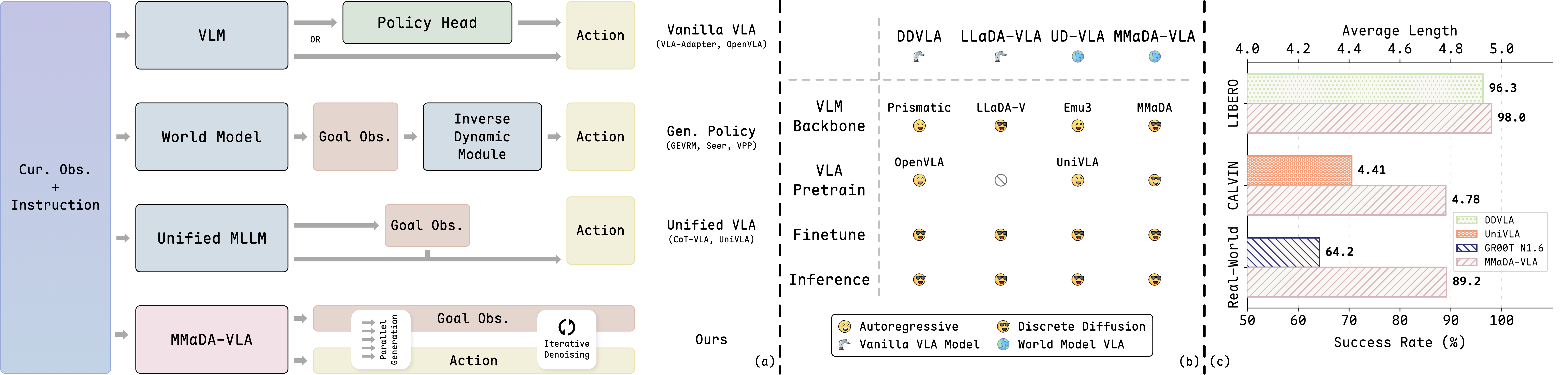
The Problem with Current VLAs
Over the past two years, the robotics community has witnessed an explosion of Vision-Language-Action (VLA) models — architectures that combine language understanding, image recognition, and robot action generation. From Google DeepMind's RT-2 to Spatial VLA, each generation of VLAs has brought significant progress. However, they all share a fundamental architectural limitation: the separation between understanding and action.
Previous-generation VLAs typically operate in a "pipeline" fashion — the language model processes text instructions and image inputs, then a separate "action head" (usually an MLP or diffusion head) is responsible for generating action sequences. This creates a semantic gap: the language understanding component and the action generation component live in two different representation spaces, communicating through a bottleneck.
The consequence? When robots need to execute long action sequences (long-horizon tasks), information loss through this bottleneck accumulates, leading to progressively larger errors. A robot might correctly understand "stack the red block on the blue block" but lose coherence between execution steps.
MMaDA-VLA (Multi-Modal Diffusion Action VLA) addresses this problem with a bold idea: merge everything — language, images, and robot actions — into a single discrete token space, then use discrete diffusion to generate them all in parallel.

Core Idea: Native Discrete Diffusion
Why "Native" Matters
Many prior models have used diffusion for robot actions — for example, Diffusion Policy operates in continuous space. MMaDA-VLA differs by using discrete diffusion — a denoising process on discrete tokens, similar to how language models work with text tokens.
What does this mean in practice? Instead of having two separate systems — an autoregressive system for language and a continuous diffusion system for actions — MMaDA-VLA uses a single mechanism for everything. Text tokens, image tokens (quantized from a visual encoder), and action tokens (discretized from the continuous action space) all live in the same vocabulary, processed by the same transformer backbone.
Masked Token Denoising
MMaDA-VLA's generation process works through masked token denoising — a variant of discrete diffusion:
- Start: All output tokens (including future goal images and action chunks) are fully masked — maximum noise state
- Iterate multiple steps: At each denoising step, the model simultaneously predicts all masked tokens, then unmasks a subset based on confidence scores
- Finish: After T steps (typically 10-20), all tokens are unmasked, producing complete output
The key insight is parallel generation — unlike autoregressive models that must generate tokens one at a time from left to right, discrete diffusion generates all tokens simultaneously and refines them gradually. This provides two advantages:
- Speed: Parallel generation is significantly faster than autoregressive approaches
- Global coherence: Each token is refined based on the context of ALL other tokens (both unmasked and still masked), rather than only seeing preceding tokens
Simultaneous Goal Image and Action Generation
One of MMaDA-VLA's most important innovations is its ability to simultaneously generate future goal observations and action chunks. When receiving the instruction "stack the red block on the blue block," the model doesn't just generate an action sequence — it also generates a predicted image of the future state, what the robot will see after completing the task.
Why is this useful? Because it creates a natural self-consistency check. If the model generates actions that place the red block to the right but the goal image shows the red block on top of the blue block, the denoising process will self-correct in subsequent steps — since both action tokens and image tokens influence each other within the same denoising process.
Architecture Overview
MMaDA-VLA is built on the MMaDA (Multi-Modal Diffusion Architecture) with the following key components:
1. Unified Tokenizer
- Text: Standard tokenizer (similar to LLaMA/GPT)
- Vision: Visual encoder (SigLIP or equivalent) + vector quantization to convert images into discrete tokens
- Actions: Binning discretization — dividing the continuous action space into discrete bins, each corresponding to a token
All share the same vocabulary, allowing the model to process them uniformly.
2. Single Transformer Backbone
A single transformer (based on a LLaMA-like architecture) receives all input tokens and generates all output tokens. There is no separate "action head," no dedicated vision decoder. Everything flows through the same network.
3. Iterative Denoising Loop
The inference process runs T denoising steps, each consisting of:
- Forward pass through the transformer
- Predict probability distribution for each masked token
- Unmask top-k tokens with highest confidence
- Repeat until all tokens are decoded

Pre-training on Open-X Embodiment
MMaDA-VLA is pre-trained on Open-X Embodiment — a massive dataset aggregating data from dozens of robotics labs worldwide, encompassing diverse robot types (robot arms, mobile manipulators, humanoids) with millions of trajectories.
The pre-training process uses an extended masked language modeling objective across all three modalities:
- Randomly mask a portion of text, image, and action tokens
- Require the model to predict the masked tokens
- Combined cross-entropy loss across all three token types
This is the most resource-intensive phase, utilizing an 8-node cluster with 8 GPUs per node using DeepSpeed ZeRO Stage-2 for memory optimization. This process helps the model learn shared representations across language, vision, and actions.
Fine-tuning on CALVIN and LIBERO
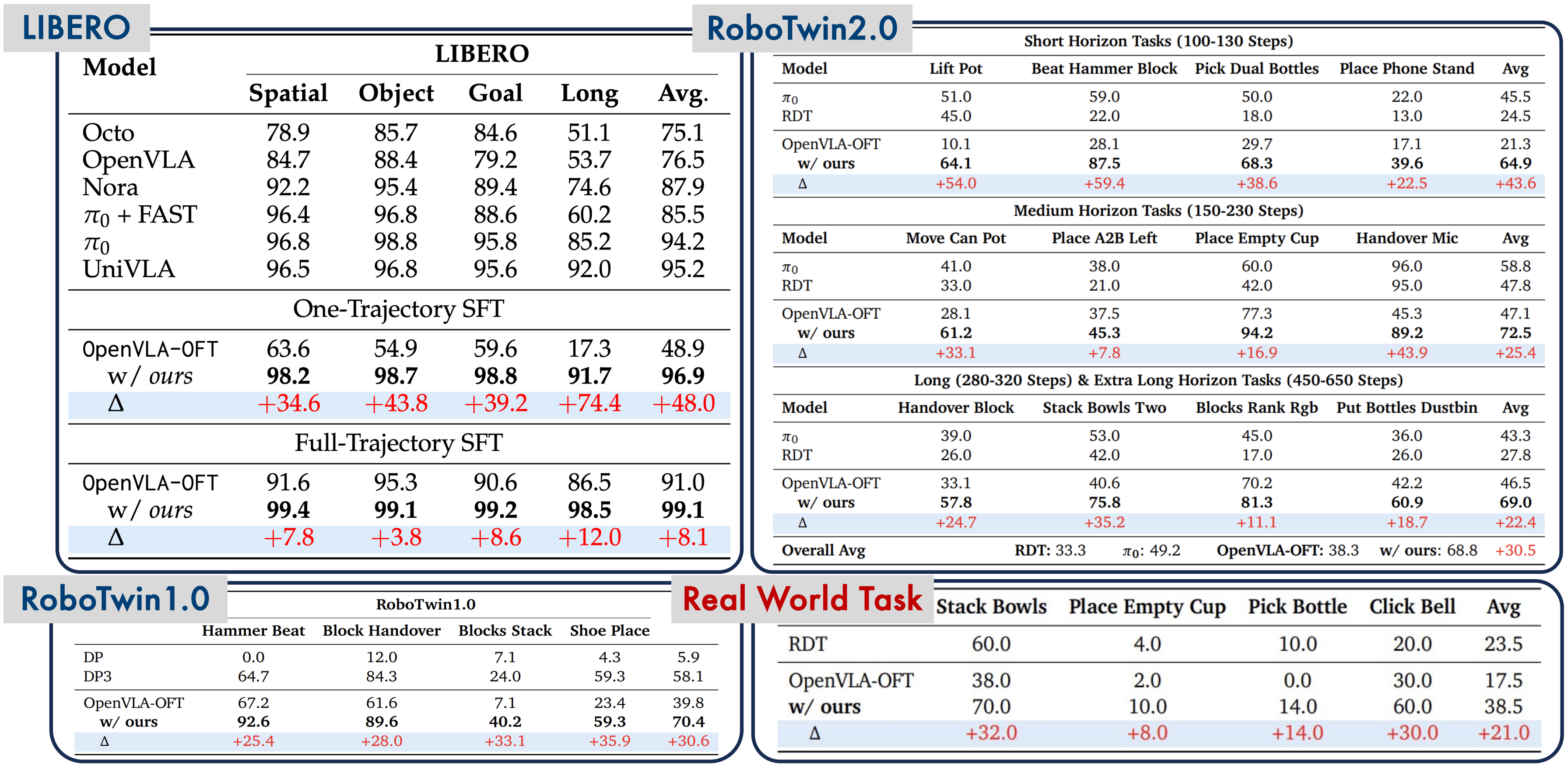
After pre-training, MMaDA-VLA is fine-tuned on two popular benchmarks:
CALVIN
CALVIN is a benchmark evaluating the ability to perform long chains of manipulation tasks following natural language instructions. The robot must complete 5 consecutive tasks without resetting — for example: "open the drawer," "place the block in the drawer," "close the drawer," "turn on the light," "rotate the lever."
LIBERO
LIBERO consists of multiple sub-suites (LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, LIBERO-Long) evaluating model generalization across different dimensions: spatial reasoning, object recognition, goal understanding, and long-horizon planning.
Fine-tuning requires only a single node with 8 GPUs, significantly less than pre-training.
Results and Comparison
MMaDA-VLA achieves impressive results on both benchmarks:
- CALVIN: Significant improvement in the completion rate for 5-task chains compared to VLA baselines. Notably, success rates for tasks 4 and 5 (where long-horizon consistency matters most) show the most improvement
- LIBERO: Achieves state-of-the-art on LIBERO-Long, demonstrating the ability to handle long tasks without losing coherence
A key finding is that iterative refinement genuinely helps — as the number of denoising steps increases, action quality improves, especially for complex tasks. This confirms the hypothesis that discrete diffusion allows the model to "reconsider" its decisions through multiple denoising steps, similar to how humans deliberate before acting.
Compared to VLA methods using separate action heads (such as RT-2 with token binning or Octo with a diffusion head), MMaDA-VLA shows clear advantages in scenarios requiring long-term consistency.
Installation and Usage Guide
MMaDA-VLA is released as open source under the MIT license at github.com/yliu-cs/MMaDA-VLA. Below is a step-by-step guide.
Environment Setup
# Clone repository
git clone https://github.com/yliu-cs/MMaDA-VLA.git
cd MMaDA-VLA
# Create conda environment
conda create -n mmada-vla python=3.11 -y
conda activate mmada-vla
# Install dependencies
pip install -r requirements.txt
Download Pre-trained Checkpoints
Checkpoints are published on HuggingFace:
# Install huggingface-cli if not already available
pip install huggingface_hub
# Download checkpoint (check the GitHub README for the exact model name)
huggingface-cli download yliu-cs/MMaDA-VLA --local-dir ./checkpoints
Data Preprocessing
For the CALVIN benchmark:
# Download CALVIN dataset
# See https://github.com/mees/calvin for detailed instructions
# Preprocess data for MMaDA-VLA format
python preprocess/calvin_preprocess.py \
--data_dir /path/to/calvin/dataset \
--output_dir /path/to/processed/data
For the LIBERO benchmark:
# Download LIBERO dataset
python preprocess/libero_preprocess.py \
--data_dir /path/to/libero/dataset \
--output_dir /path/to/processed/data
Training
Pre-training (requires multi-node cluster):
# Pre-training on Open-X Embodiment
# Uses DeepSpeed ZeRO Stage-2
# 8 nodes x 8 GPUs = 64 GPUs
deepspeed --num_nodes 8 --num_gpus 8 \
train.py \
--config configs/pretrain.yaml \
--deepspeed configs/ds_zero2.json \
--data_dir /path/to/openx/data \
--output_dir /path/to/pretrain/output
Fine-tuning (single node):
# Fine-tuning on CALVIN
deepspeed --num_gpus 8 \
train.py \
--config configs/finetune_calvin.yaml \
--deepspeed configs/ds_zero2.json \
--pretrained_model /path/to/pretrain/checkpoint \
--data_dir /path/to/calvin/processed \
--output_dir /path/to/finetune/output
# Fine-tuning on LIBERO
deepspeed --num_gpus 8 \
train.py \
--config configs/finetune_libero.yaml \
--deepspeed configs/ds_zero2.json \
--pretrained_model /path/to/pretrain/checkpoint \
--data_dir /path/to/libero/processed \
--output_dir /path/to/finetune/output
Evaluation
MMaDA-VLA uses a Flask server for benchmark evaluation:
# Start evaluation server
python eval_server.py \
--model_path /path/to/finetuned/checkpoint \
--port 5000
# Run CALVIN evaluation (in another terminal)
python eval/calvin_eval.py \
--server_url http://localhost:5000 \
--eval_episodes 1000
# Run LIBERO evaluation
python eval/libero_eval.py \
--server_url http://localhost:5000 \
--suite libero_long \
--eval_episodes 500

Why MMaDA-VLA Matters
1. A Step Toward Truly Unified Models
MMaDA-VLA is one of the first efforts to build a VLA where every modality is a first-class citizen within the same representation space. There is no "action head" bolted on — actions are generated by the same process that generates text and images. This is an important step toward genuinely versatile foundation models for robotics.
2. Iterative Refinement Enables "Thinking"
Discrete diffusion allows the model to "reconsider" its decisions through multiple denoising steps. This is analogous to "chain-of-thought" reasoning in LLMs, but applied to physical actions. The robot doesn't need to commit to an action from the first prediction — it can refine gradually.
3. Goal Image Generation as Implicit Planning
Generating future goal images in parallel with actions creates a form of implicit planning — the model must visualize the outcome before acting. This is a step in the right direction for robots to develop the ability to "imagine" the future, similar to how humans plan.
4. Open Source, MIT License
The complete code, pre-trained checkpoints, and training pipeline are all publicly available. This allows the community to quickly reproduce, extend, and build upon this foundation.
Limitations and Future Directions
However, MMaDA-VLA also has limitations worth noting:
- Computational requirements: Pre-training requires 64 GPUs — beyond the reach of most smaller labs. Fine-tuning is more feasible with 8 GPUs but still demands significant hardware
- Discrete tokens vs continuous actions: Discretizing actions into tokens inevitably loses some precision. For tasks requiring extremely precise control (sub-millimeter), this could be a bottleneck
- Inference speed: Multiple denoising steps mean inference is slower than feedforward action heads. In real-time robotics (100Hz+ control loops), this can be challenging
- No real robot experiments yet: Current results are primarily on simulation benchmarks. The sim-to-real gap remains an open question
Conclusion
MMaDA-VLA represents an exciting direction in VLA research: instead of bolting specialized components together, design a unified system from the ground up. Discrete diffusion is the tool that makes this possible — converting everything into tokens and letting a single denoising process handle them all.
While still far from achieving "AGI for robots," MMaDA-VLA is an important step along that path. With open-source code and readily available checkpoints, this is a great time for researchers and engineers to start experimenting with this approach.
Paper: MMaDA-VLA: Multi-Modal Diffusion Action VLA — Liu, Yang et al., 2026
GitHub: yliu-cs/MMaDA-VLA (MIT License)
Related Posts
- Diffusion Policy — When Diffusion Models Control Robots — Foundation of diffusion models in robotics, a prerequisite for understanding MMaDA-VLA
- VLA Models — From RT-2 to OpenVLA — Overview of VLA generations before MMaDA-VLA
- Manipulation Series: VLA for Manipulation — Applying VLA to practical manipulation problems