Early 2026, while major tech corporations were racing to build proprietary robot intelligence platforms behind closed doors, Xiaomi quietly dropped something unexpected: Xiaomi-Robotics-0 — a 4.7-billion-parameter Vision-Language-Action (VLA) model, fully open-source, capable of real-time robot control at 80ms inference latency on a consumer RTX 4090.
No data center. No cloud compute. No need to be Google or DeepMind.
This article explains the model architecture, the key technical innovations, and walks you step-by-step through installation and inference. If you've read about Diffusion Policy or previous-generation VLA models, you'll find Xiaomi-Robotics-0 represents a genuinely interesting leap forward.
Why Xiaomi-Robotics-0 Matters
Before diving into the technical details, let's understand why the robotics community is paying attention:
1. Small but not lightweight. 4.7B parameters is modest by today's LLM standards — but this is a deliberate tradeoff. Smaller model = faster inference = runs on commodity hardware. For robots, response latency is life-or-death for task performance.
2. Truly open-source. Not just open weights — Xiaomi released full code, checkpoints, and detailed technical documentation. You can fine-tune it, study it, and deploy it however you need.
3. 30Hz control frequency. Robots need smooth, continuous control. 30 frames per second is sufficient for complex manipulation tasks like towel folding or precision assembly.
4. Impressive benchmark numbers. 98.7% success rate on LIBERO — the standard benchmark suite in robot learning research.
Architecture — Two Brains, One Model
Imagine learning to cook. Part of your brain looks at the ingredients and understands "that's a carrot, that's a cutting board, it needs to be sliced thin." The other part commands your hand to execute each smooth, continuous knife stroke. Xiaomi-Robotics-0 works in exactly this way, with two distinct modules:

Module 1: VLM Backbone — Qwen3-VL-4B-Instruct
Qwen3-VL (Alibaba's Vision-Language Model) is the "cognitive brain" of the system. It receives:
- Images from the robot's cameras (wrist-mounted view, overhead view)
- Language instructions from the user ("pick up the red box and place it in the right tray")
- Proprioceptive state information (joint angles, applied forces, end-effector position)
From these inputs, the VLM generates a KV cache — essentially a compressed "context summary" encoding everything about the robot's current situation. This KV cache is the critical bridge between "understanding" and "acting."
Module 2: Diffusion Transformer (DiT) — The Motor Brain
The DiT generates the concrete motor commands the robot actually executes. It receives the KV cache from the VLM and uses flow matching — an efficient variant of diffusion — to produce a sequence of T consecutive actions (an action chunk).
If you're familiar with Diffusion Policy, this is a similar concept but deeply integrated with a VLM through cross-attention. The DiT has 16 layers, each conditioned on KV cache from the final 16 layers of the VLM.
Why flow matching instead of original DDPM? Speed. Flow matching requires only 5 denoising steps instead of DDPM's dozens, keeping latency at 80ms.
[Camera views] ─────┐
[Language task] ────┤──→ Qwen3-VL-4B ──→ KV Cache ──┐
[Robot state] ─────┘ │
▼
DiT (16 layers)
│
▼
Action Chunk [a₁, a₂, ..., aₜ]
Three Key Technical Innovations
The VLM + DiT architecture isn't new (see π0 fast). What makes Xiaomi-Robotics-0 stand out are three specific engineering improvements:
1. Λ-shape Attention Mask (Lambda Attention)
This is the cleverest trick in the paper. To understand why it's needed, first understand the problem:
In asynchronous execution (robot executes action A while the model computes action B), the model can become "lazy" — instead of looking at fresh camera frames to decide the next action, it might just copy the previous action forward. This is called shortcut bias.
The Λ-shape mask solves this by:
- Early action tokens (noisy, not yet committed) are allowed to attend to previously committed actions → ensures smooth temporal transitions
- Late action tokens (clean, about to execute) are blocked from attending to old actions → forces the model to look at fresh visual input
Result: the model must genuinely perceive the environment rather than plagiarize its previous answer.
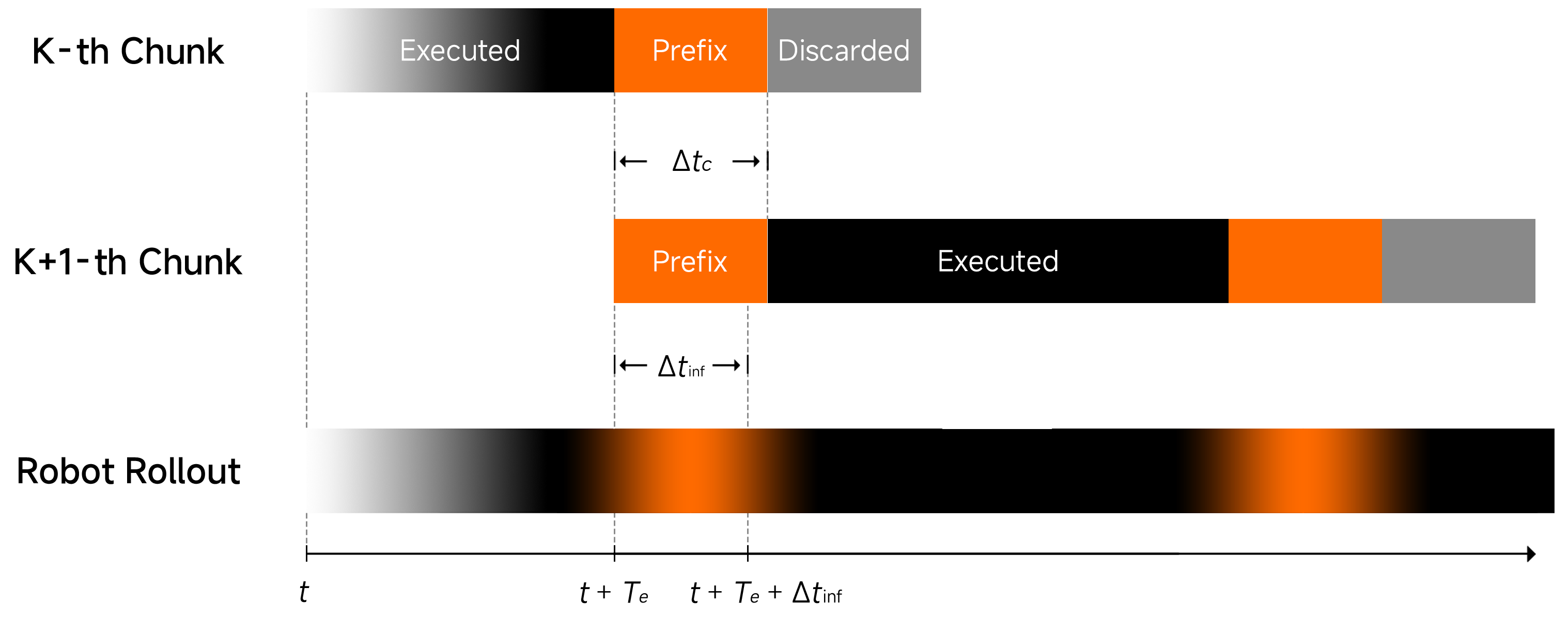
2. Action Prefixing
Rather than generating a completely fresh action chunk from scratch on every inference, the model reuses the beginning of the previous action chunk — called "committed actions." Only the tail is regenerated.
Dual benefit:
- Smooth continuity: The robot doesn't jerk between inference cycles
- Speed: Only a fraction of the action chunk needs to be recomputed
3. Asynchronous Execution

Instead of: Robot waits → Inference → Robot executes → Robot waits → ...
Xiaomi-Robotics-0 uses: Robot executes current action chunk → GPU simultaneously computes next chunk
Both happen in parallel, so the 30Hz control frequency is maintained continuously even though each inference takes 80ms.
Training Data — Where the "Experience" Comes From
This model doesn't develop skill from thin air — it learns from massive datasets:
| Data Type | Volume | Source |
|---|---|---|
| Robot trajectories | ~200M timesteps | DROID, MolmoAct, in-house bimanual |
| Vision-Language data | >80M samples | VQA, captioning, grounding, embodied reasoning |
| Lego Disassembly demos | 338 hours | In-house teleoperation |
| Towel Folding demos | 400 hours | In-house teleoperation |
The VL:robot data mixing ratio is 6:1 during Stage 1 training — ensuring the VLM doesn't "forget" its language understanding capabilities while learning robot actions.
Two-Stage Training Pipeline
Stage 1 — VLM pretraining with robot data: The VLM is trained jointly on VL tasks and robot trajectory prediction. The key technique here is Choice Policies: when multiple valid trajectories exist for the same task (a robot can pick up an object from many different angles), the model learns to commit to one trajectory rather than averaging across all — this prevents mode collapse in the action distribution.
Stage 2 — DiT training: The VLM is frozen. Only the DiT is trained from scratch using flow-matching loss. Reason for freezing: preventing catastrophic forgetting — if the entire model is trained simultaneously, the VLM risks losing language understanding.
Post-training: Additional fine-tuning with the Λ-shape attention mask and RoPE positional index offsetting to enable asynchronous execution mode.
Benchmark Results
| Benchmark | Xiaomi-Robotics-0 | Notes |
|---|---|---|
| LIBERO (Avg) | 98.7% | 4 suites: Spatial, Object, Goal, Long |
| SimplerEnv Visual Matching | 85.5% | Google Robot embodiment |
| SimplerEnv Visual Aggregation | 74.7% | Harder variant, more distractors |
| SimplerEnv WidowX | 79.2% | Bridge dataset evaluation |
| CALVIN ABCD→D | 4.80 avg tasks | Open-vocabulary manipulation |
On real robots with a dual-arm setup:
- Lego Disassembly (20 bricks): continuous disassembly with high positional accuracy
- Towel Folding: long-horizon task with deformable objects — one of the hardest categories in manipulation research
Installation — Step by Step
System Requirements
- GPU: NVIDIA RTX 4090 (24GB VRAM) — recommended. RTX 3090 (24GB) also works but slower.
- RAM: 32GB+
- Python: 3.12
- CUDA: 12.x compatible
- OS: Ubuntu 22.04 LTS (recommended)
Step 1: Create Python Environment
# Use conda to avoid dependency conflicts
conda create -n xiaomi-robotics python=3.12 -y
conda activate xiaomi-robotics
Step 2: Install PyTorch and Dependencies
# PyTorch 2.8.0 with CUDA support
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 \
--index-url https://download.pytorch.org/whl/cu128
# Specific transformers version (important!)
pip install transformers==4.57.1
# Flash Attention 2 — significantly accelerates inference
pip install flash-attn==2.8.3 --no-build-isolation
# System libraries (Ubuntu/Debian)
sudo apt-get install -y libegl1 libgl1 libgles2
Step 3: Clone Repository and Install Package
git clone https://github.com/XiaomiRobotics/Xiaomi-Robotics-0.git
cd Xiaomi-Robotics-0
pip install -e .
Step 4: Download Model Weights
Model weights are available on HuggingFace at XiaomiRobotics/Xiaomi-Robotics-0. Multiple checkpoints are available depending on your use case:
from transformers import AutoModel, AutoProcessor
# Load base model (general purpose)
model = AutoModel.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0",
trust_remote_code=True,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
).cuda().eval()
processor = AutoProcessor.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0",
trust_remote_code=True,
)
For LIBERO benchmark evaluation, use the fine-tuned checkpoint:
# LIBERO-specific checkpoint
model = AutoModel.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0-LIBERO",
trust_remote_code=True,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
).cuda().eval()
Running Inference
import torch
from transformers import AutoModel, AutoProcessor
from PIL import Image
# Initialize model and processor
model = AutoModel.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0",
trust_remote_code=True,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
).cuda().eval()
processor = AutoProcessor.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0",
trust_remote_code=True,
)
# Prepare inputs
wrist_image = Image.open("wrist_cam.jpg") # Wrist-mounted camera
front_image = Image.open("front_cam.jpg") # Front overview camera
images = [wrist_image, front_image]
instruction = "Pick up the red box and place it in the right tray"
# Proprioceptive state: joint angles, end-effector position, etc.
proprio_state = torch.zeros(1, 7).cuda() # Replace with real robot state
# Get action mask for your robot type
action_mask = processor.get_action_mask(robot_type="widowx") # or "google_robot"
# Process inputs
inputs = processor(
images=images,
text=instruction,
return_tensors="pt",
).to("cuda", dtype=torch.bfloat16)
# Inference — generate action chunk
with torch.inference_mode():
actions = model.generate_actions(
**inputs,
proprio_state=proprio_state,
action_mask=action_mask,
num_diffusion_steps=5, # 5 steps sufficient with flow matching
seed=42,
)
# actions shape: [1, T, action_dim]
# T = action chunk length (typically 16-32 steps)
# action_dim = action dimensions (7 for WidowX: 6 DoF + gripper)
print(f"Generated {actions.shape[1]} action steps")
print(f"First action: {actions[0, 0].cpu().numpy()}")

Tips for Faster Inference
# Use torch.compile for ~20% additional speedup
model = torch.compile(model, mode="reduce-overhead")
# Enable KV cache reuse for asynchronous execution
model.enable_kv_cache(max_batch_size=1, max_seq_length=512)
Comparison with Other VLA Models
| Model | Params | Inference | Control Hz | Open Source |
|---|---|---|---|---|
| Xiaomi-Robotics-0 | 4.7B | 80ms | 30Hz | ✅ Full |
| π0 fast | ~3B | ~60ms | 50Hz | ❌ Weights only |
| OpenVLA | 7B | ~200ms | 5Hz | ✅ |
| SmolVLA | 450M | ~30ms | 33Hz | ✅ |
| GR00T N1.6 | >10B | >100ms | 15Hz | ❌ |
Takeaways:
- If you need ultra-lightweight for edge deployment (Jetson Orin), SmolVLA is the better choice
- If you need the best balance of performance and speed on a consumer GPU, Xiaomi-Robotics-0 hits the sweet spot
- If you need maximum performance regardless of speed (data center), larger models will win
When Should You Use Xiaomi-Robotics-0?
Good fit when:
- You have an RTX 4090 or GPU with 24GB VRAM
- You need ≥ 30Hz control frequency for real-time manipulation
- You want to fine-tune on your own robot (especially dual-arm bimanual tasks)
- You're researching VLM + DiT architecture design
Not a good fit when:
- GPU < 16GB VRAM → consider SmolVLA or quantized versions
- Task requires complex multi-step long-horizon language planning → need a larger model
- Edge deployment on Jetson Nano → too heavy
Conclusion
Xiaomi-Robotics-0 isn't the best model on every benchmark — but it sets a new standard for practical usability: real-time, fully open-source, runs on consumer GPU. For robotics engineers working with constrained budgets, this is genuinely good news.
What I find most interesting is the design philosophy: instead of chasing parameter count, Xiaomi focused on solving a very concrete problem — how to make a VLA model control a robot smoothly, continuously, without jitter. The Λ-shape attention mask and asynchronous execution pipeline are genuinely elegant engineering solutions to a real deployment problem.
Next step? Fine-tune this model on your robot's data. Xiaomi provides complete training scripts — a major advantage over closed-source models that only let you run inference.
Paper: Xiaomi-Robotics-0: An Open-Sourced VLA Model with Real-Time Execution — Xiaomi Robotics Team, arXiv, 2026
Code & Weights: github.com/XiaomiRobotics/Xiaomi-Robotics-0