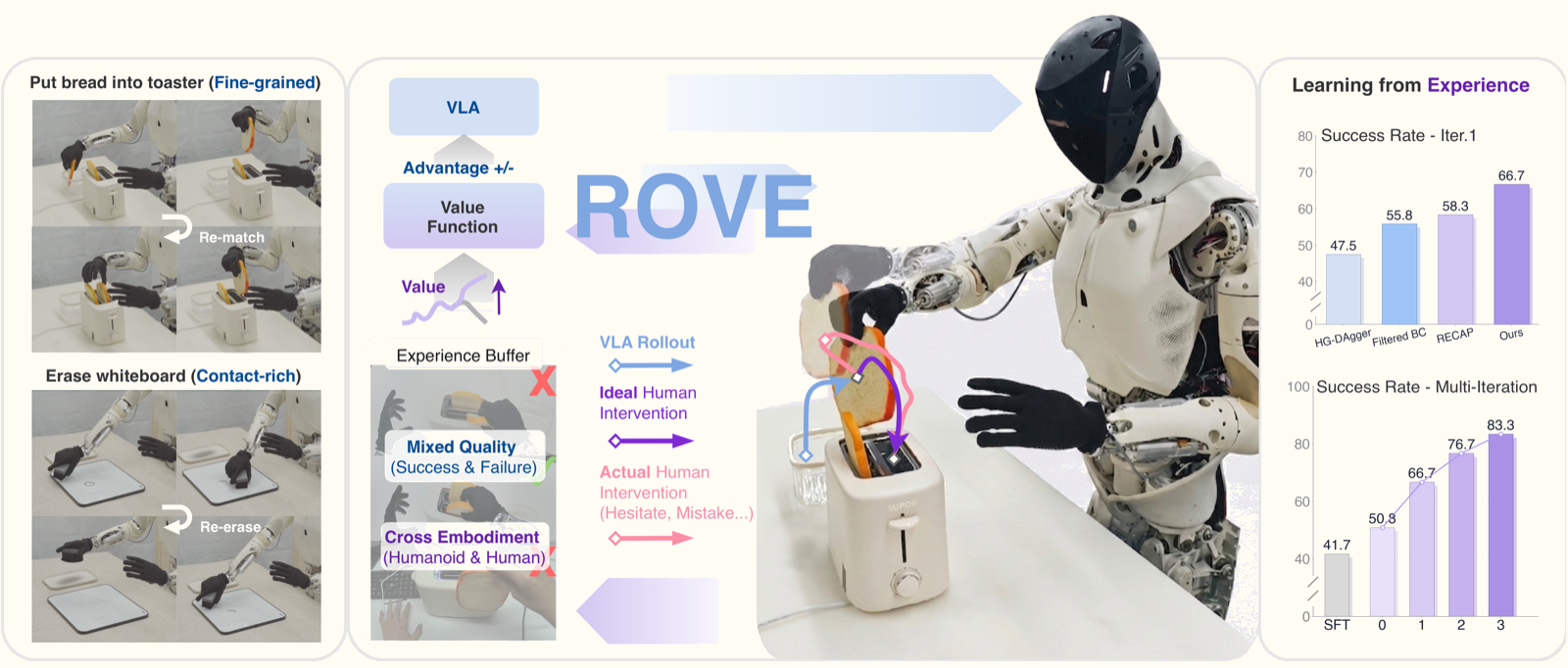
Tưởng tượng bạn đang dạy robot gấp quần áo. Robot làm sai — bạn chụp tay nó và điều chỉnh. Nhưng bạn không phải chuyên gia điều khiển robot, tay bạn run đôi chút, và cú "cứu" đó thật ra không hoàn hảo. Liệu robot có học được gì từ những can thiệp vụng về đó không?
Đây chính xác là vấn đề mà ROVE (Reinforcement Learning with Optimistic Value Estimation) của XPENG Robotics giải quyết. Bài báo xuất hiện trên arXiv tháng 6/2026, đại diện cho một hướng đi mới trong việc huấn luyện humanoid thao tác khéo léo: thay vì chỉ bắt chước dữ liệu tốt, robot học cách phân biệt hành vi có giá trị cao từ dữ liệu hỗn hợp chất lượng.
Vấn đề cốt lõi: Can thiệp của người không hoàn hảo
Trong robotics, "human-in-the-loop" (HITL) là kỹ thuật phổ biến: khi robot gặp khó khăn, người điều hành can thiệp và chỉnh sửa. Dữ liệu can thiệp này sau đó được dùng để huấn luyện policy tốt hơn.
Điều đó nghe có vẻ đơn giản — nhưng với humanoid có tay khéo léo (dexterous hands), mọi thứ phức tạp hơn rất nhiều:
-
Khoảng cách teleoperation: Người điều hành dùng VR headset + motion capture để điều khiển robot. Nhưng bàn tay người và bàn tay robot rất khác nhau về cấu trúc, và không có phản hồi lực (haptic feedback). Mỗi cử động bị "dịch" không hoàn hảo sang không gian khớp của robot.
-
Hành động can thiệp thường dưới tối ưu: Khi người cứu robot, họ thường làm nhanh, vụng về, không theo đường đi tối ưu. Nếu robot học cách bắt chước mù quáng, nó sẽ học cả những hành động tệ.
-
50 bậc tự do: Robot IRON-R01-1.11 của XPENG có 50 chiều không gian proprioceptive (khớp thân + bàn tay khéo léo). Điều khiển toàn bộ chuỗi này qua VR là thách thức kỹ thuật khổng lồ.
ROVE là gì? Framework tổng quát
ROVE là một framework RL post-training — nghĩa là nó không huấn luyện VLA từ đầu, mà tinh chỉnh (fine-tune) một VLA policy đã có sẵn bằng dữ liệu can thiệp mới thu thập được.
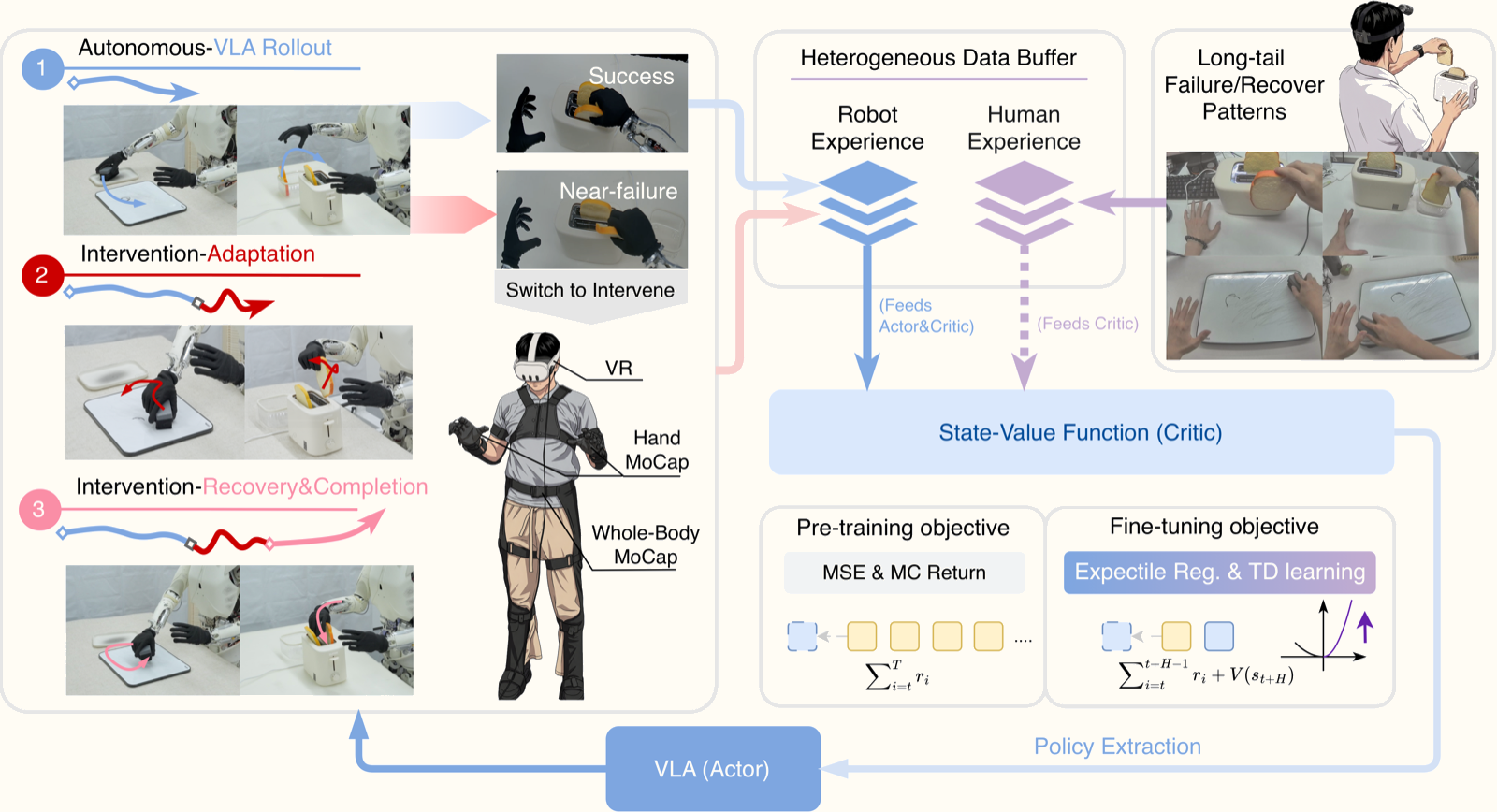
Ba thành phần cốt lõi:
1. Pipeline thu thập dữ liệu human-in-the-loop
Mỗi episode được chia làm 3 giai đoạn:
- Rollout tự động: VLA policy chạy độc lập, hoàn thành task càng nhiều càng tốt.
- Giai đoạn can thiệp-thích nghi (intervention-adaptation): Khi policy sắp thất bại, người điều hành tiếp quản. Hệ thống phát hiện "ranh giới thất bại" một cách thận trọng (conservative failure boundary labeling) để can thiệp sớm trước khi mọi thứ sụp đổ hoàn toàn.
- Giai đoạn phục hồi (intervention-recovery): Sau khi người điều hành ổn định tình hình, VLA tiếp tục hoàn thành nốt task.
Điều đặc biệt là hệ thống dùng command filter để làm mượt quá trình chuyển giao quyền điều khiển — tránh các cú giật bất ngờ có thể làm hỏng robot hoặc tạo dữ liệu nhiễu.
2. Optimistic Value Estimation (OVE)
Đây là đóng góp lý thuyết trung tâm của ROVE. Vấn đề cơ bản là: làm sao đánh giá hành động nào "đáng học" từ dữ liệu hỗn hợp?
OVE dùng expectile regression để ước tính hàm giá trị thiên về các giá trị cao hơn:
$$\mathcal{L}_{OVE}(\phi) = \mathbb{E}\left[|\tau - \mathbf{1}{\hat{V}t - V\phi(s_t) < 0}|(\hat{V}t - V\phi(s_t))^2\right]$$
Trong đó:
- $\hat{V}t = \sum{i=t}^{t+H-1} \gamma^{i-t} r_i + \gamma^H V_{\bar{\phi}}(s_{t+H})$ là giá trị mục tiêu bootstrapped H bước
- $\tau \in (0.5, 1)$ điều khiển "mức độ lạc quan" — càng gần 1, critic càng thiên về các trajectory giá trị cao
Tham số mặc định: $\tau = 0.7$, $H = 16$ bước cho inference/advantage, $H = 50$ cho huấn luyện.
Ưu điểm so với Monte-Carlo regression (bắt chước tất cả): OVE không cần query các hành động ngoài phân phối vì nó hoạt động trên value function thay vì Q-function, tránh được vấn đề phổ biến trong offline RL.
3. Advantage-conditioned policy extraction
Sau khi có critic, ROVE tính lợi thế (advantage) cho từng bước:
$$A_{\phi_k} = \sum \text{rewards} + \gamma^H V_{\phi_k}(s_{t+H}) - V_{\phi_k}(s_t)$$
Các bước được gán nhãn nhị phân: "cải thiện" nếu advantage vượt ngưỡng phân vị thứ 70, "không cải thiện" nếu dưới ngưỡng đó. Actor sau đó được fine-tune bằng advantage-conditioned behavior cloning — chỉ học từ những hành động được đánh dấu "cải thiện".
Tại inference, dùng classifier-free guidance decoding:
$$v_{cfg} = v_{neg} + \beta(v_{pos} - v_{neg})$$
Điều này "lái" generation về phía hành động có lợi thế cao mà không cần thay đổi kiến trúc mạng.
Vòng lặp huấn luyện ROVE: Từng bước
Đây là thuật toán đầy đủ theo Algorithm 1 trong paper:
Khởi tạo:
- Policy ban đầu $\pi_0$ (VLA đã được pre-train trên demonstrations)
- Dataset demonstrations $\mathcal{D}^0_{critic}$
Lặp $k = 1, 2, 3$:
- Huấn luyện critic $V_{\phi_k}$ trên $\mathcal{D}^k_{critic}$ bằng OVE objective
- Tính advantages cho tất cả transition trong dataset
- Gán nhãn nhị phân theo ngưỡng phân vị 70
- Fine-tune actor $\pi_{k+1}$ từ $\pi_k$ bằng advantage-conditioned BC
- Deploy $\pi_{k+1}$, thu thập episode mới + can thiệp → tạo $\mathcal{D}^{k+1}_{critic}$
Mỗi vòng lặp tương ứng với ~1 đợt thu thập dữ liệu thực trên robot.
Dữ liệu cross-embodiment: Học từ video của người
Một điểm thú vị khác của ROVE: học từ 180 video egocentric của người cho mỗi task. Videos này ghi lại người thực hiện thao tác tương tự, được dùng để giám sát ước tính giá trị — đặc biệt hữu ích cho các tình huống thất bại hiếm gặp (long-tailed failure modes).
Tại sao điều này hiệu quả? Vì tư thế tay của người trong các tình huống phục hồi mang thông tin về cấu trúc của bài toán — robot có thể học "khi nào cần làm gì" từ dữ liệu này, dù cơ thể robot và người khác nhau.
Thực nghiệm: 2 task thực tế khó
Task 1: Xóa bảng trắng (contact-rich)
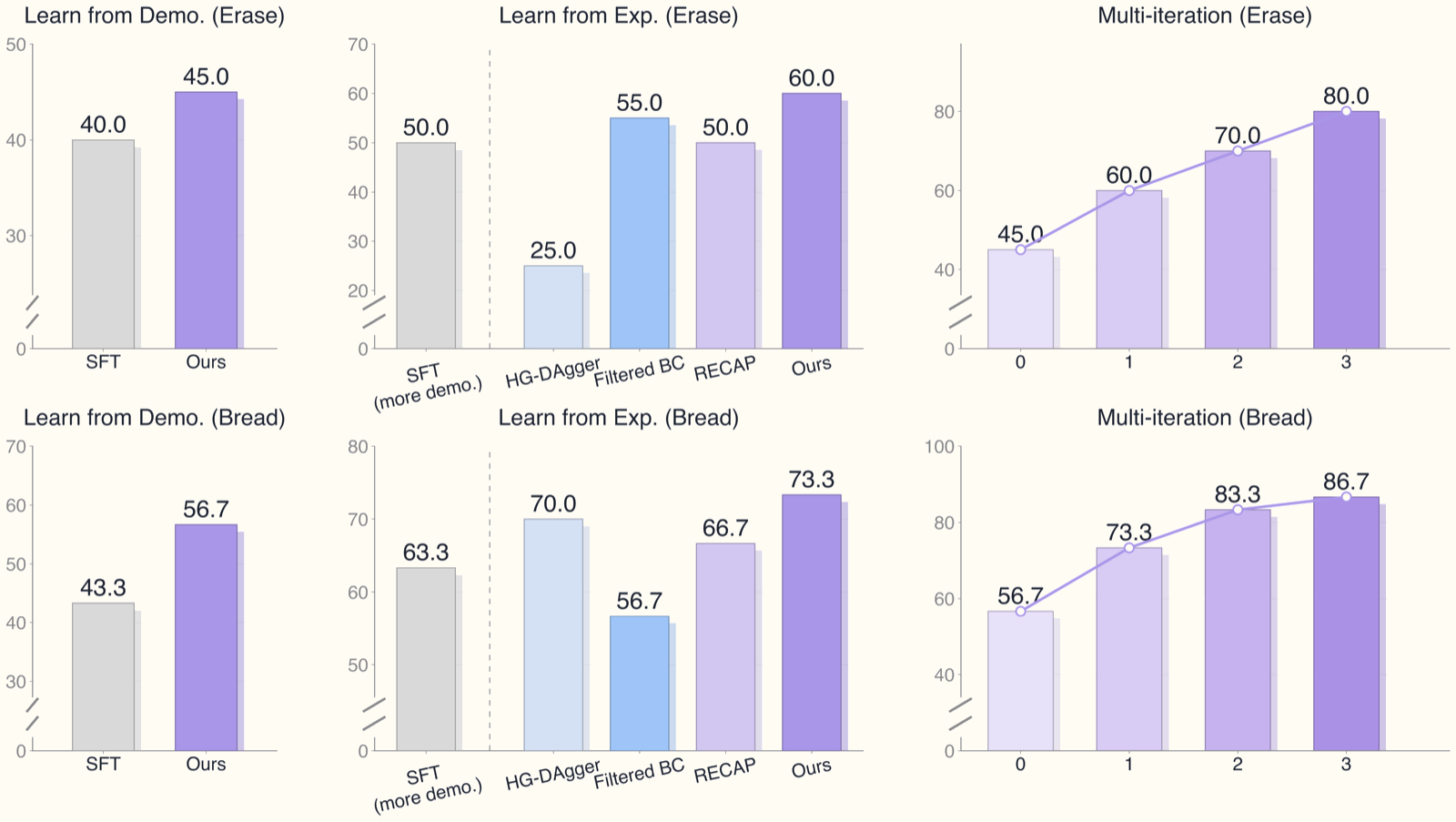
- Robot: IRON-R01-1.11
- Dữ liệu ban đầu: 225 episodes demonstration
- Mỗi vòng lặp: thêm 82/71/79 episodes mới
- Kết quả sau 3 vòng lặp: 45.0% → 80.0% success rate
Đây là task phức tạp vì đòi hỏi tiếp xúc lực liên tục (áp lực đúng mức lên bảng), điều chỉnh góc cầm, và di chuyển theo quỹ đạo mượt mà.
Task 2: Cho bánh mì vào máy nướng (fine-grained insertion)
- Dữ liệu ban đầu: 220 episodes
- Mỗi vòng lặp: thêm 97/69/104 episodes
- Tỉ lệ can thiệp: ~4.53% tổng số bước
- Kết quả sau 3 vòng lặp: 56.7% → 86.7% success rate
Task này đòi hỏi chính xác cực cao: khe cắm bánh mì có dung sai nhỏ, robot phải căn chỉnh bàn tay khéo léo trong không gian 3D với ít phản hồi lực.
So sánh với baseline
ROVE vượt trội so với tất cả baseline được thử nghiệm:
| Phương pháp | Whiteboard | Bread Toaster |
|---|---|---|
| Base policy (SFT) | 45.0% | 56.7% |
| Filtered BC | ~52% | ~63% |
| HG-DAgger | Dưới base | ~61% |
| RECAP | ~65% | ~72% |
| ROVE (ours) | 80.0% | 86.7% |
Đặc biệt đáng chú ý: HG-DAgger thất bại trên một task — thấp hơn cả policy ban đầu. Điều này xảy ra vì HG-DAgger bắt chước trực tiếp mọi can thiệp của người dùng, kể cả những can thiệp dưới tối ưu.
Tại sao OVE quan trọng? Ablation study
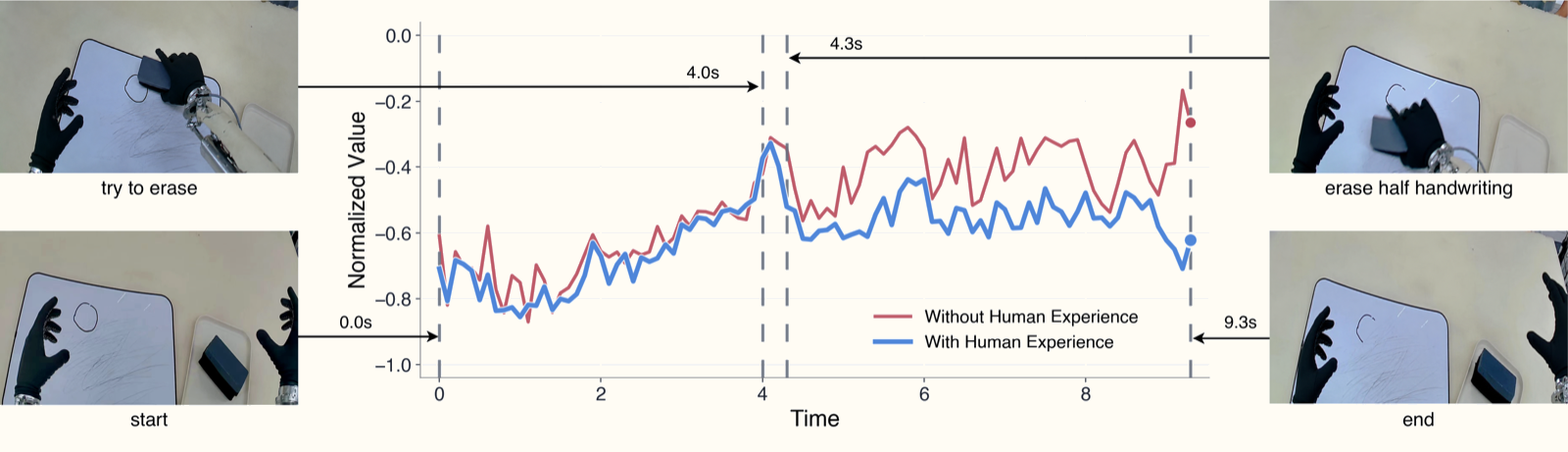
Paper thực hiện ablation:
- OVE vs. Monte-Carlo regression: OVE tốt hơn nhất quán vì không bị "kéo xuống" bởi các trajectory có giá trị thấp.
- Có vs. không có video người: Video người tăng đáng kể chất lượng ước tính giá trị trong các tình huống thất bại hiếm gặp.
- τ sensitivity: τ=0.7 là điểm cân bằng tốt giữa "quá bảo thủ" (τ=0.5, bằng mean regression) và "quá lạc quan" (τ→1, chỉ học trajectory tốt nhất).
Cách tái tạo / áp dụng ROVE trong dự án của bạn
Dù ROVE chưa có code open-source tại thời điểm viết bài, các nguyên tắc có thể áp dụng trực tiếp với bất kỳ VLA nào:
Bước 1: Chuẩn bị VLA policy ban đầu
# Giả sử bạn có một VLA (LeRobot, OpenVLA, hay π0) đã được train trên demos
# Pipeline ROVE yêu cầu VLA trả về distribution của hành động
from lerobot.common.policies.pi0 import Pi0Policy
base_policy = Pi0Policy.from_pretrained("your-checkpoint")
Bước 2: Thu thập dữ liệu human-in-the-loop
# Cấu trúc dữ liệu ROVE cần:
# - state: observation tại thời điểm t
# - action: hành động thực hiện (của robot hoặc người can thiệp)
# - reward: sparse reward (0/1 task completion)
# - intervention_flag: True nếu đây là hành động của người can thiệp
episode = {
"states": [], # List[np.ndarray] shape (T, state_dim)
"actions": [], # List[np.ndarray] shape (T, action_dim)
"rewards": [], # List[float]
"intervention": [] # List[bool]
}
Bước 3: Huấn luyện critic với OVE
import torch
import torch.nn as nn
class OVECritic(nn.Module):
def __init__(self, state_dim, hidden_dim=256):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, state):
return self.net(state).squeeze(-1)
def ove_loss(predictions, targets, tau=0.7):
"""
Expectile regression loss với tham số lạc quan tau.
tau=0.5 → mean regression thông thường
tau→1 → chỉ học từ các giá trị cao nhất
"""
errors = targets - predictions
weights = torch.where(errors >= 0,
torch.full_like(errors, tau),
torch.full_like(errors, 1 - tau))
return (weights * errors.pow(2)).mean()
# Bootstrap target
def compute_bootstrap_target(rewards, next_values, gamma=0.99, H=16):
"""
V̂_t = Σ γ^i r_i + γ^H V(s_{t+H})
"""
discounted_rewards = sum(
gamma**i * r for i, r in enumerate(rewards[:H])
)
return discounted_rewards + gamma**H * next_values
Bước 4: Tính advantage và gán nhãn
import numpy as np
def compute_advantages_and_labels(
states, rewards, critic, gamma=0.99, H=16, percentile=70
):
"""
Tính advantage và gán nhãn nhị phân theo phân vị 70.
"""
values = critic(torch.tensor(states)).detach().numpy()
advantages = []
for t in range(len(states) - H):
bootstrap_val = compute_bootstrap_target(
rewards[t:t+H], values[t+H], gamma, H
)
adv = bootstrap_val - values[t]
advantages.append(adv)
threshold = np.percentile(advantages, percentile)
labels = [1 if a >= threshold else 0 for a in advantages]
return advantages, labels
Bước 5: Fine-tune actor với advantage conditioning
def fine_tune_actor_advantage_conditioned(policy, dataset, labels):
"""
Chỉ fine-tune trên các bước có label=1 (advantage cao).
Tương đương với Advantage-Conditioned BC.
"""
optimizer = torch.optim.AdamW(policy.parameters(), lr=1e-5)
for step, (state, action, label) in enumerate(dataset):
if label == 0: # Bỏ qua bước có advantage thấp
continue
# Standard behavior cloning loss
pred_action = policy(state, improvement_signal=True)
loss = nn.MSELoss()(pred_action, action)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Regularization quan trọng
ROVE dùng hai kỹ thuật quan trọng để tránh overfitting:
- State dropout: Xác suất 0.3 để bỏ qua proprioceptive state → policy không quá phụ thuộc vào sensor đặc thù.
- Gaussian perturbation: Thêm nhiễu Gaussian (σ=0.4) vào proprioceptive input → tăng tính robustness.
Ứng dụng thực tế: Khi nào nên dùng ROVE?
ROVE phù hợp nhất khi:
- Bạn đã có VLA policy baseline — ROVE là post-training, không phải từ đầu.
- Task đòi hỏi tiếp xúc lực hoặc độ chính xác cao — reward sparse không đủ cho RL chuẩn.
- Bạn có người có thể can thiệp nhưng không phải chuyên gia robot.
- Bạn muốn cải thiện iterative — mỗi vòng thu thập thêm ~70-100 episodes.
Ngược lại, ROVE không phù hợp khi:
- Task đủ đơn giản để RL reward dense từ đầu.
- Không có người có thể thực hiện can thiệp.
- Thời gian thực đòi hỏi nhiều hơn 3 vòng lặp thu thập.
Điểm mạnh và giới hạn
Điểm mạnh:
- Tận dụng được can thiệp không hoàn hảo — thực tế hơn nhiều so với yêu cầu demonstration chuyên gia.
- OVE tránh được vấn đề phân phối ngoài phân phối của offline RL.
- Cross-embodiment learning từ video người giúp xử lý edge cases hiếm gặp.
Giới hạn hiện tại:
- Cần robot thực để thu thập dữ liệu — chưa có sim-to-real pipeline.
- Hiệu quả phụ thuộc vào chất lượng và số lượng can thiệp của người.
- Chưa có code open-source (tại thời điểm viết bài tháng 6/2026).
- Thử nghiệm trên 2 task — chưa rõ tính tổng quát.
Kết luận
ROVE trả lời một câu hỏi thực tiễn quan trọng: "Làm sao biến sự vụng về của người điều hành thành dữ liệu huấn luyện có giá trị?" Câu trả lời là dùng RL với Optimistic Value Estimation để chắt lọc giá trị từ dữ liệu hỗn hợp, thay vì bắt chước tất cả hay lọc bỏ cứng nhắc.
Với kết quả 45%→80% và 57%→87% success rate chỉ sau 3 vòng thu thập, ROVE là một bước tiến thực chất trong việc deploy humanoid thực tế — nơi không phải lúc nào cũng có chuyên gia robot ngồi bên cạnh.
Paper gốc: ROVE: Unlocking Human Interventions for Humanoid Manipulation via Reinforcement Learning — Wei Xiao et al., XPENG Robotics, arXiv tháng 6/2026

