Why Imitation Learning for Manipulation?
In Part 1 of this series, we discussed grasping -- the problem of picking up a single object. But real-world manipulation is far more complex: feeding food into a box, inserting bolts into holes, opening bottle caps... These tasks involve long horizons, multiple steps, and are difficult to code by hand (hard-coding).
Imitation Learning (IL) solves this problem by: instead of coding each step, let the robot watch a person do it and learn from that. A human teleoperates the robot to perform the task 50-100 times, collecting data, then train the policy via supervised learning.
It sounds simple, but challenges like distribution shift, multimodal actions, and compounding errors make IL more nuanced. This post covers the journey from basics (Behavioral Cloning) to state-of-the-art (ACT), with practical code and real-world tips.
If you haven't read the IL overview, see Imitation Learning 101 in the AI for Robotics series.

Data Collection: Teleoperation
Why Data Quality is Everything
In IL, data quality determines 80% of success. A policy trained on 50 high-quality demonstrations outperforms one trained on 500 poor demonstrations. "Good" means:
- Consistent: For same task, human performs similarly across episodes
- Diverse enough: Covers various initial conditions (object position, angle...)
- Smooth: No jerkiness, no pauses between steps, even speed
Teleoperation Methods
| Method | Cost | Data Quality | Setup Difficulty |
|---|---|---|---|
| Keyboard/joystick | Low | Low (jerky, slow) | Easy |
| VR controller (Quest 3) | ~$500 | Medium | Medium |
| Leader-follower (ALOHA-style) | ~$5,000-32,000 | High (most natural) | Hard |
| Kinesthetic teaching | 0 (just cobot) | High | Easy (but tiring) |
Leader-follower is the gold standard today: you control a leader robot arm, the follower robot arm copies movement exactly. This is how ALOHA and Mobile ALOHA collect data -- natural, accurate, and scalable.
If you don't have ALOHA hardware, LeRobot SO-100 from Hugging Face (~$300) supports leader-follower with 2 cheap robot arms.
Data Format
Each demonstration episode contains:
# Each timestep t in episode
{
"observation": {
"images": {
"cam_high": np.array([480, 640, 3]), # RGB top camera
"cam_wrist": np.array([480, 640, 3]), # RGB wrist camera
},
"qpos": np.array([6]), # joint positions (6-DoF arm)
"qvel": np.array([6]), # joint velocities
"gripper": float, # gripper opening (0-1)
},
"action": np.array([7]), # target joint positions + gripper
}
Note: action space can be joint positions, velocities, or end-effector pose (Cartesian). Joint positions are most common for stability and reproducibility.
Behavioral Cloning (BC): Basic Supervised Learning
Concept
BC is the simplest approach: treat IL as supervised learning -- input is observation, output is action, loss is MSE between predicted and expert action.
import torch
import torch.nn as nn
class BCPolicy(nn.Module):
def __init__(self, obs_dim, action_dim, hidden=256):
super().__init__()
self.net = nn.Sequential(
nn.Linear(obs_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, hidden),
nn.ReLU(),
nn.Linear(hidden, action_dim),
)
def forward(self, obs):
return self.net(obs)
# Training loop
policy = BCPolicy(obs_dim=18, action_dim=7)
optimizer = torch.optim.Adam(policy.parameters(), lr=1e-4)
for epoch in range(100):
for obs, action in dataloader:
pred_action = policy(obs)
loss = nn.MSELoss()(pred_action, action)
optimizer.zero_grad()
loss.backward()
optimizer.step()
The Distribution Shift Problem
BC has a critical issue called distribution shift (or compounding error):
- During training, policy sees states from expert trajectories (on-policy data)
- During deployment, policy makes slightly wrong action → robot enters unseen state
- At this novel state, policy predicts even worse action → larger deviation
- After few steps, robot is in completely different state from expert training data → task fails
Small errors at step 1 accumulate into large errors at step T. For 100-step task, only 1% error per step results in ~36% success rate.
DAgger: Fixing Distribution Shift
Core Idea
DAgger (Dataset Aggregation, Ross et al., 2011) fixes distribution shift by collecting data from states the policy encounters during deployment:
- Train policy on initial expert data (like BC)
- Run policy on robot → observe states it reaches
- Expert labels actions for those new states
- Merge new data into dataset, retrain policy
- Repeat from step 2
DAgger iteration:
D0 = expert demonstrations
pi_0 = BC(D0)
for i = 1, 2, ..., N:
Run pi_{i-1} on robot → collect states S_i
Expert labels actions for S_i → data D_i
D = D0 union D1 union ... union D_i
pi_i = BC(D)
Practical Limitations
- Requires expert present continuously for labeling -- time-consuming
- Robot running poor policy can be dangerous (collision, breaking things)
- Each iteration needs real robot deployment -> slow
Variants like HG-DAgger and LazyDAgger reduce expert interventions, but still need human in the loop.
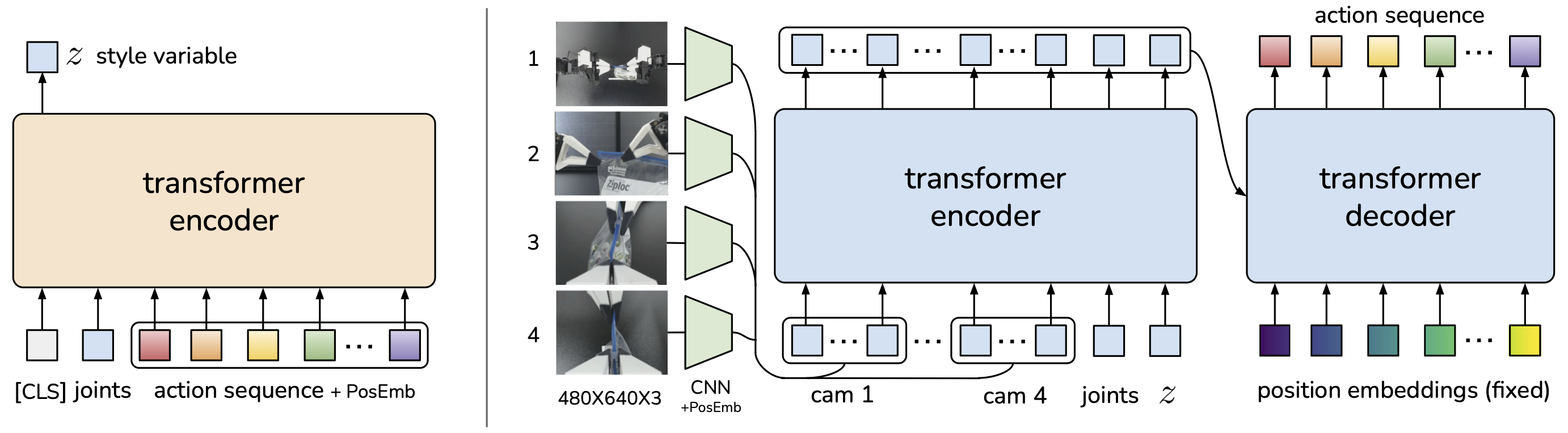
ACT: Action Chunking with Transformers
ACT's Breakthrough
ACT (Zhao et al., 2023) from Stanford is a major breakthrough for IL in manipulation. Two key ideas:
1. Action Chunking: Instead of predicting 1 action per timestep, predict a sequence of k actions (e.g., k=100, ~2 seconds). This reduces effective horizon from T to T/k, reducing compounding error proportionally.
2. CVAE (Conditional Variational Autoencoder): Handles multimodal actions -- when same observation can have multiple valid action sequences (e.g., grasp cup from left or right). CVAE encodes style variable z to capture this diversity.
Architecture
Input:
- Images: [cam_high, cam_wrist] -> ResNet18 -> visual tokens
- Joint positions: qpos -> MLP -> proprioception token
- Style variable: z ~ N(0, I) (at inference)
Encoder (training only):
- [action_sequence, obs_tokens] -> Transformer Encoder -> z (mean, var)
Decoder:
- [z, obs_tokens] -> Transformer Decoder -> action_chunk [a_t, a_{t+1}, ..., a_{t+k}]
Temporal Ensembling
When executing action chunks, at each timestep t, the robot has multiple predicted actions from previous chunks (chunks starting at t-1, t-2, ...). ACT uses temporal ensembling -- weighted average of predictions with exponential decay:
# Temporal ensembling
def temporal_ensemble(all_predictions, current_step, decay=0.01):
"""
all_predictions: dict {start_step: action_chunk}
Returns action for current_step
"""
weights = []
actions = []
for start_step, chunk in all_predictions.items():
idx = current_step - start_step
if 0 <= idx < len(chunk):
w = np.exp(-decay * idx)
weights.append(w)
actions.append(chunk[idx])
weights = np.array(weights) / sum(weights)
return sum(w * a for w, a in zip(weights, actions))
Results
ACT achieves 80-90% success rate on 6 difficult manipulation tasks (opening bottle, inserting batteries, picking food) with only 10 minutes of demonstrations (~50 episodes). This contrasts sharply with BC (~30-50% on same tasks).
BC vs DAgger vs ACT Comparison
| Criterion | BC | DAgger | ACT |
|---|---|---|---|
| Distribution shift | Serious | Mitigated (needs expert) | Mitigated (action chunking) |
| Multimodal actions | Unhandled | Unhandled | Handled (CVAE) |
| Demos needed | 100-500+ | 50-100 + iterations | 50 (10 minutes) |
| Needs expert in loop | No | Yes (each iteration) | No |
| Architecture | MLP/CNN | MLP/CNN | Transformer + CVAE |
| Long-horizon tasks | Poor | OK | Good |
| Implementation difficulty | Easy | Medium | Medium |
| Real robot risk | Low | High (poor policy) | Low |
Hands-on: Training ACT with LeRobot
LeRobot from Hugging Face has ACT built-in. Here's fastest path:
# 1. Install LeRobot
pip install lerobot
# 2. Download sample dataset
python -m lerobot.scripts.download_dataset \
--repo-id lerobot/aloha_sim_transfer_cube_human
# 3. Train ACT policy
python -m lerobot.scripts.train \
--policy.type=act \
--env.type=aloha \
--env.task=AlohaTransferCube-v0 \
--dataset.repo_id=lerobot/aloha_sim_transfer_cube_human \
--training.num_epochs=2000 \
--training.batch_size=8
# 4. Evaluate
python -m lerobot.scripts.eval \
--policy.path=outputs/train/act_aloha_transfer_cube/checkpoints/last/pretrained_model \
--env.type=aloha \
--env.task=AlohaTransferCube-v0 \
--eval.n_episodes=50
Tips for Collecting Good Data
- Go slow and smooth: Teleoperate at 50-70% max speed, avoid jerky movements
- Vary object positions: Cover variation in initial conditions
- 50 demos sufficient: For simple task with ACT
- Review data before training: Replay episodes, remove poor ones
- Camera angle matters: Position camera to clearly see contact area
Next in Series
This is Part 2 of Robot Manipulation Masterclass. Coming next:
- Part 3: Diffusion Policy in Practice: From Theory to Code -- When ACT isn't enough, Diffusion Policy is next step
- Part 4: VLA for Manipulation: RT-2, Octo, pi0 -- Foundation models for manipulation
Related Posts
- Robot Grasping 101: Analytical to Learning-Based -- Part 1 of series
- Imitation Learning 101: BC, IRL, and What You Need to Know -- Broader IL overview
- ACT: Action Chunking with Transformers Deep Dive -- Detailed ACT architecture analysis
- Diffusion Policy in Practice -- Part 3 of series
- Building a Manipulation System with LeRobot -- End-to-end deployment


