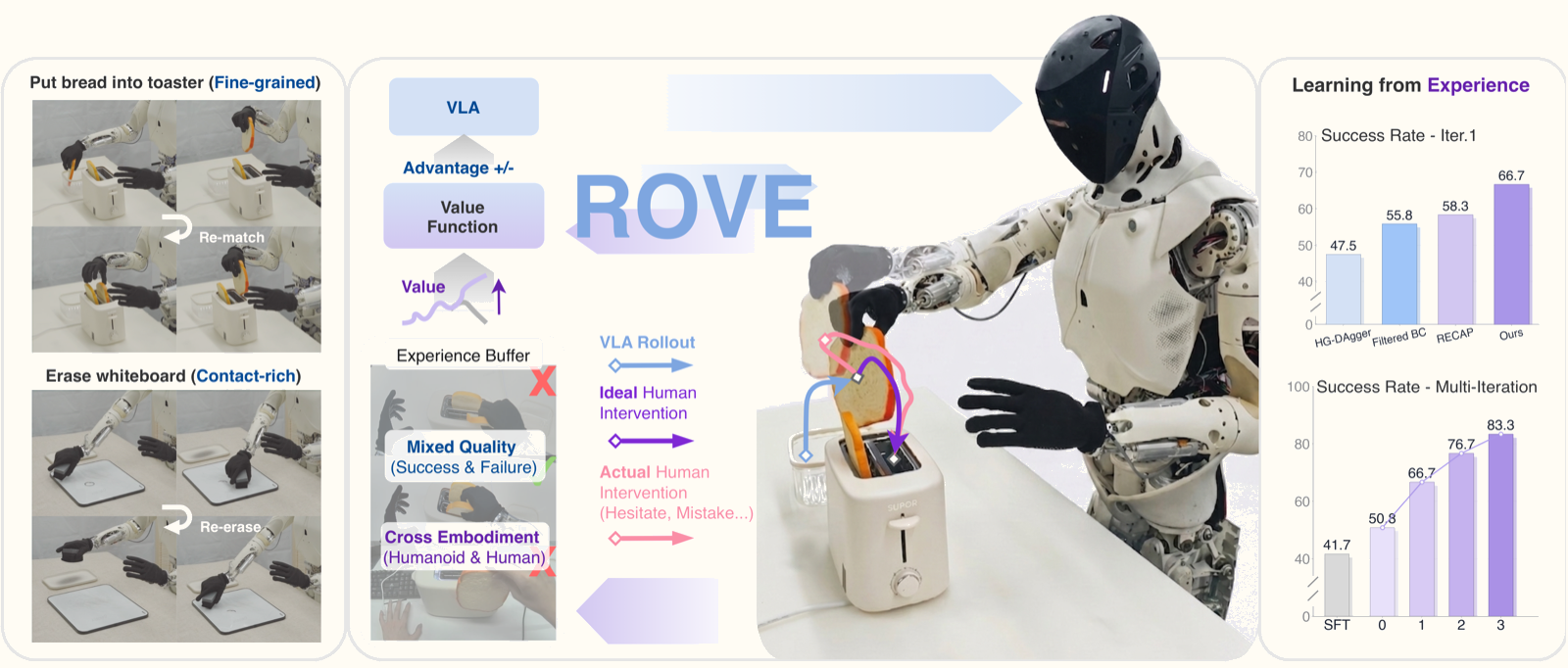
When Humans Save the Robot — But Imperfectly
Imagine a humanoid robot attempting to insert bread into a toaster. It approaches at the right angle, but the gripper is slightly misaligned and the bread falls. A nearby operator takes over, adjusts the gripper, and helps the robot complete the task.
The question is: what is that collected data actually worth?
In theory, it's invaluable. The robot just received an example of how to recover from failure — something extremely hard to find in standard demonstrations.
In practice, it's messy. Operating a humanoid with dexterous hands is difficult: operators hesitate, make redundant movements, or intervene too late. If you treat this data as expert supervision — Behavioral Cloning or DAgger style — your model will learn those imperfect behaviors too.
This is the core problem ROVE: Unlocking Human Interventions for Humanoid Manipulation via Reinforcement Learning addresses. Published in June 2026 by researchers from XPENG Robotics, Fudan University, CUHK, and SJTU. Project page: xpeng-robotics.github.io/rove.
The Teleoperation Gap
Humanoid manipulation has a specific challenge that standard robot arms don't share — the teleoperation gap.
A humanoid's action space spans 50 dimensions (body + dexterous hands). An operator must coordinate wrist orientation, finger positions, and whole-body posture simultaneously, without haptic feedback, through 50–150ms of latency. Even experienced operators produce trajectories with inconsistent quality across episodes.
How do existing methods handle this?
- Supervised Fine-Tuning (SFT): Good for standard behaviors, but doesn't teach recovery from failure.
- HG-DAgger (Human-Guided DAgger): Collects intervention data then imitates everything — "poisoned" by hesitation and redundant actions.
- Filtered BC: Thresholds out bad data — simple but discards valuable recovery signals along with the noise.
- RECAP: Aggregates experiences — can't handle mixed-quality trajectories effectively.
ROVE proposes a different path: instead of filtering data, learn to extract what's valuable regardless of quality variance.
ROVE: Three Core Components
1. Human-in-the-loop collection pipeline — Robots run autonomous rollouts; when they fail, operators intervene; robots then self-recover. Each episode is structurally decomposed into distinct phases.
2. Optimistic Value Estimation (OVE) — The core innovation. Instead of treating intervention data as expert supervision, ROVE trains a value function (critic) that distinguishes high-value behaviors from mixed-quality trajectories using expectile regression.
3. Cross-embodiment human experience videos — 180 egocentric videos of humans performing the same tasks, used to enrich value signal for long-tail failure and recovery modes that rarely appear in autonomous rollouts.
Episode Decomposition: Structuring the Data
Before diving into OVE, it's important to understand how ROVE organizes the collected data.
Each episode is divided into three stages:
[ Autonomous Rollout ] → [ Adaptation Stage ] → [ Recovery Stage ]
↓ ↓ ↓
Robot operates Human intervenes Robot self-recovers
independently (adjusts, corrects) (completes task)
Rewards are designed around this structure:
- End of adaptation stage: Penalty (conservative boundary) — the robot required human help, meaning previous states were suboptimal.
- End of recovery stage: Success reward — the task was completed, so the entire trajectory carries value.
- No intermediate sparse reward — the value function propagates reward information backward through time.
The key insight: the adaptation stage is the boundary between success and failure. If you can identify from which states the robot was heading toward failure, you can compute backward value estimates accurately.
OVE: Optimistic Value Estimation
This is the most technically significant contribution. ROVE learns a state value function V(s) rather than action-value Q(s,a), because V(s) is more flexible for heterogeneous data from different sources — robot rollouts and human videos don't share the same action space.
Step 1: Monte Carlo Pretraining
The critic is first pretrained using Monte Carlo returns from demonstrations:
- V(s) = discounted sum of rewards from timestep t to episode end
- Gives the critic a solid starting point so OVE refinement has a stable base to build on
Step 2: Expectile Regression for "Optimism"
This is the core innovation. Instead of standard mean squared error, ROVE uses expectile loss with τ = 0.7:
L_OVE = E[w(s,a) · |τ - 𝟙(target > V(s))| · (target - V(s))²]
Where:
target= H-step TD bootstrap:r_t + γ^H · V(s_{t+H})— looking H=50 steps aheadτ = 0.7: the model learns to estimate the 70th percentile of the value distributionw(s,a)= importance weights that adjust for data source quality
Why expectile instead of mean? Because imperfect intervention data is biased downward. Human interventions create trajectories with lower value than optimal — due to hesitation, redundant moves, late entry. Learning the mean pulls V(s) down. Expectile with τ > 0.5 learns to estimate the upper end: "what value would this state have under better execution conditions?"
Think of it like estimating a student's academic ability from test scores on both good and bad days. Averaging all scores underestimates their true capability. The 70th percentile gives a more accurate picture of what they can actually do.
Step 3: H-step TD Bootstrapping
ROVE uses an H=50-step lookahead rather than 1-step TD. Manipulation tasks span many timesteps, and 1-step TD propagates reward signal too slowly. With H=50, the value at state t already "sees" rewards from 50 steps ahead — enough information to determine whether the trajectory is heading in the right direction.
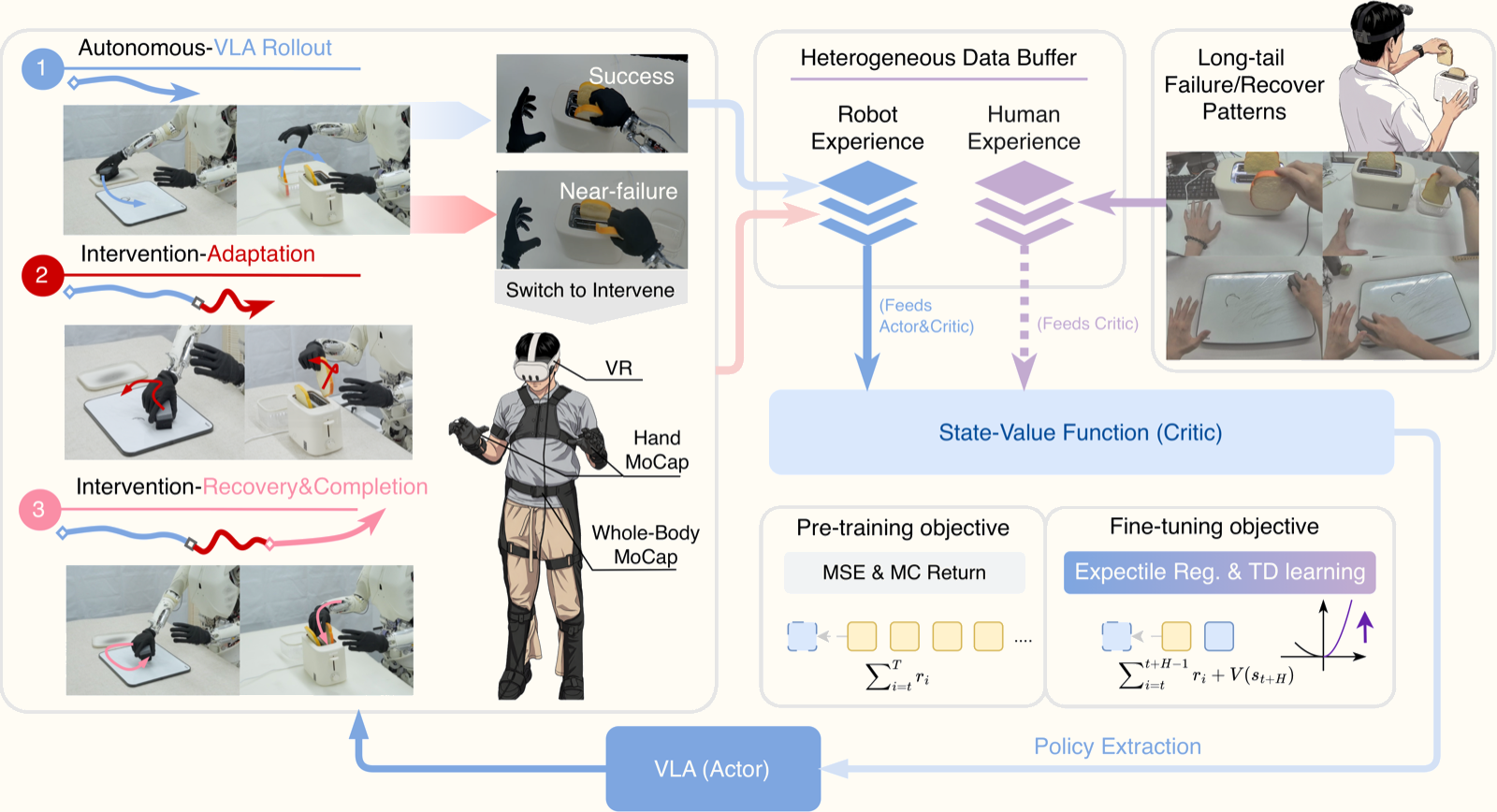
Cross-Embodiment Human Experience Videos
ROVE integrates 180 egocentric videos of humans performing the same tasks per task. The rationale:
Robots rarely encounter long-tail scenarios during autonomous rollouts — edge cases like dropped objects, stuck grippers, or incorrect orientations. These are exactly the scenarios human demo videos cover abundantly.
Since V(s) is state-only (no action required), video of human hands doesn't require action space mapping. ROVE uses Qwen3-VL visual features to encode frames from both robot and human video into a shared representation space, then integrates them into critic training.
Ablation results show:
- Without human video: critic struggles to differentiate "good partial progress" from "bad partial progress" at intermediate states
- With human video: accuracy increases significantly — critic learns that "gripper approaching at correct angle → high value" vs "gripper at wrong angle → low value"
Architecture Details
Critic (Value Function)
Input: RGB observation + proprioceptive state (50-D) + task text
↓
Qwen3-VL-4B (frozen VLM backbone)
↓
Layer 23 features → 2048-D representation
↓
Lightweight Transformer value head
↓
V(s) ∈ ℝ (scalar)
- Initialized from VLAC checkpoint (pre-trained value critic)
- VLM backbone is frozen; only the value head is trained
- State dropout 0.3 + Gaussian noise 0.4 for regularization, preventing overfitting on the narrow distribution of intervention data
Actor (Policy)
Input: RGB observation + proprioceptive state + task text
↓
Qwen3-VL-4B-Instruct (frozen VLM backbone)
↓
DiT (Diffusion Transformer) action decoder
↓
Action chunk: H=16 steps × 50-D per step
The actor is updated via advantage conditioning: rather than direct RL gradients, ROVE assigns binary labels to each segment based on the value function:
A(s,a) = V(s') − V(s) > threshold(70th percentile) → label = 1 (keep)- Otherwise → label = 0 (filter)
The actor is then fine-tuned only on positive segments via supervised loss — a lightweight form of offline RL without policy gradient and without a simulator.
Training Pipeline in Practice
ROVE trains in two phases, repeated across multiple iterations:
Phase 1: Train Critic
critic_config = {
"checkpoint": "vlac-base",
"tau": 0.7, # Expectile parameter
"horizon": 50, # H-step TD lookahead
"num_steps": 8000,
"num_gpus": 8,
"batch_size": 64,
"lr": 1e-4, # 1e-5 for subsequent iterations
"state_dropout": 0.3,
"gaussian_noise": 0.4,
}
Phase 2: Train Actor (Advantage Conditioning)
actor_config = {
"base_policy": "sft_checkpoint",
"critic": "critic_iter_N",
"advantage_threshold": "p70", # 70th percentile cutoff
"num_steps": 8000,
"num_gpus": 8,
"batch_size": 16,
"lr": 1e-4,
}
The iteration loop:
- Deploy current policy → collect rollouts (~75–90 episodes per iteration)
- Human operator intervenes on failures (4.5–25.5% of episodes depending on task difficulty)
- Train critic (Phase 1) on rollout data + human experience videos
- Extract advantages, filter positive segments (> 70th percentile)
- Fine-tune actor (Phase 2) on filtered positive segments
- Repeat with the improved policy
Data per iteration:
| Task | Initial demos | Episodes/iter | Intervention rate |
|---|---|---|---|
| Erase whiteboard | 225 | ~75 | 25.5% |
| Put bread in toaster | 220 | ~90 | 4.5% |
| Human egocentric videos | — | — | 180 per task |
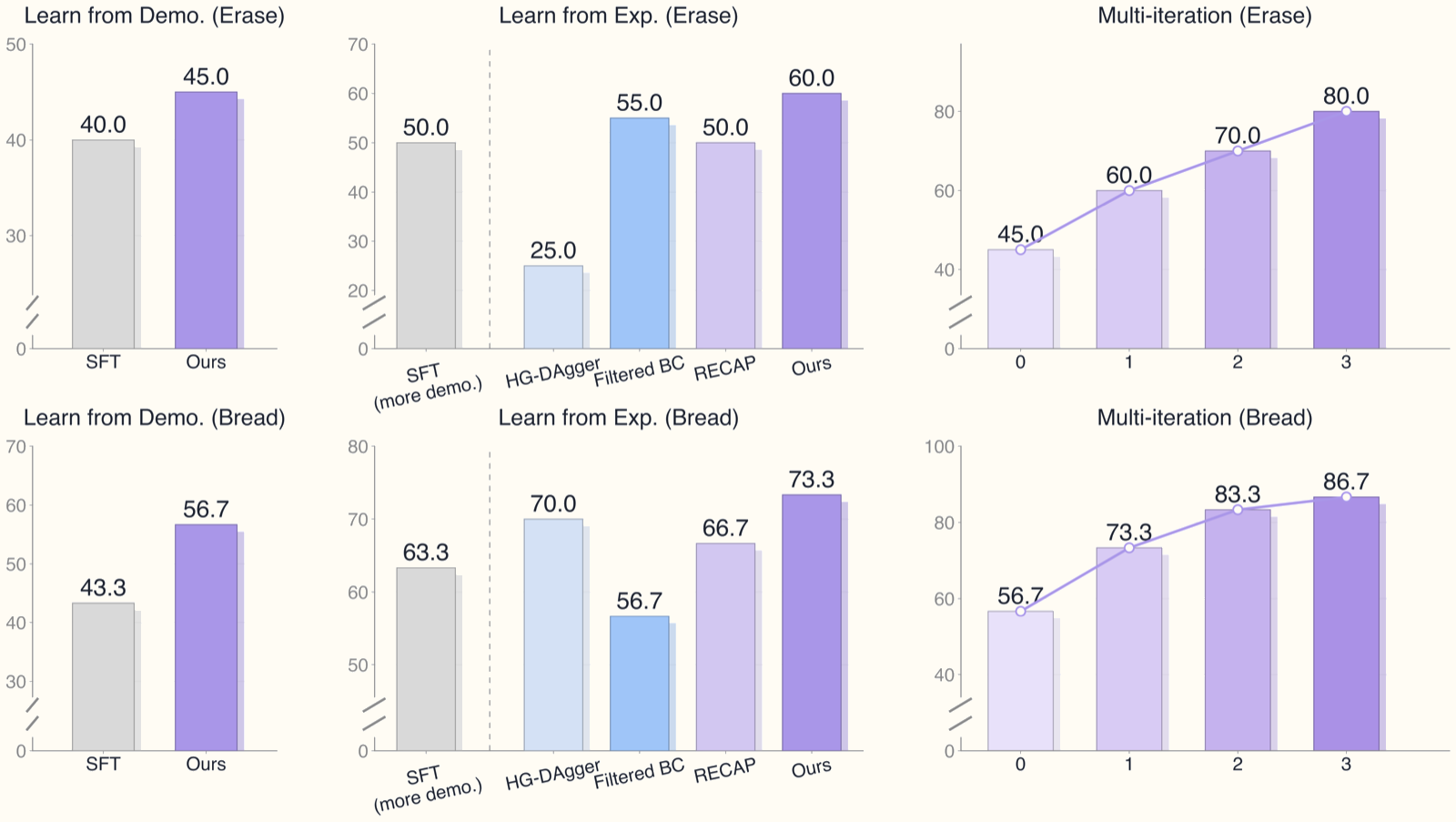
Results: Improvement Across Iterations
Real-world performance on two contact-rich humanoid manipulation tasks:
| Task | Iteration 0 | Iteration 3 | Gain |
|---|---|---|---|
| Put bread in toaster | 56.7% | 86.7% | +30 pp |
| Erase whiteboard | 45.0% | 80.0% | +35 pp |
Comparison against baselines after 3 iterations (erase whiteboard task):
| Method | Success Rate |
|---|---|
| SFT (demonstrations only) | ~45% |
| Filtered BC | ~52% |
| HG-DAgger | ~55% |
| RECAP | ~58% |
| ROVE (proposed) | 80% |
The gap over HG-DAgger is particularly meaningful. Both collect intervention data, but ROVE's ability to handle mixed-quality trajectories makes the decisive difference.
Ablation: OVE vs Monte Carlo
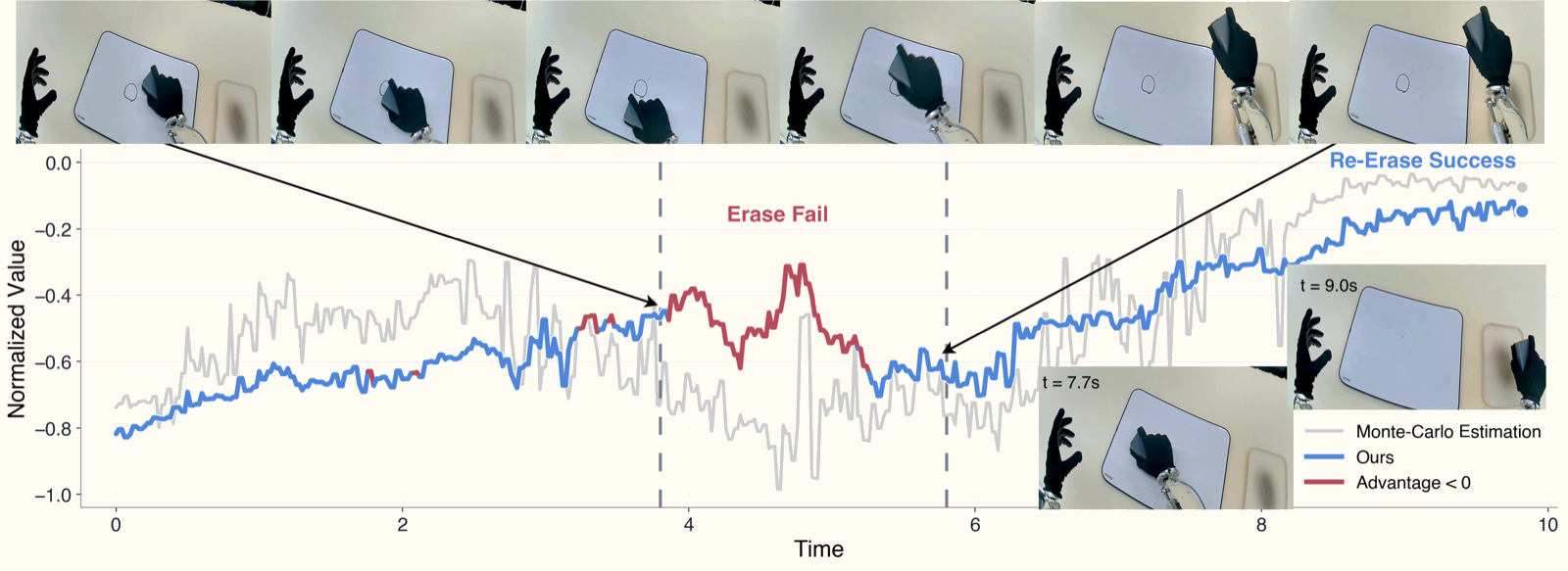
Monte Carlo returns underestimate value at intermediate states — exactly as expectile theory predicts. Human intervention creates longer trajectories with more hesitation, resulting in lower discounted returns than optimal. OVE with τ=0.7 corrects this bias, producing value estimates that reflect a state's true potential rather than the average quality of trajectories passing through it.
When to Use ROVE
ROVE is a good fit when you have:
- A pre-trained VLA (Qwen3-VL or equivalent) that needs task-specific fine-tuning
- Human operators who can intervene during robot rollouts (expert-level teleoperation is not required)
- Contact-rich manipulation tasks requiring precision — insertion, erasing, assembly
- Iterative deployment cycles — the ability to deploy → collect → retrain multiple rounds
ROVE is less appropriate when:
- You need to train a VLA from scratch (ROVE is a post-training method)
- The task is simple enough to solve with pure SFT
- You lack humanoid teleop infrastructure for human-in-the-loop collection
- Compute is severely constrained (each training run requires 8 GPUs)
Key Takeaways
1. Value functions bridge imitation and RL. ROVE achieves RL-like improvement without policy gradients, without a simulator, and without reward engineering — purely through value-based filtering and advantage conditioning.
2. Expectile regression is powerful for offline RL with mixed data. IQL (Implicit Q-Learning) and similar offline RL methods also use expectile regression. ROVE extends this to humanoid manipulation with cross-embodiment data, a meaningful new application.
3. Human experience videos fill in long-tail states. A critic trained only on robot data has blind spots at rare intermediate states. Human videos provide diverse coverage of exactly those situations that autonomous rollouts rarely surface.
4. Iteration quality beats data volume. Consistent improvement over 3 iterations with ~90 episodes each outperforms collecting 1,000 episodes at once. The policy improvement loop — not raw data scale — is the mechanism that matters.
Conclusion
ROVE addresses a practical question every team deploying VLA on humanoids will eventually face: when the robot fails and an operator saves it, how do you use that data effectively?
XPENG Robotics' answer — Optimistic Value Estimation to extract signal from mixed-quality trajectories — is a significant advance over Filtered BC or standard DAgger. Particularly notable is that ROVE requires no simulator, no reward engineering, and achieves large improvements with small intervention rates (4.5% of episodes for the toaster task). This represents a practical path toward production-grade VLA post-training on humanoid platforms.
Paper: ROVE arxiv 2606.17011 — XPENG Robotics, Fudan University, CUHK, SJTU, June 2026.
Related Posts
- UniIntervene: Real-world RL with Human Intervention — another human-in-the-loop RL framework for real robot deployment
- HILSERL: Real Robot RL via Human Feedback in LeRobot — RL from human feedback within the LeRobot framework
- ProcVLM: Dense Reward from Video for VLA — learning dense reward signals from video, complementary to ROVE's approach