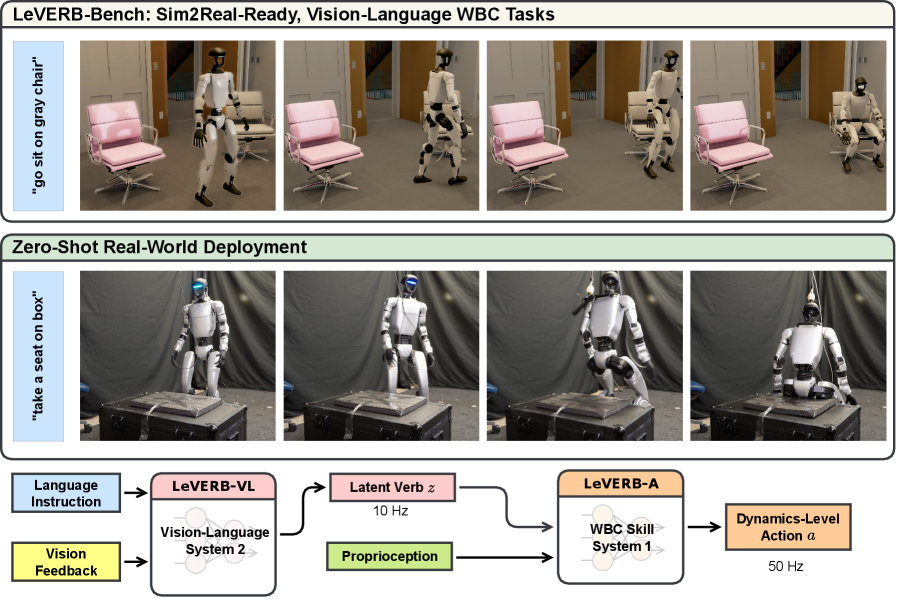
Imagine telling a humanoid robot: "Go to the red chair in the corner and sit down." Not via a scripted command, but in plain natural language. The robot must understand the sentence, visually locate the red chair among distractors, navigate there with stable bipedal locomotion, and finally perform a seated motion — all as one coherent behavior.
This is exactly the problem that UC Berkeley's Ember Lab tackles in LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction (arXiv 2506.13751). But LeVERB is more than a new algorithm — it introduces the world's first benchmark combining vision-language understanding with humanoid whole-body control under sim-to-real conditions.
The Core Problem: VLA and WBC Speak Different Languages
Before LeVERB, the robotics community had two parallel threads that never connected:
Vision-Language-Action (VLA) models — π₀, OpenVLA, RoboVLMs — excel at semantic understanding and zero-shot generalization. But they are designed for quasi-static arm manipulation. Their "action space" is typically end-effector pose (x, y, z, orientation) or high-level joint angles. This is completely unsuitable for controlling a full humanoid body in motion.
Whole-Body Control (WBC) policies — RL-based controllers for Unitree G1, Boston Dynamics platforms, or motion-tracking teachers — generate smooth, dynamically stable full-body motion. But they require structured inputs: velocity targets, trajectory waypoints, or contact forces. They don't understand natural language.
The result: a humanoid robot can either understand language commands or move agilely — not both simultaneously.
LeVERB bridges this gap with a deceptively simple idea: Latent Verbs.
What Is LeVERB? Decoding the Name
LeVERB = Latent Vision-Language-Encoded Robot Behavior.
The central idea: instead of having a VLA model output actions directly (which would be incompatible with humanoid dynamics), LeVERB trains a VLA model to output a 256-dimensional vector — called a latent verb z_t. This vector is not a joint angle or velocity; it's a compressed "description" of the overall motion objective. A separate WBC policy reads this vector and generates the actual joint commands at control frequency.
Think of it like telling a sprinter "run fast" — they know exactly how to adjust their stride, lean angle, and arm swing. You don't specify which muscles to contract. The latent verb is "run fast"; the WBC policy is the sprinter.
Two-Tier Architecture: System 1 + System 2
LeVERB implements a clear hierarchical architecture:
Upper Tier: LeVERB-VL (System 2 — "The Brain")
LeVERB-VL is a transformer-based vision-language policy with 102.56 million parameters, running at 10 Hz.
Inputs:
- Egocentric image (head-mounted camera, 1080×720)
- Third-person image (external camera, 1080×720)
- Text instruction (natural language command)
- Current state s_t (proprioception — joint positions, velocities, gravity vector)
Internal architecture:
- Vision Encoder: Frozen SigLIP ViT-B/16 — encodes both camera views into visual tokens
- Text Encoder: SigLIP model — converts the command sentence into language tokens
- Kinematics Encoder (E_ψ): MLP encoding future state trajectory from s_t+1 to s_t+M
- CVAE backbone: Combines visual + text + kinematic features to learn P(z_t | I_t, c, s_t)
- Discriminator with Gradient Reversal: Aligns latent distributions between vision-language data and language-only data
Output: Gaussian distribution N(μ_ρ, σ_ρ²) in 256-dimensional space — from which z_t is sampled.
Lower Tier: LeVERB-A (System 1 — "The Muscles")
LeVERB-A is a much smaller transformer-based whole-body action policy — only 1.1 million parameters — running at 50 Hz directly on the robot's onboard CPU.
Inputs:
- Proprioceptive observations (joint positions/velocities, IMU, gravity vector)
- Latent verb z_t from LeVERB-VL (new sample every H=5 steps = 500ms)
Internal architecture: Small transformer (2 layers, 4 heads, 128-dim hidden)
Output: Joint position commands for the entire body — legs, torso, arms — at 50 Hz
Training mechanism: LeVERB-A is trained via DAgger (Dataset Aggregation) from teacher policies trained with PPO, one per motion category. The student learns to follow latent codes rather than specific trajectories.

LeVERB-Bench: The First Vision-Language WBC Benchmark
One of the paper's major contributions is LeVERB-Bench — the world's first sim-to-real benchmark combining vision-language instructions with humanoid WBC evaluation.
Scale
| Category | # Motions | Total Duration | Avg Duration |
|---|---|---|---|
| Navigation | 101 | 465.6s | 4.61s |
| Locomotion | 20 | 64.4s | 3.22s |
| Sitting | 23 | 74.4s | 3.23s |
| Reaching | 10 | 17.4s | 1.74s |
| VL Total | 154 | 621.7s | 4.04s |
| Language-only | 460 | 1,154.5s | — |
Photorealistic Environments
The benchmark uses IsaacSim with ray-tracing rendering across 4 indoor environments:
- Brown Stone: Residential spaces with kitchens and living rooms
- Apartment: Multi-room apartment layouts
- Modern House: Large house with varied floor plans
- Kitchen: Compact, cluttered kitchen environments
Textures, objects, and camera angles are procedurally randomized to maximize diversity — critical for zero-shot sim-to-real transfer.
10 Task Categories
From simple to complex:
- VNF (Visual Navigation Front): Walk to an object in front
- VNR (Visual Navigation Rear): Turn around, navigate to an object behind
- VNS (Visual Navigation Sit): Walk → turn → sit (multi-step sequence)
- Sit: Sit down
- Stand: Stand up
- Locomotion: Forward walking, left/right turns
Each task has 3 difficulty levels: Objective (no distractors), Distractor (1-2 distracting objects), Cluttered (densely populated environment).
Training Pipeline: 4 Phases

Phase 1: Data Collection and Processing
The pipeline starts from human MoCap data, retargeted to Unitree G1 kinematics. These kinematic sequences are replayed in IsaacSim with ray-tracing rendering to produce photorealistic synthetic videos. A VLM (VILA) automatically annotates text instructions for each trajectory.
Result: 3,696 vision-language trajectories + 2,300 language-only trajectories = 17.1 hours of synthetic video.
Phase 2: Training LeVERB-VL
The CVAE is trained with a three-component loss:
L = β₁ × L_recon + β₂ × L_KL + L_disc
- L_recon: MSE between predicted and actual future states (trajectory reconstruction)
- L_KL: KL divergence regularization for the latent distribution (β₂ = 5×10⁻⁴)
- L_disc: Adversarial loss from the gradient-reversal discriminator (β₁ = 10⁻¹)
Training takes 6 hours on 2× NVIDIA Ada 6000 GPUs, batch size 512.
Why the gradient-reversal discriminator? VL data (with images) and language-only data (text only) produce different latent distributions. Without alignment, deploying with VL input would shift the latent distribution away from what LeVERB-A learned. The discriminator learns to classify the data source (VL vs. language-only), but gradient reversal flips gradients through the backbone — forcing it to produce latents that are indistinguishable across sources.
Phase 3: Teacher Policy Training (PPO)
Each motion category gets a dedicated teacher policy trained with PPO to track kinematic trajectories. Reward components:
- Motion tracking (DeepMimic-style): Penalizes deviation from reference
- Smoothness: Penalizes jerky motion
- Joint limits: Penalizes exceeding limits
- Early termination: When tracking error exceeds threshold
Domain randomization across 7 parameters: friction [0.3–0.8], restitution [0–0.5], joint calibration offsets [−0.05, 0.05], armature scale [0.2–2.0], velocity perturbations every 10–15 seconds.
Phase 4: Training LeVERB-A (DAgger)
The student policy learns to follow latent verbs through on-policy DAgger. Every H=5 steps (500ms), a new z_t is sampled from the learned distribution of LeVERB-VL. The loss is Huber loss against teacher actions — more robust than MSE to occasional outliers.
Sim-to-Real Deployment on Unitree G1
This is the most practically significant part of the paper. LeVERB is deployed zero-shot (no fine-tuning) on a Unitree G1 with the following setup:
System 1 (LeVERB-A — onboard robot):
- Inference on onboard CPU at 50 Hz
- Sensor fusion: joint encoders + IMU via custom state estimator at 500 Hz
- Runtime: ONNX (C++ implementation) — mandatory for real-time CPU inference
- Output: desired joint positions (fixed zero velocity, tuned k_p/k_d gains)
System 2 (LeVERB-VL — external workstation):
- Inference on RTX 4090 at 10 Hz
- Input: RealSense camera (onboard, 30 FPS) + third-person USB camera (30 FPS, 1080×720)
- Output: latent code z_t sent via ROS2 topic to the robot
Why does this decoupling work? LeVERB-VL is trained entirely on kinematics — no dynamics simulation required during VLA training. Only LeVERB-A must handle dynamics, and it has been domain-randomized extensively in simulation. The latent interface acts as a buffer that absorbs distribution mismatch between sim and real.

Results: The Numbers
Success Rate Comparison (%)
| Task | Environment | LeVERB | ND | NE | NVL | NS |
|---|---|---|---|---|---|---|
| VNF | Objective | 80 | 75 | 75 | 15 | 0 |
| VNF | Distractor | 75 | 55 | 60 | 0 | 0 |
| VNF | Cluttered | 50 | 5 | 25 | 15 | 0 |
| VNR | Objective | 30 | 10 | 45 | 10 | 0 |
| VNR | Cluttered | 25 | 0 | 5 | 5 | 0 |
| Sit | — | 100 | 0 | 100 | 40 | 10 |
| Stand | — | 90 | 75 | 90 | 55 | 15 |
| Locomotion | — | 100 | 100 | 100 | 100 | 50 |
| Average | — | 58.5 | 33.0 | 53.0 | 25.5 | 7.5 |
Ablation baselines:
- ND (No Discriminator): Latent space not aligned → dramatic drop on visual tasks
- NE (No Kinematics Encoder): Less fine-grained latent → modest performance decrease
- NVL (No LeVERB-VL): Direct VL→action bypassing the high-level policy → works only on language-only tasks
- NS (No Sampling): Deterministic autoencoder → unstructured latent → near-complete failure (7.5%)
Headline numbers:
- LeVERB achieves 58.5% overall vs. 7.5% naive baseline → 7.8× improvement
- 80% success on simple front visual navigation (VNF Objective)
- 100% on locomotion and sitting with language commands
- Successful zero-shot sim-to-real: real robot walks to target chair and sits from natural language instruction
Ablation Insights: What Actually Matters?
Three key technical takeaways from the ablation studies:
1. Gradient-Reversal Discriminator is critical: Removing it (ND) drops overall success from 58.5% → 33%. Effect is especially severe on cluttered visual tasks (VNF Cluttered: 50% → 5%). Without alignment, the latent distribution under VL input doesn't match what LeVERB-A was trained on.
2. Kinematics Encoder matters but isn't the bottleneck: Removing it (NE) drops performance from 58.5% → 53%. The encoder provides temporal structure that helps generalization to unseen scenes.
3. Variational sampling (not deterministic) is essential: The NS variant uses a deterministic autoencoder (no sampling) → 7.5% success. Without the variational structure, the latent space is unstructured: it cannot interpolate between motion concepts and fails to generalize.
Implementation Reference
The official code has not yet been publicly released (check ember-lab-berkeley.github.io/LeVERB-Website/). However, you can recreate the core pipeline with:
Environment setup:
# Isaac Sim 4.x (NVIDIA Omniverse)
# Python 3.10+
pip install torch torchvision # PyTorch 2.x
pip install transformers # SigLIP via Hugging Face
pip install onnxruntime # ONNX runtime for LeVERB-A
LeVERB-VL CVAE (simplified sketch):
import torch
import torch.nn as nn
class LeVERBVL(nn.Module):
def __init__(self, latent_dim=256):
super().__init__()
# SigLIP vision encoder (frozen weights)
self.vision_encoder = load_siglip_vitb16(frozen=True)
# Kinematics encoder (future state trajectory)
self.kinematic_encoder = KinematicsMLP(input_dim=state_dim * horizon)
# ViT-Base backbone (768-dim, 102M params total)
self.vit_backbone = ViTBase(hidden_dim=768, output_dim=512)
# Prior head (from VL) and posterior head (from kinematics)
self.prior_head = nn.Linear(512, latent_dim * 2) # mu, logvar
self.post_head = nn.Linear(512, latent_dim * 2) # mu, logvar
# Discriminator with gradient reversal layer
self.discriminator = Discriminator(input_dim=latent_dim)
def forward(self, image, text_tokens, state, future_states=None):
vis_feat = self.vision_encoder(image)
vl_feat = self.vit_backbone(vis_feat, text_tokens, state)
mu_p, logvar_p = self.prior_head(vl_feat).chunk(2, dim=-1)
if future_states is not None: # training
kin_feat = self.kinematic_encoder(future_states)
mu_q, logvar_q = self.post_head(kin_feat).chunk(2, dim=-1)
z = reparameterize(mu_q, logvar_q)
else: # inference: sample from prior
z = reparameterize(mu_p, logvar_p)
return z, mu_p, logvar_p, (mu_q if future_states else None)
Training loss:
def leverb_vl_loss(pred_states, true_states, mu_p, logvar_p, mu_q, logvar_q,
disc_logits, source_labels, beta1=0.1, beta2=5e-4):
L_recon = F.mse_loss(pred_states, true_states)
L_kl = -0.5 * (1 + logvar_q - logvar_p
- (mu_q - mu_p).pow(2) / logvar_p.exp()
- logvar_q.exp() / logvar_p.exp()).mean()
L_disc = F.cross_entropy(disc_logits, source_labels)
return L_recon + beta2 * L_kl + beta1 * L_disc
Deploy LeVERB-A via ONNX:
# Export to ONNX
python export_leverb_a.py --checkpoint leverb_a.pth --output leverb_a.onnx
# Verify
python -c "import onnxruntime as ort; sess = ort.InferenceSession('leverb_a.onnx'); print('OK')"
# On-robot C++ deployment:
# - Subscribe to ROS2 /leverb_latent_code topic (10 Hz from external PC)
# - Run ONNX inference + proprioception fusion at 50 Hz
# - Publish to /joint_position_command
Comparison with Related Approaches
| Approach | VL Understanding | WBC Agility | Zero-shot Transfer | Dedicated VL-WBC Benchmark |
|---|---|---|---|---|
| VLA only (π₀, OpenVLA) | ✅ Strong | ❌ None | ✅ Yes | Manipulation only |
| WBC only (RL controller) | ❌ None | ✅ Strong | ✅ Yes | Locomotion only |
| WholebodyVLA (ICLR 2026) | ✅ Strong | ✅ Strong | Partial | Loco-manipulation |
| LeVERB (UC Berkeley) | ✅ Strong | ✅ Strong | ✅ Zero-shot | First VL-WBC benchmark |
The key distinction from WholebodyVLA (ICLR 2026) is that LeVERB's latent interface fully decouples the VL policy from the WBC policy — you can upgrade LeVERB-VL to a stronger VLM without retraining LeVERB-A, and vice versa.
Known Limitations and Open Directions
The paper is transparent about its limitations:
-
Visual Navigation Rear (VNR) remains difficult: 30% success rate. The robot must execute a 180° turn while maintaining spatial awareness of the target — challenging for the current latent representation.
-
Multi-step sequence (VNS) at only 5%: Navigate + turn + sit requires long-horizon reasoning across multiple latent verb transitions. The current architecture doesn't handle this well.
-
No arm manipulation yet: The benchmark focuses on loco-navigation and sit/stand. Bimanual manipulation — the hardest part of humanoid WBC — is left to future work.
-
No public code release: At the time of writing, official code has not been released.
Natural extensions: bimanual manipulation tasks, chain-of-thought latent verb sequences for multi-step tasks, and integration with platforms beyond the Unitree G1.
Technical Summary
LeVERB makes language-instructable humanoid robots technically feasible:
- Latent verb z_t (256-dim Gaussian) = the interface language between VL semantics and WBC dynamics
- LeVERB-VL (102M params, 10 Hz) = the brain that reads language + vision and produces z_t
- LeVERB-A (1.1M params, 50 Hz) = the muscle that converts z_t into joint commands
- CVAE + Gradient-Reversal Discriminator = the most critical technical ingredient for generalization
- 58.5% overall success on 150+ task benchmark; 7.8× over naive hierarchical baseline
- Zero-shot sim-to-real validated on real Unitree G1
This is a significant step toward humanoid robots that can receive natural language commands and execute complex whole-body behaviors in real-world environments.

