Vì sao VLA cần runtime monitoring?
Vision-Language-Action model đang làm robot manipulation dễ tiếp cận hơn: bạn đưa vào ảnh camera, trạng thái robot, instruction như "pick up the red cube", model trả ra action để robot chạy. Với LeRobot, SmolVLA, OpenVLA, ACT hoặc Diffusion Policy, workflow này ngày càng giống một ML pipeline bình thường: collect demonstrations, train hoặc fine-tune policy, rollout trên robot thật.
Nhưng robot khác chatbot ở một điểm rất cụ thể: output sai không chỉ là câu trả lời sai. Output sai có thể là joint command vượt giới hạn, end-effector lao vào table, gripper đóng quá sớm, hoặc policy cứ đảo chiều liên tục cho đến khi vật bị đẩy khỏi workspace. Bài SmolVLA trên LeRobot đã nói nhiều về training; còn SafeContract bổ sung lớp còn thiếu giữa model và actuator: một lớp giám sát action trước khi action được gửi xuống robot.

Nguồn chính của bài này là paper "How VLAs Fail Differently: Black-Box Action Monitoring Reveals Architecture-Specific Failure Signatures" của Krishnam Gupta, submitted lên arXiv ngày 27/05/2026 và được nhận tại ICRA 2026 Workshop "From Data to Decisions". Paper giới thiệu SafeContract như một toolkit training-free, black-box action monitoring: không cần sửa model, không cần access internal activations, không cần retrain policy. Nó đứng ở ngoài, nhìn action stream, hiệu chỉnh bounds từ demonstration data, log violation và chặn action khi cần.
Điểm quan trọng nhất của paper không phải "thêm velocity limit là xong". Ngược lại, kết quả cho thấy velocity checking thường là monitor phổ biến nhất nhưng lại dự đoán failure rất kém. SafeContract đo nhiều tín hiệu hơn: direction reversal rate, jerk RMS, momentum coherence, spectral energy, stall, conformal p-value và CUSUM shift. Kết luận thực tế: mỗi họ kiến trúc VLA cần monitor khác nhau.
Ý tưởng paper: action-space nói rất nhiều về failure
Paper đặt câu hỏi đơn giản: nếu chỉ nhìn vào motor command do policy sinh ra, ta có thể đoán episode nào sẽ fail không? Nhóm tác giả chạy ba kiến trúc policy trên cùng protocol hoặc benchmark tương đương:
- VQ-BeT trên PushT: policy dạng discrete-token, VQ-VAE + Behavior Transformer.
- Diffusion Policy trên PushT: policy continuous, sinh action bằng denoising.
- ACT trên ALOHA 14-DOF: action-chunked policy cho bimanual manipulation.
Tổng cộng paper báo cáo 450 episodes. Với PushT, họ chạy n=200 per condition cho Diffusion Policy và VQ-BeT, cùng seed, cùng action bounds [0, 512], cùng velocity limit 30 px/step, cùng success criterion coverage >= 0.95. Với ALOHA, họ chạy ACT trên action space 14-DOF.
Điểm hay là SafeContract không cố hiểu scene hay instruction. Nó chỉ nhận một chuỗi action:
a_0, a_1, a_2, ..., a_t
Mỗi action có thể là joint position, delta joint, Cartesian delta hoặc action vector đã normalize. Từ chuỗi đó, nó hỏi:
- Action có vượt lower/upper bound không?
- Delta giữa hai step có quá lớn không?
- Policy có đổi hướng liên tục không?
- Jerk, tức đạo hàm bậc ba của trajectory, có spike không?
- Action có đang stall, gần như không di chuyển, trong nhiều step không?
- Chuỗi action mới có lệch khỏi distribution của demonstrations không?
Với beginner, hãy hình dung SafeContract giống một "flight recorder + guardrail" cho robot action. Nó không thay thế model. Nó cũng không làm robot thông minh hơn về semantic. Nếu instruction là "pick up the red cube" nhưng model đi tới cube xanh một cách rất mượt, action-space monitor có thể không phát hiện sai semantic. Nhưng nếu model sinh action giật, đảo chiều, vượt range, hoặc khác hẳn demonstration distribution, SafeContract có tín hiệu để cảnh báo hoặc chặn.
Kiến trúc SafeContract
SafeContract có ba lớp chính: contract enforcement, data-driven calibration và runtime monitoring.
1. Contract enforcement
Contract là một bộ ràng buộc vật lý trên action:
C = (lower_bounds, upper_bounds, velocity_limits)
Khi model trả action, SafeContract:
- Clip action vào per-joint bounds.
- Clamp velocity, tức giới hạn
action_t - action_{t-1}. - Clip lại lần nữa, vì velocity clamping có thể đẩy action ra ngoài bounds.
- Log violation theo timestep, dimension và magnitude.
Repo krishnam94/vla-edge hiện cung cấp decorator safety_contract để bọc bất kỳ hàm predict() nào:
from vla_edge.validate.contract import safety_contract
@safety_contract(
action_range=[-1.0, 1.0],
joint_velocity_max=0.1,
workspace_bounds=[[-0.5, 0.5], [-0.5, 0.5], [0.0, 0.8]],
on_violation="warn",
)
def predict(image, instruction, state=None):
return model(image, instruction, state)
Với LeRobot, ý tưởng là bọc policy inference hoặc post-process action trước khi gọi robot controller. Với SmolVLA, action thường là continuous chunk. Với OpenVLA, model dự đoán tokenized actions rồi decode thành continuous output actions; contract nên đặt sau bước decode, trước khi gửi command xuống robot.
2. Conformal calibration
Hand-tuned threshold rất dễ sai. Nếu bạn đặt vmax quá thấp, robot sẽ clip cả expert action đúng, làm task fail. Nếu đặt quá cao, monitor không còn tác dụng. SafeContract dùng split-conformal prediction để học bounds từ demonstration actions.
Quy trình:
- Lấy action từ demonstrations đã thu bằng teleoperation hoặc expert policy.
- Split data, ví dụ 80% calibration và 20% holdout.
- Tính nonconformity score: action mới lệch khỏi mean/std của calibration set bao nhiêu.
- Chọn quantile theo mức
alpha, ví dụalpha=0.05cho coverage khoảng 95%. - Lấy velocity limits theo percentile của consecutive action deltas, ví dụ 99th percentile.
Paper báo cáo conformal bounds đạt 97.9% holdout coverage và vẫn chặt hơn 25% so với heuristic 4σ. Đây là điểm thực dụng: bounds đủ rộng để không phá expert behavior, nhưng đủ hẹp để phát hiện action bất thường.
Trong repo, entry point gọn nhất là SafetyGuard.from_demos():
import numpy as np
from vla_edge.validate.guard import SafetyGuard
demo_actions = np.load("demo_actions.npy") # shape: (N, action_dim)
guard = SafetyGuard.from_demos(
demo_actions,
alpha=0.05,
v_max_percentile=99.0,
mode="warn",
)
raw_action = policy.select_action(observation)
safe_action = guard(raw_action)
report = guard.get_report()
3. Runtime monitors
Paper đo năm health metrics theo episode:
- Direction reversal rate: tỉ lệ cặp
(timestep, joint)nơi action delta đổi dấu. Nếu robot cứ tiến-lùi-tiến-lùi, reversal tăng. - Jerk RMS: root-mean-square của đạo hàm bậc ba của action trajectory. Jerk cao thường tương ứng motion giật, đặc biệt ở policy dạng discrete-token.
- Momentum coherence: cosine similarity giữa hai consecutive action deltas. Coherence thấp nghĩa là hướng chuyển động thiếu nhất quán.
- Spectral energy ratio: năng lượng tín hiệu ở low frequency. Policy mượt thường có phổ ổn định hơn.
- Stall detection: nhiều step liên tiếp displacement rất nhỏ.
Ngoài ra, conformal p-values được đưa vào CUSUM detector để phát hiện distribution shift tuần tự. Nếu nhiều action liên tiếp có p-value thấp hơn alpha, CUSUM tích lũy alarm. Điểm này tốt hơn kiểu moving average tùy ý, vì nó gắn với false-alarm bound rõ ràng hơn.
Kết quả: không có monitor nào đúng cho mọi VLA
Kết quả cốt lõi của paper:
| Monitor | VQ-BeT PushT | Diffusion PushT | ACT ALOHA |
|---|---|---|---|
| Reversal rate AUROC | 0.93 | 0.79 | 0.91 |
| Jerk AUROC | 0.88 | 0.41 | 0.69 |
| Momentum coherence AUROC | 0.86 | 0.70 | 0.71 |
| Spectral energy AUROC | 0.75 | 0.34 | 0.74 |
| Velocity violations AUROC | 0.69 | 0.41 | 0.52 |
| Stall rate AUROC | 0.49 | 0.50 | 0.53 |
AUROC gần 0.5 nghĩa là gần random. Nhìn vào bảng, ta thấy:
Direction reversal rate là tín hiệu ổn định nhất. Nó đạt 0.93 với VQ-BeT, 0.79 với Diffusion và 0.91 với ACT. Khi policy fail, nó thường không tiến đều đến mục tiêu mà dao động, đổi hướng hoặc mất "ý định" ở action-space.
Jerk chỉ mạnh với discrete-token policy. VQ-BeT có jerk AUROC 0.88, nhưng Diffusion chỉ 0.41. Lý do hợp lý: discrete token transition dễ tạo motion giật; continuous denoising tạo trajectory mượt hơn, nên failure của nó không nhất thiết biểu hiện bằng jerk.
Velocity checking không đủ. Diffusion có velocity AUROC 0.41, ACT 0.52, VQ-BeT 0.69. Paper nhấn mạnh đây là negative result có giá trị: nhiều deployment code chỉ kiểm tra velocity, nhưng velocity violation count không dự đoán task failure tốt. Một episode thành công đôi khi có motion lớn và quyết đoán; một episode fail có thể rất mượt nhưng đi sai chỗ hoặc stall.
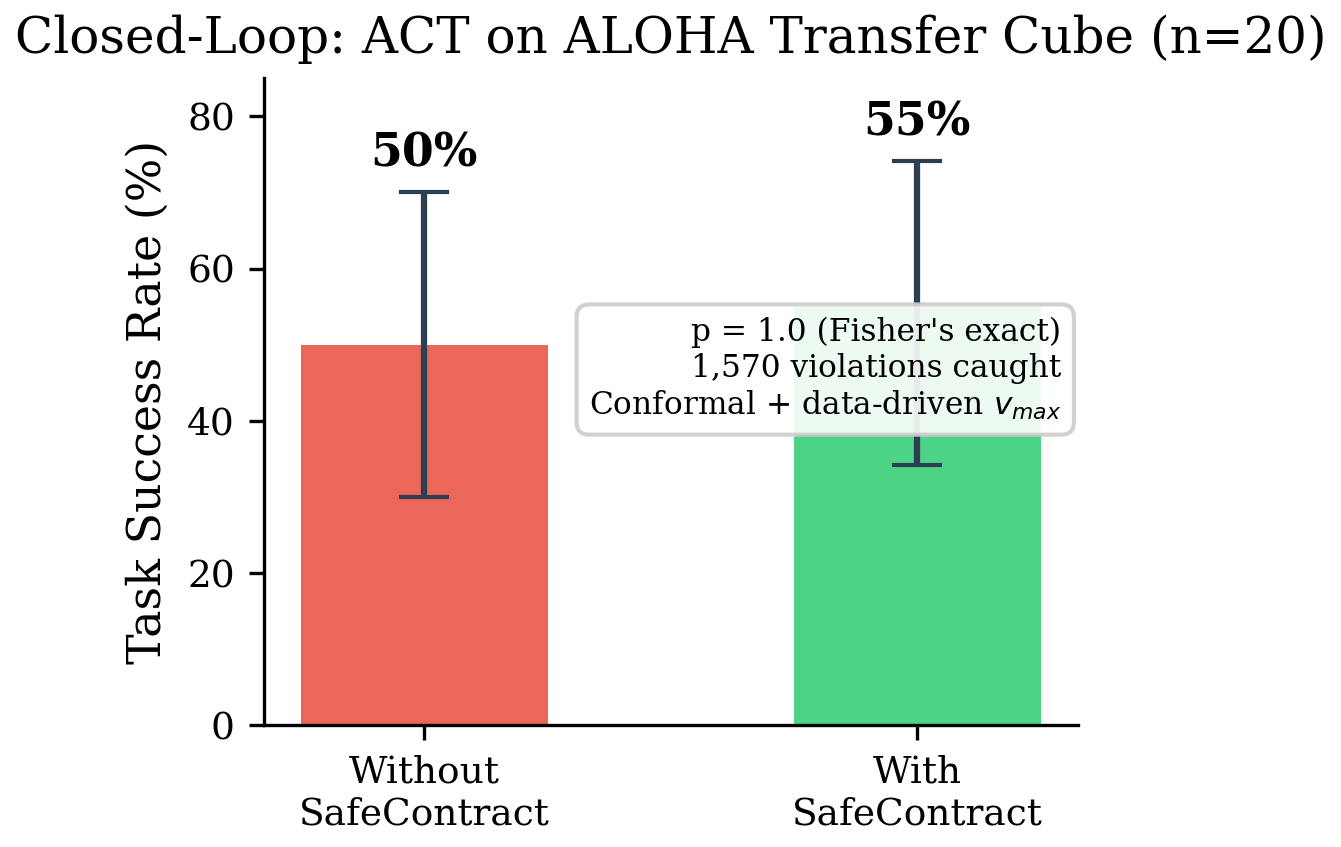
Về success rate, SafeContract enforcement không làm task degrade có ý nghĩa thống kê:
- Diffusion Policy PushT: không contract 58%, có contract 57%, Fisher p=0.92.
- VQ-BeT PushT: không contract 56.5%, có contract 54.5%, Fisher p=0.76.
- ACT ALOHA: không contract 62%, có contract 56%, Fisher p=0.68.
Nói cách khác, calibrated contract bắt được violation mà không phá behavior đúng ở mức có ý nghĩa thống kê trong các thí nghiệm này. Overhead được paper báo cáo khoảng <13 microseconds mỗi inference step, nhỏ hơn rất nhiều so với VLA inference.
Áp dụng cho SmolVLA và OpenVLA trên LeRobot

SmolVLA là VLA 450M của Hugging Face, được thiết kế cho LeRobot. Theo blog kỹ thuật của Hugging Face, SmolVLA dùng SmolVLM2 làm VLM backbone và flow-matching action expert để sinh continuous action sequence. Model nhận multi-camera RGB, sensorimotor state và language instruction, rồi sinh action chunk.
Với SafeContract, SmolVLA nên được xem gần họ continuous / flow-matching hơn là discrete-token. Paper chưa test trực tiếp SmolVLA, nên không nên nói chắc rằng kết quả Diffusion sẽ y hệt. Nhưng recommendation hợp lý là:
- Primary monitor: reversal rate.
- Secondary monitor: momentum coherence.
- Không dựa vào jerk làm tín hiệu chính.
- Vẫn enforce bounds/velocity để bảo vệ hardware, nhưng đừng dùng velocity count như failure predictor chính.
OpenVLA thì khác. OpenVLA là VLA 7B, fine-tune từ Prismatic VLM với SigLIP + DINOv2 visual encoder, projector và Llama 2 7B backbone. OpenVLA dự đoán tokenized output actions, sau đó decode thành continuous actions để robot execute.
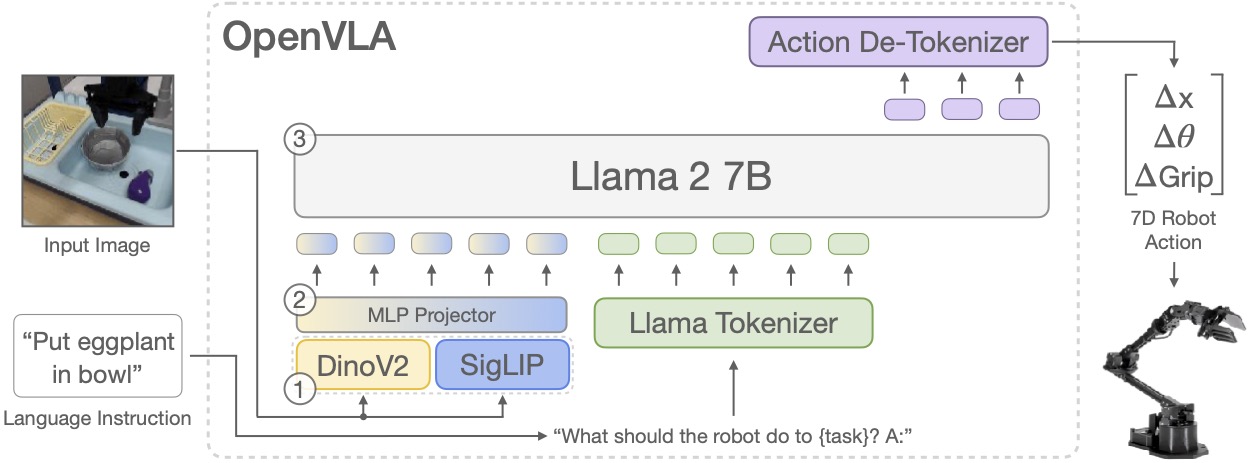
Vì OpenVLA thuộc nhóm autoregressive/tokenized action, paper đề xuất gần với discrete-token family hơn:
- Primary monitor: reversal rate + jerk RMS.
- Secondary monitor: momentum coherence hoặc spectral energy.
- Velocity limit vẫn cần cho safety envelope, nhưng không nên là dashboard metric duy nhất.
Khi triển khai với LeRobot framework, hãy đặt SafeContract ở lớp policy-to-robot, không đặt trong model. Pipeline nên là:
camera + state + instruction
-> LeRobot policy
-> raw action / action chunk
-> SafeContract / SafetyGuard
-> robot controller
-> logs + dashboard
Cài đặt
Repo gốc của toolkit là https://github.com/krishnam94/vla-edge. README mô tả vla-edge là package để profile, optimize, validate và deploy VLA trên edge hardware. Cài đặt cơ bản:
pip install vla-edge
Nếu dùng SmolVLA:
pip install "vla-edge[smolvla]"
Nếu chạy CUDA:
pip install "vla-edge[cuda]"
Và nếu muốn đầy đủ extras:
pip install "vla-edge[all]"
README ghi Python >=3.10, khuyến nghị Python 3.12 do tương thích LeRobot 0.4.4. Với LeRobot hiện đại, bạn vẫn nên pin version theo project thực tế, vì robotics stack hay lệch giữa PyTorch, transformers, CUDA và serial/camera dependencies.
Để kiểm tra hardware:
vla-edge check
Để validate action bounds ở mức CLI:
vla-edge validate smolvla --action-bound 1.0 --velocity-limit 0.1
Với OpenVLA, README liệt kê model trong nhóm supported, nhưng roadmap cũng nhắc OpenVLA adapter trong mốc tiếp theo. Vì vậy cách an toàn là kiểm tra version package bạn đang dùng, chạy unit test/minimal inference trước, rồi mới tích hợp real robot.
Training và calibration workflow
SafeContract không train model. Nhưng để monitor tốt, bạn vẫn cần calibration data. Beginner nên làm theo workflow này:
Bước 1: Train hoặc fine-tune policy
Với SmolVLA trên LeRobot:
lerobot-train \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=${HF_USER}/mydataset \
--batch_size=64 \
--steps=20000 \
--output_dir=outputs/train/my_smolvla \
--policy.device=cuda
Tài liệu SmolVLA của LeRobot nói 20k steps khoảng vài giờ trên một A100 cho fine-tune, nhưng con số thực tế phụ thuộc GPU, batch size, camera count và dataset size. Với robot nhỏ như SO-101, bạn nên bắt đầu bằng task ngắn: pick, place, push hoặc open/close gripper.
Với OpenVLA, fine-tuning phổ biến là LoRA:
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
--vla_path "openvla/openvla-7b" \
--data_root_dir <PATH_TO_DATASETS> \
--dataset_name bridge_orig \
--run_root_dir <PATH_TO_LOGS> \
--adapter_tmp_dir <PATH_TO_ADAPTERS> \
--lora_rank 32 \
--batch_size 16 \
--grad_accumulation_steps 1 \
--learning_rate 5e-4
OpenVLA README cảnh báo batch size 16 có thể cần khoảng 72GB GPU memory; nếu GPU nhỏ hơn, giảm batch size và tăng gradient accumulation.
Bước 2: Thu action calibration
Sau khi policy chạy được ở simulation hoặc robot thật trong mode an toàn, lưu action stream từ demonstrations hoặc successful rollouts:
actions = []
for episode in dataset:
for step in episode:
actions.append(step["action"])
demo_actions = np.asarray(actions, dtype=np.float32)
np.save("demo_actions.npy", demo_actions)
Nếu policy output action chunk shape (horizon, action_dim), flatten thành (N, action_dim) trước khi calibration. Quan trọng là action phải cùng scale với action khi inference: nếu training normalize action trong [-1, 1], monitor cũng calibrate trên action đã normalize hoặc post-denormalized nhất quán.
Bước 3: Tạo SafetyGuard
from vla_edge.validate.guard import SafetyGuard
guard = SafetyGuard.from_demos(
demo_actions,
alpha=0.05,
v_max_percentile=99.0,
mode="warn",
)
Với robot thật, bắt đầu bằng mode="warn" hoặc monitor_only trong simulation, đọc report, rồi mới chuyển sang clip. Nếu monitor clip quá nhiều expert actions, calibration data đang thiếu variation hoặc action representation chưa đúng.
Inference an toàn trên LeRobot
LeRobot rollout thường có vòng lặp: đọc camera/state, gọi policy, gửi action. Ta chỉ thêm một bước:
observation = robot.get_observation()
raw_action = policy.select_action(observation)
safe_action = guard(raw_action)
robot.send_action(safe_action)
report = guard.get_report()
if report and report["cusum_alarm"]:
robot.stop()
Với action chunk, bạn có hai lựa chọn:
- Guard từng action trong chunk trước khi enqueue vào controller.
- Guard action tại timestep execute, vì velocity clamp cần biết previous executed action.
Cách 2 thường đúng hơn cho real robot vì previous action thực sự là action đã gửi xuống actuator, không phải action thứ k-1 trong chunk chưa chắc được execute nếu receding horizon thay đổi.
Một policy deploy tốt nên có ba tầng:
- Hard safety: emergency stop, joint limit trong firmware/driver, workspace collision guard.
- Action contract: SafeContract clip/clamp/log action ngay trước controller.
- Task monitor: camera/perception kiểm tra object, goal, grasp success, human presence.
SafeContract chỉ là tầng thứ hai. Nó không thay thế E-stop, không thay thế collision checking, và không đảm bảo semantic correctness. Nhưng nó rất hữu ích vì nó bắt lỗi đúng nơi VLA thường bị bỏ qua: khoảng cách giữa neural network output và motor command.
Checklist triển khai thực tế
Trước khi chạy robot thật:
- Xác định action convention: joint position, joint delta, Cartesian delta hay normalized action.
- Log raw action và safe action riêng biệt.
- Calibrate bounds từ successful demos, không trộn nhiều robot embodiment nếu action space khác nhau.
- Với SmolVLA/flow-matching: ưu tiên reversal rate và momentum coherence.
- Với OpenVLA/tokenized action: thêm jerk RMS vào dashboard.
- Không dùng velocity violation count làm metric chính để kết luận policy fail.
- Chạy
monitor_onlytrong simulation hoặc dry-run trước khiclip. - Khi
clip_magnitudelớn liên tục, dừng episode và inspect data/model thay vì ép robot chạy tiếp.
Nguồn tham khảo
- Paper: How VLAs Fail Differently: Black-Box Action Monitoring Reveals Architecture-Specific Failure Signatures
- OpenReview: ICRA 2026 Workshop submission
- Code: krishnam94/vla-edge
- SmolVLA: Hugging Face blog
- OpenVLA: project page