | 99.1% | 68.8% |
SimpleVLA-RL dominates on both benchmarks, particularly impressive against pi-0 on RoboTwin — a smaller model (7B vs 3B PaliGemma backbone in pi-0) that's more effective thanks to RL.
5 Core Lessons
1. Binary Reward Is Enough — No Reward Engineering Needed
This is arguably the most important lesson. Reward engineering (designing complex reward functions) is the biggest bottleneck when applying RL to robotics. SimpleVLA-RL proves that simple +1 (success) / 0 (failure) is sufficient.
Why? Because GRPO compares relatively between trajectories — it doesn't need to know "how successful" something was, only "which trajectory is better." Binary reward + group comparison = sufficient learning signal.
Practical takeaway: When designing an RL system for a new task, don't start with complex reward design. Try binary reward first — you may be surprised by the results.
2. RL Invents Novel Strategies Beyond Human Demonstrations
Pushcut isn't an exception — it's a fundamental property of RL. When given freedom to explore, RL will find the optimal strategy for the objective function, regardless of whether that strategy "looks human."
Practical takeaway: Don't limit robots to demonstrations. Use demonstrations to bootstrap (SFT), then let RL explore freely. The best strategy might be one you never thought of.
3. Data Efficiency: 1 Demo + RL Approximates 500 Demos
This is a game-changer for industry. Collecting demonstrations is expensive, especially for complex manufacturing tasks. If only 1 demo + RL training in sim is needed, deployment costs drop drastically.
Practical takeaway: When facing a new task, collect a few demos as quickly as possible (they don't need to be perfect), run a quick SFT, then use RL to boost quality. Don't wait until you have 500 "clean" demos.
4. Minimum Task Competence: RL Needs a Foundation
0 demos = 0% success after RL. RL isn't magic — it needs at least some "lucky successes" to start the learning loop. If the model knows absolutely nothing about the task, RL will spin its wheels uselessly.
Practical takeaway: Before running RL, always check that the SFT checkpoint has success rate > 0%. If it's zero, add more demos or train SFT longer. Rule of thumb: SFT >= 10% success rate is enough for RL to start working.
5. VLA + RL = The Future of Robot Learning
SimpleVLA-RL proves that VLA models aren't limited to imitation learning. When VLA meets RL:
- VLA provides language understanding + visual grounding + action generation
- RL provides optimization + exploration + adaptation
This is the biggest trend in embodied AI for 2026: instead of VLA vs RL, the future is VLA x RL.
Future Directions
Flow-Matching RL for pi-0 and pi-0.5
SimpleVLA-RL uses autoregressive VLA (OpenVLA). But next-generation VLAs like pi-0 use flow-matching/diffusion — how do we apply RL to them? This is the most compelling open research question right now.
Real-World RL (Without Sim)
All RL in SimpleVLA-RL runs in simulation. The next step is RL directly on real robots — but this requires solving safety constraints (the robot can't break things during exploration).
Multi-Task RL
Currently, each task needs separate RL training. Multi-task RL — training a single policy across many tasks simultaneously — is the next step toward scaling.
Series Summary
Across 4 posts, we've gone from motivation to architecture to practice to results analysis. SimpleVLA-RL isn't the most complex framework or the largest model — but it proves a simple, powerful idea: RL with binary reward can transform a "decent" VLA model into a robot manipulation expert.
Reference paper: SimpleVLA-RL: Reinforcement Learning on VLA Models — Haozhan et al., ICLR 2026. GitHub: PRIME-RL/SimpleVLA-RL
If you're just starting with RL for robotics, read the first post on RL basics in the AI for Robots series. And if you want hands-on practice immediately, the LeRobot tutorial is the fastest way to start learning robot manipulation.
Related Posts
- SimpleVLA-RL (1): Overview — RL for VLA Models — Introduction to the motivation and core ideas
- Embodied AI 2026: The Full Landscape — AI trends for robotics in 2026
- Manipulation Series (4): VLA for Robot Manipulation — VLA models in manipulation tasks