SimpleVLA-RL vs LeRobot: Two Paths to Teaching Robots Manipulation
If you have been following robot manipulation research in 2026, two names keep coming up: SimpleVLA-RL — a framework that applies Reinforcement Learning directly to VLA models in simulation, and LeRobot — HuggingFace's open-source ecosystem supporting both Imitation Learning and RL on real robots. Both frameworks tackle the same problem — teaching robots to manipulate objects — but with fundamentally different philosophies.
In this post, we will analyze the strengths and weaknesses of each framework across 8 criteria, helping you choose the right tool for your project. Spoiler: they are not competing — they are complementary.
1. RL Philosophy: Simulation vs Real Robot
This is the most fundamental difference between the two frameworks.
SimpleVLA-RL: Pure RL in Simulation
SimpleVLA-RL uses GRPO (Group Relative Policy Optimization) — a PPO variant designed for language models. The reward function is remarkably simple: binary 0/1 (success or failure). No reward shaping, no reward classifier — just a simulator returning whether the task was completed.
The entire RL process happens in simulation (LIBERO, RoboTwin). The robot tries thousands of episodes in virtual environments with zero risk of hardware damage and no supervision required. Once the policy converges, it transfers to real robots via sim-to-real transfer.
GRPO features an interesting design: asymmetric clipping with a lower bound of 0.2 and an upper bound of 1.28. This encourages the model to explore novel behaviors rather than sticking to safe strategies — which is precisely how SimpleVLA-RL discovered the pushcut phenomenon (pushing to cut instead of using scissors conventionally).
LeRobot HIL-SERL: RL Directly on Real Hardware
LeRobot takes the opposite approach with HIL-SERL (Human-in-the-Loop Sample Efficient RL). The underlying algorithm is SAC (Soft Actor-Critic) — better suited for continuous control on real hardware because it is significantly more sample efficient than PPO/GRPO.
Instead of binary rewards from a simulator, LeRobot trains a reward classifier — a CNN/ResNet network that predicts success probability from camera images. This classifier is trained from approximately 15-20 demonstrations before RL begins.
The most unique aspect: humans intervene directly during training via gamepad or keyboard. When the robot is about to collide or go off-track, the operator presses a button to "correct" the behavior. This is both safer and helps the robot learn faster — but requires constant human presence.

2. Scale and Cost
This is where the two frameworks differ most dramatically in practical terms.
| Criterion | SimpleVLA-RL | LeRobot HIL-SERL |
|---|---|---|
| VLA model | OpenVLA-OFT (7B params) | SmolVLA (450M), ACT, Pi0-FAST |
| GPU required | 8x A800 80GB (~$100K+) | 1 consumer-grade GPU |
| Robot required | None (train in sim) | SO100, Koch, etc. ($200-500) |
| Training time | Several hours on GPU cluster | Several hours on 1 GPU + robot |
| Estimated cost | $500-2000/run (cloud GPU) | $500-1000 (robot + GPU purchase) |
SimpleVLA-RL demands massive compute — 8 A800 80GB GPUs to train a 7B parameter model with online RL. This level of investment is only feasible for research labs or large companies.
LeRobot takes the opposite approach — its philosophy is to democratize robotics. SmolVLA has only 450M parameters and runs on a single GPU. The SO100 robot arm costs around $200-300. Total setup cost under $1000, making it accessible to students, hobbyists, and small startups.
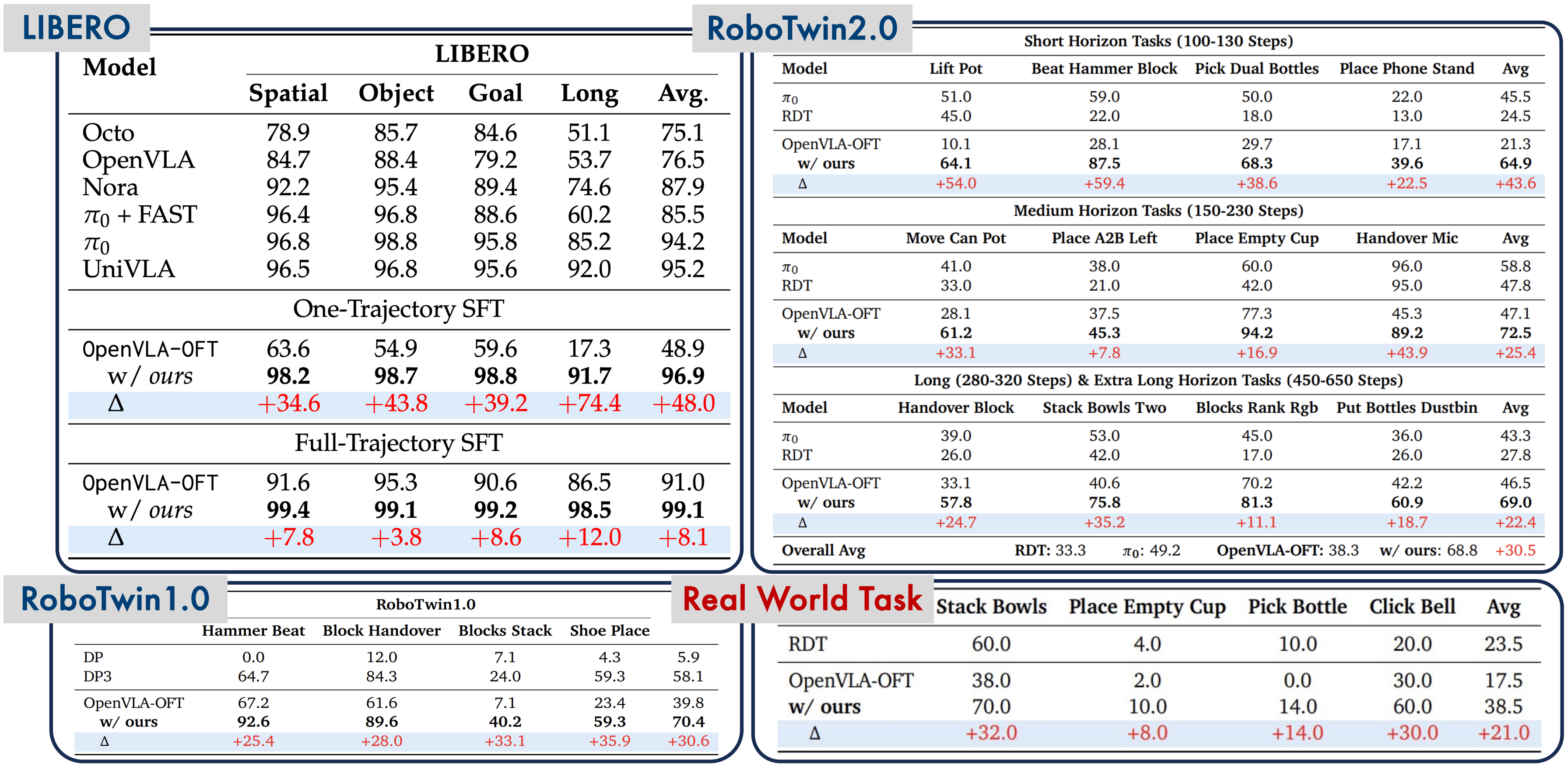
However, there is an important nuance: once SimpleVLA-RL finishes training, the policy can be deployed to many robots without additional GPU cost. LeRobot HIL-SERL must train separately on each robot (since each has different kinematics and camera configurations).
3. VLA Model Ecosystem
SimpleVLA-RL: Deep Focus on One Model
SimpleVLA-RL centers on OpenVLA-OFT — an architecture based on LLaMA2-7B combined with vision encoders. It is a powerful model, but the framework only supports this single architecture. If you want to experiment with other policies (ACT, Diffusion Policy), you need to implement them yourself.
LeRobot: The VLA Supermarket
LeRobot v0.5.1 (April 2026) supports an impressive roster of policies:
Imitation Learning:
- ACT (Action Chunking with Transformers)
- Diffusion Policy
- VQ-BeT (Vector Quantized Behavior Transformer)
- Multitask DiT
VLA Models:
- Pi0-FAST, Pi0.5
- GR00T N1.5 (NVIDIA)
- SmolVLA (450M — compact and efficient)
- XVLA
Reinforcement Learning:
- HIL-SERL (SAC + human interventions)
- TDMPC (model-based RL)
This diversity enables rapid experimentation — train an ACT baseline in 30 minutes, compare it with SmolVLA, then fine-tune Pi0-FAST if you need higher performance. This is the major advantage of an open-source ecosystem with 23K+ GitHub stars and 236 contributors.
4. Sim-to-Real vs Train-on-Real
SimpleVLA-RL: Train in Sim, Deploy on Real
The biggest advantage: no real robot needed during training. The robot attempts thousands of episodes in LIBERO or RoboTwin — failures cost nothing. But the tradeoff is facing the sim-to-real gap — differences between simulation and the real world (physics, lighting, friction, object geometry).
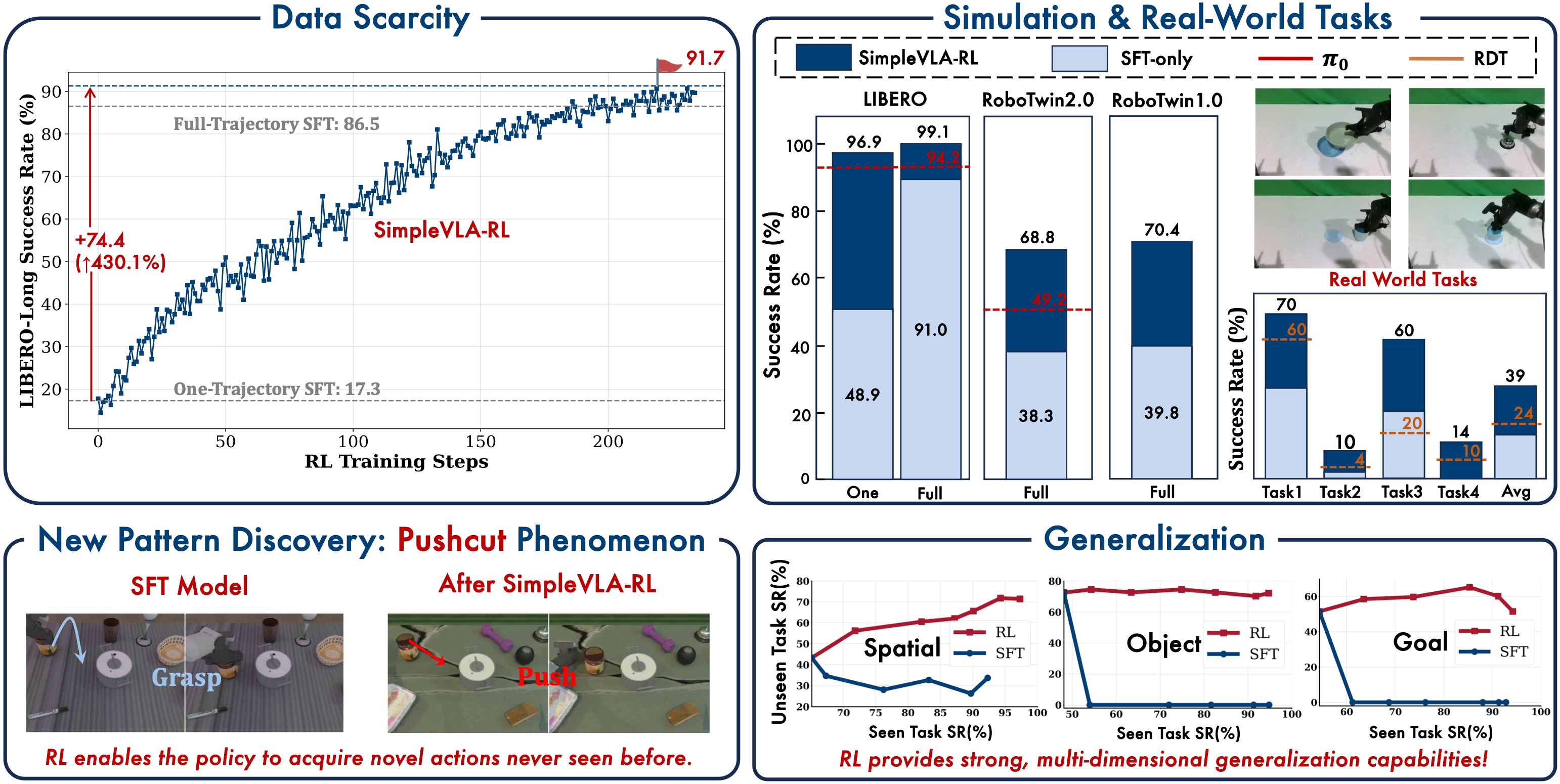
SimpleVLA-RL's sim-to-real results are encouraging: from 17.5% to 38.5% on the Piper dual-arm robot with zero demonstrations on the real robot. However, 38.5% is still far from production-ready. The sim-to-real gap remains the biggest challenge.
LeRobot HIL-SERL: Train Directly on Real
LeRobot bypasses the sim-to-real gap entirely by training directly on real hardware. Just ~15 demonstrations plus a few hours of RL on a SO100 or Koch arm achieves near-perfect performance.
The downside: it is slower (must wait for the robot to execute each action), requires continuous supervision, and the robot can be damaged if exploration is too aggressive. Actions are constrained to end-effector space (not joint space) for safety.

5. Data Efficiency: 1 Demo vs 15 Demos
This is the most surprising result from SimpleVLA-RL.
SimpleVLA-RL: Cold-Start with 1 Demo
In the cold-start experiment, SimpleVLA-RL needs only 1 demonstration for SFT (Supervised Fine-Tuning), then uses RL in simulation to improve. Result: 91.7% success rate on the LIBERO benchmark. From 1 demo to >90% — this is an unprecedented level of data efficiency.
The secret: the 7B VLA model already possesses foundational knowledge (language understanding, visual grounding) from pre-training. RL only needs to "unlock" the manipulation capability, not learn from scratch.
LeRobot HIL-SERL: ~15 Demos + Few Hours of RL
LeRobot requires more data — approximately 15-20 demonstrations to train the reward classifier and warm-start the policy. Then, a few hours of RL on the real robot (with human interventions) achieves near-perfect performance.
While more data-hungry, data collection is straightforward: teleoperate the robot by hand, record the trajectory, upload to HuggingFace Hub. The LeRobotDataset format (Parquet + MP4) makes sharing data across the community effortless.
| Metric | SimpleVLA-RL | LeRobot HIL-SERL |
|---|---|---|
| Demos required | 1 (cold-start) | ~15-20 |
| RL training time | Several hours (sim) | Several hours (real) |
| Success rate | 91.7-99.1% (sim) | Near-perfect (real) |
| Supervision needed? | No | Yes (human-in-loop) |
6. Exploration: Freedom vs Safety
SimpleVLA-RL: Free Exploration in a Sandbox
One of the most fascinating discoveries from SimpleVLA-RL is the pushcut phenomenon. When training a vegetable cutting task with scissors, instead of learning conventional scissor usage, the robot discovered that pushing the blade downward (using it like a knife) was more effective for certain vegetables.
This emerged thanks to temperature sampling at τ=1.6 — a high value that encourages the model to try novel behaviors. In simulation, bold experimentation has zero consequences — worst case, the task fails, resets, and tries again.
LeRobot HIL-SERL: Controlled Exploration
LeRobot takes a more cautious approach. Human interventions serve as safety guardrails — when the robot begins dangerous exploration (collisions, dropping objects), the operator intervenes immediately. This is safer but also limits the potential for discovering novel strategies.
SAC includes entropy regularization to encourage exploration, but at moderate levels — nowhere near as bold as GRPO with SimpleVLA-RL's asymmetric clipping.
7. Community and Ecosystem
SimpleVLA-RL: Academic Paper, Small Team
SimpleVLA-RL is a research product from ICLR 2026, developed by a small team. The code is public but the ecosystem is nascent. Documentation consists mainly of the paper and a few reproduction scripts. If you encounter bugs or want to extend functionality, you are largely on your own.
The underlying framework is veRL (Volcano Engine RL) — an RL library for LLMs from ByteDance, relatively new with a small community.
LeRobot: A Massive Ecosystem
LeRobot has the backing of HuggingFace — the company behind Transformers, Datasets, and Diffusers. The numbers speak for themselves:
- 23K+ GitHub stars
- 236 contributors
- 100+ robot models on HuggingFace Hub
- 1000+ public datasets
- Active Discord community
This ecosystem means you never train alone. Pre-trained checkpoints, ready-made datasets, tutorials, and people to help debug are all available. This is an advantage that cannot be underestimated — especially for newcomers.
LeRobot v0.5 (April 2026) also introduces many new features: Real-Time Chunking, Pi0-FAST support, 10x faster training, PEFT/LoRA fine-tuning, and EnvHub for simulation.
8. When to Use Which?
After analyzing the 7 criteria above, here are practical recommendations:
Choose SimpleVLA-RL when:
- You have a GPU cluster (8+ high-end GPUs)
- You want to train in simulation then transfer to real
- You need to scale across many tasks simultaneously (parallel sim)
- You are researching RL for VLA models
- You want to discover emergent behaviors (novel strategies)
Choose LeRobot when:
- You have a real robot and want to train directly on it
- Budget is limited (1 GPU + $300 robot)
- You need community support and a rich ecosystem
- You want to experiment with multiple VLA architectures
- You are building a real product (near-perfect real-world performance)

The Future: Combining Both?
The most interesting question is not "which one to choose" but "how to combine them." Imagine the following pipeline:
- Pre-train VLA with SFT on large-scale data (OpenVLA, Pi0)
- RL in simulation (SimpleVLA-RL style) — discover novel strategies, achieve high data efficiency, train hundreds of tasks in parallel
- Fine-tune on real robot (LeRobot HIL-SERL style) — bridge the sim-to-real gap, apply human corrections for edge cases
- Deploy with high confidence — having passed both sim training and real-world validation
This pipeline captures the best of both worlds: SimpleVLA-RL's free exploration in simulation, and LeRobot HIL-SERL's precision on real hardware. The sim-to-real gap — SimpleVLA-RL's biggest challenge — gets solved by the real-robot fine-tuning stage.
Several promising research directions to watch:
- SmolVLA + GRPO: Using LeRobot's compact 450M parameter model but training with GRPO in simulation — potentially reducing compute requirements from 8xA800 down to 1-2 GPUs
- LeRobot EnvHub + SimpleVLA-RL: Using LeRobot's simulation environments (built on Gymnasium) with SimpleVLA-RL's RL pipeline
- Shared datasets: Data from LeRobot Hub used for SFT warm-start, followed by GRPO improvement in simulation
Summary Table
| Criterion | SimpleVLA-RL | LeRobot (HIL-SERL) |
|---|---|---|
| RL Algorithm | GRPO (no KL, asymmetric clip) | SAC + human interventions |
| Training env | Simulation (LIBERO, RoboTwin) | Real robot (SO100, Koch) |
| Reward | Binary 0/1 from simulator | Learned reward classifier |
| VLA Model | OpenVLA-OFT (7B) | SmolVLA (450M), Pi0-FAST, ACT, etc. |
| Hardware | 8x A800 80GB | 1 GPU + robot arm $200-500 |
| Data efficiency | 1 demo to 91.7% | ~15 demos + few hours to near-perfect |
| Exploration | Unconstrained (τ=1.6, pushcut) | Controlled (human corrections) |
| Sim-to-real | 17.5 to 38.5% (zero-shot) | Not needed (train on real) |
| Community | Academic paper, small team | 23K+ stars, 236 contributors |
| Best for | Research, scaling, sim-to-real | Production, accessibility, real deployment |
Conclusion
SimpleVLA-RL and LeRobot are not competitors — they are two pieces of the robot learning puzzle. SimpleVLA-RL unlocks the ability to train VLA models with RL in simulation with remarkable data efficiency. LeRobot provides a complete ecosystem to turn research into real products deployed on actual robots.
If you are a researcher pushing the boundaries of VLA models, SimpleVLA-RL is the ideal playground. If you are an engineer looking to deploy robot manipulation in the real world, LeRobot is the fastest path. And if you are ambitious — combine both.
The future of robot learning is not sim or real. It is sim then real — and both frameworks play essential roles in that pipeline.
Related Posts
- SimpleVLA-RL (1): Framework Overview — Core architecture and key ideas behind SimpleVLA-RL
- AI Series (5): VLA Models — Vision-Language-Action for Robots — Foundations of modern VLA models
- LeRobot Ecosystem Guide: From Zero to Real Robot — Comprehensive guide to using the LeRobot framework