Imagine you're teaching a robot to fold clothes. It fails — you grab its hand and correct it. But you're not a robotics expert; your correction is a bit clumsy, not perfectly optimal. Can the robot still learn something useful from that imperfect intervention?
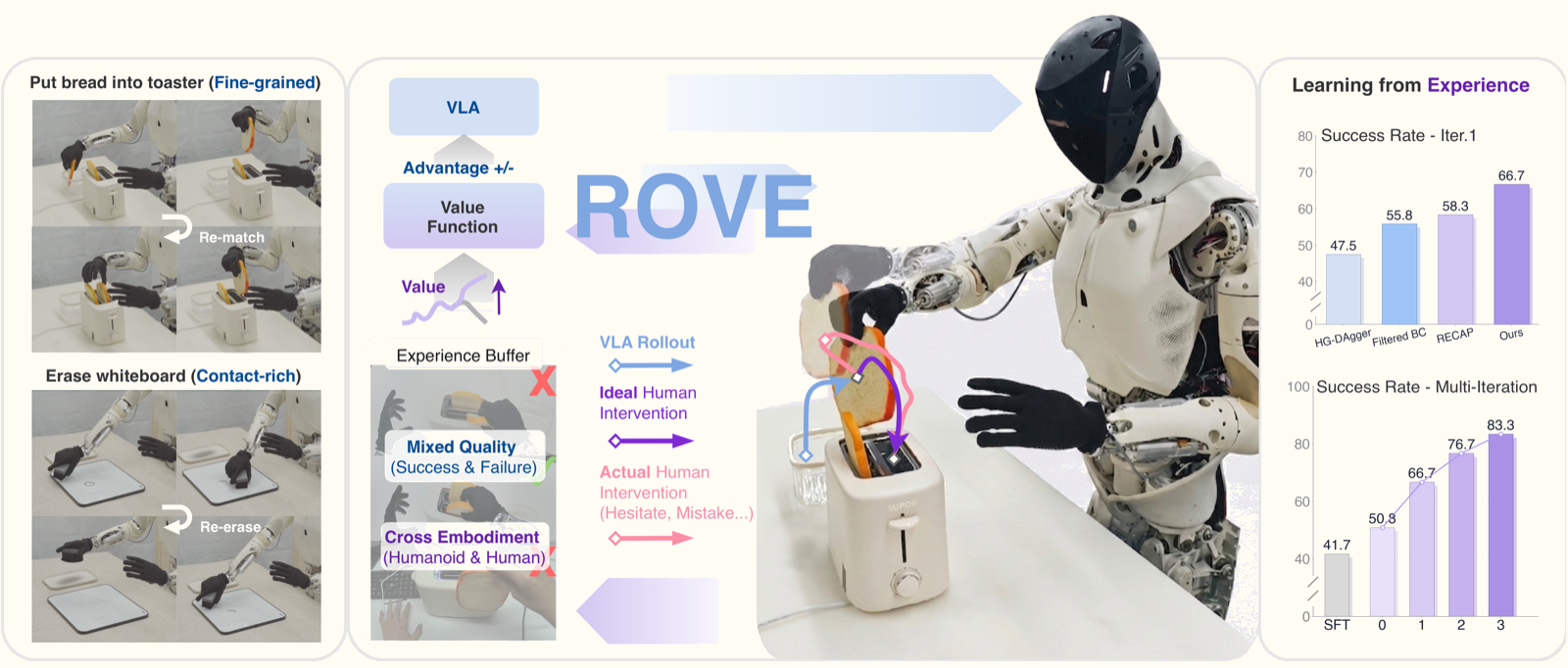
This is exactly the problem ROVE (Reinforcement Learning with Optimistic Value Estimation) from XPENG Robotics addresses. Published on arXiv in June 2026, the paper introduces a new direction for training dexterous humanoid manipulation: instead of simply imitating good data, the robot learns to extract high-value behaviors from mixed-quality trajectories.
The Core Problem: Human Interventions Are Imperfect
In robotics, "human-in-the-loop" (HITL) is a popular technique: when the robot struggles, an operator intervenes and corrects it. This intervention data is then used to train a better policy.
That sounds straightforward — but with dexterous-hand humanoids, it becomes far more complex:
-
Teleoperation gap: Operators use VR headsets + motion capture to control the robot. But the human hand and robot hand differ drastically in structure, with no haptic (force) feedback. Every movement gets "translated" imperfectly into the robot's joint space.
-
Intervention actions are often suboptimal: When saving the robot, operators act quickly, awkwardly, not following the optimal path. If the robot learns to blindly imitate everything, it will also learn bad behaviors.
-
50 degrees of freedom: XPENG's IRON-R01-1.11 robot has a 50-dimensional proprioceptive state (body joints + dexterous hands). Controlling this entire chain via VR is a massive engineering challenge.
What Is ROVE? The Overall Framework
ROVE is a post-training RL framework — it does not train a VLA from scratch, but rather fine-tunes an existing VLA policy using newly collected intervention data.
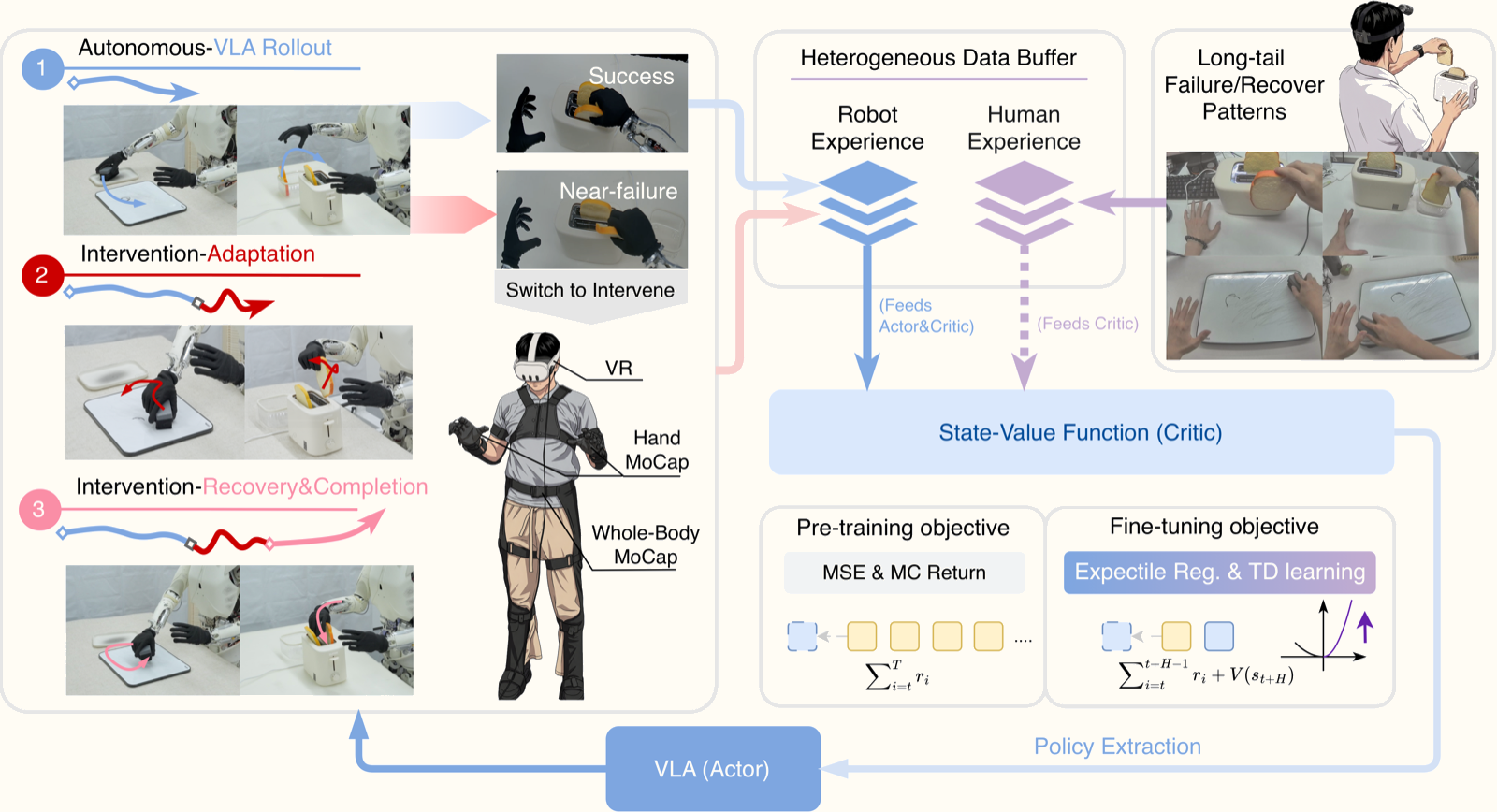
Three core components:
1. Human-in-the-Loop Data Collection Pipeline
Each episode is split into three phases:
- Autonomous rollout: The VLA policy runs independently, completing as much of the task as possible.
- Intervention-adaptation phase: When the policy is about to fail, an operator takes over. The system detects "failure boundaries" conservatively to intervene before complete collapse.
- Intervention-recovery phase: Once the operator stabilizes the situation, the VLA continues completing the remainder of the task.
A key detail: the system uses a command filter to smooth the handover of control — preventing abrupt joint jerks that could damage the robot or introduce noisy data.
2. Optimistic Value Estimation (OVE)
This is the core theoretical contribution. The fundamental question: how do you evaluate which actions are "worth learning" from mixed-quality data?
OVE uses expectile regression to estimate a value function biased toward higher values:
$$\mathcal{L}_{OVE}(\phi) = \mathbb{E}\left[|\tau - \mathbf{1}{\hat{V}t - V\phi(s_t) < 0}|(\hat{V}t - V\phi(s_t))^2\right]$$
Where:
- $\hat{V}t = \sum{i=t}^{t+H-1} \gamma^{i-t} r_i + \gamma^H V_{\bar{\phi}}(s_{t+H})$ is the H-step bootstrapped value target
- $\tau \in (0.5, 1)$ controls the "degree of optimism" — closer to 1 means the critic is more biased toward high-value trajectories
Default parameters: $\tau = 0.7$, $H = 16$ steps for inference/advantage, $H = 50$ for training.
The key advantage over Monte-Carlo regression (imitating everything): OVE does not need to query out-of-distribution actions because it operates on a value function rather than a Q-function, sidestepping the classical offline RL distribution shift problem.
3. Advantage-Conditioned Policy Extraction
After training the critic, ROVE computes the advantage for each step:
$$A_{\phi_k} = \sum \text{rewards} + \gamma^H V_{\phi_k}(s_{t+H}) - V_{\phi_k}(s_t)$$
Steps receive binary labels: "improvement" if the advantage exceeds the 70th percentile threshold, "no improvement" otherwise. The actor is then fine-tuned via advantage-conditioned behavior cloning — learning only from steps labeled "improvement."
At inference, classifier-free guidance decoding is applied:
$$v_{cfg} = v_{neg} + \beta(v_{pos} - v_{neg})$$
This steers generation toward high-advantage actions without requiring any changes to the network architecture.
The ROVE Training Loop: Step by Step
Here is the complete algorithm from Algorithm 1 in the paper:
Initialization:
- Initial policy $\pi_0$ (a VLA pre-trained on demonstrations)
- Demonstration dataset $\mathcal{D}^0_{critic}$
Iterate $k = 1, 2, 3$:
- Train critic $V_{\phi_k}$ on $\mathcal{D}^k_{critic}$ using the OVE objective
- Compute advantages for all transitions in the dataset
- Assign binary labels using the 70th percentile threshold
- Fine-tune actor $\pi_{k+1}$ from $\pi_k$ via advantage-conditioned BC
- Deploy $\pi_{k+1}$, collect new episodes + interventions → create $\mathcal{D}^{k+1}_{critic}$
Each iteration corresponds to roughly one real-robot data collection session.
Cross-Embodiment Learning: Learning from Human Videos
Another compelling aspect of ROVE: it incorporates 180 egocentric human videos per task. These videos capture humans performing similar manipulations, used to supervise value estimation — especially valuable for long-tailed failure scenarios.
Why does this work? Because human hand postures during recovery situations carry information about the structure of the problem — the robot can learn "when to do what" from this data, even though the robot and human body differ significantly.
Experiments: Two Challenging Real-World Tasks
Task 1: Erase the Whiteboard (contact-rich)
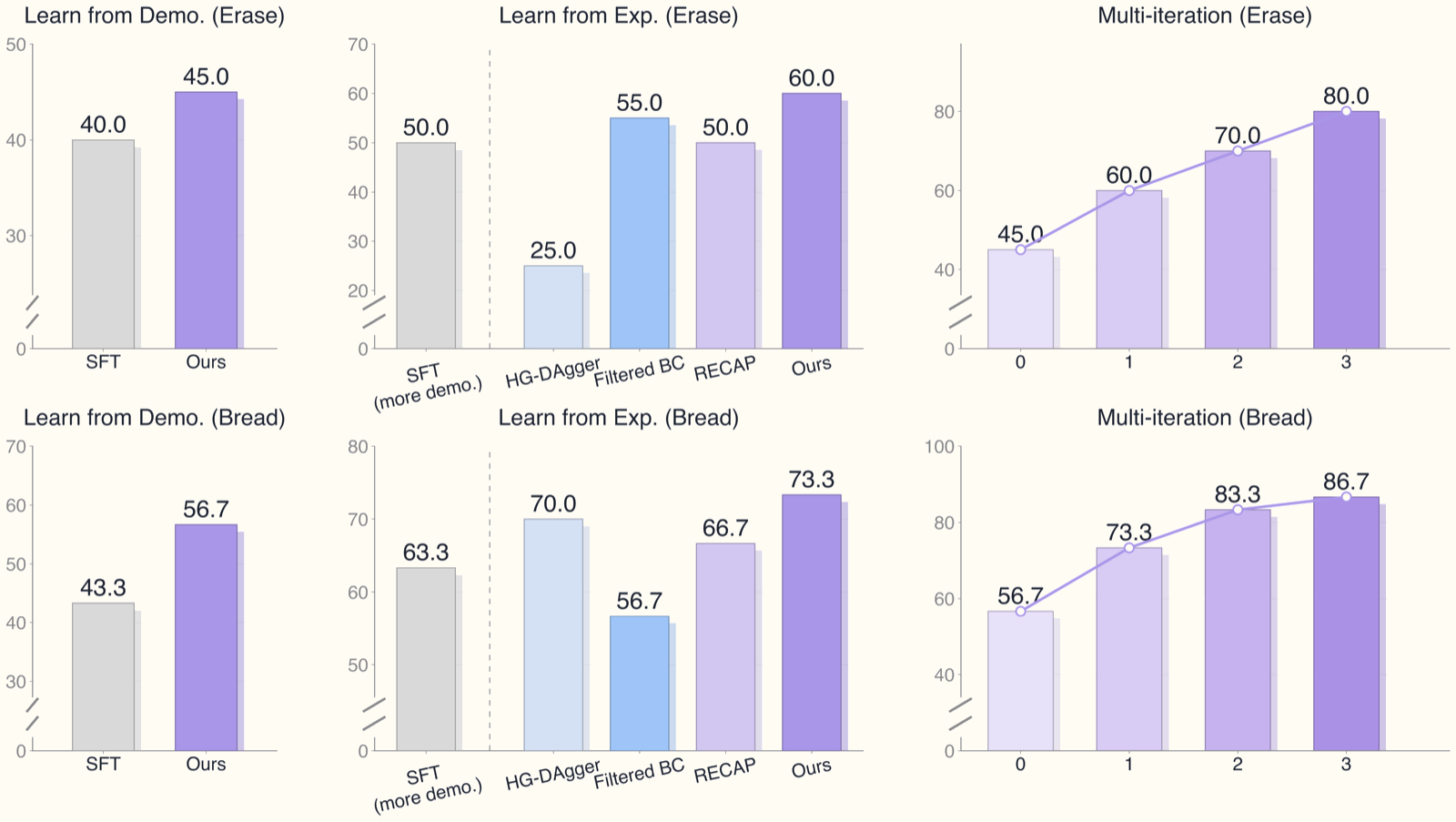
- Robot: IRON-R01-1.11
- Initial data: 225 demonstration episodes
- Per iteration: additional 82/71/79 episodes
- Result after 3 iterations: 45.0% → 80.0% success rate
This is complex because it requires continuous force contact (correct pressure on the board), grip angle adjustment, and smooth trajectory following.
Task 2: Put Bread into Toaster (fine-grained insertion)
- Initial data: 220 demonstration episodes
- Per iteration: additional 97/69/104 episodes
- Intervention fraction: ~4.53% of total steps
- Result after 3 iterations: 56.7% → 86.7% success rate
This task demands extreme precision: the toaster slot has tight tolerances, the robot must align its dexterous hand in 3D space with minimal force feedback.
Comparison Against Baselines
ROVE outperforms all baselines tested:
| Method | Whiteboard | Bread Toaster |
|---|---|---|
| Base policy (SFT) | 45.0% | 56.7% |
| Filtered BC | ~52% | ~63% |
| HG-DAgger | Below base | ~61% |
| RECAP | ~65% | ~72% |
| ROVE (ours) | 80.0% | 86.7% |
Notably: HG-DAgger fails on one task — performing worse than the initial policy. This happens because HG-DAgger directly imitates every operator intervention, including suboptimal ones.
Why OVE Matters: Ablation Study
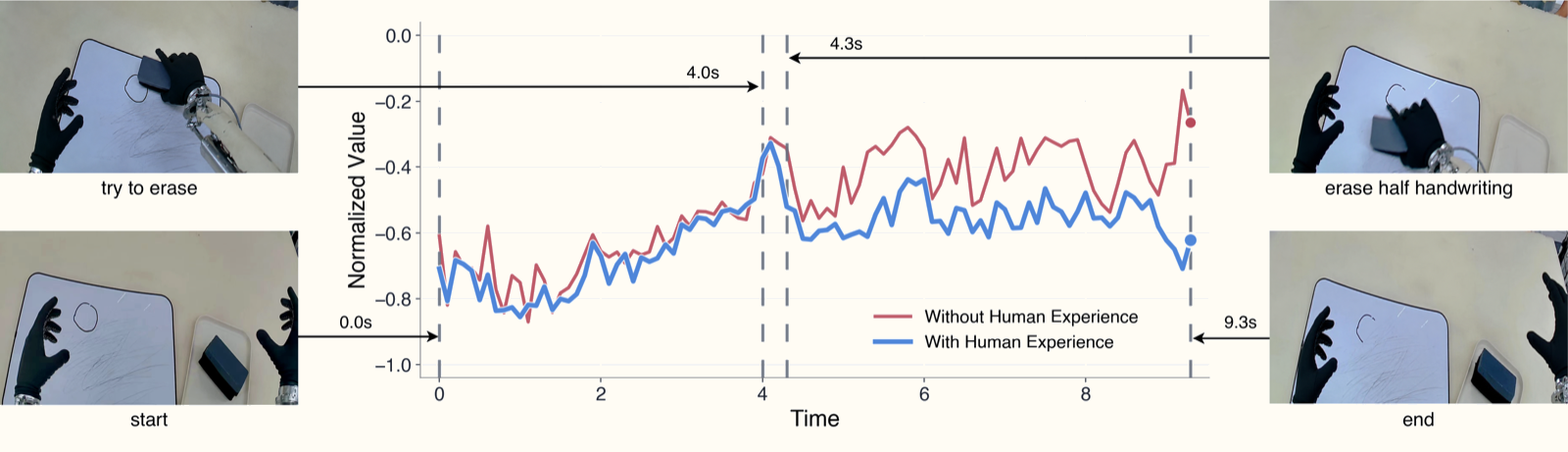
Key ablations from the paper:
- OVE vs. Monte-Carlo regression: OVE consistently wins because it isn't "dragged down" by low-value trajectories.
- With vs. without human videos: Human videos significantly improve value estimation quality for rare failure scenarios.
- τ sensitivity: τ=0.7 is the right balance — τ=0.5 degenerates to mean regression, τ→1 overfits to best-case trajectories only.
Applying ROVE Principles to Your Own Project
Although ROVE does not have open-source code at the time of writing, its principles can be applied with any VLA:
Step 1: Prepare a Base VLA Policy
# Assumes you have a VLA (LeRobot, OpenVLA, or π0) pre-trained on demos
# ROVE pipeline requires the VLA to return action distributions
from lerobot.common.policies.pi0 import Pi0Policy
base_policy = Pi0Policy.from_pretrained("your-checkpoint")
Step 2: Collect Human-in-the-Loop Data
# ROVE data structure:
# - state: observation at time t
# - action: action taken (by robot or human intervening)
# - reward: sparse reward (0/1 task completion)
# - intervention_flag: True if human intervened at this step
episode = {
"states": [], # List[np.ndarray] shape (T, state_dim)
"actions": [], # List[np.ndarray] shape (T, action_dim)
"rewards": [], # List[float]
"intervention": [] # List[bool]
}
Step 3: Train the Critic with OVE
import torch
import torch.nn as nn
class OVECritic(nn.Module):
def __init__(self, state_dim, hidden_dim=256):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, state):
return self.net(state).squeeze(-1)
def ove_loss(predictions, targets, tau=0.7):
"""
Expectile regression loss with optimism parameter tau.
tau=0.5 → standard mean regression
tau→1 → learn only from highest-value trajectories
"""
errors = targets - predictions
weights = torch.where(errors >= 0,
torch.full_like(errors, tau),
torch.full_like(errors, 1 - tau))
return (weights * errors.pow(2)).mean()
def compute_bootstrap_target(rewards, next_values, gamma=0.99, H=16):
"""
V̂_t = Σ γ^i r_i + γ^H V(s_{t+H})
"""
discounted_rewards = sum(
gamma**i * r for i, r in enumerate(rewards[:H])
)
return discounted_rewards + gamma**H * next_values
Step 4: Compute Advantages and Assign Labels
import numpy as np
def compute_advantages_and_labels(
states, rewards, critic, gamma=0.99, H=16, percentile=70
):
"""
Compute advantages and assign binary labels at the 70th percentile.
"""
values = critic(torch.tensor(states)).detach().numpy()
advantages = []
for t in range(len(states) - H):
bootstrap_val = compute_bootstrap_target(
rewards[t:t+H], values[t+H], gamma, H
)
adv = bootstrap_val - values[t]
advantages.append(adv)
threshold = np.percentile(advantages, percentile)
labels = [1 if a >= threshold else 0 for a in advantages]
return advantages, labels
Step 5: Fine-Tune the Actor with Advantage Conditioning
def fine_tune_actor_advantage_conditioned(policy, dataset, labels):
"""
Fine-tune only on steps with label=1 (high advantage).
Equivalent to Advantage-Conditioned Behavior Cloning.
"""
optimizer = torch.optim.AdamW(policy.parameters(), lr=1e-5)
for step, (state, action, label) in enumerate(dataset):
if label == 0: # Skip low-advantage steps
continue
# Standard behavior cloning loss
pred_action = policy(state, improvement_signal=True)
loss = nn.MSELoss()(pred_action, action)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Important Regularization
ROVE uses two key techniques to prevent overfitting:
- State dropout: 0.3 probability of dropping proprioceptive state → policy doesn't overfit to specific sensor readings.
- Gaussian perturbation: Add Gaussian noise (σ=0.4) to proprioceptive inputs → increases robustness.
When to Use ROVE
ROVE is best suited when:
- You already have a VLA baseline policy — ROVE is post-training, not from scratch.
- The task requires contact or high precision — sparse reward alone is insufficient for standard RL.
- You have available operators who can intervene but don't need to be robotics experts.
- You want iterative improvement — each round collects ~70-100 additional episodes.
ROVE is less suitable when:
- The task is simple enough for dense-reward RL from scratch.
- No human operators are available for real-robot interventions.
- You need more than 3 iterations with tighter timelines.
Strengths and Limitations
Strengths:
- Leverages imperfect interventions — much more realistic than requiring expert demonstrations.
- OVE sidesteps the out-of-distribution problem common in offline RL.
- Cross-embodiment learning from human videos handles rare failure edge cases.
Current Limitations:
- Requires a physical robot for data collection — no sim-to-real pipeline yet.
- Performance depends on the quality and quantity of human interventions.
- No open-source code at time of writing (June 2026).
- Tested on only 2 tasks — generality is unclear.
Conclusion
ROVE answers an important practical question: "How do you turn an operator's clumsiness into valuable training data?" The answer is to use RL with Optimistic Value Estimation to distill value from mixed-quality data, rather than imitating everything or applying rigid filters.
With results of 45%→80% and 57%→87% success rate in just 3 collection rounds, ROVE is a meaningful step toward real-world humanoid deployment — where expert robot operators aren't always available.
Original paper: ROVE: Unlocking Human Interventions for Humanoid Manipulation via Reinforcement Learning — Wei Xiao et al., XPENG Robotics, arXiv June 2026

