Nếu bạn đã từng train một VLA model bằng imitation learning và thấy robot vẫn thất bại với các vật thể chưa gặp — bạn đang đối mặt với vấn đề cốt lõi của học bắt chước: không có khám phá. Mô hình chỉ copy những gì nó thấy, không học cách thử và sửa sai.
RLinf-Co giải quyết vấn đề này bằng cách kết hợp reinforcement learning trong simulator với dữ liệu thực, giúp VLA model như π₀.₅ và OpenVLA vượt qua giới hạn của imitation learning mà không cần hàng trăm demonstration thực tế đắt đỏ.
Paper gốc: Beyond Imitation: Reinforcement Learning–Based Sim–Real Co-Training for VLA Models — Liangzhi Shi et al., Tsinghua/HIT/PKU/CMU, 2026.
Vấn đề: Tại sao imitation learning không đủ?
Hãy tưởng tượng bạn học bơi bằng cách xem video. Bạn có thể nhớ được động tác, nhưng khi xuống nước thật — với sức cản nước thực, với trọng lực thực — mọi thứ khác hoàn toàn. Đây chính xác là khoảng cách sim-to-real trong robotics.
Imitation learning (hay Supervised Fine-Tuning - SFT) có 3 vấn đề lớn:
- Distribution shift: Khi robot thực hiện hành động không có trong training data, nó không biết cách phục hồi.
- Compounding errors: Mỗi lỗi nhỏ tích lũy theo thời gian, dẫn đến thất bại hoàn toàn ở cuối trajectory.
- Data hunger: Cần hàng nghìn demonstration thực tế (tốn kém, chậm, khó scale).
Các phương pháp sim-to-real truyền thống cố bù đắp bằng cách tạo thật nhiều dữ liệu simulation, nhưng vẫn dựa vào supervised learning — tức là vẫn "học bắt chước", chỉ là từ simulator thay vì robot thật.
RLinf-Co đề xuất một hướng khác: dùng reinforcement learning trong simulator để robot thực sự học từ thử-và-sai, đồng thời neo chặt policy vào dữ liệu thực để tránh "quên" những gì đã học.
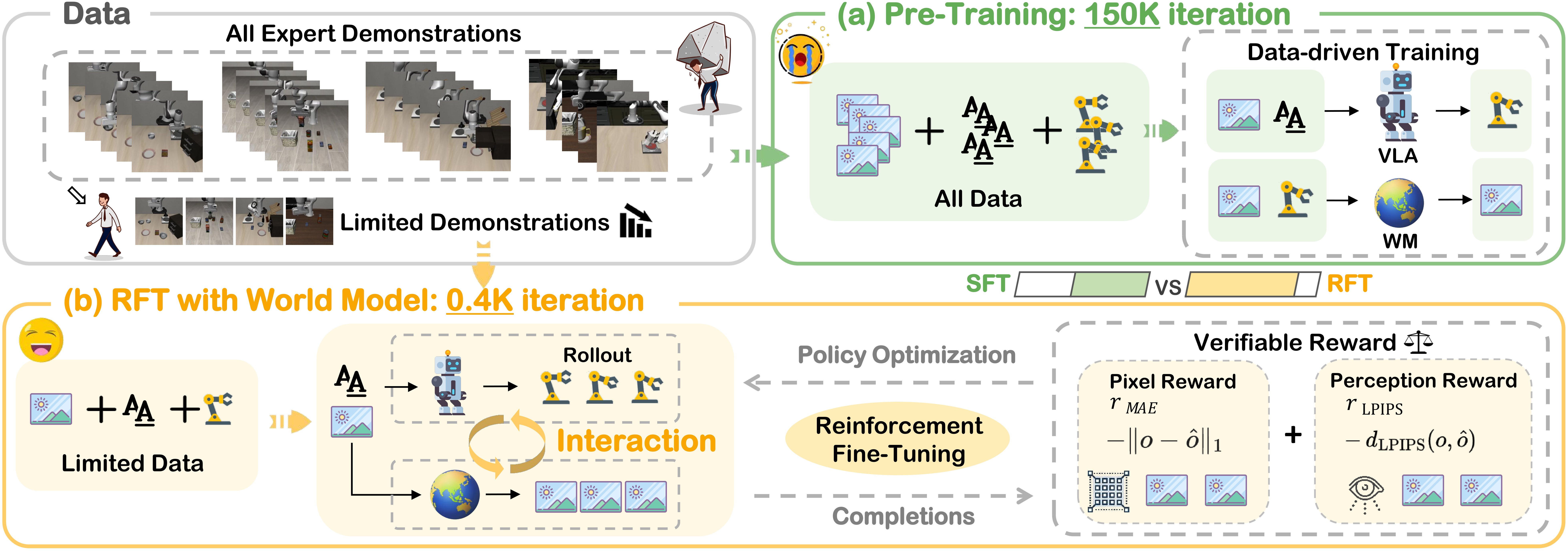
Kiến trúc: Hai giai đoạn học
RLinf-Co có cấu trúc hai giai đoạn rõ ràng:
Giai đoạn 1: SFT Co-Training (Khởi động)
Trước khi đưa robot vào môi trường RL, cần khởi động policy bằng supervised learning trên hỗn hợp dữ liệu thực + simulation:
- Khoảng 50 trajectories thực tế (teleoperation với Franka arm)
- Khoảng 1.000–1.500 trajectories simulation (tạo bằng MimicGen từ demonstration gốc)
- Tỷ lệ trộn α (thường 50 thực : 1,499 sim) được điều chỉnh theo task
Mục đích của giai đoạn này là:
- Policy học được ngôn ngữ tự nhiên của task ("pick up the red cup and place it on the plate")
- Policy hiểu visual features thực tế: ánh sáng thực, màu sắc thực, depth thực
- Chuẩn bị "mặt nền" để RL không bắt đầu từ zero
Giai đoạn 2: Real-Regularized RL (Học thực sự)
Đây là trái tim của RLinf-Co. Policy được fine-tune bằng PPO (Proximal Policy Optimization) trong simulator, nhưng với một hạn chế quan trọng:
ℒ_Total = ℒ_RL + β · ℒ_SFT(θ; D_real)
ℒ_RL: loss từ reinforcement learning trong simulatorℒ_SFT(θ; D_real): supervised loss tính trên dữ liệu thực, dùng như regularizerβ = 0.2: trọng số cân bằng giữa RL và neo giữ real-world knowledge
Tại sao cần β · ℒ_SFT? Khi RL chạy trong simulator, policy sẽ dần quên những gì học từ dữ liệu thực (hiện tượng catastrophic forgetting). Term regularization này giống như dây neo — cho phép policy khám phá trong sim nhưng không trôi quá xa khỏi real-world distribution.
Hai kiến trúc VLA được hỗ trợ
RLinf-Co hiện hỗ trợ hai VLA architectures chính:
| Model | Kiến trúc | Backbone | Action head |
|---|---|---|---|
| OpenVLA | Next-token prediction | LLaVA-based | Discrete tokenized actions |
| π₀.₅ | Flow matching | PaliGemma-based | Continuous flow-matching |
Cả hai đều chạy được với cùng framework RLinf, nhưng config khác nhau. Bài này tập trung vào π₀.₅ vì kết quả tốt hơn trên các task phức tạp.
Kết quả: Con số thực tế
Phương pháp được đánh giá trên 4 task tabletop manipulation với Franka Panda arm:
| Task | OpenVLA (baseline) | OpenVLA (RLinf-Co) | π₀.₅ (baseline) | π₀.₅ (RLinf-Co) |
|---|---|---|---|---|
| Pick & Place | ~28% | +35.4% | ~57% | +9.4% |
| Push Cube | ~47% | +16.6% | ~48% | +18.4% |
| Open Drawer | ~29% | +35% | ~1% | +65% |
| Close Drawer | ~54% | +10% | ~61% | +5% |
| Trung bình | 16.5% | 64.0% | 26.7% | 66.2% |
Điểm quan trọng: Với OpenVLA, RLinf-Co cải thiện từ 16.5% lên 64.0% average success rate — tức gấp gần 4 lần. Với π₀.₅, từ 26.7% lên 66.2%.
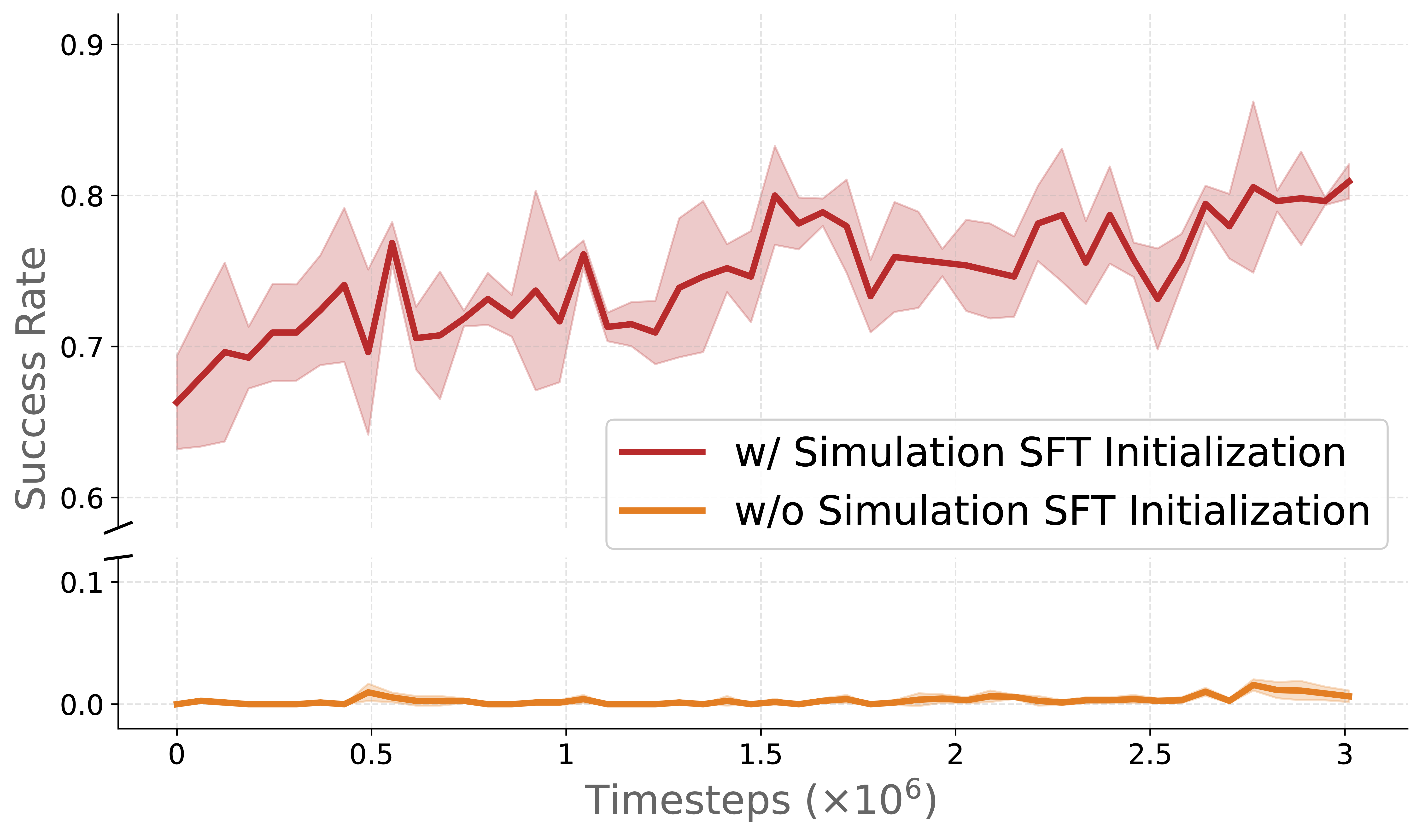
Generalization — điều ấn tượng nhất
Khi thử với vật thể chưa thấy trong training (unseen objects):
- RLinf-Co: chỉ giảm 25% performance
- Real-only SFT: giảm 46.9% performance
RL co-training học được generalizable features thay vì chỉ memorize specific objects.
Data efficiency
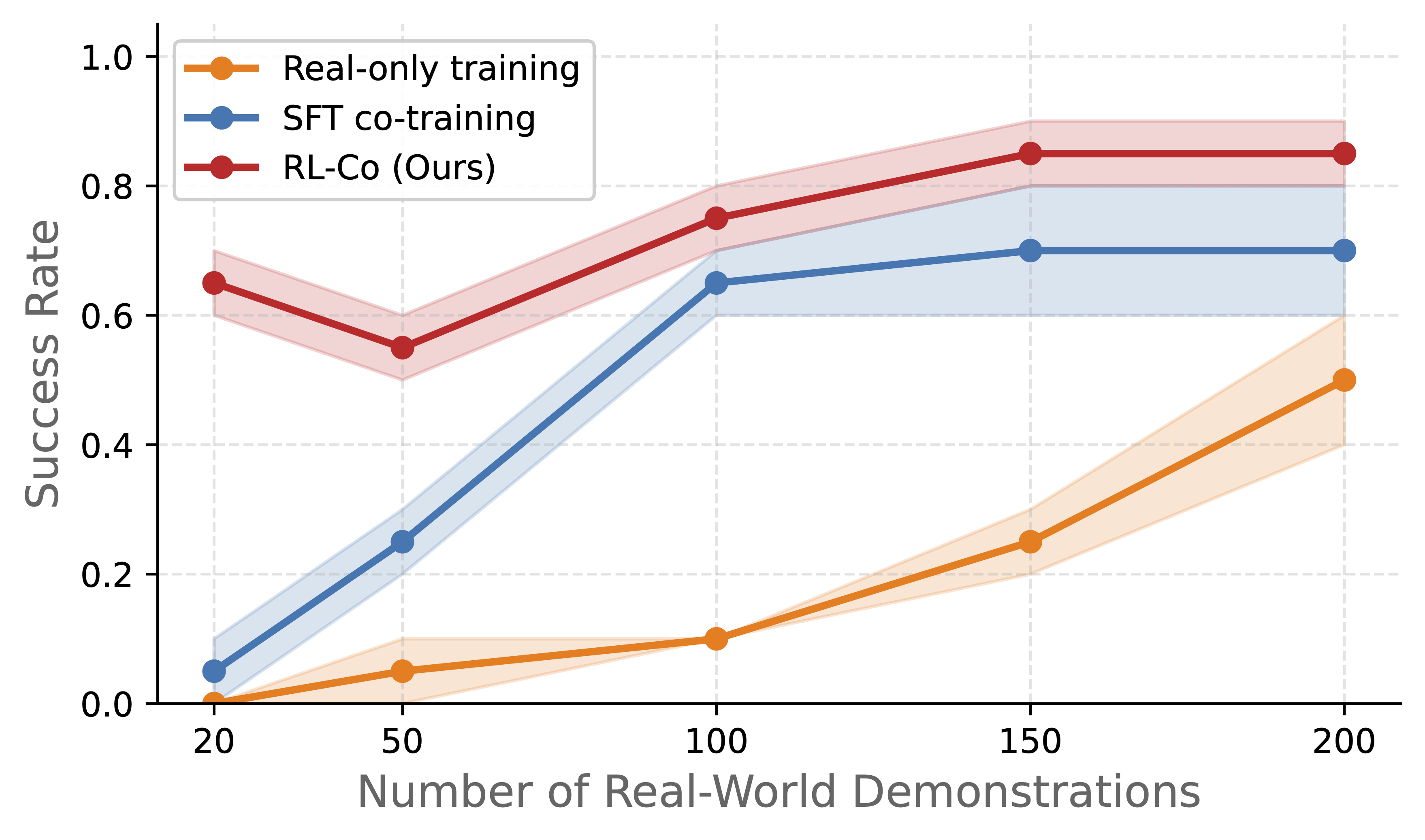
Đặc biệt khi bạn có ít dữ liệu thực (10-20 trajectories), RLinf-Co vượt xa SFT baseline. Với 50 trajectories, RLinf-Co đạt performance tương đương SFT với 200+ trajectories. Điều này cực kỳ có giá trị trong thực tế khi thu thập dữ liệu robot rất tốn kém.
Cài đặt môi trường
RLinf yêu cầu GPU (khuyến nghị A100/H100 hoặc ít nhất RTX 3090 để chạy thử), CUDA 12+, và Docker hoặc conda.
Cách 1: Docker (Khuyến nghị)
# Pull image có sẵn đầy đủ dependencies
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.2-maniskill_libero
# Khi vào container, switch sang openpi environment
source switch_env openpi
Docker image đã bao gồm ManiSkill3, openpi (π₀.₅ framework), và tất cả CUDA dependencies. Đây là cách nhanh nhất để bắt đầu.
Cách 2: Cài thủ công
# Clone repo
git clone https://github.com/RLinf/RLinf.git
cd RLinf
# Cài đặt cho embodied RL với π₀.₅ và ManiSkill
bash requirements/install.sh embodied --model openpi --env maniskill_libero
source .venv/bin/activate
Script cài đặt sẽ tạo virtual environment Python và cài tất cả dependencies bao gồm ManiSkill3, LeRobot, và openpi. Quá trình này mất khoảng 15-20 phút tùy tốc độ mạng.
Chuẩn bị dataset
Trước khi train, cần tải 3 loại asset:
1. Tải ManiSkill3 assets (simulator environment)
# Di chuyển vào thư mục assets của ManiSkill
cd <path_to_RLinf>/rlinf/envs/maniskill/assets
# Tải scene assets từ HuggingFace
hf download --repo-type dataset RLinf/RLCo-maniskill-assets \
--include "custom_assets/*" \
--local-dir .
2. Tải mixed dataset (thực + simulation) cho Stage 1
# Dataset chứa 50 real + 1,499 sim trajectories
hf download --repo-type dataset RLinf/RLCo-Example-Mix-Data \
--local-dir RLCo-Example-Mix-Data
Dataset này ở định dạng LeRobot format (HDF5), chứa cả RGB images, joint states, và ngôn ngữ instruction.
3. Tải SFT checkpoint (hoặc train từ đầu)
Có thể skip Stage 1 bằng cách dùng checkpoint đã train sẵn:
# Tải SFT checkpoint π₀.₅ đã được pre-train
hf download RLinf/RLinf-Pi05-RLCo-PandaPutOnPlateInScene25DigitalTwin-V1-SFT \
--local-dir RLinf-Pi05-RLCo-PandaPutOnPlateInScene25DigitalTwin-V1-SFT
4. Tải real-world data cho Stage 2 regularization
# 50 real trajectories dùng làm regularizer trong RL phase
hf download --repo-type dataset RLinf/RLCo-Example-Real-Data \
--local-dir RLCo-Example-Real-Data
Cấu hình training
File config YAML cho co-training stage có cấu trúc như sau:
# Phần rollout: policy chạy trong simulator
rollout:
model:
model_path: /path/to/RLinf-Pi05-RLCo-PandaPutOnPlateInScene25DigitalTwin-V1-SFT
# Phần actor: policy được update
actor:
sft_data_path: /path/to/RLCo-Example-Real-Data
model:
model_path: /path/to/RLinf-Pi05-RLCo-PandaPutOnPlateInScene25DigitalTwin-V1-SFT
openpi:
config_name: "pi05_maniskill_sim_real_co_training"
# Bật co-training mode
enable_sft_co_train: True
sft_loss_weight: 0.2 # β trong công thức ℒ_Total = ℒ_RL + β·ℒ_SFT
Giải thích tham số quan trọng:
enable_sft_co_train: True— bật chế độ co-training, tức là dùng cả RL loss + SFT losssft_loss_weight: 0.2— đây làβ. Giá trị 0.2 là default được tune qua ablation study trong paper. Tăng β → policy ổn định hơn nhưng học RL chậm hơn. Giảm β → policy học RL nhanh hơn nhưng có thể quên real-world features.config_name: "pi05_maniskill_sim_real_co_training"— preset config cho π₀.₅ với ManiSkill3 environment.
Chạy training
Sau khi chuẩn bị xong dataset và config:
# Chạy RL co-training với example script
bash examples/embodiment/run_embodiment.sh maniskill_ppo_co_training_openpi_pi05
Script này khởi chạy toàn bộ pipeline PPO co-training: collector (rollout trong sim), trainer (update policy với PPO + SFT loss), và evaluator (đánh giá định kỳ trong sim).
Theo dõi training với TensorBoard:
tensorboard --logdir ./logs --port 6006
Các metric cần theo dõi:
env/success_rate: success rate trong simulator (tăng dần từ ~0 đến ~70-80% sau 100 steps)loss/rl_loss: PPO loss, nên giảm dầnloss/sft_loss: SFT regularization loss, nên ổn định (không tăng đột biến)reward/mean: average reward, nên tăng monotonically
Quy trình từ đầu đến cuối
Nếu bạn muốn áp dụng RLinf-Co cho task của mình (không phải task example), đây là workflow đầy đủ:
Bước 1: Thu thập real data
Thu thập 20-50 trajectories thực tế qua teleoperation. Với 20 trajectories, RLinf-Co vẫn hoạt động tốt (xem data efficiency chart ở trên). Format dữ liệu phải là LeRobot format.
Bước 2: Xây dựng digital twin trong ManiSkill3
Tạo scene trong ManiSkill3 tương đối giống môi trường thực. Không cần perfect — paper cho thấy độ chênh lệch nhỏ giữa sim và real vẫn ổn.
Bước 3: Tạo sim data với MimicGen
Dùng MimicGen để generate 1.000+ trajectories từ một vài demonstration gốc. MimicGen tự động randomize vị trí object và tạo diverse data.
Bước 4: Stage 1 — SFT co-training
Train π₀.₅ hoặc OpenVLA trên hỗn hợp real + sim data. Khoảng 50k-100k steps tùy model.
Bước 5: Stage 2 — RL co-training
Fine-tune với PPO trong sim + SFT regularization trên real data. Paper cho thấy chỉ cần ~100 RL steps để thấy cải thiện đáng kể.
Bước 6: Eval trên robot thật
Deploy policy đã train lên Franka arm thực. Framework hỗ trợ Franka arm qua ROS2.
Những điều cần chú ý khi thực hành
1. Domain gap giữa sim và real
ManiSkill3 render ảnh khá thực tế (ray tracing), nhưng vẫn có gap về ánh sáng và texture. Nếu domain gap quá lớn, SFT regularization term β·ℒ_SFT sẽ không đủ mạnh để giữ policy. Giải pháp: tăng số lượng real data hoặc dùng domain randomization trong sim.
2. β là tham số nhạy cảm nhất
Paper thực hiện ablation study với β ∈ {0.05, 0.1, 0.2, 0.5}. β=0.2 cho kết quả tốt nhất trên các task test. Với task của bạn, có thể cần tune lại. Nếu thấy policy "quên" real-world (eval trên robot thật tệ đi), thử tăng β lên 0.3-0.5.
3. Số lượng RL steps không cần nhiều
Một trong những phát hiện đáng ngạc nhiên của paper: chỉ cần 100 RL steps để thấy cải thiện đáng kể. Khác với RL từ scratch (cần hàng triệu steps), co-training từ SFT checkpoint rất data-efficient vì policy đã có nền tảng tốt.
4. Task reward design
PPO cần sparse reward (0/1 cho success/fail). Paper dùng binary reward: 1 nếu object đến được target position trong threshold, 0 nếu không. Không cần dense reward phức tạp.
So sánh với các phương pháp khác
| Phương pháp | Real data cần | Sim cần | Có RL? | Generalization |
|---|---|---|---|---|
| Real-only SFT | 200+ traj | Không | Không | Yếu |
| SFT Co-training | 50 traj | Cần | Không | Trung bình |
| RLinf-Co | 20-50 traj | Cần | Có | Tốt |
| RL từ scratch | Không | Cần nhiều | Có | Tốt nhưng chậm |
RLinf-Co chiếm được vị trí "ngọt ngào" nhất: ít real data, có generalization tốt, và không cần hàng triệu RL steps để converge.
Kết luận
RLinf-Co đại diện cho một hướng đi quan trọng trong VLA training: không chỉ bắt chước, mà còn học cách cải thiện. Với framework open-source, support cho cả OpenVLA lẫn π₀.₅, và kết quả ấn tượng (+24% đến +65% trên các task), đây là công cụ đáng thử nghiệm cho bất kỳ ai đang làm robot manipulation.
Điểm mấu chốt để nhớ: 2 giai đoạn + 1 công thức. SFT co-training để khởi động, rồi ℒ_RL + 0.2·ℒ_SFT để RL học mà không quên thực tế. Đơn giản nhưng hiệu quả.