Khi human cứu robot — nhưng không hoàn hảo
Hãy tưởng tượng một robot humanoid đang cố cho bánh mì vào máy nướng. Nó tiếp cận đúng hướng, nhưng gripper hơi lệch và bánh mì rớt. Người vận hành ngồi bên cạnh nhảy vào điều khiển, căn chỉnh lại gripper, giúp robot hoàn thành tác vụ.
Câu hỏi là: dữ liệu vừa được thu thập đó có giá trị gì không?
Về lý thuyết: rất có giá trị. Robot vừa nhận được một ví dụ về cách phục hồi từ failure. Điều đó cực kỳ khó tìm trong demo thuần túy.
Về thực tế: dữ liệu đó lộn xộn. Người điều khiển humanoid với bàn tay dexterous không dễ — có lúc họ do dự, có lúc họ làm thừa động tác, có lúc họ nhúng tay vào quá muộn. Nếu bạn dùng dữ liệu đó như expert supervision (kiểu Behavioral Cloning hay DAgger), model của bạn sẽ học cả những hành vi không tốt đó.
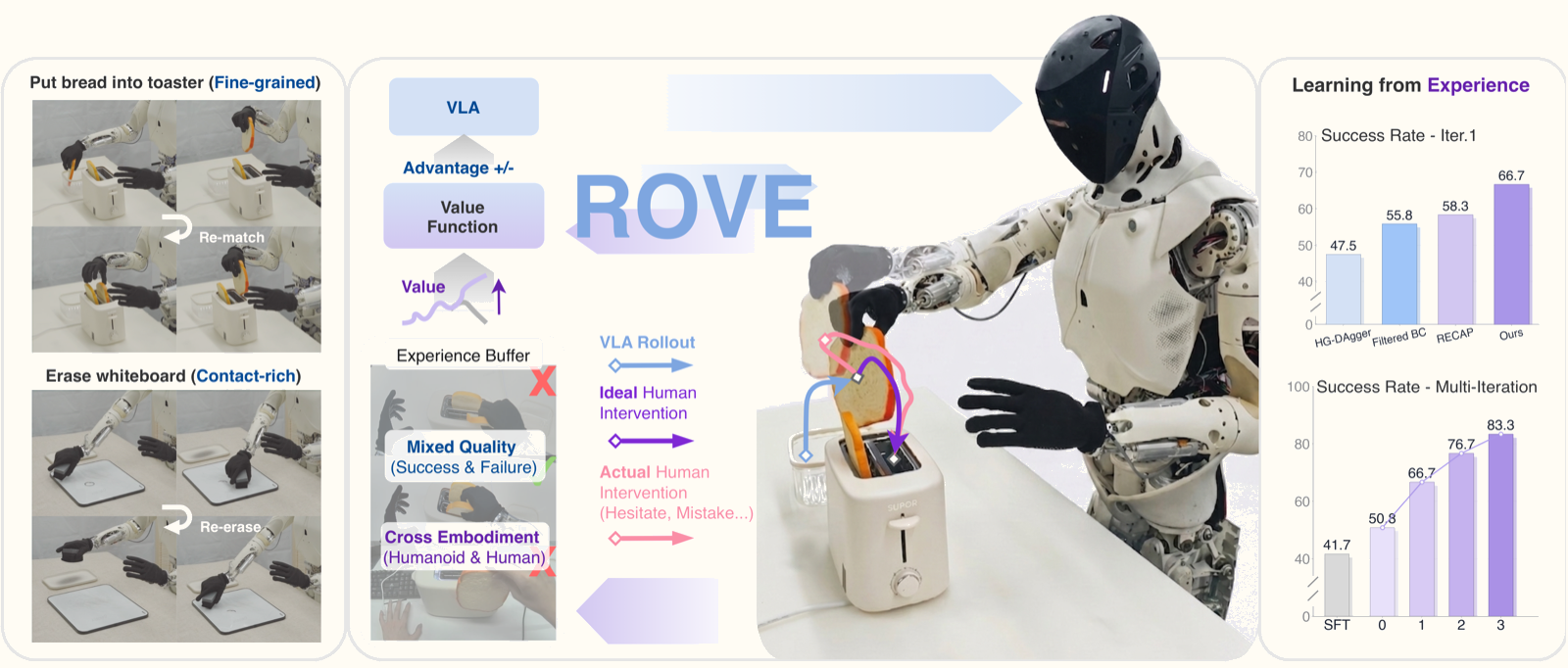
Đây là bài toán mà ROVE: Unlocking Human Interventions for Humanoid Manipulation via Reinforcement Learning của XPENG Robotics giải quyết. Paper được công bố tháng 6/2026 bởi nhóm từ XPENG Robotics, Fudan University, CUHK và SJTU. Project page: xpeng-robotics.github.io/rove.
Tại sao humanoid lại khó đặc biệt? Teleoperation Gap
Có một khoảng cách gọi là teleoperation gap trong humanoid manipulation. Đây không phải vấn đề của robot arm thông thường — robot arm 6 bậc tự do vẫn có thể điều khiển trực quan. Humanoid với tay dexterous là khác.
Không gian hành động của humanoid có đến 50 chiều (thân + tay dexterous). Người điều khiển cần phối hợp cổ tay, ngón tay, và cả cơ thể cùng lúc. Không có haptic feedback. Độ trễ từ thị giác đến tín hiệu điều khiển thêm 50–150ms. Kết quả là ngay cả operator có kinh nghiệm cũng thường tạo ra trajectories có chất lượng không đồng đều.
Các phương pháp hiện tại xử lý vấn đề này như thế nào?
- Supervised Fine-Tuning (SFT) trên demonstrations: tốt cho behavior mẫu, nhưng không học được recovery từ failure.
- HG-DAgger (Human-Guided DAgger): thu thập intervention data rồi imitate toàn bộ — bị "nhiễm độc" bởi hesitation và redundant actions.
- Filtered BC: filter dữ liệu xấu bằng threshold — đơn giản nhưng bỏ sót nhiều signal giá trị.
- RECAP: aggregate experiences — không xử lý được mixed-quality trajectories.
ROVE đề xuất một con đường khác: thay vì filter data, học cách trích xuất phần giá trị từ data dù quality không đồng đều.
ROVE: 3 thành phần cốt lõi
ROVE xây dựng trên 3 ideas chính:
1. Human-in-the-loop collection pipeline — Robot chạy autonomous rollout; khi nào fail thì human nhảy vào can thiệp (intervention); sau đó robot tự recover. Mỗi episode được phân chia thành các giai đoạn có cấu trúc.
2. Optimistic Value Estimation (OVE) — Core innovation. Thay vì dùng intervention data làm expert supervision, ROVE train một value function (critic) biết phân biệt hành vi nào thực sự tốt từ mixed-quality trajectories. Dùng expectile regression để "lạc quan" về potential của những state tốt.
3. Cross-embodiment human experience videos — 180 video egocentric của người thực hiện cùng task, dùng để làm phong phú value signal đặc biệt ở những tình huống hiếm (long-tail failure modes).
Episode Decomposition: Cấu trúc dữ liệu
Trước khi hiểu OVE, cần hiểu cách ROVE tổ chức dữ liệu thu thập.
Mỗi episode được chia thành 3 giai đoạn:
[ Autonomous Rollout ] → [ Adaptation Stage ] → [ Recovery Stage ]
↓ ↓ ↓
Robot tự làm Human nhảy vào can thiệp Robot tự recover
(success/fail) (điều chỉnh, sửa lỗi) (hoàn thành task)
Reward được thiết kế dựa trên cấu trúc này:
- Cuối adaptation stage: Penalty (conservative boundary). Human phải can thiệp đồng nghĩa trạng thái trước đó không tốt.
- Cuối recovery stage: Success reward. Robot hoàn thành task sau hỗ trợ — cả trajectory đều có giá trị.
- Không có sparse reward giữa chừng — value function sẽ "lan truyền" reward information ngược lại.
Ý tưởng then chốt: adaptation stage là "ranh giới" giữa success và failure. Nếu biết robot sẽ thành công hay thất bại từ state nào, ta có thể tính backward value một cách chính xác.
OVE: Optimistic Value Estimation — Trái tim của ROVE
Đây là phần kỹ thuật quan trọng nhất. ROVE học state value function V(s) thay vì action-value Q(s,a), vì V(s) linh hoạt hơn khi xử lý dữ liệu từ nhiều nguồn khác nhau (robot rollouts và human videos không có cùng action space).
Bước 1: Monte Carlo pretraining
Trước khi OVE, ROVE pretrain critic bằng Monte Carlo returns từ demonstrations:
- V(s) = discounted sum of rewards từ timestep t đến end của episode thành công
- Cho critic một "starting point" tốt để OVE refinement sau đó không bị drift quá xa
Bước 2: Expectile regression để "lạc quan"
Đây là phần then chốt. Thay vì dùng mean squared error thông thường, ROVE dùng expectile loss với τ = 0.7:
L_OVE = E[w(s,a) · |τ - 𝟙(target > V(s))| · (target - V(s))²]
Trong đó:
target= H-step TD bootstrap:r_t + γ^H · V(s_{t+H})— nhìn trước H=50 stepsτ = 0.7: model học estimate percentile thứ 70 của value distributionw(s,a)= importance weights điều chỉnh theo chất lượng của từng data source
Tại sao expectile thay vì mean? Bởi vì data intervention imperfect thiên về phía thấp. Human intervention thường tạo ra trajectories có value thấp hơn mức tối ưu — do hesitation, do redundant moves, do vào muộn. Nếu học mean, V(s) sẽ bị kéo xuống. Expectile với τ > 0.5 học estimate phía trên: "nếu state này có thể đạt được trong điều kiện tốt thì value là bao nhiêu?"
Tưởng tượng bạn đánh giá năng lực học sinh qua điểm kiểm tra trong những ngày tốt lẫn xấu. Trung bình cộng sẽ underestimate khả năng thật. Nhìn vào percentile thứ 70 cho một bức tranh chính xác hơn.
Bước 3: H-step TD bootstrapping
ROVE dùng H=50-step lookahead thay vì 1-step TD thông thường. Lý do: manipulation task có nhiều bước, 1-step TD propagate reward quá chậm. Với H=50, value tại state t đã "nhìn thấy" reward từ 50 steps sau — đủ để biết liệu trajectory đang đi đúng hướng hay không.
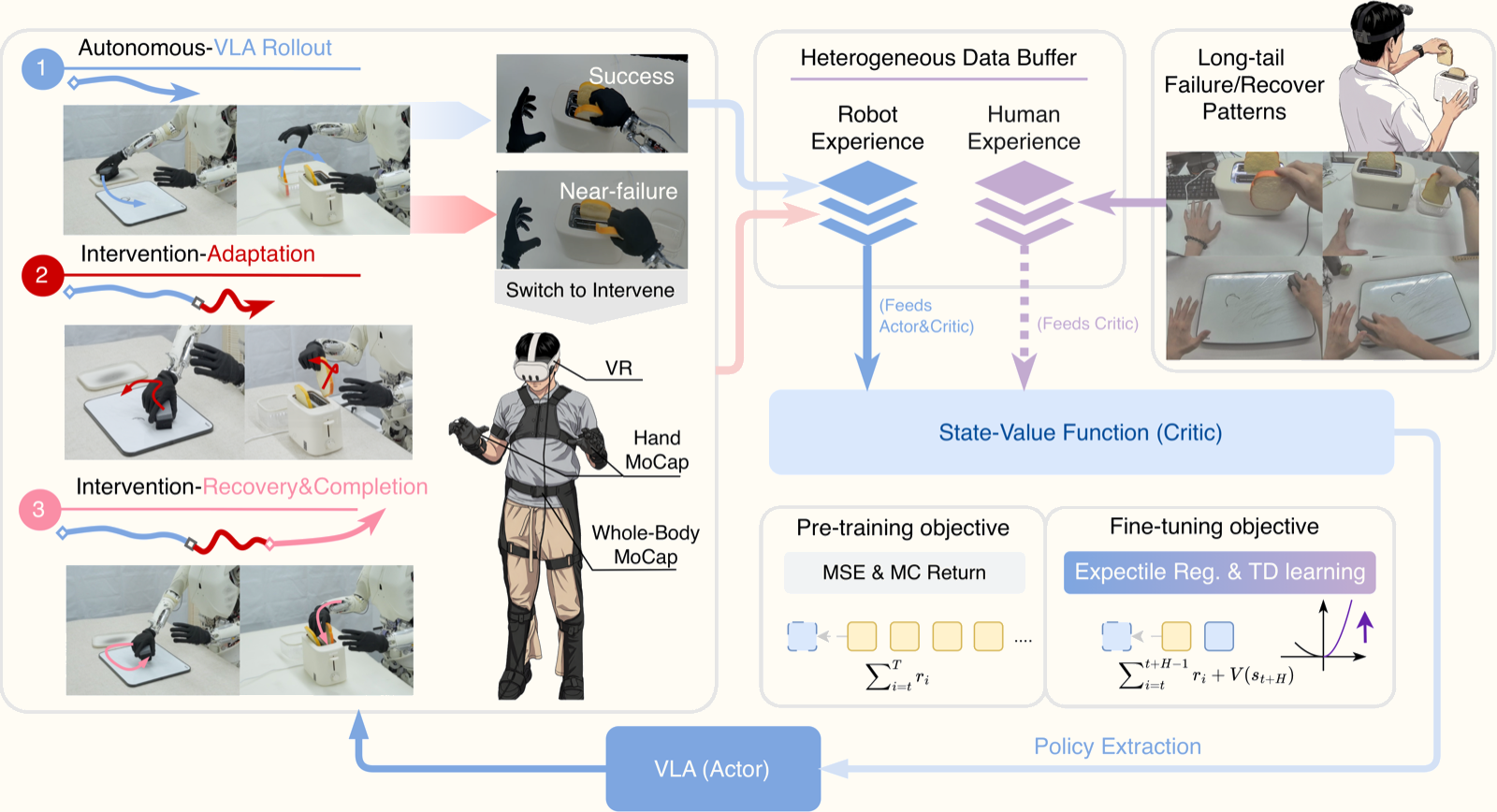
Cross-embodiment Human Experience Videos
ROVE tích hợp thêm 180 video egocentric của người thực hiện cùng task. Lý do:
Robot thường gặp long-tail scenarios — những trạng thái hiếm xảy ra trong autonomous rollout nhưng hay xảy ra khi có failure (vật bị rớt, gripper kẹt, orientation sai). Human demo video cover những tình huống này phong phú hơn nhiều.
Bởi vì V(s) là state-only (không cần action), video của người dùng không cần mapping action space. ROVE dùng visual features từ Qwen3-VL để encode frames từ video người và robot vào cùng representation space, sau đó tích hợp vào critic training.
Ablation trên 2 task cho thấy:
- Không có human video: critic gặp khó khăn phân biệt "good partial progress" vs "bad partial progress" ở intermediate states
- Có human video: accuracy tăng đáng kể — critic biết rằng "gripper đang tiếp cận đúng góc → high value" vs "gripper ở góc sai → low value"
Kiến trúc Critic và Actor
Critic (Value Function)
Input: RGB observation + proprioceptive state (50-D) + task text
↓
Qwen3-VL-4B (frozen VLM backbone)
↓
Layer 23 features → 2048-D representation
↓
Lightweight Transformer value head
↓
V(s) ∈ ℝ (scalar)
- Khởi tạo từ VLAC checkpoint (pre-trained value critic)
- Freeze toàn bộ VLM backbone, chỉ train value head
- State dropout 0.3 + Gaussian noise 0.4 để regularize, tránh overfit trên distribution hẹp của intervention data
Actor (Policy)
Input: RGB observation + proprioceptive state + task text
↓
Qwen3-VL-4B-Instruct (frozen VLM backbone)
↓
DiT (Diffusion Transformer) action decoder
↓
Action chunk: H=16 steps × 50-D per step
Actor được cập nhật bằng advantage conditioning: thay vì RL gradient trực tiếp, ROVE gán binary label cho mỗi segment dựa trên value function:
A(s,a) = V(s') − V(s) > threshold(70th percentile) → label = 1 (keep)- Ngược lại → label = 0 (filter)
Sau đó, actor chỉ được fine-tune trên positive segments thông qua supervised loss — một dạng offline RL nhẹ không cần policy gradient và không cần simulator.
Training Pipeline Thực Tế
ROVE train theo 2 phase, lặp lại qua nhiều iterations:
Phase 1: Train Critic
# Approximate config
critic_config = {
"checkpoint": "vlac-base",
"tau": 0.7, # Expectile parameter
"horizon": 50, # H-step TD lookahead
"num_steps": 8000,
"num_gpus": 8,
"batch_size": 64,
"lr": 1e-4, # 1e-5 cho các iterations tiếp theo
"state_dropout": 0.3,
"gaussian_noise": 0.4,
}
Phase 2: Train Actor (Advantage Conditioning)
actor_config = {
"base_policy": "sft_checkpoint",
"critic": "critic_iter_N",
"advantage_threshold": "p70", # percentile thứ 70
"num_steps": 8000,
"num_gpus": 8,
"batch_size": 16,
"lr": 1e-4,
}
Iteration loop:
- Deploy policy hiện tại → collect rollouts (~75–90 episodes/iteration)
- Human operator intervenes on failures (4.5–25.5% episodes tùy task)
- Train critic (Phase 1) trên rollout data + human video data
- Extract advantages, filter positive segments (> 70th percentile)
- Fine-tune actor (Phase 2)
- Lặp lại với policy mới
Data scale mỗi iteration:
| Task | Initial demos | Episodes/iter | Intervention rate |
|---|---|---|---|
| Erase whiteboard | 225 | ~75 | 25.5% |
| Put bread in toaster | 220 | ~90 | 4.5% |
| Human egocentric videos | — | — | 180/task |
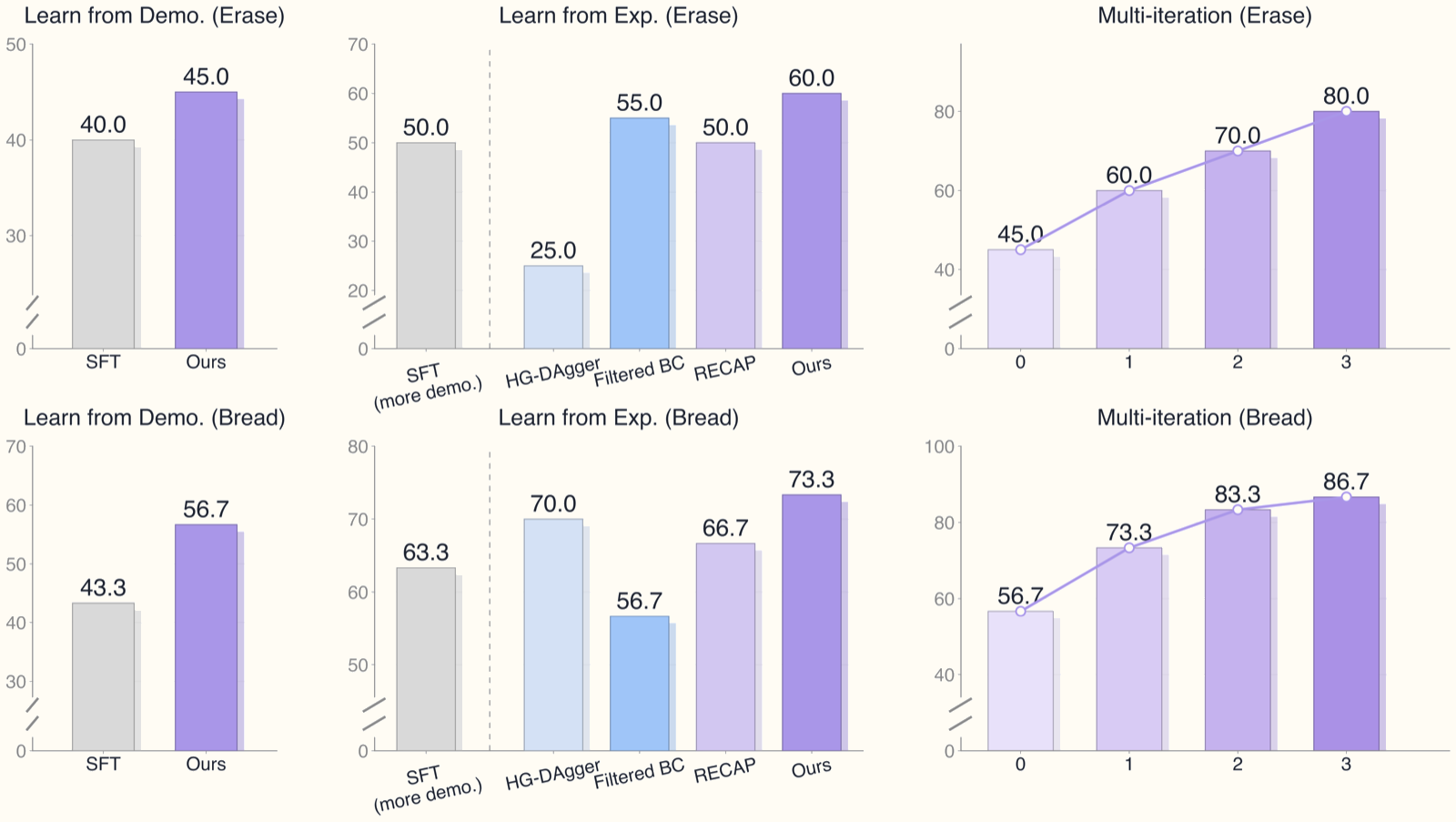
Kết Quả: Cải Thiện Qua Từng Iteration
Kết quả real-world trên robot humanoid thực tế với 2 task contact-rich:
| Task | Iteration 0 | Iteration 3 | Tăng |
|---|---|---|---|
| Put bread in toaster | 56.7% | 86.7% | +30 pp |
| Erase whiteboard | 45.0% | 80.0% | +35 pp |
So sánh với baselines sau 3 iterations (task erase whiteboard):
| Method | Success Rate |
|---|---|
| SFT (demonstrations only) | ~45% |
| Filtered BC | ~52% |
| HG-DAgger | ~55% |
| RECAP | ~58% |
| ROVE (proposed) | 80% |
Gap so với HG-DAgger đặc biệt có ý nghĩa — cả hai đều thu thập intervention data, nhưng ROVE xử lý mixed-quality trajectories đúng cách tạo ra sự khác biệt quyết định.
Ablation: OVE vs Monte Carlo
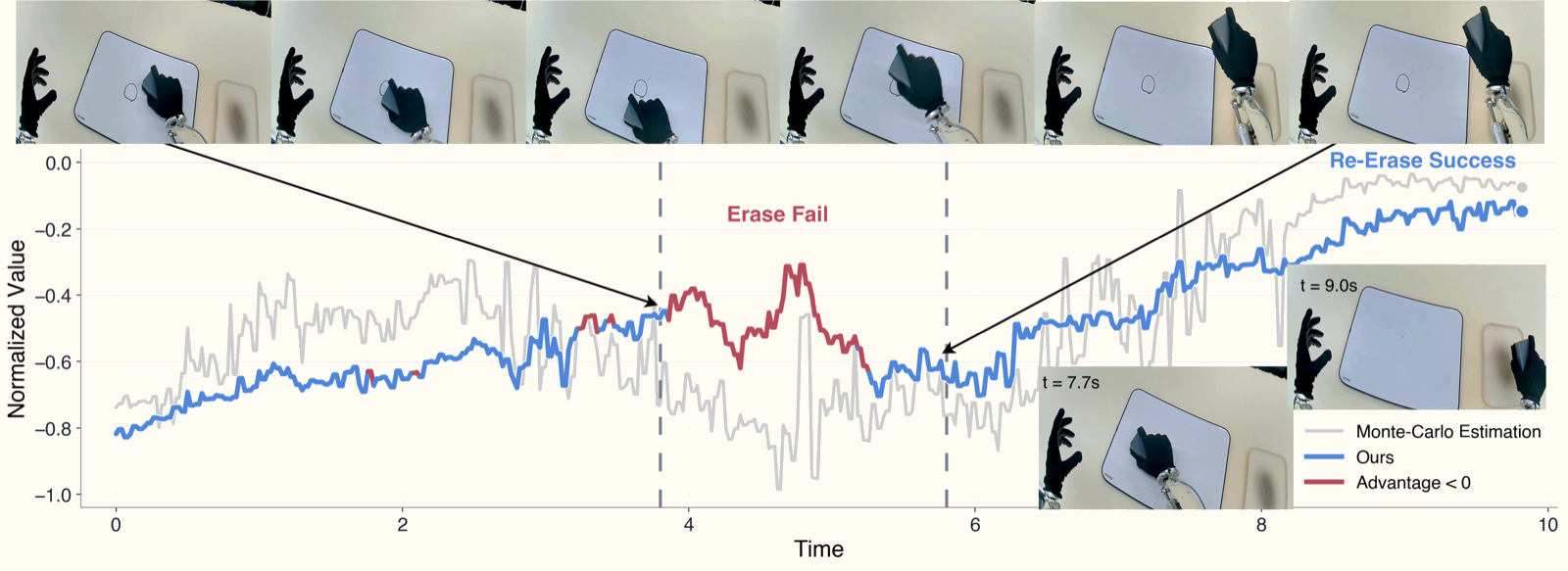
Monte Carlo returns bị underestimate ở intermediate states — đúng như lý thuyết expectile dự đoán. Human intervention tạo ra trajectories dài hơn, nhiều hesitation hơn → discounted sum reward thấp hơn mức tối ưu → MC V(s) bị kéo xuống thấp. OVE với τ=0.7 cắt được bias này, cho estimate phản ánh tiềm năng thực của state thay vì chất lượng trung bình của trajectories đi qua nó.
Khi Nào Nên Dùng ROVE?
ROVE phù hợp khi bạn có:
- VLA policy đã pre-trained (Qwen3-VL hoặc tương đương) cần fine-tune cho task cụ thể
- Human operator có thể can thiệp trong lúc robot rollout (không cần expert-level)
- Contact-rich manipulation — tasks cần precision cao như insertion, erasing, assembly
- Iterative deployment cycle — có thể triển khai → thu thập → retrain nhiều vòng
ROVE ít phù hợp khi:
- Cần train VLA từ đầu hoàn toàn (ROVE là post-training method)
- Task đơn giản đủ để giải bằng SFT thuần túy
- Không có humanoid teleop infrastructure
- Compute bị giới hạn nghiêm (cần 8 GPU riêng cho training)
Điểm Đáng Học Từ ROVE
1. Value function là cầu nối giữa imitation và RL. ROVE không dùng policy gradient, không cần simulator, không cần reward engineering — nhưng vẫn đạt được hiệu ứng RL qua value-based filtering và advantage conditioning.
2. Expectile regression là công cụ mạnh cho offline RL với mixed data. IQL (Implicit Q-Learning) và các offline RL methods khác cũng dùng expectile. ROVE mở rộng concept này sang humanoid manipulation với cross-embodiment data.
3. Human experience video "cứu" critic ở long-tail states. Critic train chỉ trên robot data có blind spots ở các intermediate states hiếm. Human video cover những tình huống này với diversity cao hơn robot rollout có thể đạt được.
4. Iteration quality quan trọng hơn data volume. ROVE cải thiện đều qua 3 iterations với ~90 episodes mỗi lần. Collect 1000 episodes một lần rồi train không hiệu quả bằng train iteratively — policy improvement loop là cơ chế tạo ra improvement.
Kết Luận
ROVE đặt ra một câu hỏi thực tế mà bất kỳ ai deploy VLA trên humanoid sẽ gặp: khi robot fail và người điều khiển nhảy vào cứu, làm thế nào dùng data đó hiệu quả?
Câu trả lời của XPENG Robotics — Optimistic Value Estimation để trích xuất signal từ mixed-quality trajectories — là bước tiến đáng kể so với Filtered BC hay DAgger. Đặc biệt ấn tượng là ROVE không cần simulator, không cần reward engineering, và chỉ cần intervention rate thấp (4.5% cho toaster task) để tạo ra improvement lớn. Đây là định hướng thực tế cho post-training VLA trên humanoid trong điều kiện production.
Paper gốc: ROVE arxiv 2606.17011 — XPENG Robotics, Fudan University, CUHK, SJTU, tháng 6/2026.
Bài Viết Liên Quan
- UniIntervene: Real-world RL với Human Intervention — framework khác cho human-in-the-loop RL trên robot thực tế
- HILSERL: Real Robot RL qua Human Feedback trong LeRobot — RL từ human feedback trong LeRobot framework
- ProcVLM: Dense Reward từ Video cho VLA — dùng video để học dense reward, bổ sung cho approach của ROVE