Từ lý thuyết đến thực hành: Chạy SimpleVLA-RL trên cluster GPU
Ở bài trước, chúng ta đã phân tích kiến trúc của SimpleVLA-RL — cách nó kết hợp GRPO với VLA models để tạo ra một pipeline RL hoàn chỉnh cho robot manipulation. Bài này sẽ đi vào phần thực hành: setup môi trường từ đầu, chạy SFT stage, và training RL trên hai benchmark phổ biến nhất — LIBERO và RoboTwin.
Đây là bài hướng dẫn dành cho những ai muốn reproduce kết quả hoặc áp dụng SimpleVLA-RL cho task riêng. Mình sẽ chia sẻ chi tiết từng bước, bao gồm cả những lỗi thường gặp mà paper không đề cập.

Yêu cầu phần cứng
SimpleVLA-RL không phải dự án bạn có thể chạy trên laptop. Đây là yêu cầu phần cứng tối thiểu mà tác giả đã sử dụng:
| Thành phần | Yêu cầu |
|---|---|
| GPU | 8× NVIDIA A800 80GB (hoặc tương đương A100 80GB) |
| CUDA | 12.4 |
| RAM | 256GB+ (khuyến nghị 512GB) |
| Storage | 2TB+ NVMe SSD (checkpoints + datasets) |
| OS | Ubuntu 20.04/22.04 |
Tại sao cần nhiều GPU như vậy? RL training cho VLA models đòi hỏi:
- Model lớn: OpenVLA-OFT có 7B parameters — chỉ riêng model weights đã chiếm ~28GB ở FP32 hoặc ~14GB ở BF16.
- Parallel rollouts: Mỗi query cần sample 8 trajectories song song để estimate advantage — mỗi trajectory chạy trong simulator riêng biệt.
- Batch size lớn: Batch 64 queries × 8 samples = 512 trajectories mỗi iteration, cần chia đều lên 8 GPUs.
Nếu bạn chỉ có 4 GPUs, bạn vẫn có thể thử với batch size nhỏ hơn, nhưng kết quả sẽ kém hơn do variance cao hơn trong gradient estimation.
Cài đặt môi trường từ A-Z
Bước 1: Tạo Conda environment
# Tạo environment mới với Python 3.10
conda create -n simplevla python==3.10 -y
conda activate simplevla
# Cài PyTorch với CUDA 12.4
pip3 install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu124
Tại sao Python 3.10? Vì đây là phiên bản được test kỹ nhất với cả veRL lẫn openvla-oft. Python 3.11+ có thể gây conflict với một số dependencies.
Bước 2: Cài veRL (RL Framework)
veRL (Volcano Engine Reinforcement Learning) là framework RL do ByteDance phát triển, được SimpleVLA-RL chọn làm backbone cho toàn bộ training pipeline.
# Clone veRL v0.2 — PHẢI dùng đúng branch v0.2.x
git clone -b v0.2.x https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
cd ..
Lưu ý quan trọng: Phải dùng branch v0.2.x, không phải main. Branch main có thể có breaking changes so với SimpleVLA-RL.
Bước 3: Cài OpenVLA-OFT (VLA Model)
OpenVLA-OFT là phiên bản fine-tuned của OpenVLA, hỗ trợ action chunking — tức là predict nhiều actions cùng lúc thay vì từng action một.
# Clone OpenVLA-OFT
git clone https://github.com/moojink/openvla-oft.git
cd openvla-oft
pip install -e .
cd ..
Bước 4: Cài Flash Attention
Flash Attention là thành phần quan trọng để tăng tốc attention computation, giảm memory footprint đáng kể khi training model 7B.
# Flash Attention — cần build from source nên khá lâu (~10-15 phút)
pip3 install flash-attn --no-build-isolation
Flag --no-build-isolation là bắt buộc — nếu thiếu, build sẽ fail vì không tìm thấy torch trong isolated build environment.
Bước 5: Clone SimpleVLA-RL
git clone https://github.com/PRIME-RL/SimpleVLA-RL.git
cd SimpleVLA-RL
Bước 6: Cài benchmark (LIBERO hoặc RoboTwin)
Tùy thuộc vào benchmark bạn muốn chạy, cài một trong hai:
Option A — LIBERO:
# Clone và cài LIBERO
cd SimpleVLA-RL
pip install -e LIBERO
pip install -r experiments/robot/libero/libero_requirements.txt
Option B — RoboTwin 2.0:
# RoboTwin cần Vulkan cho rendering
sudo apt install libvulkan1
# Cài RoboTwin
cd SimpleVLA-RL
bash script/_install.sh
bash script/_download_assets.sh
RoboTwin 2.0 sử dụng Vulkan-based renderer nên cần GPU hỗ trợ Vulkan. Nếu chạy trên cloud instance, đảm bảo driver NVIDIA đã cài Vulkan support.
Cấu trúc thư mục cuối cùng
Sau khi cài đặt xong, workspace của bạn nên có cấu trúc như sau:
workspace/
├── SimpleVLA-RL/ # Main repo
│ ├── examples/ # Training scripts
│ ├── experiments/ # Experiment configs
│ ├── LIBERO/ # LIBERO benchmark (nếu dùng)
│ └── align.json # Config file cho training
├── verl/ # veRL framework
└── openvla-oft/ # OpenVLA-OFT model

SFT Stage: Xây dựng nền tảng trước khi RL
Trước khi chạy RL, model cần có năng lực tối thiểu để hoàn thành task. Đây là vai trò của SFT (Supervised Fine-Tuning) stage — train model bằng expert demonstrations trước.
Option 1: Download pre-trained SFT checkpoints (khuyến nghị)
Tác giả đã publish sẵn SFT checkpoints trên HuggingFace, tiết kiệm hàng giờ training:
# Tải checkpoints từ HuggingFace collection
# Collection: Haozhan72/simplevla-rl
# Có nhiều checkpoints cho các task khác nhau:
# - LIBERO Spatial, Object, Goal, Long
# - RoboTwin các task
pip install huggingface_hub
python -c "
from huggingface_hub import snapshot_download
snapshot_download(
repo_id='Haozhan72/simplevla-rl-libero-spatial-sft',
local_dir='./checkpoints/sft/libero-spatial'
)
"
Option 2: Tự train SFT từ đầu
Nếu bạn muốn train SFT cho task riêng, cần chuẩn bị:
- 500 demonstrations mỗi task (hoặc ít hơn — thậm chí 1 demo cũng có thể hoạt động, xem bài kết quả)
- Format: sequences of (image, action) pairs
- Train bằng standard supervised fine-tuning trên OpenVLA-OFT
# SFT training sử dụng OpenVLA-OFT standard pipeline
cd openvla-oft
python scripts/finetune.py \
--model_name openvla-7b \
--dataset_path /path/to/your/demos \
--output_dir ./checkpoints/sft-custom \
--num_epochs 50 \
--batch_size 16 \
--learning_rate 2e-5
Tip quan trọng: Kết quả trong paper cho thấy thậm chí chỉ 1 demonstration cũng đủ để SFT cho model đạt được năng lực tối thiểu, sau đó RL sẽ nâng lên gần bằng mức 500 demos. Nhưng 0 demos thì không được — model cần ít nhất thấy task một lần.
RL Training: Cấu hình và chạy
Bước 1: Cấu hình environment variables
Chỉnh sửa file align.json trong thư mục SimpleVLA-RL:
{
"WANDB_API_KEY": "your-wandb-api-key-here",
"WANDB_PROJECT": "simplevla-rl",
"WANDB_ENTITY": "your-username"
}
Weights & Biases (W&B) là tool monitoring training mặc định. Nếu không có tài khoản, đăng ký miễn phí tại wandb.ai.
Bước 2: Cấu hình training script
Mở file shell script tương ứng với benchmark (ví dụ: examples/run_openvla_oft_rl_libero.sh) và chỉnh các biến sau:
# Path tới SFT checkpoint đã download hoặc tự train
SFT_MODEL_PATH="/workspace/checkpoints/sft/libero-spatial"
# Path lưu RL checkpoints
CKPT_PATH="/workspace/checkpoints/rl/libero-spatial"
# Tên dataset trong LIBERO
DATASET_NAME="libero_spatial"
# Số GPUs (mặc định 8)
NUM_GPUS=8
Bước 3: Bảng hyperparameters
Đây là bảng hyperparameters đầy đủ mà tác giả sử dụng:
| Hyperparameter | LIBERO | RoboTwin | Giải thích |
|---|---|---|---|
| Learning rate | 5e-6 | 5e-6 | Thấp hơn nhiều so với SFT vì RL cần update nhẹ nhàng |
| Batch size | 64 | 64 | Số queries mỗi iteration |
| Samples per query | 8 | 8 | Số trajectories sample cho mỗi query (cho GRPO) |
| Mini-batch size | 128 | 128 | Cho gradient accumulation |
| Clip range | (0.2, 1.28) | (0.2, 1.28) | Asymmetric — cho phép tăng probability nhiều hơn giảm |
| Temperature | 1.6 | 1.6 | Cao hơn bình thường để khuyến khích exploration |
| Action chunks | 8 | 25 | Số actions predict cùng lúc |
| Max steps per episode | 512 | varies | Giới hạn độ dài trajectory |
Giải thích các hyperparameters quan trọng:
- Clip range (0.2, 1.28): Đây là asymmetric clip — khác với PPO chuẩn dùng symmetric (0.8, 1.2). Clip trên cao hơn (1.28 vs 1.2) cho phép model tự do tăng probability cho actions tốt nhiều hơn so với giảm probability cho actions xấu. Điều này giúp RL nhanh chóng khuếch đại những hành vi hiệu quả mà model phát hiện.
- Temperature 1.6: Cao hơn đáng kể so với giá trị mặc định (thường 0.7-1.0). Temperature cao khuyến khích exploration — model thử nhiều strategies khác nhau thay vì chỉ exploit chiến lược tốt nhất hiện tại.
- Action chunks: LIBERO dùng 8 vì tasks đơn giản hơn, RoboTwin dùng 25 vì tasks phức tạp hơn cần planning xa hơn.
Bước 4: Chạy training
cd SimpleVLA-RL
# Chạy RL training trên LIBERO
bash examples/run_openvla_oft_rl_libero.sh
# Hoặc trên RoboTwin
bash examples/run_openvla_oft_rl_robotwin.sh
Training sẽ mất khoảng 12-24 giờ tùy thuộc vào task và hardware. Trên 8× A800, LIBERO Spatial thường converge sau ~300-500 iterations.
Monitoring training với W&B
Khi training bắt đầu, mở W&B dashboard để theo dõi các metrics quan trọng:
Metrics cần theo dõi
- Success rate (quan trọng nhất): Tỷ lệ task hoàn thành thành công — đây là binary reward nên dễ theo dõi.
- Average reward: Giá trị reward trung bình. Với binary reward, đây chính là success rate.
- KL divergence: Đo lường model đã thay đổi bao nhiêu so với SFT checkpoint. Nếu KL quá cao (>10), model có thể đã diverge.
- Entropy: Đo lường mức exploration. Entropy giảm dần là bình thường — model đang converge sang exploitation.
- Gradient norm: Nếu explode (>100), cần giảm learning rate.
Kỳ vọng training curve
Với LIBERO Spatial (task dễ nhất):
- Iteration 0-50: Success rate tăng nhẹ từ baseline SFT (~95%)
- Iteration 50-200: Tăng mạnh nhất, đạt ~98%
- Iteration 200-500: Converge dần, đạt ~99%+
Với RoboTwin (khó hơn):
- Training lâu hơn, curve gập ghềnh hơn
- Đừng hoảng nếu success rate giảm tạm thời — đây là hiện tượng bình thường trong RL
Checkpoint management
Lưu checkpoint
SimpleVLA-RL tự động lưu checkpoints theo interval cấu hình trong script. Mỗi checkpoint bao gồm:
- Model weights (BF16)
- Optimizer state
- Training metadata (iteration, metrics)
Mỗi checkpoint chiếm khoảng 15-20GB, nên cần đảm bảo có đủ storage. Với 500 iterations, bạn có thể cần 100GB+ cho checkpoints.
Chọn checkpoint tốt nhất
Không phải lúc nào checkpoint cuối cùng cũng tốt nhất. Sử dụng W&B để tìm iteration với success rate cao nhất, rồi evaluate checkpoint đó:
# Evaluate checkpoint cụ thể
# Sửa trong script: trainer.val_only=True
# Rồi chạy với checkpoint tương ứng
bash examples/run_openvla_oft_rl_libero.sh
Evaluation
Để đánh giá model sau training, chỉ cần thay đổi một config:
# Trong shell script, set:
# trainer.val_only=True
# Sau đó chạy script bình thường
bash examples/run_openvla_oft_rl_libero.sh
Evaluation sẽ chạy model qua tất cả test episodes và báo cáo success rate trung bình. Mỗi suite trong LIBERO có 10 tasks × 50 evaluation episodes = 500 episodes tổng cộng.
Troubleshooting: Những lỗi thường gặp
1. CUDA Out of Memory
RuntimeError: CUDA out of memory. Tried to allocate 2.00 GiB
Nguyên nhân: Không đủ GPU memory cho batch size hiện tại.
Giải pháp: Giảm samples_per_query từ 8 xuống 4, hoặc giảm batch_size. Nhưng lưu ý kết quả sẽ kém hơn.
2. Flash Attention build fail
error: command 'gcc' failed
Nguyên nhân: Thiếu CUDA toolkit hoặc version mismatch.
Giải pháp: Đảm bảo nvcc --version trả về CUDA 12.4, và gcc --version >= 9.0.
3. LIBERO import error
ImportError: cannot import name 'LIBERO' from 'libero'
Nguyên nhân: Cài LIBERO bằng pip install thay vì pip install -e . (editable mode).
Giải pháp: cd LIBERO && pip install -e .
4. Vulkan error (RoboTwin)
RuntimeError: Failed to initialize Vulkan
Nguyên nhân: GPU không có Vulkan driver hoặc chạy headless server.
Giải pháp: sudo apt install libvulkan1 mesa-vulkan-drivers. Nếu headless: cần EGL rendering fallback.
5. Training diverge (reward giảm liên tục)
Nguyên nhân: SFT checkpoint quá yếu — model chưa có khả năng cơ bản để hoàn thành task. Giải pháp: Kiểm tra SFT checkpoint có success rate >= 30% không. Nếu dưới mức đó, cần train SFT lâu hơn hoặc thêm demonstrations.
6. W&B connection timeout
wandb: ERROR Error communicating with wandb process
Nguyên nhân: Firewall block outbound connection.
Giải pháp: Set WANDB_MODE=offline để log locally, sau đó wandb sync khi có internet.
Tối ưu cho hardware khác nhau
Nếu bạn không có đúng 8× A800, đây là cách điều chỉnh:
| Hardware | Thay đổi cần thiết |
|---|---|
| 4× A100 80GB | Giảm batch_size xuống 32, samples_per_query giữ 8 |
| 8× A100 40GB | Bật gradient checkpointing, giảm max_steps xuống 256 |
| 4× A6000 48GB | Giảm batch_size xuống 16, bật DeepSpeed ZeRO-3 |
| 2× H100 80GB | Batch 32, dùng tensor parallelism |
Lưu ý: Giảm batch size ảnh hưởng đến chất lượng gradient estimation trong GRPO. Batch nhỏ hơn → variance cao hơn → training ít ổn định hơn → cần giảm learning rate tương ứng.
Tiếp theo
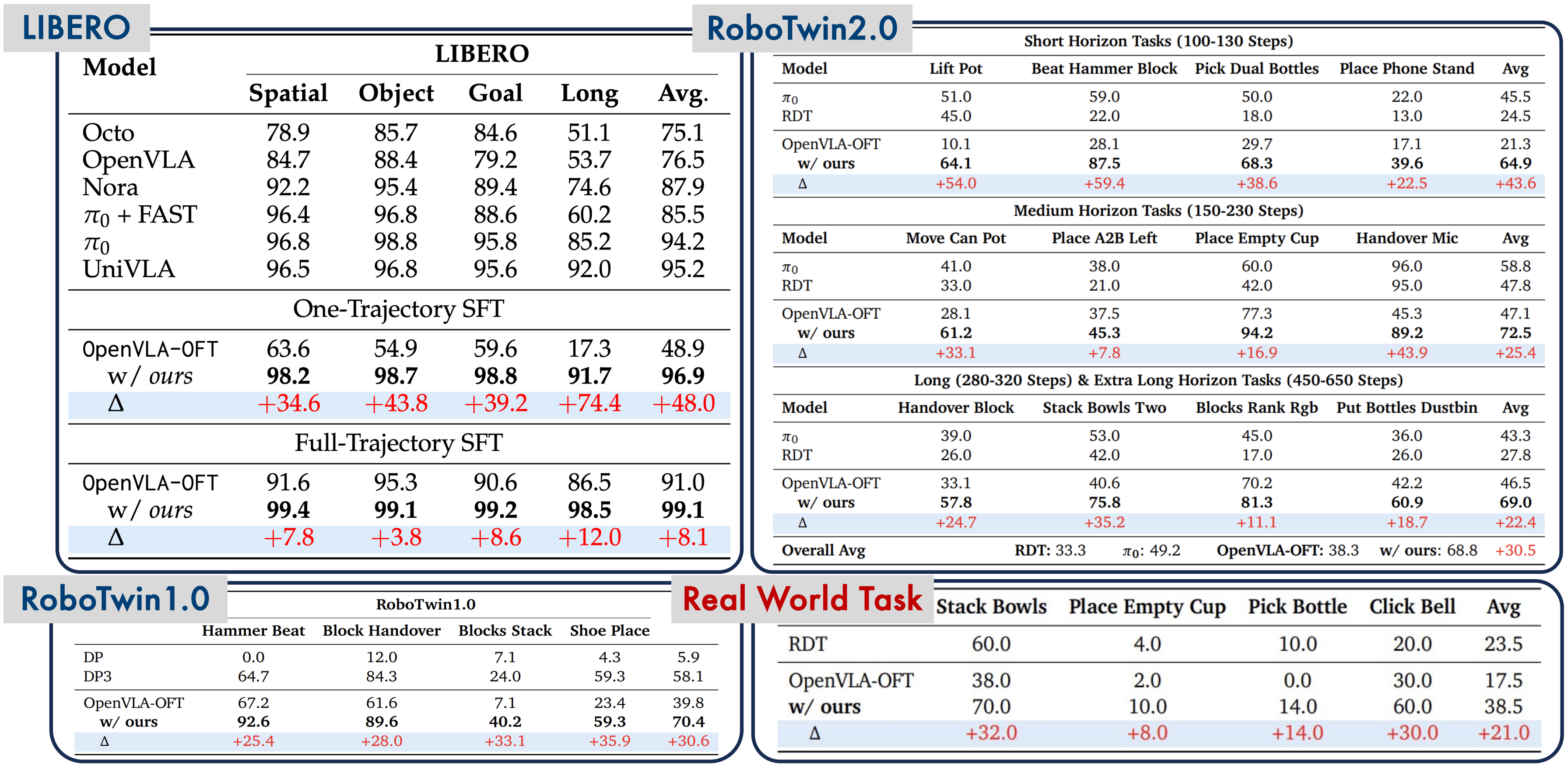
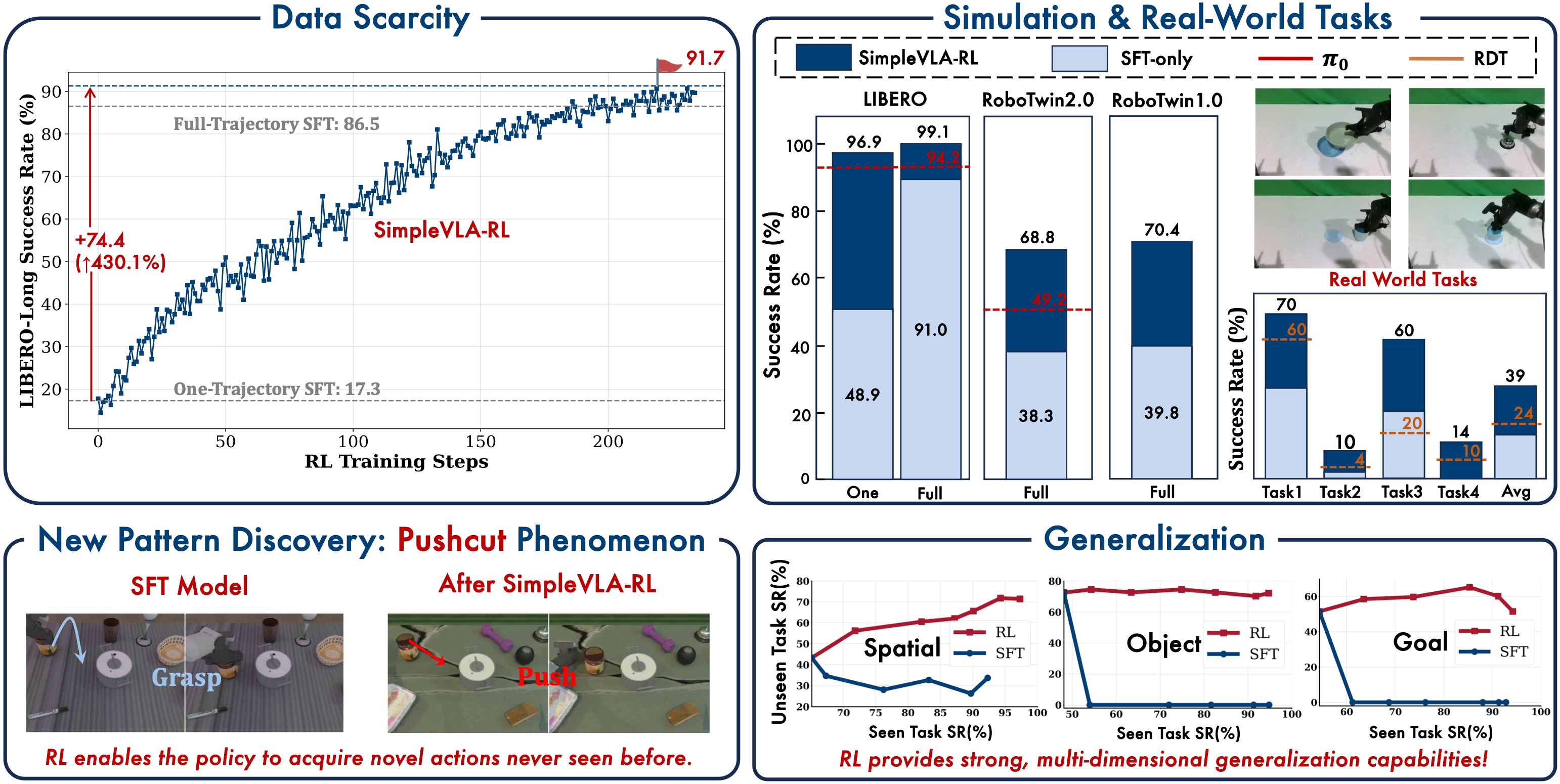
Ở bài tiếp theo — SimpleVLA-RL (4): Kết quả & Bài học, chúng ta sẽ phân tích chi tiết kết quả thực nghiệm: từ con số ấn tượng trên LIBERO (99%+ success rate) đến hiện tượng thú vị "pushcut" — khi RL phát hiện ra chiến lược mà con người không dạy. Và quan trọng nhất: 5 bài học rút ra cho bất kỳ ai muốn áp dụng RL cho robot learning.
Nếu bạn chưa đọc phần kiến trúc, hãy quay lại SimpleVLA-RL (2): Kiến trúc & Thuật toán để hiểu tại sao các hyperparameters được chọn như vậy. Và nếu bạn muốn hiểu nền tảng VLA models, series AI cho Robot là điểm khởi đầu tốt.
Bài viết liên quan
- SimpleVLA-RL (1): Tổng quan — RL cho VLA Models — Giới thiệu ý tưởng và motivation của SimpleVLA-RL
- SimpleVLA-RL (2): Kiến trúc & Thuật toán — Deep dive vào GRPO adaptation cho robotics
- AI Series (5): VLA Models — Vision-Language-Action — Nền tảng về VLA models cho robot manipulation