ABot-M0: VLA Foundation Model with Action Manifold Learning from AMAP CVLab
In March 2026, the AMAP CVLab team at Alibaba Group released ABot-M0 — a VLA foundation model for robotic manipulation, together with full code, pretrained weights, and the data processing pipeline. The most interesting bit is not the scale (though their UniACT training set with 6+ million trajectories and 9,500 hours of data is currently the largest open mixture), but a paradigm shift in how the model learns actions: instead of learning noise like familiar diffusion policies, ABot-M0 directly learns clean actions lying on a low-dimensional manifold shaped by physics and task constraints.
This post walks from the core idea, through the architecture, to running the pretrained weights yourself. Useful for engineers looking for a "plug-and-play" VLA on their own robot arm or humanoid.
References: ABot-M0 paper on arXiv, the official project page, GitHub repo, and HuggingFace weights.

1. The core idea: Action Manifold Hypothesis
If you've ever trained Diffusion Policy or π0, the familiar recipe is: add Gaussian noise to an action chunk, then have the model denoise — predicting the noise step-by-step to recover the clean action. It's powerful, but ABot-M0 calls out two problems:
- Slow decoding — many denoising steps per action chunk.
- Instability across embodiments — a shared noise schedule applies to all robots, yet Franka, Aloha, UR-5, and dual-arm humanoids have very different action spaces, so the denoising process doesn't converge at the same rate.
The AMAP team proposes a hypothesis: in high-dimensional action space, successful actions are not scattered uniformly — they lie on a low-dimensional manifold shaped by physical constraints (kinematics, dynamics, contact), task goals, and environment. A pick-and-place trajectory isn't any random sequence in $\mathbb{R}^{T \times 7}$ — it's a thin slice within it.
If the manifold truly exists, we should learn a projection onto it rather than the noise. In code, the loss shifts from:
# Diffusion policy
noise_pred = model(noisy_action, t, obs)
loss = mse(noise_pred, true_noise)
to:
# Action Manifold Learning (AML)
action_pred = model(latent, obs)
loss = mse(action_pred, clean_action)
Much simpler, but to prevent the model from collapsing to the mean action, AML adds a few mechanisms: a structured latent prior, action-sequence smoothness regularization, and a residual head to capture fine detail. The paper's ablation shows AML both reduces decode steps and improves stability when training on heterogeneous cross-embodiment data.
To compare these two paradigms in a single codebase, read Diffusion Policy first — it explains denoising in detail and makes it clear where AML "inverts" the formulation.
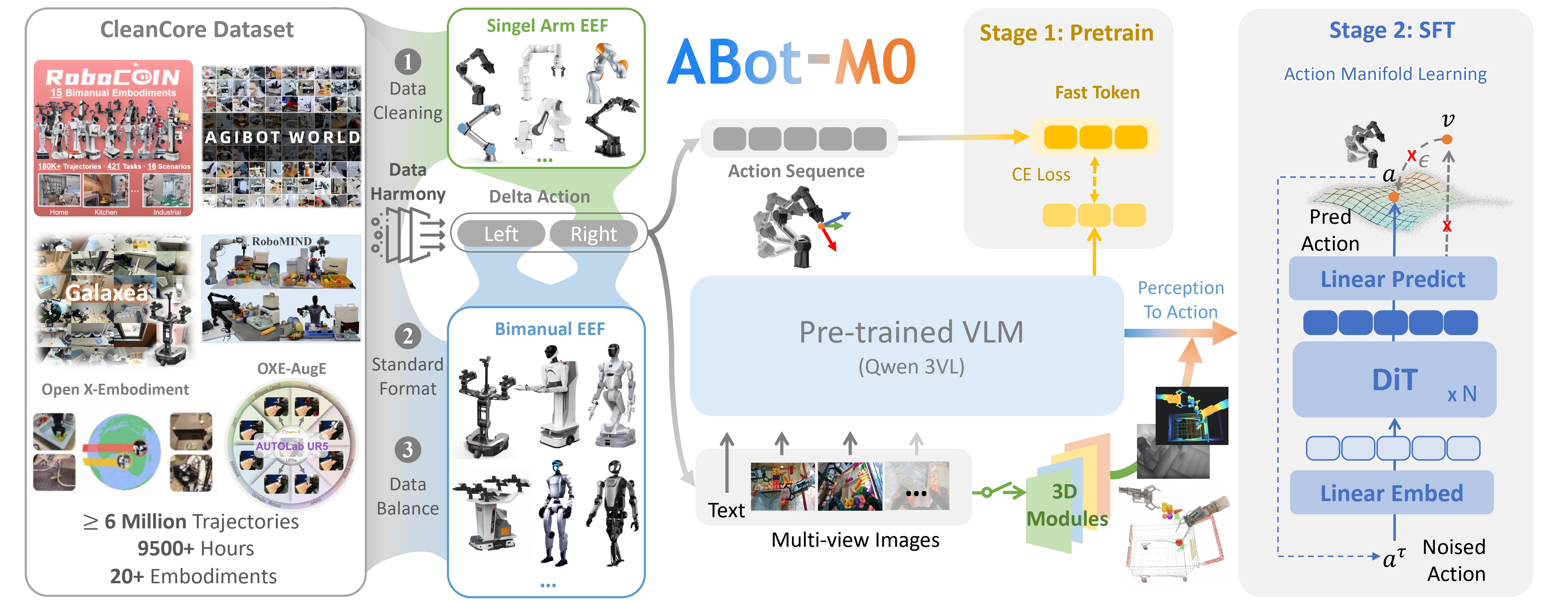
2. Overall architecture
ABot-M0 uses a familiar DiT (Diffusion Transformer) backbone, but reworks the output head to emit actions directly instead of noise. There are three main blocks:
(a) VLM encoder — Takes multi-view RGB + a text instruction. Outputs semantic tokens describing "what to do, what is seen".
(b) 3D perception adapter (plug-and-play) — A clever design choice: ABot-M0 doesn't force a specific 3D module. You can plug VGGT (Visual Geometry Grounded Transformer) for dense point maps, or Qwen-Image-Edit for geometric priors, without touching the backbone. 3D tokens are concatenated alongside VLM tokens.
(c) Action manifold decoder — A transformer mapping (semantic tokens, 3D tokens, robot state) to an action chunk in manifold space. The final un-projection head converts manifold latents back to delta-actions in end-effector coordinates.
A key technical detail for cross-embodiment: actions are normalized to end-effector delta with rotation vector representation (3D rotation, not 4D quaternion or 9D matrix). Why: rotation vectors are more continuous than quaternions (no double-cover ambiguity), more compact than matrices, and the delta range is easier to normalize across robots. For mixing single-arm and dual-arm data, they use pad-to-dual: always pad to 2 arms (14-DoF action), and zero-out the second arm for single-arm samples — so one model serves both.

3. UniACT Dataset — 6M+ trajectories
The data engineering behind ABot-M0 is arguably more valuable than the model itself. They merge six largest public datasets (Open X-Embodiment, DROID, AgiBot-Beta, RoboMIND, RH20T, BridgeData V2…) into UniACT-dataset with:
- 6,000,000+ trajectories
- 9,500+ hours of interaction
- 20+ embodiments (Franka Panda, UR-5, Aloha, Kuka, Galaxea, AgiBot, humanoid GR1/GR2…)
The pipeline has four stages:
- Filter invalid samples — drop trajectories with empty instructions, blurry frames, or NaN actions.
- Action normalization — convert to delta end-effector (rotation vector), normalize using per-embodiment statistics.
- Pad-to-dual — as described above.
- Re-balance — over/under-sample by embodiment so a giant dataset (like OXE) doesn't dominate every gradient step.
If you've done imitation learning before, you know how critical step 4 is. A dataset that's 70% Franka pick-and-place will yield a model that's only good at Franka pick-and-place, regardless of how "cross-embodiment" you claim.
4. Benchmark results
ABot-M0 sits at or near the top on the main benchmarks:
| Benchmark | ABot-M0 | GR00T-N1.6 | X-VLA | π0-FAST |
|---|---|---|---|---|
| LIBERO (avg 4 suites) | 98.6% | 97.0% | 98.1% | 96.4% |
| LIBERO-Plus (zero-shot, 7 shifts) | 80.5% | — | — | — |
| RoboCasa-GR1 (24 tasks) | 58.3% | 47.6% | — | — |
| RoboTwin2.0 Clean | 80.4% | — | — | — |
| RoboTwin2.0 Randomized | 81.2% | — | — | — |
The most informative number isn't LIBERO (saturated) but LIBERO-Plus zero-shot 80.5% — a stress-test with 7 distribution shifts (lighting, camera pose, distractors, language paraphrasing…). Topping that table is a real signal that the manifold actually generalizes, not just memorizes.
5. Installation
Minimum hardware for inference: 1× 24GB GPU (RTX 4090, A5000), 32GB RAM. For full fine-tuning: 4× A100 80GB or equivalent.
# Clone repo
git clone https://github.com/amap-cvlab/ABot-Manipulation.git
cd ABot-Manipulation
# Conda env
conda create -n ABot python=3.10 -y
conda activate ABot
# Core deps
pip install -r requirements.txt
# FlashAttention2 (required for the DiT backbone)
pip install flash-attn --no-build-isolation
# VGGT for 3D perception (optional, plug-and-play)
pip install vggt
# Install ABot package
pip install -e .
Common first-run errors:
flash-attnbuild fails → CUDA toolkit mismatch. Make sure CUDA 12.x is installed andnvcc --versionmatches your PyTorch CUDA build.ModuleNotFoundError: vggt→ either runpip install vggt, or use a variant that doesn't need a 3D adapter (you can skip it).
6. Inference with pretrained weights
There are 4 variants under HuggingFace acvlab/:
| Variant | Use case |
|---|---|
ABot-Pretrain |
Generalist backbone, fine-tunable |
ABot-LIBERO |
Fine-tuned for LIBERO, ready to eval |
ABot-RoboCasa-GR1 |
Tabletop manipulation with humanoid GR1 |
ABot-RoboTwin2 |
Dual-arm Clean + Randomized |
Basic inference with the LIBERO weights:
from abot import ABotPolicy
from abot.envs import LiberoEnv
# Load policy
policy = ABotPolicy.from_pretrained("acvlab/ABot-LIBERO", device="cuda")
# Env LIBERO Spatial
env = LiberoEnv(suite="libero_spatial", task_id=0)
obs = env.reset()
for step in range(200):
# ABot-M0 predicts a clean action chunk (H=16 steps)
action_chunk = policy.predict(
rgb_images=obs["images"], # multi-view RGB
instruction=obs["language"], # text
robot_state=obs["state"], # joint + gripper
)
# Execute the first step of the chunk, then re-predict (open-loop chunking)
obs, reward, done, info = env.step(action_chunk[0])
if done:
break
On a single RTX 4090, decoding one action chunk takes about 80ms — faster than typical diffusion policy (200-400ms for 50 denoising steps), because AML only needs one forward pass.
7. Fine-tuning on your own robot
Recommended workflow:
- Collect teleop data — at least 50-100 demos for a simple task, 200-500 for tasks with multiple objects or phases.
- Convert to UniACT format —
data_process/convert_to_uniact.pyin the repo handles this. You'll need: RGB from cameras (≥2 views recommended), language instruction, robot state, delta end-effector action. - Fine-tune from
ABot-Pretrain:
python examples/finetune.py \
--pretrained acvlab/ABot-Pretrain \
--dataset /path/to/your_dataset \
--output_dir ./checkpoints/my_robot \
--batch_size 32 \
--learning_rate 1e-4 \
--num_epochs 30 \
--enable_3d_adapter vggt # optional
- Evaluate — run 10-20 rollouts on the real robot, log success rate. If you see <50% on a simple task → audit your data quality before throwing more epochs at it.
If you're fine-tuning on a full-body humanoid, the recent Whole-Body VLA paper has a data recipe compatible with ABot's dual-arm structure.
8. Comparison with other VLAs
| Model | Params | Predict target | Cross-embodiment data | Open weights |
|---|---|---|---|---|
| RT-2 | ~55B | Action token | Limited | ❌ |
| OpenVLA | 7B | Action token | OXE | ✅ |
| π0 / π0-FAST | 3B | Noise (flow) | DROID + custom | Partial |
| GR00T-N1.6 | 2-3B | Noise (diffusion) | Mixed | ✅ |
| ABot-M0 | 2-3B | Clean action (AML) | UniACT 6M | ✅ full |
ABot-M0 isn't the biggest, nor the absolute SOTA on every benchmark, but as of 2026 it's the most complete open-source package: code, pretrained, data pipeline, and eval scripts are all public, with a commercial-friendly license (double-check the repo before shipping to production).
For a wider view of the VLA landscape, see the VLA models overview and VLA-0: action as text — VLA-0 goes the opposite direction (text tokens instead of a continuous manifold), and comparing the two approaches is genuinely illuminating.
9. Deployment pitfalls
- Don't skip the 3D adapter too early — running with RGB tokens only works, but on spatial reasoning tasks (LIBERO-Spatial, stacking) VGGT or Qwen-Image-Edit improves success rate by ≥5%.
- Chunk horizon H — default is H=16. If your robot runs at 10Hz, that's 1.6s open-loop, which can be too long for contact-rich tasks. Drop to H=8 if the gripper drifts.
- Camera calibration — ABot-M0 expects intrinsics close to the DROID/OXE setup. Cameras that are too wide (FOV >120°) or too narrow (FOV <40°) confuse the 3D adapter. Calibrate before blaming the model.
- Don't overfit pad-to-dual — single-arm robots padded to dual should have the second arm at zero, but if your fine-tune data leaves dummy actions non-zero, the model learns spurious patterns.
10. Roads not taken
Three directions AMAP tried and dropped, worth knowing:
- Score matching on the manifold — more complex than AML without better success rates, and training was less stable.
- Token-based actions à la RT-2 / VLA-0 — simpler code, but lower precision on continuous control tasks (grasping a cup, gentle pushes).
- End-to-end 3D backbone — instead of a plug-and-play 3D adapter. Compute-heavy, hard to scale, and loses modularity.
Keeping the modular 3D + AML head is the reason the repo is so research-friendly — swapping modules is trivial.
Related Posts
- VLA-Adapter from OpenHelix: Tiny-Scale VLA on 9.6GB VRAM — opposite end of the scale spectrum.
- Manipulation Series #4: Vision-Language-Action Models — the VLA foundations before diving into ABot.
- GigaBrain-0: VLA + World Model + RL — how to bolt a world model alongside a VLA backbone.