If you've ever trained a VLA model with imitation learning and still watched your robot fail on unseen objects, you've hit the core limitation of behavioral cloning: no exploration. The model can only copy what it saw — it never learns how to try, fail, and adapt.
RLinf-Co addresses this directly by combining reinforcement learning in simulation with real-world data regularization, enabling VLA models like π₀.₅ and OpenVLA to break through the ceiling of imitation learning without needing hundreds of expensive real demonstrations.
Paper: Beyond Imitation: Reinforcement Learning–Based Sim–Real Co-Training for VLA Models — Liangzhi Shi et al., Tsinghua/HIT/PKU/CMU, 2026.
The problem: Why imitation learning isn't enough
Think of learning to swim by watching videos. You memorize the strokes, but the moment you're in the water — with real resistance, real buoyancy, real fatigue — everything is different. This is exactly the sim-to-real gap in robotics.
Imitation learning (Supervised Fine-Tuning / SFT) has three fundamental problems:
- Distribution shift: When the robot encounters a state not seen in training data, it has no recovery strategy.
- Compounding errors: Small mistakes accumulate over a trajectory and cause complete failure by the end.
- Data hunger: You need thousands of real demonstrations — expensive, slow, hard to scale.
Traditional sim-to-real approaches tried to compensate by generating massive simulation datasets, but still relied on supervised learning — meaning they were still "imitating," just from a simulator instead of a real robot.
RLinf-Co takes a different approach: use reinforcement learning inside a simulator so the robot genuinely learns from trial and error, while anchoring the policy to real-world data to prevent forgetting what it already knows.
Architecture: Two-stage learning
RLinf-Co is structured in two clearly defined stages:
Stage 1: SFT Co-Training (Warm-up)
Before RL, the policy needs a warm-up via supervised learning on a mixture of real and simulated data:
- Approximately 50 real-world trajectories (teleoperation with Franka arm)
- Approximately 1,000–1,500 simulation trajectories (generated by MimicGen from seed demonstrations)
- Mixing ratio α (typically 50 real : 1,499 sim) tuned per task
The purpose of this stage is to:
- Teach the policy the natural language of the task ("pick up the red cup and place it on the plate")
- Learn real-world visual features: actual lighting, colors, depth
- Provide a solid foundation so RL doesn't start from zero
Stage 2: Real-Regularized RL (Actual learning)
This is the heart of RLinf-Co. The policy is fine-tuned with PPO (Proximal Policy Optimization) inside the simulator, but with a critical constraint:
ℒ_Total = ℒ_RL + β · ℒ_SFT(θ; D_real)
ℒ_RL: reinforcement learning loss from simulator interactionℒ_SFT(θ; D_real): supervised loss computed on real data, used as a regularizerβ = 0.2: balancing weight between RL exploration and real-world anchoring
Why do we need β · ℒ_SFT? When RL runs in simulation, the policy gradually forgets what it learned from real data — the classic catastrophic forgetting problem. This regularization term acts like an anchor: allowing exploration in sim, but preventing the policy from drifting too far from the real-world distribution.
Two supported VLA architectures
RLinf-Co currently supports two major VLA architectures:
| Model | Architecture | Backbone | Action head |
|---|---|---|---|
| OpenVLA | Next-token prediction | LLaVA-based | Discrete tokenized actions |
| π₀.₅ | Flow matching | PaliGemma-based | Continuous flow-matching |
Both work with the same RLinf framework but require different configs. This guide focuses on π₀.₅, which achieves better results on complex manipulation tasks.
Results: Real numbers
The method was evaluated on 4 tabletop manipulation tasks with a Franka Panda arm:
| Task | OpenVLA (baseline) | OpenVLA (RLinf-Co) | π₀.₅ (baseline) | π₀.₅ (RLinf-Co) |
|---|---|---|---|---|
| Pick & Place | ~28% | +35.4% | ~57% | +9.4% |
| Push Cube | ~47% | +16.6% | ~48% | +18.4% |
| Open Drawer | ~29% | +35% | ~1% | +65% |
| Close Drawer | ~54% | +10% | ~61% | +5% |
| Average | 16.5% | 64.0% | 26.7% | 66.2% |
Key takeaway: For OpenVLA, RLinf-Co improves from 16.5% to 64.0% average success rate — nearly 4× improvement. For π₀.₅, from 26.7% to 66.2%.
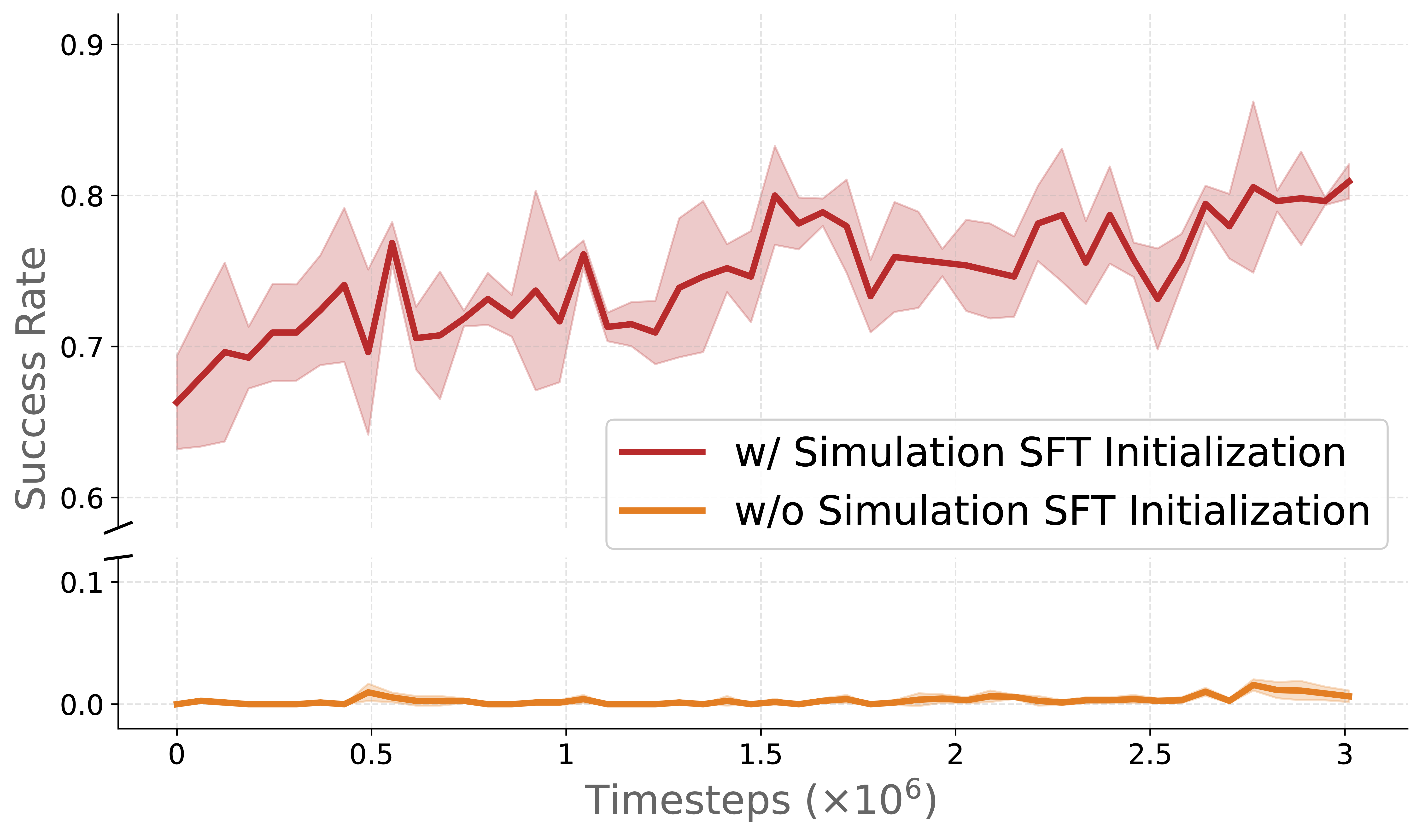
Generalization — the most impressive finding
When tested with unseen objects not present in training:
- RLinf-Co: only 25% performance drop
- Real-only SFT: 46.9% performance drop
RL co-training learns generalizable features rather than memorizing specific object appearances.
Data efficiency
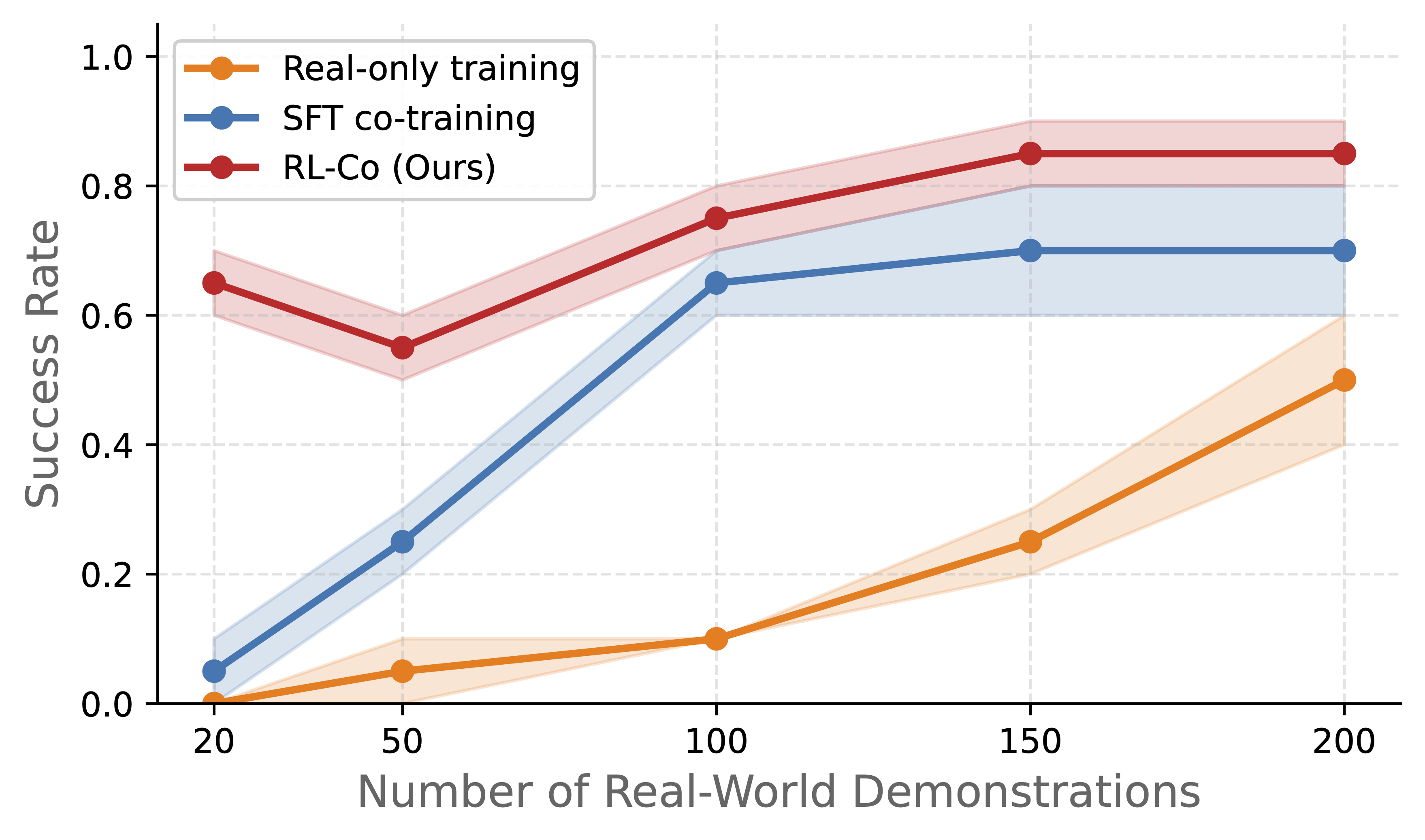
Especially when you have very few real trajectories (10–20), RLinf-Co substantially outperforms SFT baselines. With 50 real trajectories, RLinf-Co matches what SFT achieves with 200+ trajectories. This matters enormously in practice where collecting real robot data is expensive and slow.
Environment setup
RLinf requires a GPU (A100/H100 recommended, or at minimum an RTX 3090 for experiments), CUDA 12+, and either Docker or conda.
Option 1: Docker (Recommended)
# Pull the pre-built image with all dependencies
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.2-maniskill_libero
# Inside the container, switch to openpi environment
source switch_env openpi
The Docker image includes ManiSkill3, openpi (π₀.₅ framework), and all CUDA dependencies. This is the fastest way to get started.
Option 2: Manual installation
# Clone the repository
git clone https://github.com/RLinf/RLinf.git
cd RLinf
# Install for embodied RL with π₀.₅ and ManiSkill
bash requirements/install.sh embodied --model openpi --env maniskill_libero
source .venv/bin/activate
The install script creates a Python virtual environment and installs all dependencies including ManiSkill3, LeRobot, and openpi. Expect 15–20 minutes depending on your network speed.
Dataset preparation
Three types of assets are needed before training:
1. Download ManiSkill3 assets (simulator environment)
# Navigate to the ManiSkill assets directory
cd <path_to_RLinf>/rlinf/envs/maniskill/assets
# Download scene assets from HuggingFace
hf download --repo-type dataset RLinf/RLCo-maniskill-assets \
--include "custom_assets/*" \
--local-dir .
2. Download mixed dataset (real + simulation) for Stage 1
# Dataset contains 50 real + 1,499 sim trajectories in LeRobot format
hf download --repo-type dataset RLinf/RLCo-Example-Mix-Data \
--local-dir RLCo-Example-Mix-Data
This dataset is in LeRobot format (HDF5), containing RGB images, joint states, and language instructions.
3. Download SFT checkpoint (or train from scratch)
You can skip Stage 1 by using a pre-trained checkpoint:
# Download the pre-trained π₀.₅ SFT checkpoint
hf download RLinf/RLinf-Pi05-RLCo-PandaPutOnPlateInScene25DigitalTwin-V1-SFT \
--local-dir RLinf-Pi05-RLCo-PandaPutOnPlateInScene25DigitalTwin-V1-SFT
4. Download real-world data for Stage 2 regularization
# 50 real trajectories used as the RL regularizer
hf download --repo-type dataset RLinf/RLCo-Example-Real-Data \
--local-dir RLCo-Example-Real-Data
Training configuration
The YAML config for co-training has this structure:
# Rollout section: policy runs inside the simulator
rollout:
model:
model_path: /path/to/RLinf-Pi05-RLCo-PandaPutOnPlateInScene25DigitalTwin-V1-SFT
# Actor section: policy receives gradient updates
actor:
sft_data_path: /path/to/RLCo-Example-Real-Data
model:
model_path: /path/to/RLinf-Pi05-RLCo-PandaPutOnPlateInScene25DigitalTwin-V1-SFT
openpi:
config_name: "pi05_maniskill_sim_real_co_training"
# Enable co-training mode
enable_sft_co_train: True
sft_loss_weight: 0.2 # β in: ℒ_Total = ℒ_RL + β·ℒ_SFT
Key parameter explanations:
enable_sft_co_train: True— activates co-training mode, combining RL loss + SFT losssft_loss_weight: 0.2— this isβ. The value 0.2 was determined through ablation studies in the paper. Higher β → more stable but slower RL learning. Lower β → faster RL but risk of forgetting real-world features.config_name: "pi05_maniskill_sim_real_co_training"— preset config for π₀.₅ with ManiSkill3.
Running training
Once datasets and config are ready:
# Launch RL co-training
bash examples/embodiment/run_embodiment.sh maniskill_ppo_co_training_openpi_pi05
This starts the full PPO co-training pipeline: collector (rollout in sim), trainer (PPO + SFT loss updates), and evaluator (periodic evaluation in sim).
Monitor training with TensorBoard:
tensorboard --logdir ./logs --port 6006
Key metrics to watch:
env/success_rate: simulator success rate (rises from ~0 to ~70–80% after 100 steps)loss/rl_loss: PPO loss, should decrease graduallyloss/sft_loss: SFT regularization loss, should remain stable (no sudden spikes)reward/mean: average reward, should increase monotonically
End-to-end workflow for your own task
If you want to apply RLinf-Co to your own task (not just the example task), here's the complete workflow:
Step 1: Collect real data
Collect 20–50 real-world trajectories via teleoperation. With just 20 trajectories, RLinf-Co still works well (see the data efficiency chart). Data must be in LeRobot format.
Step 2: Build a digital twin in ManiSkill3
Create a scene in ManiSkill3 that roughly resembles your real environment. It doesn't need to be perfect — the paper shows that modest sim-real gaps are tolerable.
Step 3: Generate sim data with MimicGen
Use MimicGen to generate 1,000+ trajectories from a few seed demonstrations. MimicGen automatically randomizes object positions and creates diverse data.
Step 4: Stage 1 — SFT co-training
Train π₀.₅ or OpenVLA on the mixed real + sim dataset. Approximately 50k–100k steps depending on model size.
Step 5: Stage 2 — RL co-training
Fine-tune with PPO in sim + SFT regularization on real data. The paper shows that just ~100 RL steps yields significant improvement.
Step 6: Evaluate on real robot
Deploy the trained policy to a physical Franka arm. The framework supports Franka arms via ROS2.
Practical pitfalls to watch for
1. Domain gap between sim and real
ManiSkill3 renders fairly realistic images (ray tracing), but gaps in lighting and texture still exist. If the domain gap is too large, the β·ℒ_SFT regularization may not be strong enough to keep the policy grounded. Fix: increase real data volume or add domain randomization in the simulator.
2. β is the most sensitive hyperparameter
The paper ablates β ∈ {0.05, 0.1, 0.2, 0.5}. β=0.2 works best across the test tasks. For your own task, you may need to retune. If you see the policy "forgetting" real-world behavior (real robot performance declining), try increasing β to 0.3–0.5.
3. RL doesn't need many steps
One of the paper's most surprising findings: only ~100 RL steps are needed for meaningful improvement. Unlike RL from scratch (requiring millions of steps), co-training from an SFT checkpoint is extremely data-efficient because the policy already has strong priors.
4. Task reward design
PPO uses sparse reward (0/1 for success/fail). The paper uses binary reward: 1 if the object reaches target position within a threshold, 0 otherwise. No complex dense reward shaping needed.
Comparison with other approaches
| Approach | Real data needed | Sim needed | Uses RL? | Generalization |
|---|---|---|---|---|
| Real-only SFT | 200+ trajectories | No | No | Weak |
| SFT Co-training | 50 trajectories | Yes | No | Moderate |
| RLinf-Co | 20–50 trajectories | Yes | Yes | Strong |
| RL from scratch | None | Yes (many) | Yes | Strong but slow |
RLinf-Co occupies the "sweet spot": minimal real data, strong generalization, no need for millions of RL steps to converge.
Conclusion
RLinf-Co represents an important direction in VLA training: not just imitation, but genuine improvement. With an open-source framework, support for both OpenVLA and π₀.₅, and impressive results (+24% to +65% on manipulation tasks), this is worth experimenting with if you're doing robot manipulation research.
The key insight to remember: 2 stages + 1 formula. SFT co-training to warm up, then ℒ_RL + 0.2·ℒ_SFT to let RL learn without forgetting reality. Simple but effective.