Why VLA Deployment Needs Runtime Monitoring
Vision-Language-Action models make robot manipulation feel much closer to a normal machine learning workflow. You collect demonstrations, train or fine-tune a policy, pass camera frames and a language instruction into the model, and receive robot actions as output. LeRobot, SmolVLA, OpenVLA, ACT, and Diffusion Policy all fit this pattern.
The difference is that a robot action is not a harmless text token. A bad output can exceed joint limits, push the gripper into the table, oscillate until the object leaves the workspace, or keep moving smoothly toward the wrong target. Our SmolVLA on LeRobot guide covers training; SafeContract adds the missing runtime layer between the model and the actuator: it monitors and constrains actions before the robot executes them.

The main technical source for this article is "How VLAs Fail Differently: Black-Box Action Monitoring Reveals Architecture-Specific Failure Signatures" by Krishnam Gupta. The paper was submitted to arXiv on May 27, 2026 and accepted to the ICRA 2026 Workshop "From Data to Decisions". It introduces SafeContract as a training-free, black-box action monitoring toolkit: no internal model access, no policy retraining, and no architecture-specific code path inside the neural network.
The core message is more subtle than "just add a velocity limit." In fact, the paper shows that velocity checking is the most common runtime safety mechanism but a poor predictor of task failure. SafeContract watches richer signals: direction reversal rate, jerk RMS, momentum coherence, spectral energy, stall detection, conformal p-values, and CUSUM shift alarms. The practical conclusion is clear: different VLA architecture families need different monitors.
The Paper's Core Idea: Action Space Reveals Failure
The paper asks a direct question: if we only observe the motor commands emitted by a VLA policy, can we predict which episodes will fail? To answer it, the author evaluates three representative policy architectures:
- VQ-BeT on PushT: a discrete-token policy using VQ-VAE plus Behavior Transformer.
- Diffusion Policy on PushT: a continuous denoising policy.
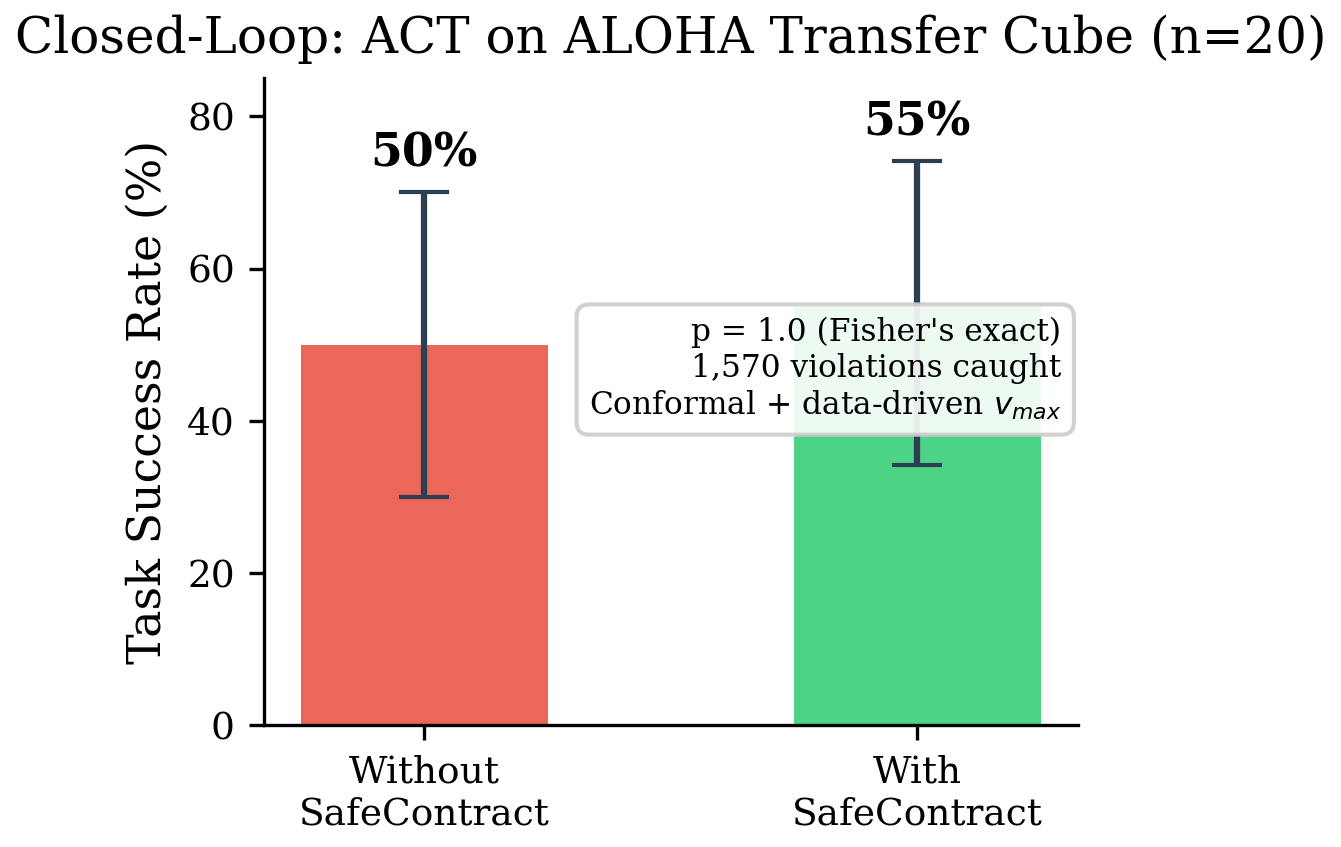
- ACT on ALOHA 14-DOF: an action-chunked bimanual manipulation policy.
The study reports 450 episodes. For PushT, VQ-BeT and Diffusion Policy are evaluated with identical seeds, action bounds [0, 512], velocity limit 30 px/step, and a success criterion of coverage >= 0.95. ACT is evaluated on a 14-DOF ALOHA setup.
SafeContract does not need to understand the scene, the prompt, or the object category. It sees an action sequence:
a_0, a_1, a_2, ..., a_t
From that stream, it asks practical deployment questions:
- Is this action outside the lower or upper bound for any joint?
- Is the delta between consecutive steps too large?
- Is the policy reversing direction repeatedly?
- Does the trajectory have large jerk spikes?
- Is the policy stalled, producing nearly zero movement for many steps?
- Does the new action stream look unlike the demonstration distribution?
For beginners, think of SafeContract as a combined flight recorder and guardrail for robot actions. It does not replace the VLA model. It does not solve semantic correctness. If the instruction is "pick up the red cube" and the model smoothly moves toward the blue cube, an action-space monitor may not detect that semantic error. But if the model produces jerky, oscillatory, out-of-range, or distribution-shifted actions, SafeContract can warn, clip, stop, and log the event.
SafeContract Architecture
SafeContract has three practical layers: contract enforcement, data-driven calibration, and runtime monitoring.
1. Contract Enforcement
A safety contract is a physical constraint on the action:
C = (lower_bounds, upper_bounds, velocity_limits)
When the policy returns an action, SafeContract:
- Clips the action to per-joint bounds.
- Clamps velocity, meaning
action_t - action_{t-1}. - Clips again, because velocity clamping can push an action back outside the original bounds.
- Logs violations by timestep, dimension, and magnitude.
The krishnam94/vla-edge repository exposes this through a safety_contract decorator that can wrap any predict() function:
from vla_edge.validate.contract import safety_contract
@safety_contract(
action_range=[-1.0, 1.0],
joint_velocity_max=0.1,
workspace_bounds=[[-0.5, 0.5], [-0.5, 0.5], [0.0, 0.8]],
on_violation="warn",
)
def predict(image, instruction, state=None):
return model(image, instruction, state)
For LeRobot, the right place is usually the policy-to-robot boundary, not inside the model itself. For SmolVLA, the policy usually returns continuous action chunks. For OpenVLA, the model predicts tokenized output actions that are decoded into continuous robot actions. In both cases, the contract should run after action decoding and before the robot controller receives the command.
2. Conformal Calibration
Hand-tuned thresholds are fragile. If vmax is too low, the monitor clips correct expert behavior and causes failures. If it is too high, the monitor becomes decorative. SafeContract uses split-conformal prediction to calibrate bounds from demonstration actions.
The calibration workflow is:
- Collect action streams from teleoperation demonstrations or successful policy rollouts.
- Split the data, for example 80% calibration and 20% holdout.
- Compute nonconformity scores that measure how far an action is from the calibration distribution.
- Select the quantile for a significance level such as
alpha=0.05. - Set velocity limits from action deltas, for example the 99th percentile of consecutive changes.
The paper reports that conformal bounds reached 97.9% holdout coverage while being 25% tighter than a 4σ heuristic. That is the useful deployment property: the bounds are wide enough not to break expert actions, but tight enough to reveal unusual behavior.
In code, the most convenient entry point is SafetyGuard.from_demos():
import numpy as np
from vla_edge.validate.guard import SafetyGuard
demo_actions = np.load("demo_actions.npy") # shape: (N, action_dim)
guard = SafetyGuard.from_demos(
demo_actions,
alpha=0.05,
v_max_percentile=99.0,
mode="warn",
)
raw_action = policy.select_action(observation)
safe_action = guard(raw_action)
report = guard.get_report()
3. Runtime Monitors
The paper computes five episode-level health metrics:
- Direction reversal rate: the fraction of
(timestep, joint)pairs where the action delta changes sign. High reversal means the policy is moving back and forth instead of progressing. - Jerk RMS: the root mean square of the third derivative of the action trajectory. High jerk often appears in discrete-token policies.
- Momentum coherence: cosine similarity between consecutive action deltas. Low coherence means the direction of motion is inconsistent.
- Spectral energy ratio: the share of signal energy in low frequencies. Smooth policies tend to have more stable spectra.
- Stall detection: repeated steps with very small displacement.
SafeContract also converts conformal p-values into a CUSUM detector for sequential shift detection. If many recent actions have p-values below alpha, CUSUM accumulates an alarm. This is better than an arbitrary moving average because it gives a more principled false-alarm behavior.
Results: No Single Monitor Works for Every VLA
The key result table is:
| Monitor | VQ-BeT PushT | Diffusion PushT | ACT ALOHA |
|---|---|---|---|
| Reversal rate AUROC | 0.93 | 0.79 | 0.91 |
| Jerk AUROC | 0.88 | 0.41 | 0.69 |
| Momentum coherence AUROC | 0.86 | 0.70 | 0.71 |
| Spectral energy AUROC | 0.75 | 0.34 | 0.74 |
| Velocity violations AUROC | 0.69 | 0.41 | 0.52 |
| Stall rate AUROC | 0.49 | 0.50 | 0.53 |
An AUROC near 0.5 is close to random guessing. The table gives three deployment lessons.
Direction reversal rate is the most consistent signal. It reaches 0.93 for VQ-BeT, 0.79 for Diffusion Policy, and 0.91 for ACT. When a policy fails, it often loses coherent progress and starts oscillating in action space.
Jerk is architecture-dependent. VQ-BeT reaches 0.88 AUROC for jerk, but Diffusion Policy drops to 0.41. This makes sense: discrete-token transitions can produce jerky motion, while continuous denoising can fail smoothly.
Velocity checking is not enough. Velocity violation AUROC is 0.41 for Diffusion Policy and 0.52 for ACT. That is the paper's most important negative result. Many deployment stacks watch velocity because it is simple, but velocity violation count is not a reliable task-failure predictor. Successful episodes may involve large confident motions; failed episodes may be smooth but wrong.
SafeContract enforcement also did not cause statistically significant degradation in the reported experiments:
- Diffusion Policy PushT: 58% without contract, 57% with contract, Fisher p=0.92.
- VQ-BeT PushT: 56.5% without contract, 54.5% with contract, Fisher p=0.76.
- ACT ALOHA: 62% without contract, 56% with contract, Fisher p=0.68.
The paper reports monitoring overhead of roughly under 13 microseconds per inference step, which is tiny compared with VLA inference latency.
Applying It to SmolVLA and OpenVLA on LeRobot

SmolVLA is Hugging Face's 450M VLA designed for LeRobot. The technical blog describes it as using SmolVLM2 as the VLM backbone and a flow-matching action expert to generate continuous action sequences. It consumes multi-camera RGB inputs, sensorimotor state, and a language instruction, then outputs an action chunk.
Because SmolVLA uses a flow-matching continuous action expert, it is closer to the paper's continuous family than to discrete-token policies. The paper did not directly evaluate SmolVLA, so this is an architecture-based recommendation rather than a measured claim. A sensible monitor profile is:
- Primary monitor: reversal rate.
- Secondary monitor: momentum coherence.
- Do not use jerk as the main failure signal.
- Still enforce bounds and velocity for hardware safety, but do not treat velocity violation count as the main failure metric.
OpenVLA is different. It is a 7B VLA trained from a Prismatic VLM with a SigLIP + DINOv2 fused visual encoder, a projector, and a Llama 2 7B backbone. It predicts tokenized output actions, which are decoded into continuous robot actions for execution.
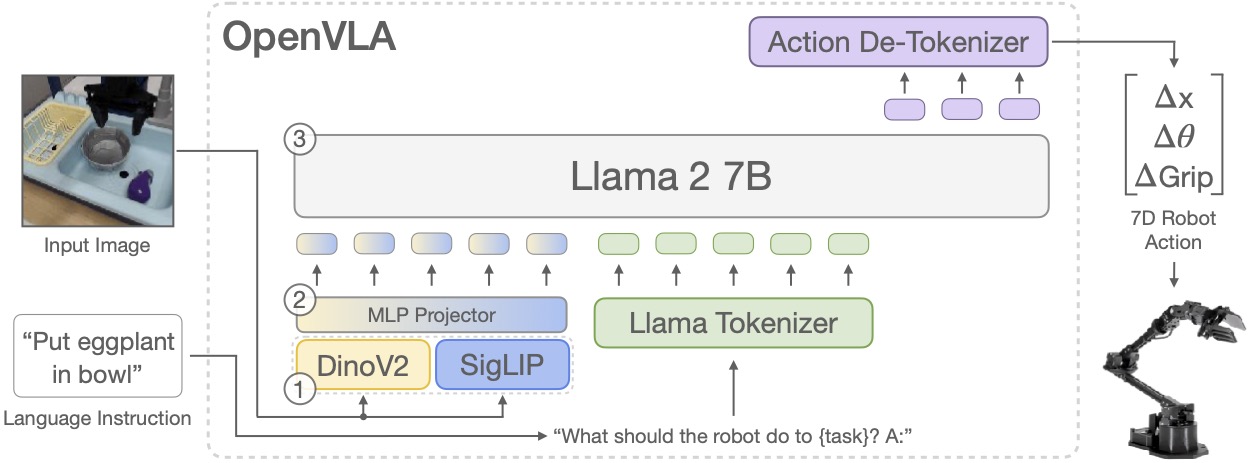
Because OpenVLA is autoregressive over action tokens, it is closer to the discrete-token family. The paper's practical recommendation maps to:
- Primary monitor: reversal rate + jerk RMS.
- Secondary monitor: momentum coherence or spectral energy.
- Use velocity limits as a hardware envelope, not as the only dashboard metric.
When deploying with the LeRobot framework, place SafeContract at the policy-to-robot boundary:
camera + state + instruction
-> LeRobot policy
-> raw action / action chunk
-> SafeContract / SafetyGuard
-> robot controller
-> logs + dashboard
Installation
The original toolkit is hosted at https://github.com/krishnam94/vla-edge. The README describes vla-edge as a package for profiling, optimizing, validating, and deploying VLA models on edge hardware. Basic installation:
pip install vla-edge
With SmolVLA support:
pip install "vla-edge[smolvla]"
With CUDA support:
pip install "vla-edge[cuda]"
With all extras:
pip install "vla-edge[all]"
The README lists Python >=3.10 and recommends Python 3.12 because of LeRobot 0.4.4 compatibility. In a real robotics project, pin your versions carefully: PyTorch, transformers, CUDA, camera drivers, serial drivers, and LeRobot can drift apart quickly.
To check hardware:
vla-edge check
To run a basic safety validation:
vla-edge validate smolvla --action-bound 1.0 --velocity-limit 0.1
For OpenVLA, the README lists the model as supported, while the roadmap also mentions continued OpenVLA adapter work. Treat that as a version check requirement: test a minimal inference path in your exact package version before connecting to hardware.
Training and Calibration Workflow
SafeContract does not train the policy. It calibrates a monitor. You still need a trained or fine-tuned VLA.
Step 1: Train or Fine-Tune the Policy
For SmolVLA on LeRobot:
lerobot-train \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=${HF_USER}/mydataset \
--batch_size=64 \
--steps=20000 \
--output_dir=outputs/train/my_smolvla \
--policy.device=cuda
The LeRobot SmolVLA docs say 20k fine-tuning steps can take a few hours on a single A100, but your runtime depends on GPU, batch size, number of cameras, and dataset size. For a small SO-101-style setup, begin with short tasks: pick, place, push, or gripper open/close.
For OpenVLA, LoRA fine-tuning is the usual practical path:
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
--vla_path "openvla/openvla-7b" \
--data_root_dir <PATH_TO_DATASETS> \
--dataset_name bridge_orig \
--run_root_dir <PATH_TO_LOGS> \
--adapter_tmp_dir <PATH_TO_ADAPTERS> \
--lora_rank 32 \
--batch_size 16 \
--grad_accumulation_steps 1 \
--learning_rate 5e-4
The OpenVLA README warns that batch size 16 can require around 72GB of GPU memory. On smaller GPUs, reduce batch size and increase gradient accumulation to keep an effective batch size that trains stably.
Step 2: Collect Calibration Actions
After the policy can run in simulation or a safe robot mode, save action streams from demonstrations or successful rollouts:
actions = []
for episode in dataset:
for step in episode:
actions.append(step["action"])
demo_actions = np.asarray(actions, dtype=np.float32)
np.save("demo_actions.npy", demo_actions)
If the policy outputs chunks shaped like (horizon, action_dim), flatten them into (N, action_dim) before calibration. Keep the action scale consistent. If training uses normalized actions in [-1, 1], calibrate and monitor in the same normalized space, or consistently post-denormalize before monitoring.
Step 3: Create the SafetyGuard
from vla_edge.validate.guard import SafetyGuard
guard = SafetyGuard.from_demos(
demo_actions,
alpha=0.05,
v_max_percentile=99.0,
mode="warn",
)
Start with mode="warn" or mode="monitor_only" in simulation, inspect the reports, then move to clipping. If the guard clips many expert actions, your calibration set is too narrow or your action representation is inconsistent.
Safe Inference on LeRobot
A LeRobot rollout loop usually reads camera/state, calls the policy, and sends actions to the robot. SafeContract adds one step:
observation = robot.get_observation()
raw_action = policy.select_action(observation)
safe_action = guard(raw_action)
robot.send_action(safe_action)
report = guard.get_report()
if report and report["cusum_alarm"]:
robot.stop()
For action chunks, you have two choices:
- Guard every action in the chunk before enqueueing it.
- Guard each action at execution time.
The second approach is usually better on real robots because velocity clamping should compare against the previously executed action, not merely the previous element inside a chunk that may be replaced by receding-horizon inference.
A real deployment should have three layers:
- Hard safety: emergency stop, firmware joint limits, driver-level limits, and collision constraints.
- Action contract: SafeContract clips, clamps, monitors, and logs actions immediately before the controller.
- Task monitor: perception or task-level checks for object state, grasp success, human presence, and semantic correctness.
SafeContract is the second layer. It does not replace E-stop, collision checking, or task success detection. Its value is that it covers a part of the VLA deployment stack that is often ignored: the gap between neural network output and motor command.
Practical Deployment Checklist
Before running on a real robot:
- Define the action convention: joint position, joint delta, Cartesian delta, or normalized action.
- Log raw action and safe action separately.
- Calibrate from successful demonstrations, and do not mix different robot embodiments unless the action space is identical.
- For SmolVLA and flow-matching policies, prioritize reversal rate and momentum coherence.
- For OpenVLA and tokenized-action policies, add jerk RMS to the dashboard.
- Do not use velocity violation count as your main failure signal.
- Run
monitor_onlyin simulation or dry-run mode before switching toclip. - If
clip_magnitudestays large for several steps, stop the episode and inspect the data/model instead of forcing execution.
Sources
- Paper: How VLAs Fail Differently: Black-Box Action Monitoring Reveals Architecture-Specific Failure Signatures
- OpenReview: ICRA 2026 Workshop submission
- Code: krishnam94/vla-edge
- SmolVLA: Hugging Face blog
- OpenVLA: project page