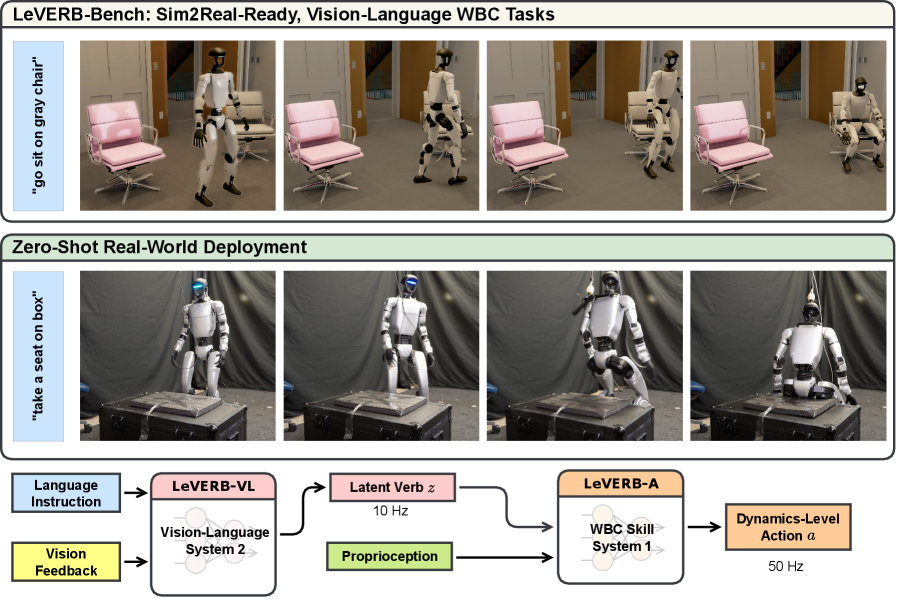
Thử tưởng tượng bạn muốn một robot humanoid đi đến cái ghế màu đỏ ở góc phòng, tự mình ngồi xuống — không phải bằng command scripted, mà bằng câu tiếng Anh thuần túy: "Go to the red chair and sit down." Nghe đơn giản, nhưng đây là bài toán cực kỳ khó vì nó đòi hỏi robot phải hiểu ngôn ngữ, nhận diện cảnh vật, lập kế hoạch chuyển động, và kiểm soát toàn bộ cơ thể cùng lúc — từ chân đến thân đến tay.
Đây chính xác là bài toán mà nhóm nghiên cứu từ UC Berkeley (Ember Lab) đã giải quyết trong paper LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction (arXiv 2506.13751). Điểm đặc biệt là LeVERB không chỉ là một algorithm mới — nó còn là benchmark đầu tiên trên thế giới kết hợp vision-language với whole-body control humanoid trong điều kiện sim-to-real.
Vấn đề cốt lõi: VLA và WBC đang nói hai ngôn ngữ khác nhau
Trước LeVERB, cộng đồng robotics đang theo hai hướng song song nhưng không kết nối:
Vision-Language-Action (VLA) models như π₀, OpenVLA, hay RoboVLMs rất giỏi hiểu ngữ cảnh và zero-shot generalization — nhưng chúng được thiết kế cho manipulation tay tĩnh. "Action space" của chúng thường là end-effector pose (x, y, z, orientation) hoặc joint angles cấp cao. Hoàn toàn không phù hợp để điều khiển cả cơ thể humanoid đang chuyển động.
Whole-Body Control (WBC) policies như controller trên Unitree G1, Boston Dynamics, hay các model RL-based thì rất giỏi tạo ra chuyển động mượt mà, ổn định về mặt dynamics — nhưng chúng cần input dạng structured rõ ràng: velocity target, trajectory waypoint, hay contact force. Chúng không hiểu ngôn ngữ tự nhiên.
Kết quả: một con robot humanoid chỉ có thể làm một trong hai — hiểu lệnh ngôn ngữ hoặc đi đứng linh hoạt, chưa thể làm cả hai cùng lúc.
LeVERB lấp đầy khoảng trống này bằng một khái niệm rất thông minh: Latent Verbs (động từ tiềm ẩn).
LeVERB là gì? Giải mã cái tên
LeVERB = Latent Vision-Language-Encoded Robot Behavior.
Ý tưởng trung tâm: thay vì để VLA model output action trực tiếp (vốn không phù hợp với dynamics humanoid), LeVERB dạy một VLA model output ra một vector 256 chiều — gọi là latent verb z_t. Vector này không phải là joint angle hay velocity, mà là một "mô tả nén" về mục tiêu chuyển động tổng thể. Rồi một WBC policy khác sẽ đọc vector này và thực sự tạo ra torque/joint command cụ thể.
Giống như khi bạn nói "chạy nhanh" với một vận động viên — họ tự biết phải bước chân như thế nào, tốc độ cơ thể nghiêng bao nhiêu. Bạn không cần nói từng cơ nào co lại. Latent verb là cái "chạy nhanh" đó, còn WBC policy là vận động viên.
Kiến trúc hai tầng: System 1 + System 2
LeVERB áp dụng kiến trúc phân cấp rõ ràng:
Tầng trên: LeVERB-VL (System 2 — "Não to")
LeVERB-VL là một transformer-based vision-language policy với 102.56 triệu tham số, chạy ở 10 Hz.
Input:
- Ảnh egocentric (camera gắn trên đầu robot, 1080×720)
- Ảnh third-person (camera ngoài, 1080×720)
- Text instruction (câu lệnh ngôn ngữ tự nhiên)
- State hiện tại s_t (proprioception — vị trí joint, velocity, gravity vector)
Kiến trúc bên trong:
- Vision Encoder: Frozen SigLIP ViT-B/16 — encode cả ảnh egocentric lẫn third-person thành visual tokens
- Text Encoder: SigLIP model — convert câu lệnh thành language tokens
- Kinematics Encoder (E_ψ): MLP encode future state trajectory từ s_t+1 đến s_t+M
- CVAE backbone: Kết hợp visual + text + kinematic features để học phân phối P(z_t | I_t, c, s_t)
- Discriminator với Gradient Reversal: Align latent distribution giữa vision-language data và language-only data
Output: Phân phối Gaussian N(μ_ρ, σ_ρ²) trong không gian 256 chiều — từ đó sample ra latent verb z_t.
Tầng dưới: LeVERB-A (System 1 — "Cơ bắp")
LeVERB-A là một transformer-based whole-body action policy nhỏ hơn nhiều, chỉ 1.1 triệu tham số, chạy ở 50 Hz trực tiếp trên onboard CPU của robot.
Input:
- Proprioceptive observations (joint positions/velocities, IMU, gravity vector)
- Latent verb z_t từ LeVERB-VL (sample mới mỗi H=5 steps = 500ms)
Kiến trúc bên trong: Transformer nhỏ (2 layers, 4 heads, 128-dim hidden)
Output: Joint position commands cho toàn bộ cơ thể — chân, thân, tay — tại 50 Hz
Cơ chế hoạt động: LeVERB-A được train bằng DAgger (Dataset Aggregation) từ các teacher policies được train bằng PPO riêng cho từng category chuyển động. Student học cách follow latent code thay vì follow trajectory cụ thể.

LeVERB-Bench: Benchmark đầu tiên cho Vision-Language WBC
Một trong những đóng góp lớn nhất của paper này là LeVERB-Bench — bộ benchmark sim-to-real đầu tiên kết hợp vision-language với humanoid WBC.
Quy mô
| Category | Số motions | Tổng thời gian | Avg duration |
|---|---|---|---|
| Navigation | 101 | 465.6s | 4.61s |
| Locomotion | 20 | 64.4s | 3.22s |
| Sitting | 23 | 74.4s | 3.23s |
| Reaching | 10 | 17.4s | 1.74s |
| Tổng VL | 154 | 621.7s | 4.04s |
| Language-only | 460 | 1,154.5s | — |
Môi trường photorealistic
Benchmark dùng IsaacSim với ray-tracing rendering để tạo 4 loại môi trường trong nhà:
- Brown Stone: Không gian dân dụng với bếp, phòng khách
- Apartment: Chung cư nhiều phòng
- Modern House: Nhà lớn nhiều layout
- Kitchen: Không gian bếp nhỏ, đông đúc
Texture, vật thể, góc camera đều được randomize để tăng diversity. Điều này rất quan trọng cho zero-shot sim-to-real.
10 loại task
Từ đơn giản đến phức tạp:
- VNF (Visual Navigation Front): Đi đến vật thể phía trước
- VNR (Visual Navigation Rear): Quay lại, đi đến vật thể phía sau
- VNS (Visual Navigation Sit): Đi → quay → ngồi (chuỗi action)
- Sit: Ngồi xuống
- Stand: Đứng dậy
- Locomotion: Đi thẳng, quẹo trái/phải Mỗi task có 3 mức độ khó: Objective (không có distractor), Distractor (1-2 vật gây nhiễu), Cluttered (môi trường đông đúc).
Pipeline training: 4 giai đoạn

Giai đoạn 1: Thu thập và xử lý data
Nhóm bắt đầu từ MoCap data của người thật, rồi retarget sang kinematic của humanoid Unitree G1. Tiếp theo replay trong IsaacSim với ray-tracing rendering để tạo synthetic video photorealistic. VLM (VILA) được dùng để tự động annotate text instruction cho từng trajectory.
Kết quả: 3,696 vision-language trajectories + 2,300 language-only trajectories, tổng cộng 17.1 giờ video synthetic.
Giai đoạn 2: Training LeVERB-VL
CVAE được train với loss function gồm 3 thành phần:
L = β₁ × L_recon + β₂ × L_KL + L_disc
- L_recon: MSE giữa predicted và actual future states (trajectory reconstruction)
- L_KL: KL divergence để regularize phân phối latent (β₂ = 5×10⁻⁴)
- L_disc: Adversarial loss từ discriminator với gradient reversal để align latent space giữa VL data và language-only data (β₁ = 10⁻¹)
Training mất 6 giờ trên 2× NVIDIA Ada 6000 GPUs, batch size 512.
Tại sao cần discriminator với gradient reversal? Vì VL data (có ảnh) và language-only data (chỉ text) có phân phối latent khác nhau. Nếu không align, khi deploy với VL input, latent space sẽ shift so với lúc train LeVERB-A — dẫn đến failure. Discriminator học phân biệt source (VL vs language-only), nhưng gradient reversal đảo chiều gradient của backbone → buộc backbone phải tạo ra latent indistinguishable giữa hai source.
Giai đoạn 3: Training Teacher Policies (PPO)
Mỗi category chuyển động có một teacher policy riêng, được train bằng PPO để track kinematic trajectory. Reward gồm:
- Motion tracking reward (DeepMimic-style): Penalize deviation từ reference trajectory
- Smoothness reward: Penalize jerky motion
- Joint limit reward: Penalize exceeding joint limits
- Early termination: Khi position/orientation error vượt threshold
Domain randomization 7 parameters: friction [0.3-0.8], restitution [0-0.5], joint calibration offsets, armature scale, velocity perturbations mỗi 10-15 giây.
Giai đoạn 4: Training LeVERB-A (DAgger)
Student policy học follow latent verb bằng DAgger — một hình thức imitation learning on-policy. Mỗi H=5 steps (500ms), sample z_t mới từ phân phối đã học của LeVERB-VL. Loss là Huber loss so với teacher actions (robust hơn MSE với outliers).
Sim-to-Real trên Unitree G1: Kiến trúc deploy thực tế
Đây là phần ứng dụng thực tế nhất của paper. LeVERB được deploy zero-shot (không fine-tune) lên Unitree G1 với setup:
System 1 (LeVERB-A — onboard robot):
- Inference trên onboard CPU ở 50 Hz
- Sensor fusion từ joint encoders + IMU, qua custom state estimator chạy 500 Hz
- Runtime: ONNX (C++ implementation) — quan trọng vì phải real-time trên CPU nhúng
- Output: desired joint positions (fixed zero velocity, tuned k_p/k_d gains)
System 2 (LeVERB-VL — external PC):
- Inference trên RTX 4090 ở 10 Hz (latency chấp nhận được vì high-level planning)
- Input: RealSense camera onboard (30 FPS) + USB camera third-person (30 FPS)
- Output: latent code z_t truyền qua ROS2 topic tới robot
Tại sao decoupling này hiệu quả? Vì LeVERB-VL được train hoàn toàn trên kinematics (không cần dynamics simulation). Chỉ LeVERB-A phải handle dynamics — và nó đã được domain-randomized kỹ trong sim. Latent interface hoạt động như một "buffer" hấp thụ distribution mismatch giữa sim và real.

Kết quả: Con số ấn tượng
Bảng so sánh success rate (%)
| Task | Environment | LeVERB | ND | NE | NVL | NS |
|---|---|---|---|---|---|---|
| VNF | Objective | 80 | 75 | 75 | 15 | 0 |
| VNF | Distractor | 75 | 55 | 60 | 0 | 0 |
| VNF | Cluttered | 50 | 5 | 25 | 15 | 0 |
| VNR | Objective | 30 | 10 | 45 | 10 | 0 |
| VNR | Cluttered | 25 | 0 | 5 | 5 | 0 |
| Sit | — | 100 | 0 | 100 | 40 | 10 |
| Stand | — | 90 | 75 | 90 | 55 | 15 |
| Locomotion | — | 100 | 100 | 100 | 100 | 50 |
| Average | — | 58.5 | 33.0 | 53.0 | 25.5 | 7.5 |
Các baseline:
- ND (No Discriminator): Không có gradient reversal — latent space không align → drop mạnh ở visual tasks
- NE (No Kinematics Encoder): Không có trajectory encoder — latent kém fine-grained
- NVL (No LeVERB-VL): Direct VL→action không qua high-level policy — chỉ hoạt động khi không cần visual feedback
- NS (No Sampling): Latent space unstructured → near-complete failure (7.5%)
Kết quả nổi bật:
- LeVERB đạt 58.5% overall so với 7.5% của naive baseline → 7.8× improvement
- 80% success trên visual navigation đơn giản (VNF Objective)
- 100% trên locomotion và sitting với language command
- Zero-shot sim-to-real thành công: robot thật đi đến ghế và ngồi xuống dựa trên text instruction
Ablation insights: Điều gì thực sự quan trọng?
Từ ablation studies, có 3 bài học kỹ thuật quan trọng:
1. Discriminator với Gradient Reversal là critical: Khi remove (ND), tổng success rate giảm từ 58.5% xuống 33%. Đặc biệt tệ ở visual tasks như VNF Cluttered (50% → 5%). Không có discriminator, latent từ VL input và language-only input không align → LeVERB-A không generalize sang VL mode.
2. Kinematics Encoder quan trọng nhưng không critical: Khi remove (NE), giảm từ 58.5% → 53%. Encoder giúp latent encode fine-grained temporal structure, đặc biệt quan trọng với unseen scenes.
3. Sampling từ distribution (không phải deterministic) là bắt buộc: Variant NS dùng deterministic CVAE (không sample) → 7.5% success. Lý do: latent space unstructured khi không có variational sampling → không interpolate được, không generalize được.
Hướng cài đặt và tái hiện
Hiện tại LeVERB chưa có public code release. Nhóm có project website tại ember-lab-berkeley.github.io/LeVERB-Website/. Tuy nhiên, bạn có thể tái hiện pipeline tương tự với:
Setup môi trường:
# Isaac Sim 4.x (NVIDIA Omniverse)
# Python 3.10+
pip install torch torchvision # PyTorch 2.x
pip install transformers # SigLIP
pip install onnxruntime # Runtime cho LeVERB-A
Retarget MoCap sang Unitree G1:
# Dùng retargeting package tương thích với SMPL/AMASS format
# Tham khảo: Motion Retargeting trong Isaac Lab
from isaaclab.utils.math import quat_from_euler_xyz
def retarget_humanoid_motion(smpl_poses, target_robot_urdf):
"""
Map SMPL joint rotations sang robot joint angles
thông qua IK và forward kinematics matching.
"""
# 1. Extract joint rotations từ SMPL
# 2. Solve IK cho target robot skeleton
# 3. Verify via forward kinematics
pass
Train LeVERB-VL CVAE:
import torch
import torch.nn as nn
class LeVERBVL(nn.Module):
def __init__(self, latent_dim=256):
super().__init__()
self.latent_dim = latent_dim
# SigLIP vision encoder (frozen)
self.vision_encoder = load_siglip_vitb16(frozen=True)
# Kinematics encoder
self.kinematic_encoder = KinematicsMLP(input_dim=state_dim * horizon)
# CVAE backbone (ViT-Base)
self.vit_backbone = ViTBase(hidden_dim=768, output_dim=512)
# Prior và posterior heads
self.prior_head = nn.Linear(512, latent_dim * 2) # mu, logvar từ VL
self.post_head = nn.Linear(512, latent_dim * 2) # mu, logvar từ kinematic
# Discriminator (với gradient reversal)
self.discriminator = Discriminator(input_dim=latent_dim)
def forward(self, image, text_tokens, state, future_states=None):
# Encode VL
vis_feat = self.vision_encoder(image)
vl_feat = self.vit_backbone(vis_feat, text_tokens, state)
mu_p, logvar_p = self.prior_head(vl_feat).chunk(2, dim=-1)
if future_states is not None:
# Training: encode kinematics
kin_feat = self.kinematic_encoder(future_states)
mu_q, logvar_q = self.post_head(kin_feat).chunk(2, dim=-1)
z = reparameterize(mu_q, logvar_q)
else:
# Inference: sample từ prior
z = reparameterize(mu_p, logvar_p)
return z, mu_p, logvar_p, (mu_q if future_states else None)
Deploy ONNX trên robot:
# Export model sang ONNX
python export_leverb_a.py --checkpoint leverb_a.pth --output leverb_a.onnx
# Verify ONNX model
python -c "import onnxruntime as ort; sess = ort.InferenceSession('leverb_a.onnx'); print('OK')"
# Trên robot (C++ / Python):
# - Subscribe ROS2 topic /leverb_latent_code
# - Forward qua ONNX runtime ở 50 Hz
# - Publish /joint_command
So sánh với các approach khác
| Approach | VL Understanding | WBC Agility | Zero-shot Transfer | Benchmark |
|---|---|---|---|---|
| VLA thuần (π₀, OpenVLA) | ✅ Tốt | ❌ Không có | ✅ Có | Manipulation only |
| WBC thuần (RL controller) | ❌ Không | ✅ Tốt | ✅ Có | Locomotion only |
| WholebodyVLA (ICLR 2026) | ✅ Tốt | ✅ Tốt | Partial | Loco-manipulation |
| LeVERB (UC Berkeley) | ✅ Tốt | ✅ Tốt | ✅ Zero-shot | WBC + VL benchmark |
Điểm khác biệt lớn nhất so với WholebodyVLA (ICLR 2026) là LeVERB không yêu cầu fine-tune WBC policy khi thêm VL understanding. Latent interface tách biệt hoàn toàn — bạn có thể cải tiến LeVERB-VL mà không cần retrain LeVERB-A.
Điểm hạn chế và hướng mở rộng
Paper thành thật về các limitation:
-
Visual Navigation Rear (VNR) vẫn khó: 30% success rate — robot phải quay 180° trước khi di chuyển, và việc maintain spatial awareness trong quá trình quay vẫn chưa ổn định.
-
VNS (Navigation + Sit sequence) chỉ đạt 5%: Chuỗi action dài với nhiều giai đoạn là thách thức lớn nhất. Multi-step reasoning qua latent space chưa được giải quyết tốt.
-
Chưa có manipulation: Benchmark hiện tại tập trung loco-navigation và sitting, chưa bao gồm arm manipulation — vốn là phần khó nhất của humanoid WBC.
-
Chưa public code: Tại thời điểm viết bài, paper chưa release code chính thức.
Hướng phát triển tự nhiên: mở rộng sang bimanual manipulation, multi-step task planning qua chain-of-thought latent verbs, và tích hợp với robot nền tảng ngoài G1.
Tóm tắt kỹ thuật
LeVERB giải quyết bài toán "nói chuyện với robot humanoid" theo cách thực sự khả thi về mặt kỹ thuật:
- Latent verb z_t (256-dim Gaussian) là ngôn ngữ trung gian giữa VL semantic và WBC dynamics
- LeVERB-VL (102M params, 10 Hz) = "não" hiểu ngôn ngữ + nhìn cảnh vật
- LeVERB-A (1.1M params, 50 Hz) = "cơ bắp" thực thi chuyển động
- CVAE + Gradient Reversal = cơ chế quan trọng nhất để align latent space
- 58.5% success rate trên benchmark 150+ tasks, 7.8× so với naive baseline
- Zero-shot sim-to-real thành công trên Unitree G1 thực tế
Đây là bước tiến quan trọng hướng đến humanoid robot thực sự có thể nhận lệnh ngôn ngữ và thực hiện hành động toàn thân phức tạp trong môi trường thực tế.

