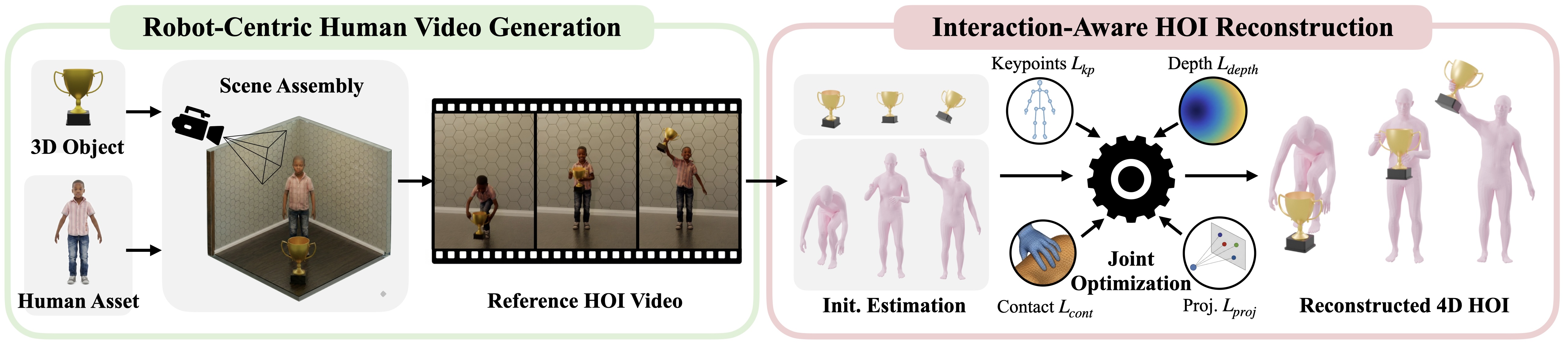
Trong bài 1, chúng ta đã xem asset 3D và terrain như lớp dữ liệu có metric scale. Trong bài 2, Blender dựng frame điều kiện, camera, depth, rồi Kling tạo video 2D human-object interaction. Bài 3 đi vào bước khó nhất của nhánh manipulation: tái dựng 4D HOI từ video.
"4D" ở đây không có gì huyền bí: đó là 3D cộng thời gian. Output không chỉ là một mesh người ở một frame, mà là chuỗi pose người, pose tay, pose object và contact theo từng frame. Tài liệu GRAIL mô tả stage này là quá trình khôi phục full human-object interaction gồm SMPL-X body pose, MANO hand pose và object trajectory 6-DoF. Nói theo cách robotics: từ một video RGB ngắn, pipeline cần trả lời các câu hỏi downstream sẽ dùng để train robot: người đứng ở đâu, tay chạm vào đâu, object xoay/dịch chuyển thế nào, khi nào contact bắt đầu, và kết quả có đủ sạch để retarget sang Unitree G1 không.
GRAIL có lợi thế hơn các pipeline tái dựng video in-the-wild vì nó không bắt đầu từ video lạ. Trang dự án NVIDIA nhấn mạnh rằng GRAIL bắt đầu từ cấu hình 3D đã biết: geometry object, camera parameters, metric scale, environment depth và character có tỷ lệ phù hợp robot. Bước recon_4dhoi tận dụng chính "privileged context" này để giảm ambiguity về scale, camera và hình học object.
Nguồn kỹ thuật chính dùng trong bài:
- GRAIL project page
- GRAIL GitHub README
- 4D HOI Reconstruction docs
- recon_4dhoi.py
- manip_smplx.yaml
- SAM2, MoGe, FoundationPose, WiLoR, ScenePic, PyTorch3D
Roadmap series
- Tạo asset 3D và terrain cho GRAIL: hai nhánh asset, prompt object, sharding và chuẩn bị file cho downstream.
- Sinh video 2D HOI bằng Blender và Kling: render frame điều kiện, camera/depth và video foundation model.
- Tái dựng 4D HOI: GEM, SAM2, MoGe: pose người, object tracking, optimization, filtering và visualization.
- Locomotion trên terrain tĩnh: dùng curb, slope, stairs cho scene-centric motion.
- Retarget trajectory sang Unitree G1: chuyển motion người/object thành mục tiêu robot.
- Train policy và export dữ liệu: đóng gói demonstration, train tracker/policy và chuẩn bị sim-to-real.
Nếu bạn muốn đặt bài này vào bối cảnh rộng hơn của whole-body policy, có thể đọc thêm NVIDIA GR00T/SONIC cho whole-body VLA và LeRobot v0.5 với humanoid G1. Hai bài đó giải thích vì sao dữ liệu motion sạch, có object và contact, quan trọng hơn một video đẹp.
Mục tiêu của bài
Sau bài này, bạn sẽ hiểu sáu stage của grail.pipelines.recon_4dhoi, biết lệnh smoke test, biết tìm output ở đâu, biết đọc nhanh hoi_data/hoi_data.pkl, recon_result.mp4, recon_comparison.mp4, và biết chỉnh các trường quan trọng trong configs/recon_4dhoi/manip_smplx.yaml: opt_stage_specs.init_opt, contact_opt, filter_object_motion: dynamic_only, và pipeline.is_static_obj.
Lệnh cơ bản cho object manipulation:
python -m grail.pipelines.recon_4dhoi \
--dataset ComAsset \
--category cordless_drill \
--results_dir results
Lệnh chạy một video cụ thể:
python -m grail.pipelines.recon_4dhoi \
--video_id ComAsset/cordless_drill/<video_name> \
--results_dir results
Nếu bạn đã chạy xong pose người, mask/depth và object pose, rồi chỉ muốn chạy lại optimization sau khi chỉnh config:
python -m grail.pipelines.recon_4dhoi \
--dataset ComAsset \
--category cordless_drill \
--results_dir results \
--skip_step1 \
--skip_step2 \
--skip_step3
Đừng chạy lệnh này từ thư mục blog. Bạn cần chạy từ root repo GRAIL, trong môi trường đã cài checkpoint. README chính thức dùng Docker, cài Blender và checkpoint, rồi chạy bash scripts/setup/download_checkpoints.sh để tải GEM-SMPL/GEM-SOMA/FoundationPose weights.
Bản đồ sáu stage
recon_4dhoi là một stack nhiều model. Beginner thường gặp lỗi vì nghĩ đây là một model end-to-end duy nhất. Thực tế, mỗi stage tạo cache cho stage sau:
| # | Stage | Công cụ chính | Input | Output dùng tiếp |
|---|---|---|---|---|
| 1 | Human pose | GEM-SMPL hoặc GEM-SOMA, WiLoR | Video RGB | .npz pose người, keypoint body/tay |
| 2 | Preprocess | SAM2, MoGe, camera/depth cache | Video, first-frame masks, camera | mask object/người theo frame, depth/point cloud |
| 3 | Object pose | FoundationPose | RGB, mask object, mesh OBJ | object 6-DoF pose theo frame |
| 4 | HOI optimization | HOIOptimizer |
pose người, object pose, mesh, depth, masks | hoi_data.pkl thô |
| 5 | Filter và post-process | threshold, contact/motion checks | hoi_data.pkl thô |
folder _valid, mesh_data, video so sánh |
| 6 | Visualization | PyTorch3D, ScenePic | HOI đã lọc | MP4 overlay, top view, HTML 3D |
Tài liệu GRAIL ghi thời gian tham khảo trên L40S: human pose khoảng 45 giây/video, SAM2 + MoGe khoảng 36 giây/video, FoundationPose khoảng 40 giây/video, còn HOI optimization là phần nặng nhất, khoảng 9-10 phút/video. Con số này không phải SLA; nó giúp bạn biết stage nào đáng shard, stage nào chỉ cần cache lại.
Stage 1: GEM-SMPL và WiLoR cho pose người
Stage 1 gọi run_human_pose_est. Với config mặc định manip_smplx.yaml, human_model.body_model là g1_smplx. Điều này nói với pipeline rằng output cần tương thích thân người SMPL-X đã được điều chỉnh cho G1, không phải một body model chung chung.
GEM là model human motion của NVIDIA cho monocular video. Model card GEM-X mô tả GEM như một hệ ước lượng 3D body pose từ video RGB, có global motion trajectory và local body kinematics. Trong GRAIL, tài liệu reconstruction nói stage này dùng GEM-SMPL body và WiLoR hands, rồi fuse per-frame. WiLoR là model 3D hand localization/reconstruction in-the-wild; paper và repo của WiLoR nhấn mạnh pipeline có hand localization real-time và 3D reconstruction dựa trên MANO. Với manipulation, phần tay không phải chi tiết phụ. Nếu wrist, finger hoặc hand keypoint lệch, optimizer có thể "ép" contact sai vào object.
Output chính của stage 1 thường nằm dưới:
results/generation/hmr_smplx/
results/generation/hmr_smplx_cache/
Trong code, stage này lưu cả motion_global và motion_incam. Bạn có thể hiểu đơn giản:
motion_incam: pose trong hệ camera, hữu ích cho reprojection/keypoint tracking.motion_global: pose đã có global trajectory, cần cho motion 4D theo thời gian.- cache keypoint: dùng để debug tay/chân có bám video không.
Lỗi beginner hay gặp: video Kling có người bị crop chân hoặc tay, nhưng bạn vẫn chạy reconstruction. Khi stage 1 thiếu keypoint ổn định, các stage sau không thể "sửa kỳ diệu". Nếu recon_result.mp4 cho thấy skeleton trượt khỏi người ngay từ đầu, hãy quay lại kiểm tra video 2D hoặc frame render ở bài 2.
Stage 2: SAM2 mask tracking và MoGe depth
Stage 2 làm hai việc: track mask và ước lượng depth. Trong code, preprocess_masks dùng mask object/human ở first frame từ output render/FoundationPose input, rồi track qua video. SAM2 phù hợp cho việc này vì Meta giới thiệu nó như một model segmentation thống nhất cho image và video, có thể segment object trong ảnh/video và theo dõi qua frame. Với GRAIL, SAM2 giúp biến video RGB thành hai tín hiệu rất thực dụng: vùng pixel của object và vùng pixel của người.
Sau mask là depth. GRAIL dùng MoGe cho monocular geometry estimation khi cần depth từ ảnh/video. MoGe là project của Microsoft cho open-domain monocular geometry; trong pipeline này, depth không dùng một mình, mà kết hợp với camera intrinsic, mask và mesh để tạo ràng buộc hình học cho optimizer.
Cache quan trọng:
results/generation/4dhoi_recon_cache/masks/<video_id>.npz
results/generation/4dhoi_recon_cache/depth/<video_id>.pt
Nếu --verbose, pipeline có thể xuất debug mask/depth. Bạn nên bật verbose khi thêm object mới, khi object bị occlude nhiều, hoặc khi video model tạo bàn tay che object quá lâu. Mask sai thường nhìn thấy ngay: object mask nhảy sang tay người, mất object trong vài frame, hoặc dính cả background. Depth sai khó thấy hơn, nhưng hậu quả là object/human bị kéo sai theo trục z.
Một checklist thực dụng:
| Hiện tượng | Nguyên nhân thường gặp | Hành động |
|---|---|---|
| Object mask mất sau khi người chạm | SAM2 bị occlusion hoặc object quá nhỏ | Render camera gần hơn, tăng kích thước object, chọn video rõ hơn |
| Human mask dính object | Object cùng màu/quá sát cơ thể | Kiểm tra first-frame masks, giảm occlusion trong prompt video |
| Depth làm object nổi hoặc chìm | Monocular depth thiếu anchor | Dùng depth GT nếu có, kiểm tra camera/depth từ bài 2 |
| Cache không đổi dù đã sửa video | --skip_done dùng cache cũ |
Xóa cache liên quan hoặc tắt --skip_done |
Stage 3: FoundationPose cho object 6-DoF
Stage 3 chạy FoundationPose để track pose object. FoundationPose là model NVIDIA cho 6D pose estimation và tracking of novel objects, hỗ trợ cả model-based setup khi có CAD/mesh object. GRAIL đúng là có mesh object từ bài 1, nên object tracking không cần đoán category từ zero.
6-DoF nghĩa là object có 3 bậc tự do translation và 3 bậc tự do rotation. Với robot manipulation, đây là dữ liệu cực quan trọng. Nếu drill được nâng lên nhưng tracker giữ nó đứng yên trên bàn, policy downstream sẽ học sai. Nếu rotation quanh trục dài bị flip, grasp/contact có thể không còn ăn khớp.
Stage 3 đọc mesh từ:
results/generation/mesh/<dataset>/<category>/*.obj
và output pose:
results/generation/foundation_pose_output/<video_id>/pose_estimation_output/poses_in_cam.pkl
Trong manip_smplx.yaml:
obj_pose_tracking:
foundation_pose_debug: 2
crop_image: false
interpolation_factor: 1
foundation_pose_debug: 2 giữ mức debug khá hữu ích. crop_image: false nghĩa pipeline không crop image trước khi track; giữ toàn frame có thể ổn hơn khi camera/render đã sạch. interpolation_factor: 1 không nội suy thêm frame.
Trường cần hiểu là static/dynamic:
pipeline:
is_static_obj: false
Với manipulation/pickup, object được kỳ vọng di chuyển, nên is_static_obj: false để FoundationPose chạy tracking. Với terrain hoặc sitting, object/scene thường tĩnh; config locomotion đặt static-object mode để bypass FoundationPose. Nếu bạn đặt sai, filter ở stage 5 sẽ loại kết quả hoặc giữ nhầm kết quả vô nghĩa.
Stage 4: Multi-stage HOIOptimizer
Đây là trái tim của reconstruction. Ba stage đầu chỉ cho estimate riêng lẻ: pose người, mask/depth, pose object. HOIOptimizer biến chúng thành một trajectory HOI nhất quán hơn bằng cách tối ưu nhiều biến cùng lúc.
Một bản rút gọn của config:
optimization:
opt_stage_specs:
init_opt:
opt_vars:
human_trans_global: { lr: 0.003 }
human_trans_res: { lr: 0.003 }
human_pose_res: { lr: 0.0001 }
obj_t_res: { lr: 0.003 }
obj_R_res: { lr: 0.0001 }
niter: 400
loss_cfg:
keypoint_tracking: { weight: 0.3, beta: 0.1 }
human_smoothness: { weight: 30.0, beta: 0.1 }
human_pose_reg: { weight: 100.0 }
human_foot_contact: { weight: 10.0 }
obj_smoothness: { weight: 50.0 }
depth_pointcloud:
weight: 100.0
num_gt_samples: 3000
trim_pct: 0.2
depth_tol: 0.02
contact_opt:
niter: 200
loss_cfg:
contact:
weight: 30000.0
depth_only: true
max_contact_dist: 0.15
init_opt là stage kéo mọi thứ về cùng một hệ tọa độ hợp lý trước. Nó không nên quá hung hăng với pose residual, vì nếu pose người bị bẻ mạnh chỉ để fit object, motion sẽ mất tự nhiên. Các loss chính:
| Loss | Ý nghĩa |
|---|---|
keypoint_tracking |
Giữ pose render lại bám keypoint 2D trong video |
human_smoothness |
Tránh người giật frame-to-frame |
human_pose_reg |
Không để pose lệch quá xa prior |
human_foot_contact |
Giữ chân hợp lý với mặt đất khi cần |
verts_tracking |
Dùng vertex/mask alignment để kéo mesh bám ảnh |
obj_smoothness |
Tránh object trajectory giật |
depth_pointcloud |
Bám depth/point cloud để giảm lỗi z-scale |
contact_opt chạy sau khi có contact labels. Tài liệu GRAIL ghi stage 4 có OpenAI vision calls trong grail/core/contact_label.py để detect contact joints theo interval, mặc định dùng gpt-4o. Mục tiêu không phải để LLM "điều khiển robot"; nó chỉ giúp gán khoảng thời gian và joint nào có khả năng tiếp xúc object. Sau đó optimizer dùng loss contact để kéo điểm tay/cơ thể và object gần nhau trong những interval hợp lý.
Khi nào chỉnh init_opt?
| Triệu chứng | Gợi ý chỉnh |
|---|---|
| Người trượt khỏi video nhưng object ổn | Tăng nhẹ keypoint_tracking, kiểm tra stage 1 trước |
| Motion người rung | Tăng human_smoothness, không tăng quá cao |
| Object nhảy frame-to-frame | Tăng obj_smoothness, kiểm tra FoundationPose |
| Object sai độ sâu | Kiểm tra depth; chỉ tăng depth_pointcloud khi mask/depth đáng tin |
Khi nào chỉnh contact_opt?
| Triệu chứng | Gợi ý chỉnh |
|---|---|
| Tay gần object nhưng không chạm | Tăng contact weight hoặc max_contact_dist nhẹ |
| Tay bị hút xuyên object | Giảm contact weight, kiểm tra penetration/filter |
| Contact bắt đầu sai thời điểm | Chạy lại contact labeling hoặc kiểm tra video prompt |
| Object bị kéo theo tay khi chưa chạm | Chú ý obj_precontact_reg và interval contact |
Rule cho beginner: đừng sửa tất cả weight cùng lúc. Chọn một video, chạy lại từ stage 4, so sánh recon_comparison.mp4, rồi mới chỉnh tiếp.
Stage 5: Filtering và post-processing
Optimization luôn có thể trả ra một trajectory nhìn "có vẻ" hợp lý nhưng không đáng dùng cho training. Vì vậy stage 5 lọc kết quả. Tài liệu GRAIL liệt kê các threshold chính: human-position error, mask alignment, keypoint tracking, contact penalty, penetration và motion magnitude.
Trong manip_smplx.yaml:
filtering:
camera_trans_thr: 0.1
object_mask_tol: 0.5
total_mask_tol: 0.3
human_static_thr: 0.01
min_frames: null
filter_object_motion: "dynamic_only"
object_static_thr: 0.02
filter_object_motion: dynamic_only là một chi tiết quan trọng. Bài này là manipulation/pickup, nên pipeline muốn loại những reconstruction trong đó object gần như không di chuyển. Nếu video chỉ có người đứng cạnh drill, hoặc FoundationPose thất bại và object trajectory bị static, kết quả đó không có ích cho manipulation policy. Ngược lại, với locomotion terrain ở bài 4, object/terrain tĩnh lại là đúng; config locomotion dùng static_only.
Khi một result pass filter, pipeline đóng gói vào:
results/generation/4dhoi_recon_smplx_valid/<dataset>/<category>/<video_id>/
hoi_data/
hoi_data.pkl
mesh_data/
model.obj
model.mtl
...
result_vis/
input.mp4
recon_result.mp4
recon_result_top_view.mp4
recon_comparison.mp4
recon_result.html
Nếu result fail, bạn sẽ thấy marker invalid trong folder output thô. Đừng chỉ xóa marker để ép dữ liệu vào training. Filter fail thường có lý do: mask kém, pose người sai, object không động, contact phi vật lý hoặc motion quá ngắn.
Stage 6: ScenePic và PyTorch3D visualization
Visualization không phải phần phụ để làm đẹp. Nó là cách nhanh nhất để bạn quyết định trajectory có đáng retarget không. Tài liệu GRAIL nói stage visualize dùng PyTorch3D top-down và side-by-side renders, cùng ScenePic HTML. PyTorch3D cung cấp rendering 3D/differentiable rendering trong hệ PyTorch/CUDA; ScenePic là thư viện 3D visualization xuất HTML nhẹ, mở được bằng browser mà không cần Blender.
Ba file nên mở sau mỗi run:
| File | Bạn kiểm tra gì |
|---|---|
result_vis/recon_result.mp4 |
Mesh người/object có bám video input không |
result_vis/recon_comparison.mp4 |
So sánh input và reconstruction side-by-side |
result_vis/recon_result.html |
Xoay scene 3D, nhìn top/side, kiểm tra contact và penetration |
recon_result_top_view.mp4 đặc biệt hữu ích cho lỗi không thấy trong camera view. Một reconstruction có thể khớp ảnh 2D nhưng sai chiều sâu: nhìn từ camera thì ổn, nhìn top view thì tay cách object 30 cm. Đây là lý do GRAIL dùng camera/depth/mesh thay vì chỉ fit silhouette 2D.
Đọc nhanh hoi_data/hoi_data.pkl
hoi_data.pkl là artifact chính. Nó là pickle Python, nên bạn không nên mở bằng text editor. Dùng script nhỏ:
import pickle
from pathlib import Path
path = Path("results/generation/4dhoi_recon_smplx_valid/ComAsset/cordless_drill/<video_id>/hoi_data/hoi_data.pkl")
with path.open("rb") as f:
hoi = pickle.load(f)
print(hoi.keys())
print(hoi["human_data"].keys())
print(hoi["object_data"].keys())
print(hoi["meta"].keys())
poses = hoi["human_data"]["poses"]
obj_pose = hoi["object_data"]["object_poses"]
print("num frames:", poses.shape[0])
print("human poses:", poses.shape)
print("object poses:", obj_pose.shape)
Tên key có thể thay đổi theo phiên bản code, nhưng pattern thường là:
human_data: pose, translation, body params, keypoints hoặc joints.object_data: object pose/trajectory theo frame.meta: đường dẫn mesh, file object pose thô, masks cache, render config.contact: contact labels hoặc contact points nếu đã post-process.
Bạn đang tìm ba điều:
- Số frame hợp lý, không rỗng, không ngắn bất thường.
- Human/object arrays có cùng chiều thời gian.
meta.obj_path,masks_cache_file,render_config_filetrỏ đúng artifact của video.
Nếu hoi_data.pkl pass nhưng visualization fail, hãy ưu tiên visualization. Dataset tốt là dataset có thể nhìn lại và giải thích được, không chỉ là pickle có đủ key.
Chỉnh manip_smplx.yaml theo tình huống
Bốn field người mới nên nhớ:
| Field | Mặc định | Khi nào đổi |
|---|---|---|
optimization.opt_stage_specs.init_opt |
Stage tối ưu ban đầu | Khi pose/object/depth đã đúng cache nhưng alignment chưa tốt |
optimization.opt_stage_specs.contact_opt |
Stage tối ưu contact | Khi tay/object gần đúng nhưng contact sai |
filtering.filter_object_motion |
dynamic_only |
Giữ cho manipulation chỉ nhận object có chuyển động |
pipeline.is_static_obj |
false |
Chỉ đổi thành true cho terrain/static object |
Ví dụ giữ manipulation dynamic:
filtering:
filter_object_motion: "dynamic_only"
object_static_thr: 0.02
pipeline:
is_static_obj: false
Ví dụ nếu bạn cố tình tái dựng một scene static để debug:
python -m grail.pipelines.recon_4dhoi \
--dataset ComAsset \
--category cordless_drill \
--results_dir results \
--is_static_obj
Nhưng đừng dùng static mode cho pickup thật. Nó có thể giúp debug mask/depth, nhưng không tạo object trajectory động đúng cho manipulation.
Debug theo thứ tự nào?
Đừng bắt đầu bằng việc tăng loss weight. Hãy debug theo thứ tự artifact:
- Mở video input trong
results/generation/videos_kling. - Kiểm tra stage 1 keypoint/body cache nếu người trượt.
- Kiểm tra mask
.npzhoặc debug mask nếu object mất. - Kiểm tra
poses_in_cam.pklbằng visualization FoundationPose nếu object pose sai. - Chạy lại stage 4 sau khi chỉnh
init_opthoặccontact_opt. - Chỉ nới filter khi bạn hiểu vì sao filter fail.
- Mở
recon_comparison.mp4vàrecon_result.htmltrước khi đưa dữ liệu sang retarget.
Với batch lớn, dùng sharding:
python -m grail.pipelines.recon_4dhoi \
--dataset ComAsset \
--results_dir results \
--job_chunk_idx 0 \
--num_job_chunks 8
Tài liệu GRAIL ghi một run 8 chunk có thể xử lý khoảng 24 video trong khoảng 35 phút wall-clock. Điểm quan trọng là cache: sau khi stage 1-3 ổn định, bạn có thể lặp stage 4-5 nhanh hơn nhiều so với chạy lại toàn bộ.
Kết luận
grail.pipelines.recon_4dhoi không chỉ "reconstruct video". Nó là cầu nối giữa video foundation model và dữ liệu robot học được. GEM-SMPL/WiLoR tạo prior người và tay. SAM2/MoGe biến RGB thành mask/depth. FoundationPose bám object 6-DoF bằng mesh đã biết. HOIOptimizer gom tất cả thành trajectory có contact. Filtering loại kết quả tệ. ScenePic/PyTorch3D giúp bạn kiểm tra trước khi retarget.
Điểm thực dụng nhất: hãy tin artifact hơn tin log. hoi_data.pkl cho bạn dữ liệu, nhưng recon_result.mp4, recon_comparison.mp4 và recon_result.html mới cho bạn biết dữ liệu đó có đáng dùng không. Khi reconstruction đã ổn, bài 5 sẽ chuyển trajectory người/object sang Unitree G1; còn bài 6 sẽ đóng gói motion này cho training và export.