SARM targets a real VLA training problem
The standard LeRobot VLA workflow is straightforward: collect demonstrations, save them as a LeRobotDataset, then fine-tune a policy such as ACT, SmolVLA, Pi0, or Pi0.5. This works surprisingly well, but it carries a hidden assumption: every frame in the dataset is equally useful. Real robot data violates that assumption all the time. A single episode may include hesitation, a bad grasp, a teleoperator correction, back-and-forth motion, or a rollout that almost succeeds and then ruins the object state. If behavior cloning gives every frame the same weight, the policy learns both progress-making behavior and noisy behavior.
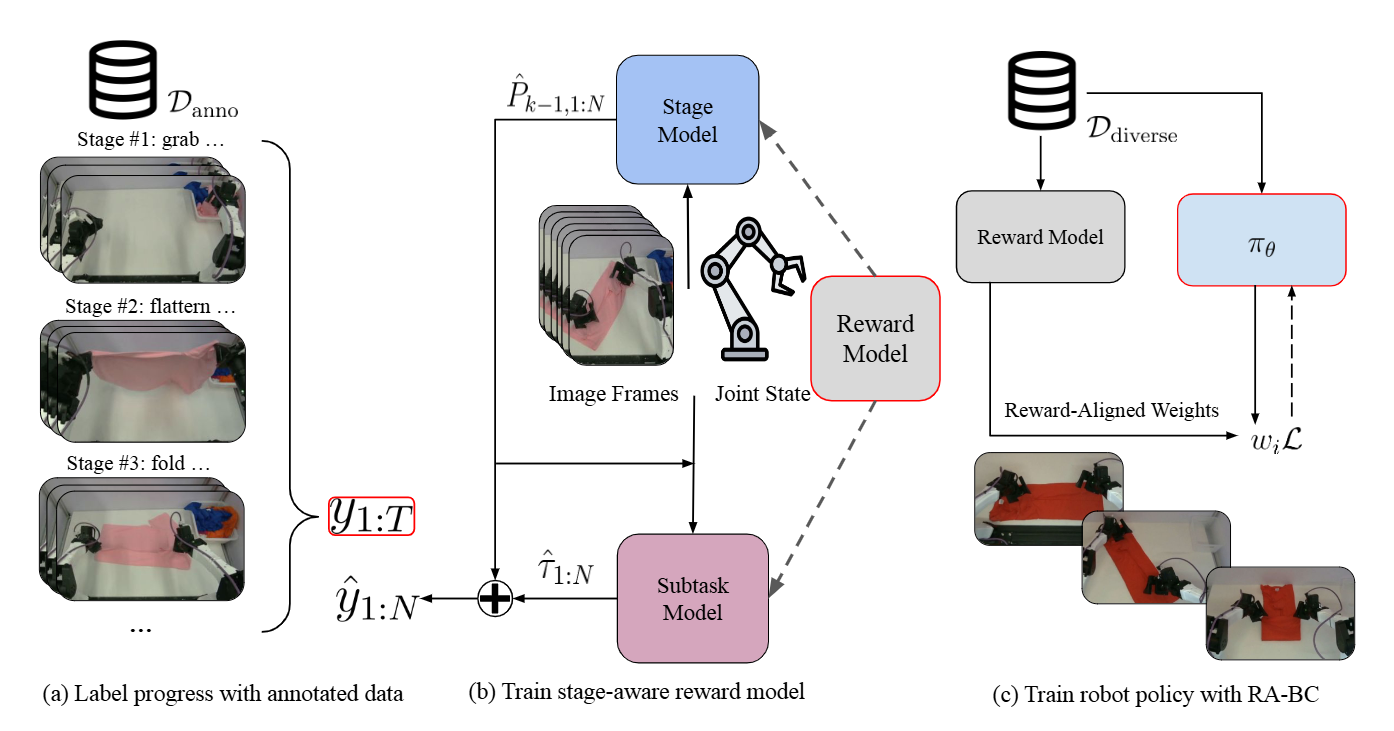
SARM, short for Stage-Aware Reward Modeling, is a video-based reward model for long-horizon robot manipulation. The original paper is SARM: Stage-Aware Reward Modeling for Long Horizon Robot Manipulation, with a project page at qianzhong-chen.github.io/sarm.github.io, open-source code at xdofai/opensarm, and official integration notes in the LeRobot SARM documentation.
The short version: instead of asking “what frame index is this?”, SARM asks “which task stage is the robot in, and how far has it progressed inside that stage?”. Given a short video window, task text, and optional robot state, SARM predicts task progress from 0 to 1. That progress signal can score rollouts, filter poor data, or train a VLA policy through Reward-Aligned Behavior Cloning (RA-BC).
If you are new to this stack, start with VLA & LeRobot framework and training SmolVLA on a consumer GPU. This tutorial focuses on the reward-model layer: how to turn robot videos into a progress signal strong enough to improve a VLA from rollout data.
Why frame-index rewards are brittle
The easiest progress label is frame_index / episode_length. The first frame is 0, the final frame is 1. For a very simple task, such as pushing a cube rightward with clean demonstrations, that can be a usable baseline. For long-horizon manipulation, especially deformable-object tasks such as folding cloth, it breaks in three ways.
First, the same physical state can occur at very different timestamps. Operator A may fold a shirt in 45 seconds. Operator B may need 90 seconds. If progress is normalized time, the same “shirt is flattened” state might be labeled 0.35 in one episode and 0.70 in another. A reward model trained on those labels learns inconsistent supervision.
Second, long tasks have stages. A folding task may require grasping the shirt, moving it to the center, flattening it, folding it, and placing it in the corner. If the model only compares the current frame to the final goal, the early stages are ambiguous. A shirt that has just been flattened is not a failure. It is simply in an earlier stage.
Third, policy rollouts often contain out-of-distribution failure modes: misgrasps, recovery attempts, repeated motions, or a near-complete state that gets destroyed at the end. A reward model must distinguish real progress from motion that merely looks active. The SARM project page shows rollout examples where the model keeps progress low during early misgrasps and reflects progress loss when a failed rollout crumples the shirt again.
SARM replaces raw time labels with stage + within-stage progress:
episode video + task text
|
v
subtask boundaries: stage 0, stage 1, stage 2, ...
|
v
target at each frame = k + tau
k = stage index
tau = progress inside stage k, in [0, 1]
At inference time, LeRobot converts k + tau into normalized progress:
progress_t = P_(k-1) + alpha_k * tau_t
P_(k-1) = cumulative temporal proportion of previous stages
alpha_k = average temporal proportion of stage k in the dataset
tau_t = within-stage progress at time t
The key detail is that alpha_k is computed at the dataset level. This helps the model assign a consistent progress range to states such as “flattening is complete,” even when episodes have different speeds and lengths.
SARM architecture: estimate stage, then progress
SARM does not predict one scalar reward from a single frame. It uses a short observation window with RGB frames, task text, and robot state. In LeRobot, the SARM processor encodes images and text using CLIP ViT-B/32, pads or truncates robot state to a fixed size, and builds targets as sparse_targets and, when needed, dense_targets.
The data flow is easier to remember as a two-head estimator:
RGB frames task text robot state
| | |
v v v
CLIP vision CLIP text state projection
| | |
+------------------+-----------------------+
|
v
temporal estimator
|
+-------------+-------------+
| |
v v
stage estimator subtask estimator
predicts stage k predicts tau in stage
| |
+-------------+-------------+
|
v
normalized progress
The paper describes two main parts: a stage estimator that predicts the current task stage and a subtask estimator that predicts progress within that stage. The stage prediction is passed into the subtask estimator, so the model knows which part of the task it is scoring. This is the major difference from reward models that only compute similarity between the current image and a goal text.
LeRobot exposes three annotation modes:
| Mode | Annotation required? | Heads | Best use |
|---|---|---|---|
single_stage |
No | Sparse only | Short tasks, fast experiments, no VLM |
dense_only |
Dense VLM annotations | Auto sparse + dense | Detailed tracking without manually defining coarse stages |
dual |
Sparse + dense VLM annotations | Dual head | Long tasks with meaningful coarse and fine stages |
For beginners, single_stage is the fastest way to prove the pipeline works. For bimanual folding, cable routing, assembly, or humanoid manipulation with many phases, dual is closer to the full paper setup.
Prepare a LeRobotDataset
SARM does not replace LeRobotDataset; it sits on top of it. At minimum, the dataset needs:
task: a text description such as"fold the towel"or"pick up the red cube"- an image key such as
observation.images.base - a state key, usually
observation.state - episode videos or synchronized image frames with state and action
A typical LeRobot-style dataset looks like this:
my-dataset/
data/
chunk-000/
episode_000000.parquet
episode_000001.parquet
meta/
episodes.jsonl
info.json
stats.json
tasks.jsonl
videos/
chunk-000/
observation.images.base/
episode_000000.mp4
episode_000001.mp4
In the original opensarm repository, the reward column stores scalar progress at each timestep rather than a traditional reinforcement-learning reward. In native LeRobot SARM, progress is commonly precomputed into sarm_progress.parquet, which RA-BC reads during policy training.
Before training the reward model, check the dataset with practical questions:
| Check | Good signal | Failure mode |
|---|---|---|
| Camera placement | Object and end-effector are visible | SARM may learn background artifacts |
| Task text consistency | Same task uses the same wording | Text embeddings become noisy |
| Complete episodes | Beginning and ending are not cut off | Progress labels become distorted |
| Moderate diversity | Speed varies, but episodes are understandable | Model cannot separate progress from noise |
| State shape | observation.state is stable |
Processor must pad or truncate too much |
If you are running real-robot VLA training, you can collect teleop data in LeRobot, then use SARM to score both demonstrations and policy rollouts. For human-in-the-loop real-robot RL, see HIL-SERL in LeRobot. SARM does not replace safety procedures, but it can provide a dense progress signal instead of a sparse success/failure reward.
Install LeRobot with SARM
The official LeRobot docs recommend installing the sarm extra:
git clone https://github.com/huggingface/lerobot
cd lerobot
pip install -e ".[sarm]"
Check that PyTorch can see your GPU:
python - <<'PY'
import torch
print("cuda:", torch.cuda.is_available())
print("device:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "cpu")
PY
The original opensarm repository uses uv:
git clone https://github.com/xdofai/opensarm
cd opensarm
pip install uv
uv sync
source .venv/bin/activate
This tutorial uses native LeRobot commands because they integrate directly with lerobot-train and RA-BC sample weighting. The opensarm repo is still useful for reading the paper-style configuration: n_obs_steps: 8, frame_gap: 30, CLIP checkpoint openai/clip-vit-base-patch32, batch size 32, learning rate 5e-5, and the stage annotations used for T-shirt folding.
Step 1: create or verify subtask annotations
For a quick baseline:
# No annotation is required.
# The whole episode becomes one stage named "task".
# Use this for simple tasks or a first pipeline test.
For long tasks, use a VLM to generate dense annotations. Example for towel folding:
python src/lerobot/data_processing/sarm_annotations/subtask_annotation.py \
--repo-id your-username/your-dataset \
--dense-only \
--dense-subtasks "Bring robot arms up from starting position,Grab near side and do 1st fold,Grab side and do 2nd fold,Grab side and do 3rd fold to finish folding" \
--video-key observation.images.base \
--num-workers 4 \
--push-to-hub
For dual mode, provide both coarse and fine stages:
python src/lerobot/data_processing/sarm_annotations/subtask_annotation.py \
--repo-id your-username/your-dataset \
--sparse-subtasks "Bring arms up from starting position,Fold the towel" \
--dense-subtasks "Bring robot arms up from starting position,Grab near side and do 1st fold,Grab side and do 2nd fold,Grab side and do 3rd fold to finish folding" \
--video-key observation.images.base \
--num-workers 4 \
--push-to-hub
After this step, the dataset contains temporal proportions and subtask boundary columns in its episode metadata or parquet files. Do not skip visualization:
python src/lerobot/data_processing/sarm_annotations/subtask_annotation.py \
--repo-id your-username/your-dataset \
--visualize-only \
--visualize-type both \
--num-visualizations 5 \
--video-key observation.images.base \
--output-dir ./subtask_viz
If the boundaries are off, make the subtask names more specific. “Fold” is too vague. “Grab near side and fold toward center” is better. Annotation quality strongly controls reward-model quality.
Step 2: train the SARM reward model
Fast baseline with single_stage:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=sarm \
--policy.annotation_mode=single_stage \
--policy.image_key=observation.images.base \
--output_dir=outputs/train/sarm_single \
--batch_size=32 \
--steps=5000 \
--wandb.enable=true \
--wandb.project=sarm \
--policy.repo_id=your-username/your-sarm-model
Training with dense annotations:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=sarm \
--policy.annotation_mode=dense_only \
--policy.image_key=observation.images.base \
--output_dir=outputs/train/sarm_dense \
--batch_size=32 \
--steps=5000 \
--wandb.enable=true \
--wandb.project=sarm \
--policy.repo_id=your-username/your-sarm-model
Training with sparse and dense annotations:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=sarm \
--policy.annotation_mode=dual \
--policy.image_key=observation.images.base \
--output_dir=outputs/train/sarm_dual \
--batch_size=32 \
--steps=5000 \
--wandb.enable=true \
--wandb.project=sarm \
--policy.repo_id=your-username/your-sarm-model
Key arguments:
| Argument | Meaning | Practical note |
|---|---|---|
policy.n_obs_steps |
Observation history; total frames are n_obs_steps + 1 |
Default 8 |
policy.frame_gap |
Gap between sampled frames | 30 frames is about 1 second at 30 fps |
policy.image_key |
Camera used for reward training | Choose the camera that sees the task clearly |
policy.state_key |
Robot state vector | Usually observation.state |
batch_size |
Training batch size | 32 if VRAM allows |
For multiple GPUs:
accelerate launch \
--multi_gpu \
--num_processes=4 \
src/lerobot/scripts/lerobot_train.py \
--dataset.repo_id=your-username/your-dataset \
--policy.type=sarm \
--policy.annotation_mode=dual \
--policy.image_key=observation.images.base \
--output_dir=outputs/train/sarm_dual \
--batch_size=32 \
--steps=5000
Step 3: inference, visualization, and rollout scoring
Once you have a model, do not immediately train a policy. Visualize predictions first:
python -m lerobot.rewards.sarm.compute_rabc_weights \
--dataset-repo-id your-username/your-dataset \
--reward-model-path your-username/your-sarm-model \
--visualize-only \
--num-visualizations 5 \
--head-mode sparse \
--output-dir ./sarm_viz
The visualization should show three things: predicted progress, stage probabilities over time, and key frames from the episode. A good reward model does not need to increase perfectly linearly. It should increase when the robot actually makes progress, stay flat during hesitation, and stall or drop when a rollout damages the task state.
When the model looks credible, compute progress for the full dataset:
python -m lerobot.rewards.sarm.compute_rabc_weights \
--dataset-repo-id your-username/your-dataset \
--reward-model-path your-username/your-sarm-model \
--head-mode sparse \
--num-visualizations 5 \
--push-to-hub
The default output is sarm_progress.parquet:
| Column | Meaning |
|---|---|
index |
Global frame index |
episode_index |
Episode number |
frame_index |
Local frame in the episode |
progress_sparse |
Progress from the sparse head |
progress_dense |
Progress from the dense head, if computed |
For new rollouts, save the rollout as a LeRobotDataset and run the same progress computation. This is how SARM helps a VLA improve from rollouts: the policy generates more trajectories, SARM estimates which segments made progress, and RA-BC gives higher weight to useful segments while reducing weight for stagnant or regressive segments. It is not fully autonomous online RL by itself. You still need safety controls, resets, and reward-model validation.
Step 4: train a VLA policy with RA-BC
RA-BC uses progress delta rather than absolute progress. For each training sample, LeRobot compares progress at the current observation and progress after one action chunk:
r_i = phi(o_(t + Delta)) - phi(o_t)
phi = SARM progress prediction
Delta = policy chunk_size
If r_i is positive, that segment moves the task forward. If it is negative, the robot made the state worse. If it is near zero, the robot may be stalled or moving without useful progress.
Train Pi0 with RA-BC:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=pi0 \
--sample_weighting.type=rabc \
--sample_weighting.head_mode=sparse \
--sample_weighting.kappa=0.01 \
--output_dir=outputs/train/policy_rabc \
--batch_size=32 \
--steps=40000
According to the current LeRobot docs, RA-BC supports Pi0, Pi0.5, and SmolVLA. For an edge-friendly VLA experiment, use SmolVLA with the same sample weighting:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=smolvla \
--sample_weighting.type=rabc \
--sample_weighting.head_mode=sparse \
--sample_weighting.kappa=0.01 \
--output_dir=outputs/train/smolvla_rabc \
--batch_size=32 \
--steps=40000
The weighting rules are simple:
| Condition | Weight |
|---|---|
delta > kappa |
1.0 |
0 <= delta <= kappa |
Soft weight from running mean/std |
delta < 0 |
0.0 |
Monitor these metrics:
| Metric | Healthy range | Problem signal |
|---|---|---|
sample_weight_mean_weight |
0.3-0.8 | Near 1.0 means kappa is too low |
sample_weighting/delta_mean |
> 0 | Negative values suggest dataset or reward issues |
sample_weighting/delta_std |
> 0 | Too low means reward cannot separate good and bad data |
The default kappa=0.01 was tuned for a roughly 90-second T-shirt folding task at 30 fps. For your own dataset, inspect delta_mean and delta_std. If almost every sample gets full weight, RA-BC becomes close to vanilla BC. If almost no sample gets weight, training lacks useful supervision.
Results from the paper
The SARM paper evaluates T-shirt folding, a hard long-horizon task because cloth is deformable. Vanilla BC achieves 8% success from the flattened state and 0% from the crumpled state. With SARM + RA-BC, the policy reaches 83% success on the medium task and 67% on the hard task. In the appendix rollout table, at 40K training steps, RA-BC with SARM reaches 10/12 on medium and 8/12 on hard, outperforming RA-BC with a ReWiND reward model.
The important lesson is not just the headline success rate. The paper also shows that reward-model quality is central. If the reward model misjudges progress, RA-BC assigns bad sample weights, the policy learns the wrong behavior, and the filtering benefit disappears. A reliable workflow is:
1. Train SARM
2. Visualize predictions on demonstrations
3. Score a few policy rollouts
4. Compare scores against human judgment
5. Train RA-BC only when the reward looks reasonable
For your own robot, build a small benchmark:
| Run | Policy | Dataset | Reward weighting | Success |
|---|---|---|---|---|
| A | SmolVLA | clean demos | none | baseline |
| B | SmolVLA | demos + rollouts | none | tests whether rollout data hurts |
| C | SmolVLA | demos + rollouts | SARM RA-BC | expected improvement |
| D | Pi0/Pi0.5 | demos + rollouts | SARM RA-BC | larger model comparison |
If C does not beat B, do not immediately conclude that SARM is useless. Check annotation boundaries, camera view, head_mode, kappa, and rollout distribution. Reward modeling only helps when it can distinguish real progress from noisy motion.
Beginner implementation checklist
Start small:
Day 1:
- Collect 30-50 demonstrations for one clear task
- Train SARM single_stage for 5k steps
- Visualize 5 episodes
Day 2:
- If the task has multiple stages, add dense_only annotation
- Retrain SARM
- Generate sarm_progress.parquet
Day 3:
- Train SmolVLA/Pi0 with vanilla BC
- Train the same policy with RA-BC
- Run 20 real or simulated rollouts
Common failure modes:
| Failure | Symptom | Fix |
|---|---|---|
| Progress rises like a clock | Model learned time, not task state | Add speed diversity and stage annotations |
| Progress jumps randomly | Camera or annotation is poor | Change camera or visualize boundaries |
| RA-BC matches BC | Mean weight is near 1.0 | Increase kappa |
| RA-BC becomes unstable | Too few samples get weight | Lower kappa or add good demos |
| Failed rollouts score high | Reward model has not seen failures | Add failure rollouts to validation and retrain |
On a real robot, treat SARM as a progress meter, not a safety system. Workspace limits, emergency stop, human intervention, and staged testing remain mandatory.
Conclusion
SARM fills a missing layer in VLA training: estimating task progress from video instead of treating every frame equally. In LeRobot, the workflow is now practical: install the SARM extra, create subtask annotations when needed, train the reward model, visualize predictions, precompute progress, and train Pi0, Pi0.5, or SmolVLA with RA-BC.
The strongest idea is stage awareness. Long-horizon tasks are not one smooth line from start to finish; they are sequences of meaningful stages. SARM makes that structure explicit, which is why it fits folding, assembly, bimanual manipulation, and whole-body VLA tasks with multiple phases. Its weakness is that reward quality depends heavily on camera placement, annotations, and rollout distribution. Used carefully, it is one of the most practical open-source ways to convert messy rollouts into useful learning signal for VLA policies.


