Kết quả thực nghiệm: Con số nói lên tất cả
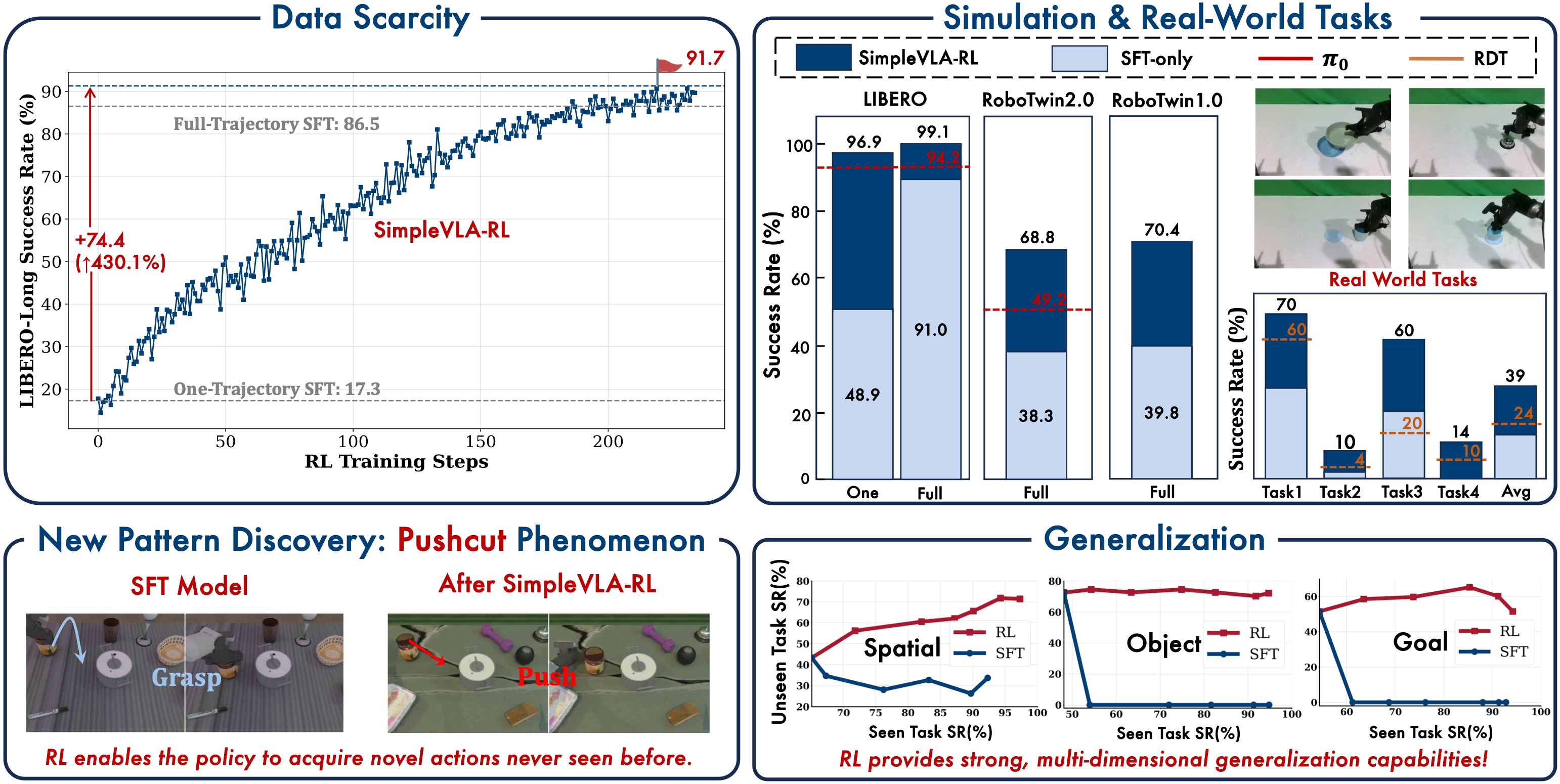
Sau khi đã hiểu kiến trúc và cách setup training, giờ là lúc nhìn vào kết quả. Và phải nói thẳng: kết quả của SimpleVLA-RL (arXiv:2509.09674, ICLR 2026) vượt xa kỳ vọng ban đầu của mình. Từ mức 86% lên 99% trên LIBERO, từ 39% lên 70% trên RoboTwin, và đặc biệt — chỉ 1 demonstration + RL đã gần bằng 500 demonstrations + RL.
Bài này sẽ phân tích từng kết quả, giải thích tại sao chúng quan trọng, và rút ra 5 bài học cốt lõi cho bất kỳ ai muốn áp dụng RL vào robot learning.

LIBERO: Từ tốt lên gần hoàn hảo
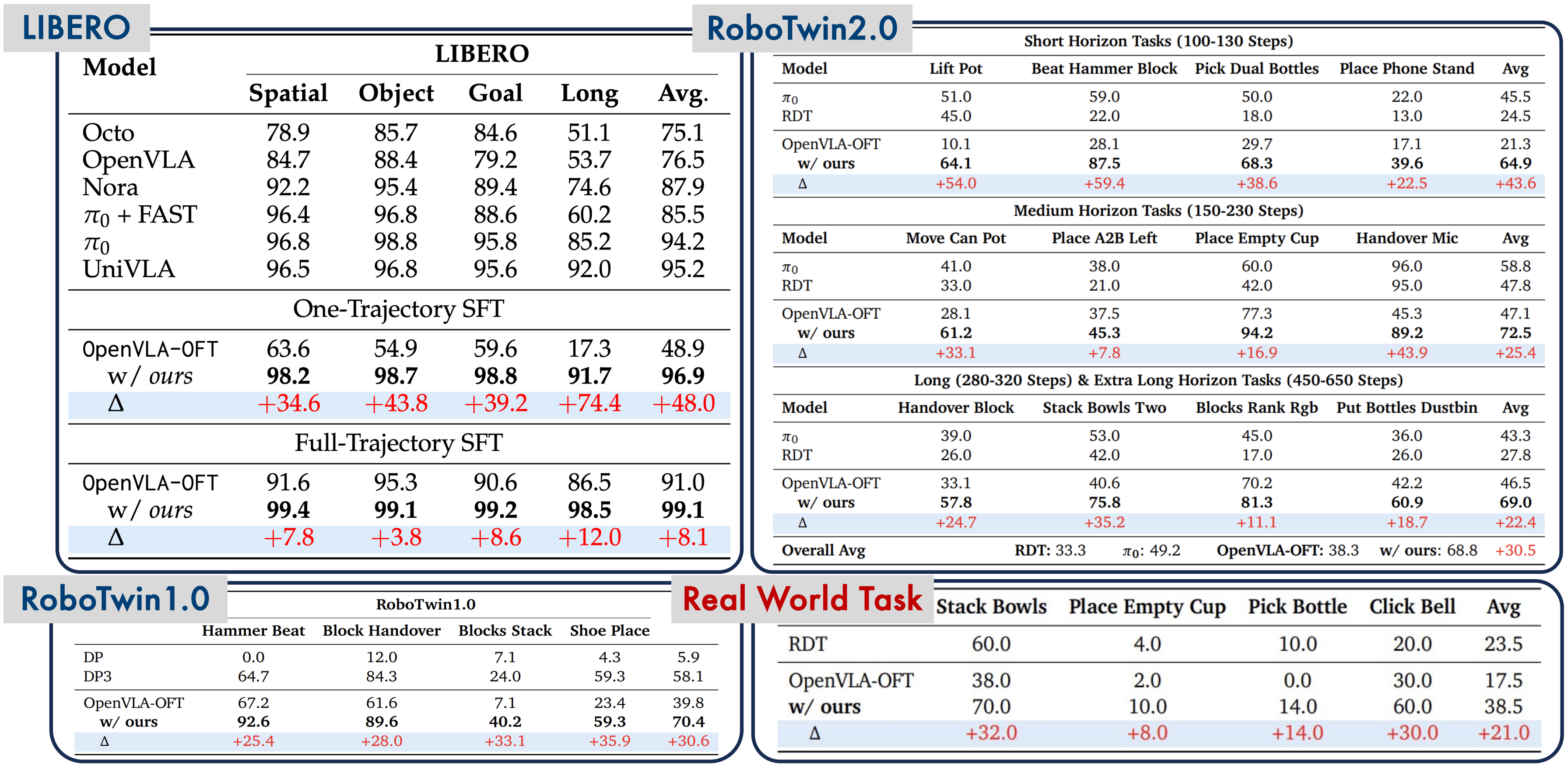
LIBERO là benchmark gồm 4 suites với độ khó tăng dần: Spatial, Object, Goal, và Long. Mỗi suite có 10 tasks, đánh giá trên 50 episodes mỗi task.
Bảng kết quả LIBERO
| Suite | SFT (baseline) | SFT + RL | Cải thiện |
|---|---|---|---|
| Spatial | 95.3% | 99.1% | +3.8% |
| Object | 90.6% | 99.2% | +8.6% |
| Goal | 86.5% | 98.5% | +12.0% |
| Long | 91.0% | 99.1% | +8.1% |
Nhìn vào bảng, bạn có thể nghĩ "+3.8% trên Spatial thì không ấn tượng lắm". Nhưng hãy suy nghĩ lại: từ 95.3% lên 99.1% nghĩa là giảm tỷ lệ thất bại từ 4.7% xuống 0.9% — giảm hơn 5 lần. Trong manufacturing, đây là sự khác biệt giữa "khá tốt" và "production-ready".
Suite Goal có cải thiện lớn nhất (+12%) vì đây là nơi SFT yếu nhất. RL đặc biệt hiệu quả khi model đã có khả năng cơ bản nhưng chưa tối ưu — nó "đánh bóng" performance, đặc biệt ở những edge cases mà demonstrations không cover.
Cách đánh giá (Evaluation)
Để evaluate model sau khi train, chỉ cần thay đổi config trong training script:
# Trong shell script, set flag:
# trainer.val_only=True
# Rồi chạy lại script bình thường
bash examples/run_openvla_oft_rl_libero.sh
Script sẽ load checkpoint, chạy qua tất cả evaluation episodes, và báo cáo success rate trung bình cho từng task. Kết quả được log lên W&B nếu đã cấu hình.
Cold-start miracle: 1 demo gần bằng 500 demos
Đây là kết quả gây shock nhất trong paper. Tác giả thử giảm số lượng SFT demonstrations xuống mức tối thiểu và chạy RL:
| Số demos (SFT) | SFT only | SFT + RL | So sánh |
|---|---|---|---|
| 500 demos | 91.0% | 99.1% | Baseline |
| 100 demos | 78.4% | 98.2% | -0.9% so với 500+RL |
| 50 demos | 65.2% | 97.8% | -1.3% so với 500+RL |
| 10 demos | 52.1% | 97.5% | -1.6% so với 500+RL |
| 1 demo | 48.9% | 96.9% | -2.2% so với 500+RL |
| 0 demos | 0% | 0% | RL hoàn toàn thất bại |
Hãy dừng lại và cảm nhận con số này: 1 demonstration + RL cho ra kết quả 96.9% — chỉ cách 500 demonstrations + RL có 2.2%.
Điều này có nghĩa gì cho thực tế? Thu thập 500 demonstrations tốn hàng ngày (thậm chí hàng tuần) cho mỗi task. Nhưng thu thập 1 demonstration chỉ mất vài phút. Nếu SimpleVLA-RL scale được, chi phí data collection sẽ giảm hàng trăm lần.
Critical threshold: Không demo = Không học được
Dòng cuối cùng trong bảng là quan trọng nhất: 0 demos → 0% success rate sau RL. RL không phải phép màu — nó cần model có khả năng tối thiểu để tạo ra ít nhất một vài trajectory thành công, từ đó GRPO mới có positive reward signals để optimize.
Tưởng tượng bạn dạy một người chưa bao giờ nấu ăn: bạn có thể cho feedback "ngon" hay "dở" mỗi lần họ nấu, nhưng nếu họ không biết bếp ở đâu, nồi là gì, thì feedback sẽ vô nghĩa. Ít nhất phải chỉ cho họ nấu 1 lần, rồi mới để họ tự cải thiện qua feedback.
RoboTwin: Benchmark khó hơn, cải thiện lớn hơn
RoboTwin là benchmark bimanual manipulation (robot 2 cánh tay), phức tạp hơn LIBERO nhiều vì cần coordination giữa 2 tay.
RoboTwin 1.0
| Phương pháp | Success Rate |
|---|---|
| SFT only | 39.8% |
| SFT + RL | 70.4% |
| Cải thiện | +30.6% |
RoboTwin 2.0
| Phương pháp | Success Rate |
|---|---|
| OpenVLA (SFT) | 38.3% |
| RDT | 33.3% |
| π₀ | 49.2% |
| SimpleVLA-RL | 68.8% |
SimpleVLA-RL vượt π₀ gần 20 điểm phần trăm trên RoboTwin 2.0. Đây là kết quả đáng chú ý vì π₀ là model flow-matching diffusion tiên tiến nhất hiện nay (từ Physical Intelligence), và RDT là Robotics Diffusion Transformer — cả hai đều là heavy-weight models.
Cải thiện +30.6% trên RoboTwin cho thấy RL càng hiệu quả khi baseline SFT càng yếu. Với LIBERO (SFT đã 90%+), room for improvement hẹp. Với RoboTwin (SFT chỉ 39%), RL có nhiều không gian để optimize.

Hiện tượng Pushcut: RL phát hiện chiến lược mới
Một trong những phát hiện thú vị nhất của paper là hiện tượng mà tác giả gọi là "pushcut" — khi RL tự phát hiện ra chiến lược hoàn thành task mà không có trong demonstrations.
Ví dụ: Task "Move Can to Pot"
- Chiến lược SFT (từ demos): Gắp can → nâng lên → di chuyển trên không → đặt vào pot. Đây là cách con người tự nhiên sẽ dạy robot.
- Chiến lược RL (tự phát hiện): Đẩy can trượt trên bàn về phía pot → đẩy vào pot. Không cần gắp, không cần nâng!
Tại sao RL chọn push thay vì grasp? Vì push đơn giản hơn — ít bước hơn, ít cơ hội thất bại hơn, và vẫn đạt được binary reward (+1 khi can ở trong pot). RL không care "đẹp" hay "giống người" — nó chỉ care thành công hay thất bại.
Ví dụ khác: "Place Object A to B"
Tương tự, thay vì pick-and-place truyền thống, RL học cách đẩy object từ A sang B khi khoảng cách ngắn và mặt bàn phẳng. Khi khoảng cách xa hoặc có chướng ngại vật, RL vẫn dùng grasp — nó không ngu, nó tối ưu.
Ý nghĩa của Pushcut
Pushcut cho thấy RL không chỉ "cải thiện" chiến lược có sẵn mà có thể phát minh chiến lược hoàn toàn mới. Đây là điều SFT/IL (Imitation Learning) không bao giờ làm được — vì SFT chỉ bắt chước, không sáng tạo.
Đối với nghiên cứu VLA models, pushcut đặt ra câu hỏi: liệu demonstrations có đang giới hạn khả năng robot? Nếu RL có thể phát hiện chiến lược tốt hơn, thì việc thu thập demonstrations "chuẩn" có thực sự cần thiết?
Ablation Studies: Mỗi thành phần đóng góp bao nhiêu?
Tác giả thực hiện ablation study kỹ lưỡng trên LIBERO Long (suite khó nhất) để đo lường đóng góp của từng thành phần:
Dynamic Sampling: +10%
Dynamic sampling là kỹ thuật ưu tiên sample nhiều hơn cho tasks khó. Thay vì chia đều rollouts cho mỗi task, SimpleVLA-RL dành nhiều rollouts hơn cho tasks có success rate thấp.
| Cấu hình | Success Rate |
|---|---|
| Uniform sampling | 89.1% |
| Dynamic sampling | 99.1% |
+10% là con số rất lớn. Dynamic sampling giúp RL tập trung compute vào nơi cần nhất, thay vì lãng phí rollouts vào tasks đã gần perfect.
Higher Clip Range: +5-7%
So sánh symmetric clip (PPO chuẩn) với asymmetric clip:
| Clip range | Success Rate |
|---|---|
| Symmetric (0.8, 1.2) | 92-94% |
| Asymmetric (0.2, 1.28) | 99.1% |
Asymmetric clip cho phép model mạnh dạn tăng probability cho actions tốt (clip trên = 1.28) nhưng hạn chế việc giảm probability cho actions "xấu" (clip dưới = 0.2 tức ratio >= 0.2). Điều này có lý: trong robotics, có nhiều cách thành công nhưng ít cách thất bại rõ ràng — ta muốn model khám phá nhiều chiến lược thành công hơn là trừng phạt thất bại.
Higher Temperature: +8-10%
| Temperature | Success Rate |
|---|---|
| 1.0 (mặc định) | 89-91% |
| 1.6 | 99.1% |
Temperature 1.6 nghe phi trực giác — thông thường ta muốn temperature thấp (0.7) cho output chính xác. Nhưng trong RL training, temperature cao = exploration cao = model thử nhiều strategies = GRPO có nhiều positive samples để học từ. Sau training, inference dùng temperature thấp hơn.
Tổng hợp ablation
Mỗi thành phần đóng góp đáng kể, và chúng cộng hưởng với nhau — dynamic sampling + high clip + high temperature cùng lúc cho kết quả tốt hơn nhiều so với từng thành phần riêng lẻ. Đây là lý do SimpleVLA-RL đạt 99%+ trong khi các phương pháp RL đơn giản hơn chỉ đạt 89-94%.
Generalization: Train 9, test 1
Để đánh giá khả năng generalize, tác giả thử train RL trên 9/10 tasks trong mỗi suite, rồi test trên task thứ 10 chưa từng thấy:
Kết quả: RL model vẫn cải thiện đáng kể trên unseen task, dù không được train trực tiếp. Điều này cho thấy RL không chỉ overfitting vào task cụ thể mà đang học general manipulation skills — grip tốt hơn, trajectory smooth hơn, recovery từ lỗi nhỏ tốt hơn.
Real-world: Sim-to-Real Transfer
SimpleVLA-RL không chỉ hoạt động trong simulation. Tác giả thử nghiệm trên Piper dual-arm robot trong thực tế:
| Task | SFT only | SFT + RL | Cải thiện |
|---|---|---|---|
| Stack Bowls | 38% | 70% | +32% |
| Click Bell | 30% | 60% | +30% |
| Trung bình | 17.5% | 38.5% | +120% |
Đặc biệt, RL được train hoàn toàn trong simulation — không dùng bất kỳ real-world demonstration nào cho RL stage. SFT dùng sim demos, RL train trong sim, rồi deploy thẳng lên real robot.
Mức cải thiện +120% (từ 17.5% lên 38.5%) cho thấy RL policy transfer tốt hơn sang real world so với SFT policy. Giả thuyết: RL tạo ra policy robust hơn vì nó đã thử hàng nghìn trajectories với noise và variation trong sim, trong khi SFT chỉ memorize trajectories từ demonstrations.
So sánh với các baselines
| Phương pháp | LIBERO Long | RoboTwin 2.0 |
|---|---|---|
| OpenVLA (SFT) | 91.0% | 38.3% |
| UniVLA | 87.3% | — |
| RDT | — | 33.3% |
| π₀ | — | 49.2% |
| SimpleVLA-RL | 99.1% | 68.8% |
SimpleVLA-RL vượt trội trên cả hai benchmarks, đặc biệt ấn tượng khi so với π₀ trên RoboTwin — model nhỏ hơn (7B vs 3B PaliGemma backbone trong π₀) nhưng hiệu quả hơn nhờ RL.
5 Bài học cốt lõi
1. Binary reward là đủ — không cần reward engineering
Đây có lẽ là bài học quan trọng nhất. Reward engineering (thiết kế hàm reward phức tạp) là bottleneck lớn nhất khi áp dụng RL vào robotics. SimpleVLA-RL chứng minh rằng chỉ cần +1 (thành công) / 0 (thất bại) là đủ.
Tại sao? Vì GRPO so sánh tương đối giữa các trajectories — nó không cần biết "thành công bao nhiêu phần trăm", chỉ cần biết "trajectory nào tốt hơn trajectory nào". Binary reward + group comparison = đủ signal cho learning.
Bài học ứng dụng: Khi thiết kế RL system cho task mới, đừng bắt đầu bằng thiết kế reward phức tạp. Thử binary reward trước — bạn có thể ngạc nhiên về kết quả.
2. RL phát minh chiến lược mới, vượt xa demonstrations
Pushcut không phải ngoại lệ — đó là tính chất cơ bản của RL. Khi được tự do khám phá, RL sẽ tìm ra chiến lược tối ưu cho objective function, bất kể chiến lược đó có "giống người" hay không.
Bài học ứng dụng: Đừng giới hạn robot bằng demonstrations. Dùng demonstrations để bootstrap (SFT), rồi để RL tự do khám phá. Chiến lược tốt nhất có thể là thứ bạn chưa bao giờ nghĩ tới.
3. Data efficiency: 1 demo + RL ≈ 500 demos
Đây là game-changer cho industry. Thu thập demonstrations tốn kém, đặc biệt cho tasks phức tạp trong manufacturing. Nếu chỉ cần 1 demo + RL training trong sim, chi phí deployment giảm drastically.
Bài học ứng dụng: Khi có task mới, thu thập vài demos nhanh nhất có thể (không cần hoàn hảo), train SFT nhanh, rồi dùng RL để nâng chất lượng. Đừng đợi đến khi có 500 demos "đẹp".
4. Minimum task competence: RL cần nền tảng
0 demos = 0% success sau RL. RL không phải phép màu — nó cần ít nhất một ít "may mắn thành công" để bắt đầu learning loop. Nếu model hoàn toàn không biết gì về task, RL sẽ quay vòng vô ích.
Bài học ứng dụng: Trước khi chạy RL, luôn kiểm tra SFT checkpoint có success rate > 0%. Nếu bằng 0%, thêm demos hoặc train SFT lâu hơn. Rule of thumb: SFT >= 10% success rate là đủ để RL bắt đầu hoạt động.
5. VLA + RL = Tương lai của robot learning
SimpleVLA-RL chứng minh rằng VLA models không bị giới hạn bởi imitation learning. Khi kết hợp VLA + RL:
- VLA cung cấp language understanding + visual grounding + action generation
- RL cung cấp optimization + exploration + adaptation
Đây là xu hướng lớn nhất trong embodied AI 2026: thay vì VLA vs RL, tương lai là VLA × RL.
Hướng phát triển tiếp theo
Flow-matching RL cho π₀ và π₀.5
SimpleVLA-RL dùng autoregressive VLA (OpenVLA). Nhưng thế hệ VLA mới như π₀ dùng flow-matching/diffusion — làm sao áp dụng RL cho chúng? Đây là open research question hấp dẫn nhất hiện tại.
Real-world RL (không qua sim)
Tất cả RL trong SimpleVLA-RL chạy trong simulation. Bước tiếp theo là RL trực tiếp trên real robot — nhưng cần giải quyết safety constraints (robot không được phá đồ trong quá trình exploration).
Multi-task RL
Hiện tại mỗi task cần RL training riêng. Multi-task RL — train 1 policy cho nhiều tasks cùng lúc — sẽ là bước tiếp theo để scaling.
Tổng kết series SimpleVLA-RL
Qua 4 bài viết, chúng ta đã đi từ motivation → kiến trúc → thực hành → phân tích kết quả. SimpleVLA-RL không phải là framework phức tạp nhất hay model lớn nhất — nhưng nó chứng minh một ý tưởng đơn giản và mạnh mẽ: RL với binary reward có thể biến một VLA model "khá" thành một robot manipulation expert.
Paper tham khảo: SimpleVLA-RL: Reinforcement Learning on VLA Models — Haozhan et al., ICLR 2026. GitHub: PRIME-RL/SimpleVLA-RL
Nếu bạn mới bắt đầu với RL cho robotics, hãy đọc bài đầu tiên về RL basics trong series AI cho Robot. Và nếu muốn hands-on ngay, LeRobot tutorial là cách nhanh nhất để bắt đầu thực hành robot learning.
Bài viết liên quan
- SimpleVLA-RL (1): Tổng quan — RL cho VLA Models — Giới thiệu motivation và ý tưởng chính
- Embodied AI 2026: Bức tranh toàn cảnh — Xu hướng AI cho robotics trong 2026
- Manipulation Series (4): VLA cho Robot Manipulation — VLA models trong bài toán manipulation