VLA: Jump from Task-Specific to General-Purpose
In Part 2 and Part 3, I covered ACT and Diffusion Policy — methods that train one policy per task. Want a new task? Collect new data, retrain from scratch.
Vision-Language-Action (VLA) models change this paradigm: train one model on data from many robots and tasks, then fine-tune or zero-shot for specific tasks. Like GPT-4 understanding many languages, VLA models understand many robot tasks.
This post analyzes 3 most important VLA models: RT-2 (Google DeepMind), Octo (UC Berkeley), and pi0 (Physical Intelligence) — with practical perspective on when to use, when not to.
See VLA Models deep dive for detailed theory.

RT-2: Vision-Language-Action from Google DeepMind
Idea
RT-2 (Brohan et al., 2023) is the first VLA model proving web-scale knowledge transfers to robot control. Simple but powerful idea: take a Vision-Language Model (VLM) pre-trained on billions of internet images + text, then co-fine-tune with robot trajectory data.
Architecture
Input:
- Image: camera observation -> Vision encoder (ViT)
- Language: task instruction "Pick up the red cup"
- History: previous observations + actions
VLM backbone: PaLM-E (12B) or PaLI-X (55B)
Output:
- Action tokens: generated like text tokens
- Decode: token -> [dx, dy, dz, droll, dpitch, dyaw, gripper]
Special point: RT-2 doesn't change VLM architecture. It just adds robot action tokens to vocabulary and co-fine-tunes. VLM still understands language and images normally, but now outputs robot actions.
Emergent Capabilities
Most impressive aspect of RT-2: emergent capabilities — abilities never explicitly trained:
- Reasoning about objects: "Pick up the object that is NOT a fruit" -> robot picks water bottle, not apple
- Symbol grounding: "Move to number 3" -> robot understands text on table
- Zero-shot generalization: sees unseen object in robot data, but seen in web data
Results (6,000 evaluation trials):
- Seen objects: 73% (baseline RT-1: 75% — equivalent)
- Unseen objects: 62% (RT-1: 32% — 2x better!)
- Semantic reasoning: 36% (RT-1: 0% — impossible before)
Limitations
- Model huge: 12B-55B parameters, needs TPU cluster for training and inference
- Slow: ~1-3Hz action frequency (robot arms need 10-50Hz)
- Closed-source: Google doesn't release weights
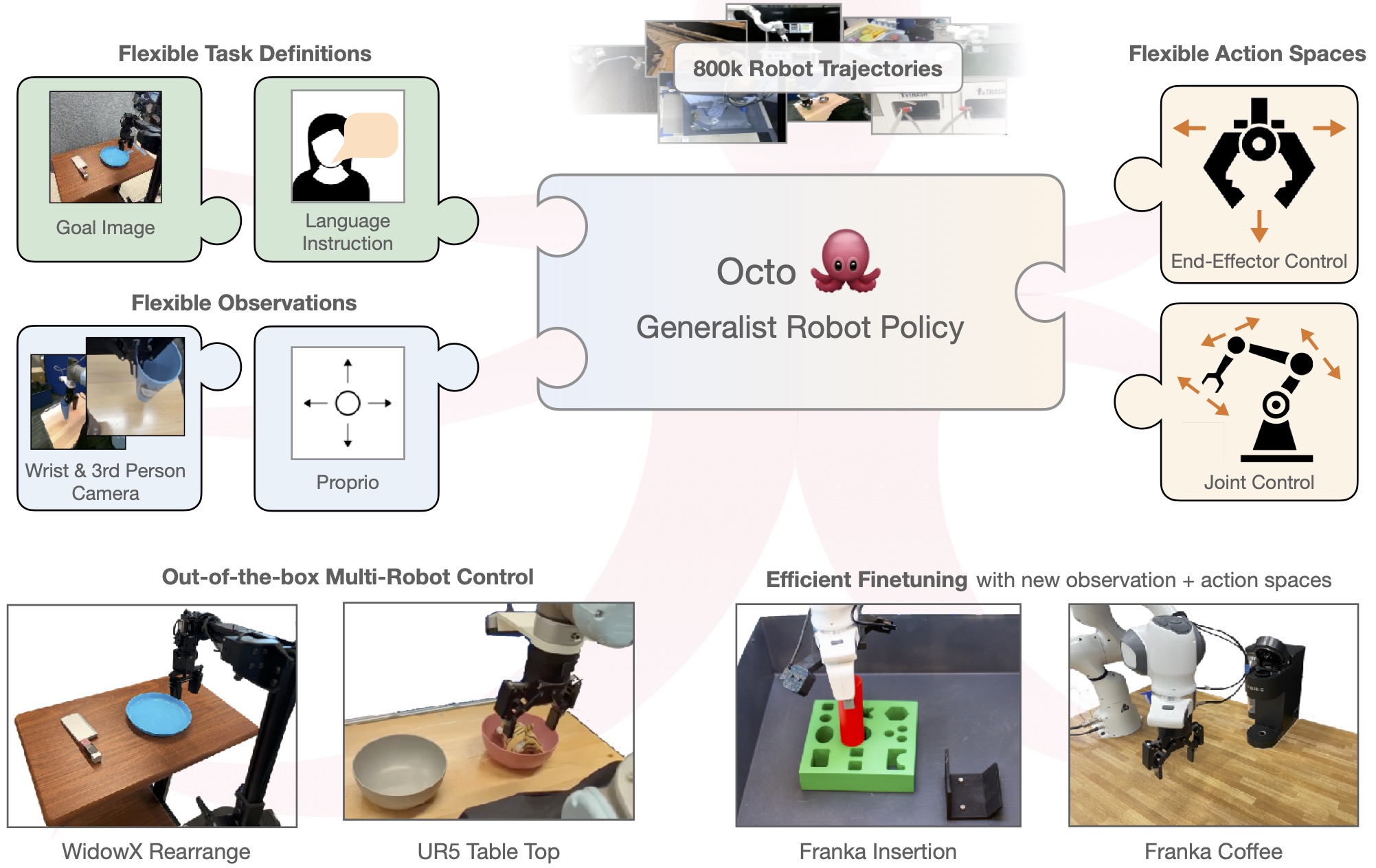
Octo: Open-Source Generalist Policy
Why Octo Matters
Octo (Ghosh et al., 2024) from UC Berkeley solves RT-2's biggest problem: accessibility. Octo is open-source, trained on Open X-Embodiment dataset (800K trajectories from 22 robot platforms), and can be fine-tuned on consumer GPU in hours.
Architecture
Input tokens:
- Task: language instruction OR goal image -> tokenizer
- Observations: images + proprio -> patchify + linear projection
- Readout tokens: learnable tokens to decode actions
Transformer backbone:
- 27M (Octo-Small) or 93M (Octo-Base) parameters
- Block-wise attention: obs tokens attend to task tokens,
readout tokens attend to all
Action head:
- Diffusion head (default) or MSE head
- Output: action chunk [a_t, ..., a_{t+H}]
Fine-Tuning Workflow
This is Octo's real power — fine-tune for your robot with minimal data:
# Fine-tune Octo for custom robot (simplified)
from octo.model.octo_model import OctoModel
from octo.data.dataset import make_single_dataset
# 1. Load pre-trained Octo
model = OctoModel.load_pretrained("hf://rail-berkeley/octo-base-1.5")
# 2. Load custom dataset (need only 50-100 demos)
dataset = make_single_dataset(
dataset_kwargs={
"name": "my_robot_data",
"data_dir": "/path/to/my/data",
},
train=True,
)
# 3. Fine-tune (2-4 hours on RTX 4090)
model.finetune(
dataset,
steps=50000,
batch_size=128,
learning_rate=3e-5,
# Freeze vision encoder, only train action head + readout
frozen_keys=["octo_transformer/BlockTransformer_0/*"],
)
# 4. Save and deploy
model.save_pretrained("my_finetuned_octo")
Fine-Tuning Results
On 9 robot platforms, Octo fine-tuned with 50-100 demos:
- Beats BC from scratch on 7/9 platforms
- Matches task-specific training on most tasks
- Fine-tuning takes only 2-4 hours on 1 GPU (vs days for RT-2)
pi0: Flow Matching for General Robot Control
Breakthrough from Physical Intelligence
pi0 (Black et al., 2024) from Physical Intelligence is the newest and arguably most powerful VLA model. Instead of autoregressive token generation (like RT-2), pi0 uses flow matching — a generalization of diffusion models — to generate actions.
Architecture
Pre-trained VLM backbone: PaliGemma (3B vision-language model)
Flow matching action expert:
- Separate action generation module
- Trained with flow matching objective
- Output: continuous action trajectories (no discretization)
Training:
- Pre-train on diverse multi-robot dataset (7 robot platforms)
- Fine-tune for specific tasks with 50-100 demos
Why Flow Matching?
RT-2 discretizes actions into tokens -> loses precision. pi0 uses flow matching to generate continuous actions directly, preserving accuracy for fine-grained manipulation.
Comparison:
- RT-2: output "token 47" -> decode to dx=0.03 (quantization error)
- pi0: output dx=0.0312 directly (continuous, more precise)
Results
pi0 achieves impressive results on dexterous manipulation tasks:
- Laundry folding: 80% success (human-level difficulty)
- Table bussing: 85% success
- Box assembly: 70% success
- Zero-shot transfer across different robot platforms

Comparison of 3 VLA Models
| Criterion | RT-2 | Octo | pi0 |
|---|---|---|---|
| Team | Google DeepMind | UC Berkeley | Physical Intelligence |
| Size | 12B-55B | 27M-93M | ~3B |
| Open-source | No | Yes | No (weights closed) |
| Training data | Google internal | Open X-Embodiment (800K) | Multi-robot (proprietary) |
| Action generation | Autoregressive tokens | Diffusion head | Flow matching |
| Action precision | Low (discrete) | Medium | High (continuous) |
| Inference speed | 1-3 Hz | 5-10 Hz | 5-15 Hz |
| Fine-tune cost | TPU days | GPU hours | GPU hours |
| Zero-shot | Good (web knowledge) | Limited | Good |
| Dexterous tasks | Medium | Medium | Best |
| Best for | Semantic reasoning | Open-source research | Production deployment |
Fine-Tuning VLA for Custom Tasks
When to Fine-Tune VLA?
Do fine-tune when:
- You have new robot setup (different cameras, action space)
- Task needs language conditioning (multiple tasks, instructions)
- Want to leverage pre-trained representations vs training from scratch
- Have 50-100 demos and want fast results
DON'T use VLA when:
- Just one simple task (use ACT or Diffusion Policy — simpler, faster)
- Need real-time (<5ms inference) — VLA too slow
- No GPU (Octo-Base needs at least RTX 3080)
- Task doesn't need language understanding
Fine-Tuning Best Practices
-
Freeze vision encoder: only train action head and readout tokens. Vision encoder learned well from pre-training; fine-tuning causes overfitting.
-
Low learning rate: 3e-5 for Octo, lower for pi0. VLA pre-trained weights are valuable, don't want to erase them.
-
Data diversity > quantity: 50 diverse demos (different initial conditions) better than 200 identical demos.
-
Evaluate frequently: every 5,000 steps, run 20 eval episodes. VLA overfits fast on small datasets.
-
Gradient checkpointing: save VRAM, allows fine-tuning 3B model on 24GB GPU.
VLA Limitations (2026)
1. Speed Still a Bottleneck
5-15 Hz insufficient for many manipulation tasks (contact-rich, force-sensitive). Groups like Stanford researching asynchronous VLA — high-level VLA outputs subgoals, low-level policy executes fast.
2. Sim-to-Real Gap
VLA models train mostly on real data, but real data is expensive and slow to collect. Integrating sim data into VLA pre-training remains open challenge.
3. Safety
VLA is black box — no guarantees about behavior. In industry, this is deal-breaker for safety-critical. Need separate safety mechanisms (force limits, workspace bounds, human detection).
4. Data Ownership
RT-2 trains on Google proprietary data. pi0 trains on Physical Intelligence data. Only Octo uses public dataset. When fine-tuning, your data might leak through model weights — IP concerns.
Future: VLA + Manipulation
pi0.5 and Beyond
pi0.5 (Physical Intelligence, 2025) extends pi0 with open-world generalization — robot does tasks never seen in training, just from language instruction. Closest yet to "general-purpose robot."
Open-Source Catching Up
Octo team working on newer versions with larger datasets and better fine-tuning. Hugging Face LeRobot community integrating VLA models. Gap between open-source and proprietary shrinking.
VLA + Diffusion Policy
Strongest combination: VLA for high-level understanding (understand task from language), Diffusion Policy for low-level execution (smooth, precise trajectories). pi0 does this with flow matching; other labs following.
Next in Series
- Part 5: Dexterous Manipulation: Teaching Robot Hands — When gripper isn't enough
- Part 6: Bimanual Manipulation: Teaching Robots Both Arms — Coordination between 2 arms
Related Articles
- Diffusion Policy in Practice: From Theory to Code — Part 3 of this series
- VLA Models: RT-2, Octo, OpenVLA — Detailed VLA theory
- Spatial VLA and Future of Robot AI — 3D-aware VLA models
- Foundation Models for Robotics — Foundation models overview


