SARM giải quyết đúng điểm đau của VLA
Khi train VLA trong LeRobot, pipeline cơ bản thường là: thu thập demonstrations, lưu thành LeRobotDataset, rồi fine-tune một policy như ACT, SmolVLA, Pi0 hoặc Pi0.5. Cách này đơn giản và rất mạnh, nhưng có một giả định ẩn: mọi frame trong dataset đều đáng học như nhau. Thực tế không như vậy. Một episode có thể chứa hesitation, robot cầm trượt, người teleop sửa hướng, vật thể bị kéo ngược, hoặc rollout gần thành công rồi thất bại ở cuối. Nếu policy học tất cả frame với trọng số bằng nhau, nó học cả hành vi tốt lẫn hành vi làm chậm tiến độ.
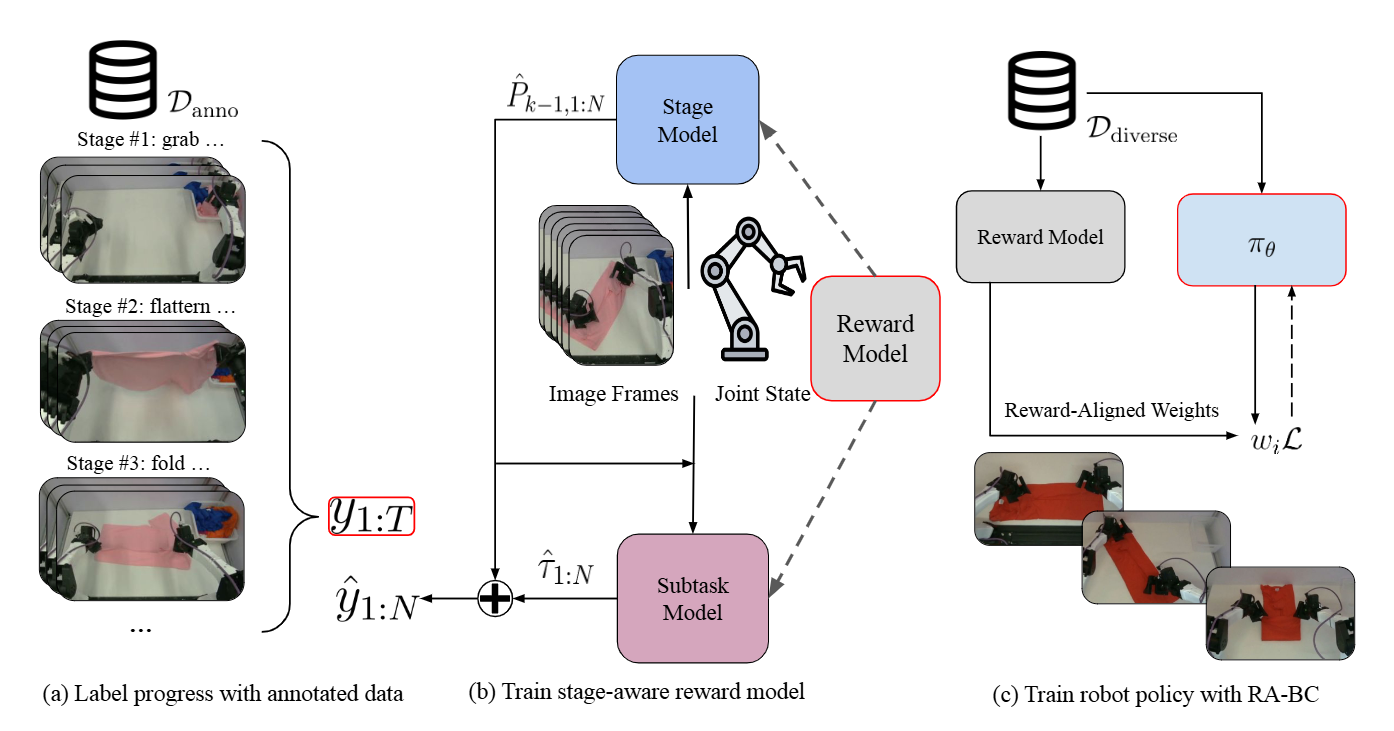
SARM, viết tắt của Stage-Aware Reward Modeling, là một reward model video-based cho long-horizon robot manipulation. Paper gốc là SARM: Stage-Aware Reward Modeling for Long Horizon Robot Manipulation, được nhóm Stanford, UC Berkeley và xdof.ai công bố, project page ở qianzhong-chen.github.io/sarm.github.io, code open-source tại xdofai/opensarm, và hiện đã có hướng dẫn chính thức trong LeRobot docs.
Ý tưởng ngắn gọn: thay vì hỏi “frame này ở giây thứ mấy của episode?”, SARM hỏi “robot đang ở stage nào của task, và đã đi được bao nhiêu phần trăm trong stage đó?”. Với một cửa sổ video ngắn, task text và robot state, SARM dự đoán task progress từ 0 đến 1. Tín hiệu này có thể dùng để chấm điểm rollout, lọc dữ liệu kém, hoặc train VLA bằng Reward-Aligned Behavior Cloning (RA-BC).
Nếu bạn mới bắt đầu với LeRobot, nên đọc trước VLA & LeRobot framework và bài train SmolVLA trên consumer GPU. Bài này tập trung vào reward model: làm sao biến video robot thành progress signal đủ ổn để policy tự cải thiện từ dữ liệu rollout.
Vì sao frame index reward không đủ?
Một cách gán progress rất dễ là lấy frame_index / episode_length. Frame đầu là 0, frame cuối là 1. Với task đơn giản như “đẩy cube sang phải” và demo rất sạch, cách này tạm dùng được. Nhưng với long-horizon manipulation, đặc biệt task deformable như gấp áo, nó sai ở ba điểm.
Thứ nhất, cùng một trạng thái vật lý có thể xuất hiện ở các thời điểm khác nhau. Operator A gấp áo nhanh trong 45 giây, operator B loay hoay 90 giây. Nếu dùng normalized time, cùng một trạng thái “áo đã được flatten” có thể bị gán progress 0.35 ở demo này và 0.70 ở demo kia. Reward model học từ label như vậy sẽ nhiễu.
Thứ hai, task dài có nhiều stage. Với gấp áo, robot phải lấy áo, đưa vào trung tâm, flatten, fold, rồi đặt áo gấp vào góc. Nếu chỉ nhìn khoảng cách đến goal cuối, reward trong các stage đầu rất mơ hồ. Robot flatten áo tốt nhưng chưa fold thì không phải failure. Nó chỉ đang ở stage trước.
Thứ ba, rollout của policy thường có lỗi ngoài phân phối demo: misgrasp, back-and-forth motion, kéo áo lệch, hoặc gần xong rồi làm hỏng. Reward model cần nhận ra “tiến bộ thật” và “chuyển động nhiều nhưng không tiến bộ”. Paper SARM cho thấy model vẫn có thể giữ progress thấp trong các đoạn misgrasp ban đầu, và phản ánh hợp lý khi rollout thất bại làm task bị lùi.
SARM thay label theo thời gian bằng label theo stage + within-stage progress:
episode video + task text
|
v
subtask boundaries: stage 0, stage 1, stage 2, ...
|
v
target tại mỗi frame = k + tau
k = stage index
tau = progress trong stage k, nằm trong [0, 1]
Khi inference, giá trị k + tau được đổi thành progress chuẩn hóa:
progress_t = P_(k-1) + alpha_k * tau_t
P_(k-1) = tổng temporal proportion của các stage trước
alpha_k = tỷ lệ thời lượng trung bình của stage k trong dataset
tau_t = progress nội bộ trong stage k
Điểm quan trọng là alpha_k được tính ở mức dataset. Nhờ vậy, SARM học rằng “flatten xong” tương ứng một vùng progress ổn định, dù episode nhanh hay chậm.
Kiến trúc SARM: stage trước, progress sau
SARM không cố dự đoán một scalar reward trực tiếp từ một frame đơn lẻ. Nó dùng một cửa sổ quan sát gồm nhiều RGB frames, task text và tùy chọn robot state. Trong LeRobot, processor của SARM encode ảnh và text bằng CLIP ViT-B/32, pad hoặc truncate state về kích thước cố định, rồi tạo target dạng sparse_targets và có thể thêm dense_targets.
Luồng chính có thể hình dung như sau:
RGB frames task text robot state
| | |
v v v
CLIP vision CLIP text state projection
| | |
+------------------+-----------------------+
|
v
temporal estimator
|
+-------------+-------------+
| |
v v
stage estimator subtask estimator
predicts stage k predicts tau in stage
| |
+-------------+-------------+
|
v
normalized progress
Paper mô tả hai thành phần chính: stage estimator dự đoán stage hiện tại, và subtask estimator dự đoán scalar progress trong stage đó. Dự đoán stage được đưa vào subtask estimator để model biết mình đang chấm phần nào của task. Đây là khác biệt lớn so với reward model chỉ dựa trên similarity giữa ảnh hiện tại và goal text.
Trong LeRobot, bạn có ba annotation mode:
| Mode | Cần annotation? | Head dùng | Khi nào dùng |
|---|---|---|---|
single_stage |
Không | Sparse only | Task ngắn, thử nhanh, không cần VLM |
dense_only |
Dense từ VLM | Sparse auto + dense | Muốn tracking chi tiết nhưng không chia stage lớn |
dual |
Sparse + dense từ VLM | Dual head | Task dài, nhiều stage rõ ràng |
Với beginner, single_stage là cách bắt đầu nhanh nhất. Nhưng nếu task của bạn là bimanual folding, cable routing, assembly hoặc humanoid manipulation nhiều bước, dual mới là cấu hình gần với paper.
Chuẩn bị dataset LeRobot
SARM không thay thế LeRobotDataset; nó ngồi trên dataset đó. Dataset tối thiểu cần có:
task: mô tả nhiệm vụ bằng text, ví dụ"fold the towel"hoặc"pick up the red cube"- image key, ví dụ
observation.images.base - state key, thường là
observation.state - episode video hoặc image frames đồng bộ với action/state
Một cấu trúc dataset kiểu LeRobot thường như sau:
my-dataset/
data/
chunk-000/
episode_000000.parquet
episode_000001.parquet
meta/
episodes.jsonl
info.json
stats.json
tasks.jsonl
videos/
chunk-000/
observation.images.base/
episode_000000.mp4
episode_000001.mp4
Trong repo opensarm, cột reward được dùng như scalar progress tại timestep, không nhất thiết là reward RL theo nghĩa truyền thống. Trong LeRobot native SARM, progress thường được tính ra file sarm_progress.parquet để RA-BC đọc lại khi train policy.
Trước khi train reward model, hãy kiểm tra dataset bằng các câu hỏi rất thực dụng:
| Kiểm tra | Dấu hiệu tốt | Nếu sai thì sao |
|---|---|---|
| Camera cố định | Vật thể và end-effector nhìn rõ | SARM học nhầm background |
| Task text nhất quán | Cùng task dùng cùng mô tả | Text embedding bị phân tán |
| Episode có đủ stage | Không cắt cụt đoạn đầu/cuối | Progress label méo |
| Demo đa dạng vừa phải | Có tốc độ khác nhau nhưng không quá hỗn loạn | Model khó phân biệt progress thật |
| State đúng shape | observation.state ổn định |
Processor pad/truncate quá nhiều |
Nếu đang làm VLA trên robot thật, bạn có thể dùng workflow teleop trong LeRobot, sau đó dùng SARM để chấm lại demo và rollout. Với real-robot RL có human intervention, xem thêm HIL-SERL trong LeRobot. SARM không thay thế human safety loop, nhưng nó giúp bạn có dense progress signal thay vì reward sparse “thành công/thất bại”.
Cài đặt LeRobot với SARM
LeRobot docs khuyến nghị cài extra dependency sarm:
git clone https://github.com/huggingface/lerobot
cd lerobot
pip install -e ".[sarm]"
Kiểm tra GPU và package cơ bản:
python - <<'PY'
import torch
print("cuda:", torch.cuda.is_available())
print("device:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "cpu")
PY
Với repo gốc opensarm, workflow cài đặt dùng uv:
git clone https://github.com/xdofai/opensarm
cd opensarm
pip install uv
uv sync
source .venv/bin/activate
Trong bài này, ta ưu tiên LeRobot native vì lệnh tích hợp trực tiếp với lerobot-train và RA-BC. Repo opensarm vẫn hữu ích nếu bạn muốn đọc config paper, ví dụ n_obs_steps: 8, frame_gap: 30, CLIP checkpoint openai/clip-vit-base-patch32, batch size 32, learning rate 5e-5, và các stage annotation của task T-shirt folding.
Bước 1: tạo hoặc kiểm tra subtask annotations
Nếu chỉ muốn thử nhanh:
# Không cần annotation. Toàn episode là một stage "task".
# Sử dụng khi task đơn giản hoặc khi bạn muốn baseline nhanh.
Với task dài, dùng VLM để tạo dense annotation. Ví dụ với towel folding:
python src/lerobot/data_processing/sarm_annotations/subtask_annotation.py \
--repo-id your-username/your-dataset \
--dense-only \
--dense-subtasks "Bring robot arms up from starting position,Grab near side and do 1st fold,Grab side and do 2nd fold,Grab side and do 3rd fold to finish folding" \
--video-key observation.images.base \
--num-workers 4 \
--push-to-hub
Với mode dual, bạn khai báo cả stage lớn và stage nhỏ:
python src/lerobot/data_processing/sarm_annotations/subtask_annotation.py \
--repo-id your-username/your-dataset \
--sparse-subtasks "Bring arms up from starting position,Fold the towel" \
--dense-subtasks "Bring robot arms up from starting position,Grab near side and do 1st fold,Grab side and do 2nd fold,Grab side and do 3rd fold to finish folding" \
--video-key observation.images.base \
--num-workers 4 \
--push-to-hub
Sau bước này, dataset có thêm temporal proportions và các cột subtask boundary trong episode metadata/parquet. Đừng bỏ qua bước visualize:
python src/lerobot/data_processing/sarm_annotations/subtask_annotation.py \
--repo-id your-username/your-dataset \
--visualize-only \
--visualize-type both \
--num-visualizations 5 \
--video-key observation.images.base \
--output-dir ./subtask_viz
Nếu boundary bị lệch, hãy sửa tên subtask cụ thể hơn. “Fold” quá mơ hồ; “grab near side and fold toward center” tốt hơn. Annotation tốt quyết định chất lượng reward model.
Bước 2: train SARM reward model
Baseline nhanh với single_stage:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=sarm \
--policy.annotation_mode=single_stage \
--policy.image_key=observation.images.base \
--output_dir=outputs/train/sarm_single \
--batch_size=32 \
--steps=5000 \
--wandb.enable=true \
--wandb.project=sarm \
--policy.repo_id=your-username/your-sarm-model
Train với dense annotation:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=sarm \
--policy.annotation_mode=dense_only \
--policy.image_key=observation.images.base \
--output_dir=outputs/train/sarm_dense \
--batch_size=32 \
--steps=5000 \
--wandb.enable=true \
--wandb.project=sarm \
--policy.repo_id=your-username/your-sarm-model
Train với đầy đủ sparse + dense:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=sarm \
--policy.annotation_mode=dual \
--policy.image_key=observation.images.base \
--output_dir=outputs/train/sarm_dual \
--batch_size=32 \
--steps=5000 \
--wandb.enable=true \
--wandb.project=sarm \
--policy.repo_id=your-username/your-sarm-model
Các tham số nên hiểu trước khi chạy:
| Tham số | Ý nghĩa | Gợi ý |
|---|---|---|
policy.n_obs_steps |
Số bước quan sát lịch sử, tổng frame là n_obs_steps + 1 |
Mặc định 8 |
policy.frame_gap |
Khoảng cách giữa frame được sample | 30 frame ≈ 1 giây nếu dataset 30 fps |
policy.image_key |
Camera dùng để train reward model | Chọn camera nhìn rõ task |
policy.state_key |
State vector | Thường là observation.state |
batch_size |
Batch size training | 32 nếu GPU đủ VRAM |
Nếu có nhiều GPU:
accelerate launch \
--multi_gpu \
--num_processes=4 \
src/lerobot/scripts/lerobot_train.py \
--dataset.repo_id=your-username/your-dataset \
--policy.type=sarm \
--policy.annotation_mode=dual \
--policy.image_key=observation.images.base \
--output_dir=outputs/train/sarm_dual \
--batch_size=32 \
--steps=5000
Bước 3: inference, visualize và chấm điểm rollout
Sau khi có model, bước đầu tiên không phải train policy ngay. Hãy visualize prediction:
python -m lerobot.rewards.sarm.compute_rabc_weights \
--dataset-repo-id your-username/your-dataset \
--reward-model-path your-username/your-sarm-model \
--visualize-only \
--num-visualizations 5 \
--head-mode sparse \
--output-dir ./sarm_viz
Visualization nên cho bạn thấy ba thứ: đường predicted progress, xác suất stage theo thời gian, và các key frames trong episode. Một reward model tốt không nhất thiết phải tăng tuyến tính mượt. Nó nên tăng khi robot thật sự tiến bộ, đứng yên khi robot loay hoay, và có thể giảm hoặc chững lại khi rollout làm hỏng trạng thái.
Khi đã tin model đủ ổn, tính progress cho toàn dataset:
python -m lerobot.rewards.sarm.compute_rabc_weights \
--dataset-repo-id your-username/your-dataset \
--reward-model-path your-username/your-sarm-model \
--head-mode sparse \
--num-visualizations 5 \
--push-to-hub
Output mặc định là sarm_progress.parquet, gồm các cột như:
| Cột | Ý nghĩa |
|---|---|
index |
Global frame index |
episode_index |
Episode number |
frame_index |
Frame trong episode |
progress_sparse |
Progress từ sparse head |
progress_dense |
Progress từ dense head nếu có |
Với rollout mới, bạn có thể ghi rollout thành LeRobotDataset rồi chạy lại script này để chấm điểm. Đây là cách SARM giúp VLA “tự cải thiện từ rollout”: policy tạo thêm trajectories, SARM ước lượng đoạn nào tạo progress, RA-BC tăng trọng số cho segment tốt và giảm trọng số cho segment đứng yên hoặc regress. Nó không phải phép màu online RL hoàn toàn tự động; bạn vẫn cần kiểm soát an toàn, reset môi trường, và kiểm tra reward model.
Bước 4: train VLA với RA-BC
RA-BC dùng progress delta thay vì progress tuyệt đối. Với mỗi sample, LeRobot so sánh progress ở observation hiện tại và observation sau một action chunk:
r_i = phi(o_(t + Delta)) - phi(o_t)
phi = SARM progress prediction
Delta = policy chunk_size
Nếu r_i dương, segment đó giúp task tiến lên. Nếu r_i âm, robot đang làm task tệ đi. Nếu gần 0, robot có thể đang đứng yên hoặc chuyển động không hữu ích.
Train Pi0 với RA-BC trong LeRobot:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=pi0 \
--sample_weighting.type=rabc \
--sample_weighting.head_mode=sparse \
--sample_weighting.kappa=0.01 \
--output_dir=outputs/train/policy_rabc \
--batch_size=32 \
--steps=40000
Theo docs hiện tại, RA-BC hỗ trợ Pi0, Pi0.5 và SmolVLA. Nếu bạn đang làm edge-friendly VLA, có thể thay --policy.type=pi0 bằng policy phù hợp như SmolVLA, rồi giữ sample weighting:
lerobot-train \
--dataset.repo_id=your-username/your-dataset \
--policy.type=smolvla \
--sample_weighting.type=rabc \
--sample_weighting.head_mode=sparse \
--sample_weighting.kappa=0.01 \
--output_dir=outputs/train/smolvla_rabc \
--batch_size=32 \
--steps=40000
Logic weighting:
| Điều kiện | Trọng số |
|---|---|
delta > kappa |
1.0 |
0 <= delta <= kappa |
soft weight theo running mean/std |
delta < 0 |
0.0 |
Hãy theo dõi các metric:
| Metric | Range khỏe | Vấn đề |
|---|---|---|
sample_weight_mean_weight |
0.3-0.8 | Gần 1.0 nghĩa là kappa quá thấp |
sample_weighting/delta_mean |
> 0 | Nếu âm, dataset hoặc reward model có vấn đề |
sample_weighting/delta_std |
> 0 | Nếu quá thấp, reward không phân biệt data tốt/xấu |
kappa=0.01 là default được tune cho T-shirt folding khoảng 90 giây ở 30 fps. Với dataset khác, hãy nhìn delta_mean và delta_std. Nếu phần lớn sample đều full weight, RA-BC gần như trở thành vanilla BC. Nếu quá ít sample có weight, training thiếu dữ liệu.
Kết quả paper: vì sao đáng thử?
Paper SARM đánh giá trên T-shirt folding, một task dài và khó vì áo là deformable object. Vanilla BC đạt 8% success từ trạng thái flattened và 0% từ trạng thái crumpled. Khi dùng SARM + RA-BC, policy đạt 83% success ở medium task và 67% ở hard task. Trong appendix, bảng rollout ở 40K steps cho thấy RA-BC với SARM đạt 10/12 ở medium và 8/12 ở hard, tốt hơn RA-BC dùng ReWiND reward model.
Điều đáng chú ý không chỉ là con số success rate. Paper cũng chỉ ra reward model chất lượng thấp làm RA-BC yếu đi rõ rệt. Nếu reward model chấm sai progress, sample weighting sẽ sai, policy học lệch, và lợi ích lọc dữ liệu biến mất. Vì vậy, workflow đúng là:
1. Train SARM
2. Visualize prediction trên demo
3. Chấm rollout thử
4. So sánh với human judgment
5. Chỉ khi reward hợp lý mới train RA-BC
Với task của bạn, hãy tạo một bảng benchmark nhỏ:
| Run | Policy | Dataset | Reward weighting | Success |
|---|---|---|---|---|
| A | SmolVLA | demo sạch | none | baseline |
| B | SmolVLA | demo + rollout | none | xem rollout có làm hại không |
| C | SmolVLA | demo + rollout | SARM RA-BC | kỳ vọng tốt hơn |
| D | Pi0/Pi0.5 | demo + rollout | SARM RA-BC | so với model lớn |
Nếu C không hơn B, đừng vội kết luận SARM vô dụng. Hãy kiểm tra annotation boundary, camera view, head_mode, kappa, và distribution rollout. Reward model chỉ giúp khi nó phân biệt được progress thật.
Checklist thực chiến cho beginner
Bạn có thể bắt đầu bằng phiên bản nhỏ:
Ngày 1:
- Thu 30-50 demo cho một task rõ ràng
- Train SARM single_stage 5k steps
- Visualize 5 episode
Ngày 2:
- Nếu task nhiều stage, thêm dense_only annotation
- Train lại SARM
- Tạo sarm_progress.parquet
Ngày 3:
- Train SmolVLA/Pi0 vanilla BC
- Train cùng policy với RA-BC
- Chạy 20 rollout thật hoặc simulation
Các lỗi thường gặp:
| Lỗi | Triệu chứng | Cách sửa |
|---|---|---|
| Progress tăng đều như clock | Model học time, không học task | Tăng diversity tốc độ, dùng stage annotation |
| Progress nhảy lung tung | Camera mờ hoặc annotation sai | Chọn camera khác, visualize boundary |
| RA-BC không khác BC | Mean weight gần 1.0 | Tăng kappa |
| RA-BC train không ổn | Quá ít sample có weight | Giảm kappa, thêm demo tốt |
| Rollout failure vẫn được reward cao | Reward model chưa thấy failure | Thêm rollout failure vào validation, retrain |
Khi triển khai trên robot thật, hãy coi SARM là “bộ đo tiến độ”, không phải bộ đảm bảo an toàn. Workspace bounds, emergency stop, human intervention và kiểm thử từng bước vẫn bắt buộc.
Kết luận
SARM đưa reward modeling vào đúng chỗ còn thiếu của VLA training: đánh giá tiến độ task từ video thay vì đối xử mọi frame như nhau. Trong LeRobot, nó đã trở thành một workflow khá rõ: cài extra dependency, tạo subtask annotation nếu cần, train SARM, visualize prediction, precompute progress, rồi train Pi0/Pi0.5/SmolVLA với RA-BC.
Điểm mạnh của SARM là stage-aware. Nó hiểu long-horizon task theo từng đoạn, nên phù hợp với folding, assembly, bimanual manipulation và các bài toán whole-body VLA có nhiều phase. Điểm yếu là chất lượng reward phụ thuộc mạnh vào camera, annotation và distribution rollout. Nếu làm cẩn thận, SARM là một trong những cách thực dụng nhất hiện nay để biến rollout hỗn tạp thành tín hiệu học có ích cho VLA.


