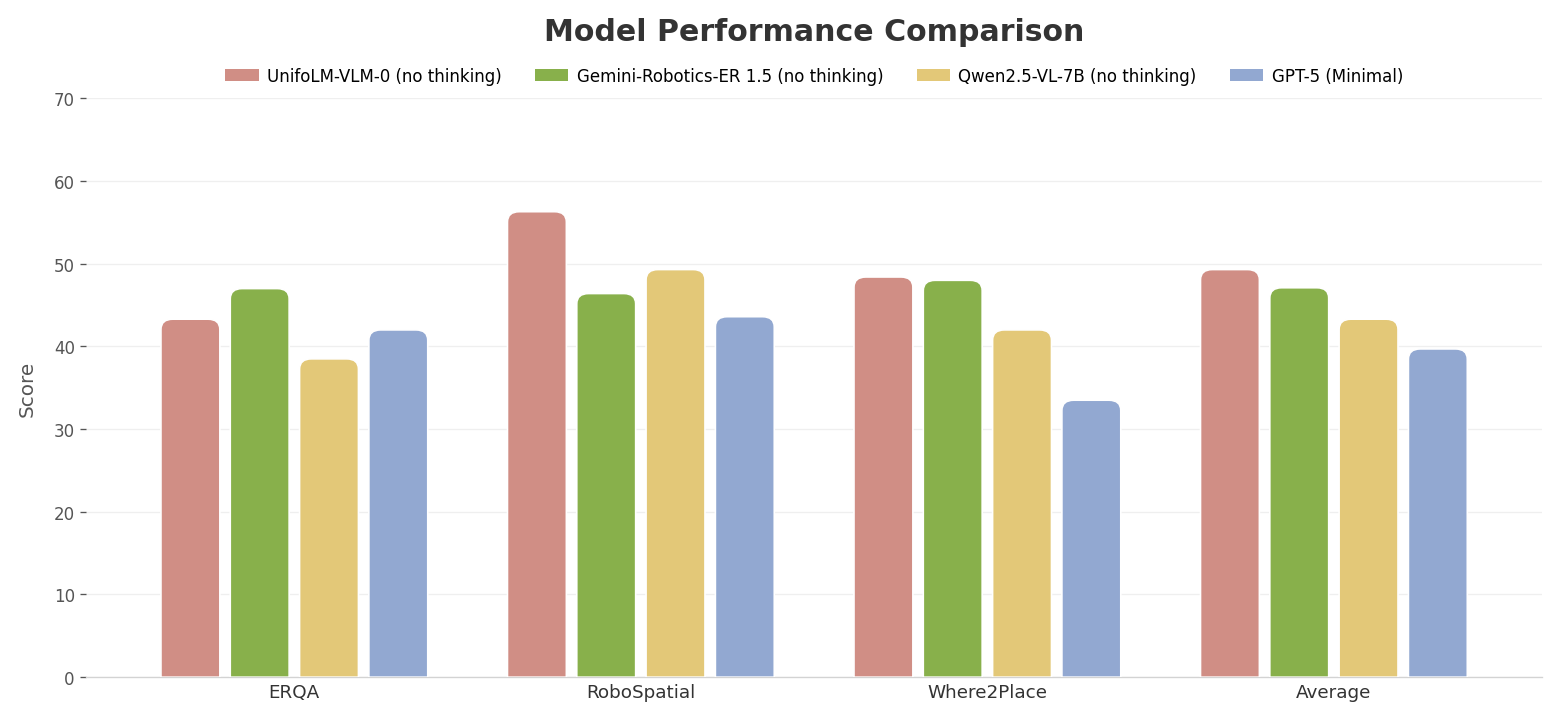
Introducing UnifoLM-VLA-0
In January 2026, Unitree Robotics officially released UnifoLM-VLA-0 — an open-source Vision-Language-Action (VLA) model specifically designed to run on the G1 humanoid robot. This marks a significant milestone in embodied AI: for the first time, a complete VLA model has been released with open-source weights, training data, a data collection pipeline, and practical deployment instructions for specific hardware.
Unlike previous VLA models such as RT-2 or OpenVLA that primarily operate on fixed robot arms, UnifoLM-VLA-0 is optimized for humanoid manipulation — meaning the robot must coordinate its whole body, maintain balance, and perform complex tasks with dexterous hands in real-world environments.

Model Architecture
Foundation: Qwen2.5-VL-7B
UnifoLM-VLA-0 is built on top of Qwen2.5-VL-7B — a 7-billion parameter Vision-Language Model developed by Alibaba. The reasons for choosing Qwen2.5-VL over other backbones (LLaMA, PaLM):
- Native vision encoder: Qwen2.5-VL has a built-in ViT (Vision Transformer) encoder capable of processing images at multiple resolutions, eliminating the need for complex adapters.
- Appropriate size: 7B parameters is large enough to capture complex patterns while still being runnable on workstation-grade GPUs (1x A100 or 2x RTX 4090).
- Multilingual support: Supports both Chinese and English — suitable for Unitree's team based in Hangzhou.
Continued Pre-training on Robot Data
The most significant differentiator of UnifoLM-VLA-0 compared to other VLAs is its continued pre-training (CPT) approach. Instead of directly fine-tuning from a pretrained VLM, Unitree adds a CPT phase with robot data:
Qwen2.5-VL-7B (pretrained VLM)
│
▼ Continued Pre-training (CPT)
│ - 500K robot interaction episodes
│ - Multi-task, multi-embodiment data
│ - Mixed with 10% original VLM data (prevents catastrophic forgetting)
│
▼ UnifoLM-VLA-0 (robot-aware VLM)
│
▼ Task-specific Fine-tuning
│ - 12 manipulation task categories
│ - G1 specific kinematics + dynamics
│
▼ Deployed UnifoLM-VLA-0
Action Space Design
UnifoLM-VLA-0 uses a tokenized action space — each action is represented as a sequence of discrete tokens, similar to how LLMs tokenize text:
# Action space for G1 upper body
# Each arm: 7 DOF (shoulder 3 + elbow 1 + wrist 3)
# Waist: 3 DOF (yaw, pitch, roll)
# Each Dex3-1 hand: 7 DOF (thumb 3 + index 2 + middle 2)
# Total: 7*2 + 3 + 7*2 = 31 DOF
ACTION_DIM = 31 # Total degrees of freedom
ACTION_BINS = 256 # Discrete bins per DOF
CHUNK_SIZE = 10 # Number of action steps predicted at once (action chunking)
# At each timestep, the model outputs:
# [action_token_1, action_token_2, ..., action_token_310]
# = 31 DOF × 10 steps = 310 tokens per prediction
Unitree G1 Upper Body Specifications
To understand how UnifoLM-VLA-0 controls the G1, you need to know the upper body hardware configuration:
| Component | DOF | Details |
|---|---|---|
| Shoulder | 3 per arm | Pitch, roll, yaw — wide range of motion |
| Elbow | 1 per arm | Flexion/extension |
| Wrist | 3 per arm | Pronation/supination, flexion, deviation |
| Waist | 1-3 | Yaw (basic), optionally pitch + roll |
| Dex3-1 Hand | 7 per hand | Thumb 3 DOF, index 2 DOF, middle 2 DOF |
The Dex3-1 Hand is Unitree's unique design — only 3 fingers (instead of 5 like a human hand) but sufficient for most manipulation tasks thanks to the opposable thumb with 3 DOF. This strategy significantly reduces complexity compared to 5-finger hands (from ~20 DOF down to 7 DOF) while maintaining diverse grasping capabilities.
12 Manipulation Task Categories
UnifoLM-VLA-0 is trained on 12 categories of manipulation tasks with a single unified policy — meaning one model handles all tasks without task-specific specialization:
- Pick and Place — Grasp objects and place them at designated locations
- Pouring — Pour liquids from one container to another
- Stacking — Stack blocks, boxes on top of each other
- Tool Use — Use tools (hammer, pliers, screwdriver)
- Drawer Open/Close — Open and close drawers
- Door Manipulation — Open doors with round knobs or lever handles
- Button Press — Press buttons, flip switches
- Cloth Folding — Fold fabric, towels
- Cable Routing — Thread wires, plug in cables
- Bimanual Tasks — Tasks requiring two-hand coordination
- In-hand Manipulation — Rotate, flip objects within the palm
- Dynamic Tasks — Catch moving objects, toss and catch

Implementation Guide
1. Environment Setup
# Create conda environment
conda create -n unifolm python=3.10 -y
conda activate unifolm
# Install PyTorch with CUDA 12.1
pip install torch==2.3.1 torchvision==0.18.1 --index-url https://download.pytorch.org/whl/cu121
# Clone repository
git clone https://github.com/unitreerobotics/unifolm-vla.git
cd unifolm-vla
# Install dependencies
pip install -e ".[all]"
# Key dependencies include:
# - transformers>=4.43.0 (for Qwen2.5-VL)
# - accelerate>=0.33.0 (distributed training)
# - deepspeed>=0.14.0 (ZeRO optimization)
# - unitree-sdk2-python>=0.2.0 (G1 control)
# - opencv-python>=4.9.0 (image processing)
# - wandb (logging)
2. Model Architecture — Detailed Code
"""
UnifoLM-VLA-0 Model Architecture
Built on Qwen2.5-VL-7B with action head for robot control
"""
import torch
import torch.nn as nn
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
class ActionHead(nn.Module):
"""
Action prediction head: transforms VLM hidden states
into discrete action tokens for the robot.
Input: hidden_states from Qwen2.5-VL (dim=3584)
Output: action_logits (batch, chunk_size * action_dim, num_bins)
"""
def __init__(
self,
hidden_dim: int = 3584, # Qwen2.5-VL-7B hidden size
action_dim: int = 31, # G1 upper body DOF
chunk_size: int = 10, # Action chunking window
num_bins: int = 256, # Discretization bins
dropout: float = 0.1,
):
super().__init__()
self.action_dim = action_dim
self.chunk_size = chunk_size
self.num_bins = num_bins
# MLP projector: VLM hidden → action space
self.projector = nn.Sequential(
nn.Linear(hidden_dim, 2048),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(2048, 1024),
nn.GELU(),
nn.Dropout(dropout),
)
# Per-DOF action predictors
# Each DOF gets its own classifier → more accurate than shared head
self.action_heads = nn.ModuleList([
nn.Linear(1024, num_bins)
for _ in range(action_dim * chunk_size)
])
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
"""
Args:
hidden_states: (batch, hidden_dim) — extracted from [ACT] token
Returns:
action_logits: (batch, chunk_size * action_dim, num_bins)
"""
# Project from VLM space to action space
features = self.projector(hidden_states) # (batch, 1024)
# Predict each DOF at each timestep
logits = []
for head in self.action_heads:
logits.append(head(features)) # (batch, num_bins)
# Stack into tensor
action_logits = torch.stack(logits, dim=1) # (batch, 310, 256)
return action_logits
class UnifoLMVLA(nn.Module):
"""
UnifoLM-VLA-0: End-to-end VLA model for Unitree G1.
Pipeline:
1. Receive image (wrist/head camera) + language instruction
2. Qwen2.5-VL encodes into hidden representations
3. ActionHead decodes into robot actions
"""
def __init__(self, model_name: str = "Qwen/Qwen2.5-VL-7B-Instruct"):
super().__init__()
# Load pretrained Qwen2.5-VL
self.vlm = Qwen2VLForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# Processor for tokenization
self.processor = AutoProcessor.from_pretrained(model_name)
# Action prediction head
self.action_head = ActionHead(
hidden_dim=self.vlm.config.hidden_size, # 3584 for 7B
action_dim=31, # G1 upper body
chunk_size=10, # 10 steps ahead
num_bins=256, # 256 discrete bins
)
# Special token [ACT] — marks position to extract action
self._add_action_token()
def _add_action_token(self):
"""Add special token [ACT] to vocabulary"""
special_tokens = {"additional_special_tokens": ["[ACT]"]}
self.processor.tokenizer.add_special_tokens(special_tokens)
self.vlm.resize_token_embeddings(len(self.processor.tokenizer))
self.act_token_id = self.processor.tokenizer.convert_tokens_to_ids("[ACT]")
def forward(
self,
images: torch.Tensor,
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
action_labels: torch.Tensor = None,
):
"""
Forward pass: image + text → actions.
Args:
images: (batch, C, H, W) — camera observation
input_ids: (batch, seq_len) — tokenized instruction + [ACT]
attention_mask: (batch, seq_len) — attention mask
action_labels: (batch, chunk_size, action_dim) — ground truth
Only used during training
"""
# 1. Forward through VLM to get hidden states
outputs = self.vlm(
input_ids=input_ids,
attention_mask=attention_mask,
pixel_values=images,
output_hidden_states=True,
)
# 2. Extract hidden state at [ACT] token position
last_hidden = outputs.hidden_states[-1] # (batch, seq, hidden)
act_mask = (input_ids == self.act_token_id)
act_hidden = last_hidden[act_mask] # (batch, hidden)
# 3. Predict actions
action_logits = self.action_head(act_hidden)
# action_logits: (batch, 310, 256)
# 4. Compute loss if training
loss = None
if action_labels is not None:
# Flatten labels: (batch, chunk_size, action_dim) → (batch, 310)
flat_labels = action_labels.reshape(-1,
self.action_head.chunk_size * self.action_head.action_dim)
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(
action_logits.reshape(-1, self.action_head.num_bins),
flat_labels.reshape(-1).long(),
)
return {
"loss": loss,
"action_logits": action_logits,
}
def predict_action(
self,
image: torch.Tensor,
instruction: str,
) -> torch.Tensor:
"""
Inference: predict action from observation + instruction.
Returns:
actions: (chunk_size, action_dim) — continuous actions
de-discretized to [-1, 1]
"""
# Tokenize instruction with [ACT] token at the end
prompt = f"Task: {instruction} [ACT]"
inputs = self.processor(
text=prompt,
images=image,
return_tensors="pt",
).to(self.vlm.device)
with torch.no_grad():
outputs = self.forward(
images=inputs["pixel_values"],
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
)
# Argmax to get discrete action
action_tokens = outputs["action_logits"].argmax(dim=-1) # (1, 310)
# De-discretize: [0, 255] → [-1.0, 1.0]
actions = (action_tokens.float() / 255.0) * 2.0 - 1.0
# Reshape: (1, 310) → (10, 31)
actions = actions.reshape(
self.action_head.chunk_size,
self.action_head.action_dim,
)
return actions
3. Data Collection — Teleoperation on G1
Data collection is the most critical step. UnifoLM-VLA-0 uses teleoperation via Unitree SDK to collect demonstration data:
"""
Data Collection Pipeline for Unitree G1
Uses Unitree SDK2 to teleoperate and record trajectories.
"""
import time
import json
import numpy as np
import cv2
from pathlib import Path
from unitree_sdk2py.core.channel import ChannelSubscriber, ChannelPublisher
from unitree_sdk2py.idl.unitree_hg import LowCmd_, LowState_
class G1DataCollector:
"""
Collects demonstration data from G1 via teleoperation.
Workflow:
1. Connect to G1 via ethernet
2. Read current state (joint angles, images)
3. Operator sends commands via VR controller / keyboard
4. Record entire trajectory (observation, action pairs)
"""
# Upper body DOF configuration
# Index mapping follows Unitree SDK convention
UPPER_BODY_JOINTS = {
# Left arm (7 DOF)
"left_shoulder_pitch": 12,
"left_shoulder_roll": 13,
"left_shoulder_yaw": 14,
"left_elbow": 15,
"left_wrist_yaw": 16,
"left_wrist_pitch": 17,
"left_wrist_roll": 18,
# Right arm (7 DOF)
"right_shoulder_pitch": 19,
"right_shoulder_roll": 20,
"right_shoulder_yaw": 21,
"right_elbow": 22,
"right_wrist_yaw": 23,
"right_wrist_pitch": 24,
"right_wrist_roll": 25,
# Waist (3 DOF)
"waist_yaw": 9,
"waist_pitch": 10,
"waist_roll": 11,
}
# Dex3-1 hand DOF (separate channel)
HAND_JOINTS = {
"left_thumb_mcp": 0, "left_thumb_pip": 1, "left_thumb_dip": 2,
"left_index_pip": 3, "left_index_dip": 4,
"left_middle_pip": 5, "left_middle_dip": 6,
"right_thumb_mcp": 7, "right_thumb_pip": 8, "right_thumb_dip": 9,
"right_index_pip": 10, "right_index_dip": 11,
"right_middle_pip": 12, "right_middle_dip": 13,
}
def __init__(self, save_dir: str, fps: int = 30):
self.save_dir = Path(save_dir)
self.save_dir.mkdir(parents=True, exist_ok=True)
self.fps = fps
self.recording = False
self.episode_data = []
self.episode_count = 0
# Camera setup (G1 has cameras on head and wrist)
self.head_cam = cv2.VideoCapture(0) # Head camera
self.wrist_cam = cv2.VideoCapture(2) # Wrist camera
# Unitree SDK subscriber for joint states
self.state_subscriber = ChannelSubscriber("rt/lowstate", LowState_)
self.state_subscriber.Init()
def get_observation(self) -> dict:
"""
Get current observation including:
- Joint positions (31 DOF)
- Camera images (head + wrist)
- Joint velocities
- Torques
"""
# Read joint state from SDK
state = self.state_subscriber.Read()
# Extract upper body joint positions
joint_pos = np.zeros(31)
idx = 0
for name, sdk_idx in self.UPPER_BODY_JOINTS.items():
joint_pos[idx] = state.motor_state[sdk_idx].q
idx += 1
# Extract hand joint positions
for name, hand_idx in self.HAND_JOINTS.items():
joint_pos[idx] = state.motor_state[26 + hand_idx].q
idx += 1
# Capture camera frames
_, head_img = self.head_cam.read()
_, wrist_img = self.wrist_cam.read()
# Resize for model input (Qwen2.5-VL accepts dynamic resolution)
head_img = cv2.resize(head_img, (640, 480))
wrist_img = cv2.resize(wrist_img, (320, 240))
return {
"joint_positions": joint_pos.copy(),
"head_image": head_img.copy(),
"wrist_image": wrist_img.copy(),
"timestamp": time.time(),
}
def record_step(self, action: np.ndarray):
"""
Record a single step: observation + action pair.
Args:
action: (31,) numpy array — target joint positions
from teleoperation input
"""
if not self.recording:
return
obs = self.get_observation()
self.episode_data.append({
"observation": obs,
"action": action.copy(),
})
def start_episode(self, task_description: str, task_category: str):
"""Start recording a new episode"""
self.recording = True
self.episode_data = []
self.current_task = task_description
self.current_category = task_category
print(f"[REC] Starting episode: {task_description}")
def end_episode(self, success: bool = True):
"""
End episode and save data.
Storage format:
save_dir/
episode_000/
metadata.json — task description, category, success
observations.npz — joint states (compressed numpy)
actions.npz — actions (compressed numpy)
images/ — camera frames (JPEG)
"""
self.recording = False
if not self.episode_data:
print("[WARN] Empty episode, skipping")
return
# Create episode directory
ep_dir = self.save_dir / f"episode_{self.episode_count:04d}"
ep_dir.mkdir(exist_ok=True)
img_dir = ep_dir / "images"
img_dir.mkdir(exist_ok=True)
# Split data
joint_positions = []
actions = []
for i, step in enumerate(self.episode_data):
joint_positions.append(step["observation"]["joint_positions"])
actions.append(step["action"])
# Save images
cv2.imwrite(
str(img_dir / f"head_{i:05d}.jpg"),
step["observation"]["head_image"],
[cv2.IMWRITE_JPEG_QUALITY, 90],
)
cv2.imwrite(
str(img_dir / f"wrist_{i:05d}.jpg"),
step["observation"]["wrist_image"],
[cv2.IMWRITE_JPEG_QUALITY, 90],
)
# Save numpy arrays
np.savez_compressed(
ep_dir / "observations.npz",
joint_positions=np.array(joint_positions),
)
np.savez_compressed(
ep_dir / "actions.npz",
actions=np.array(actions),
)
# Metadata
metadata = {
"task": self.current_task,
"category": self.current_category,
"num_steps": len(self.episode_data),
"fps": self.fps,
"success": success,
"timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
}
with open(ep_dir / "metadata.json", "w") as f:
json.dump(metadata, f, indent=2)
print(f"[SAVE] Episode {self.episode_count}: "
f"{len(self.episode_data)} steps, success={success}")
self.episode_count += 1
4. Training Pipeline
Training UnifoLM-VLA-0 consists of 2 phases: continued pre-training followed by task-specific fine-tuning. Below is the code for the fine-tuning phase (the phase users typically need to run):
"""
Training pipeline for UnifoLM-VLA-0.
Fine-tune on G1 manipulation data.
"""
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import get_cosine_schedule_with_warmup
from accelerate import Accelerator
import numpy as np
import cv2
import json
import wandb
from pathlib import Path
class G1ManipulationDataset(Dataset):
"""
Dataset loader for G1 manipulation data.
Each sample = (image, instruction, action_chunk)
"""
def __init__(
self,
data_dir: str,
processor, # Qwen2.5-VL processor
chunk_size: int = 10,
num_bins: int = 256,
action_range: tuple = (-1.0, 1.0),
):
self.data_dir = Path(data_dir)
self.processor = processor
self.chunk_size = chunk_size
self.num_bins = num_bins
self.action_range = action_range
# Scan all episodes
self.episodes = sorted(self.data_dir.glob("episode_*"))
# Build index: (episode_idx, start_step)
self.index = []
for ep_idx, ep_dir in enumerate(self.episodes):
meta = json.load(open(ep_dir / "metadata.json"))
if not meta["success"]:
continue # Skip failed episodes
num_steps = meta["num_steps"]
# Sliding window through episode
for start in range(0, num_steps - chunk_size + 1):
self.index.append((ep_idx, start))
print(f"Dataset: {len(self.episodes)} episodes, "
f"{len(self.index)} training samples")
def discretize_action(self, action: np.ndarray) -> np.ndarray:
"""
Convert continuous action [-1, 1] → discrete bin [0, 255].
Discretization allows the model to predict actions as classification
instead of regression → more stable training.
"""
lo, hi = self.action_range
normalized = (action - lo) / (hi - lo) # [0, 1]
binned = np.clip(normalized * self.num_bins, 0, self.num_bins - 1)
return binned.astype(np.int64)
def __len__(self):
return len(self.index)
def __getitem__(self, idx):
ep_idx, start = self.index[idx]
ep_dir = self.episodes[ep_idx]
# Load metadata
meta = json.load(open(ep_dir / "metadata.json"))
# Load observation image (using head camera)
img = cv2.imread(str(ep_dir / "images" / f"head_{start:05d}.jpg"))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Load action chunk
actions_data = np.load(ep_dir / "actions.npz")
action_chunk = actions_data["actions"][start:start + self.chunk_size]
# Discretize
action_labels = self.discretize_action(action_chunk)
# Format instruction
instruction = f"Task: {meta['task']} [ACT]"
# Process through Qwen2.5-VL processor
inputs = self.processor(
text=instruction,
images=img,
return_tensors="pt",
padding="max_length",
max_length=512,
truncation=True,
)
return {
"input_ids": inputs["input_ids"].squeeze(0),
"attention_mask": inputs["attention_mask"].squeeze(0),
"pixel_values": inputs["pixel_values"].squeeze(0),
"action_labels": torch.tensor(action_labels), # (10, 31)
}
def train_unifolm_vla(
data_dir: str = "./data/g1_manipulation",
output_dir: str = "./checkpoints/unifolm-vla",
num_epochs: int = 50,
batch_size: int = 8,
learning_rate: float = 1e-4,
weight_decay: float = 0.01,
warmup_ratio: float = 0.05,
gradient_accumulation_steps: int = 4,
use_wandb: bool = True,
):
"""
Main training function for UnifoLM-VLA-0.
Recommended hardware:
- 1x A100 80GB: batch_size=8, gradient_accumulation=4 (effective=32)
- 2x RTX 4090: batch_size=4, gradient_accumulation=8 (effective=32)
"""
# Accelerator for mixed precision + multi-GPU
accelerator = Accelerator(
mixed_precision="bf16",
gradient_accumulation_steps=gradient_accumulation_steps,
)
if use_wandb and accelerator.is_main_process:
wandb.init(project="unifolm-vla", name="g1-finetune")
# Model
model = UnifoLMVLA(model_name="unitreerobotics/unifolm-vla-0-base")
# Freeze VLM backbone (only train action head + LoRA adapters)
for param in model.vlm.parameters():
param.requires_grad = False
# Unfreeze last 4 layers for fine-tuning
for layer in model.vlm.model.layers[-4:]:
for param in layer.parameters():
param.requires_grad = True
# Action head is always trainable
for param in model.action_head.parameters():
param.requires_grad = True
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
total = sum(p.numel() for p in model.parameters())
print(f"Trainable: {trainable/1e6:.1f}M / {total/1e6:.1f}M "
f"({trainable/total*100:.1f}%)")
# Dataset
dataset = G1ManipulationDataset(
data_dir=data_dir,
processor=model.processor,
chunk_size=10,
)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4,
pin_memory=True,
drop_last=True,
)
# Optimizer: AdamW with weight decay
optimizer = torch.optim.AdamW(
filter(lambda p: p.requires_grad, model.parameters()),
lr=learning_rate,
weight_decay=weight_decay,
betas=(0.9, 0.95),
)
# Learning rate scheduler
total_steps = len(dataloader) * num_epochs // gradient_accumulation_steps
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=int(total_steps * warmup_ratio),
num_training_steps=total_steps,
)
# Prepare with accelerator
model, optimizer, dataloader, scheduler = accelerator.prepare(
model, optimizer, dataloader, scheduler,
)
# Training loop
global_step = 0
best_loss = float("inf")
for epoch in range(num_epochs):
model.train()
epoch_loss = 0.0
for batch_idx, batch in enumerate(dataloader):
with accelerator.accumulate(model):
outputs = model(
images=batch["pixel_values"],
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
action_labels=batch["action_labels"],
)
loss = outputs["loss"]
accelerator.backward(loss)
# Gradient clipping — important to prevent divergence
accelerator.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
epoch_loss += loss.item()
global_step += 1
# Logging
if global_step % 50 == 0 and accelerator.is_main_process:
avg_loss = epoch_loss / (batch_idx + 1)
lr = scheduler.get_last_lr()[0]
print(f"Epoch {epoch} | Step {global_step} | "
f"Loss: {avg_loss:.4f} | LR: {lr:.2e}")
if use_wandb:
wandb.log({
"loss": avg_loss,
"lr": lr,
"epoch": epoch,
"step": global_step,
})
# Save checkpoint every epoch
avg_epoch_loss = epoch_loss / len(dataloader)
if accelerator.is_main_process:
print(f"\n[Epoch {epoch}] Average Loss: {avg_epoch_loss:.4f}")
if avg_epoch_loss < best_loss:
best_loss = avg_epoch_loss
save_path = Path(output_dir) / "best_model"
accelerator.save_state(save_path)
print(f"[SAVE] Best model saved to {save_path}")
# Save periodic checkpoint
if (epoch + 1) % 10 == 0:
save_path = Path(output_dir) / f"checkpoint_epoch_{epoch+1}"
accelerator.save_state(save_path)
if use_wandb and accelerator.is_main_process:
wandb.finish()
print(f"\nTraining complete! Best loss: {best_loss:.4f}")
# Config file for training (save as config.yaml)
TRAIN_CONFIG = """
# UnifoLM-VLA-0 Training Configuration
model:
name: "unitreerobotics/unifolm-vla-0-base"
action_dim: 31
chunk_size: 10
num_bins: 256
freeze_backbone: true
unfreeze_last_n_layers: 4
data:
train_dir: "./data/g1_manipulation/train"
val_dir: "./data/g1_manipulation/val"
image_size: [640, 480]
max_text_length: 512
training:
num_epochs: 50
batch_size: 8
learning_rate: 1e-4
weight_decay: 0.01
warmup_ratio: 0.05
gradient_accumulation_steps: 4
max_grad_norm: 1.0
mixed_precision: "bf16"
# DeepSpeed ZeRO Stage 2 for multi-GPU
deepspeed:
zero_stage: 2
offload_optimizer: false
logging:
wandb_project: "unifolm-vla"
log_every_n_steps: 50
save_every_n_epochs: 10
"""
5. Inference and Deployment on G1
"""
Inference pipeline: run UnifoLM-VLA-0 directly on Unitree G1.
Hardware requirements:
- NVIDIA Jetson AGX Orin (onboard G1) or
- External workstation with GPU, connected via ethernet to G1
"""
import torch
import numpy as np
import cv2
import time
from unitree_sdk2py.core.channel import ChannelPublisher, ChannelSubscriber
from unitree_sdk2py.idl.unitree_hg import LowCmd_, LowState_
class G1VLAController:
"""
Controller running UnifoLM-VLA-0 to control G1 in real-time.
Loop:
1. Capture camera image
2. Run VLA inference → action chunk (10 steps)
3. Execute actions via low-level control
4. Repeat when action chunk is consumed or new observation arrives
"""
def __init__(
self,
model_path: str,
control_freq: int = 30, # Hz — command sending frequency
inference_freq: int = 3, # Hz — model inference frequency
kp: float = 40.0, # PD controller P gain
kd: float = 5.0, # PD controller D gain
):
self.control_freq = control_freq
self.inference_freq = inference_freq
self.kp = kp
self.kd = kd
# Load model
print("[INIT] Loading UnifoLM-VLA-0...")
self.model = UnifoLMVLA()
checkpoint = torch.load(model_path, map_location="cuda")
self.model.load_state_dict(checkpoint["model_state_dict"])
self.model.eval().cuda()
# TensorRT optimization (optional, ~2x speedup)
# self.model = torch.compile(self.model, mode="reduce-overhead")
print("[INIT] Model loaded successfully")
# Camera
self.camera = cv2.VideoCapture(0)
# Unitree SDK channels
self.cmd_publisher = ChannelPublisher("rt/lowcmd", LowCmd_)
self.cmd_publisher.Init()
self.state_subscriber = ChannelSubscriber("rt/lowstate", LowState_)
self.state_subscriber.Init()
# Action buffer
self.action_buffer = None
self.buffer_idx = 0
def capture_image(self) -> torch.Tensor:
"""Capture and preprocess camera image"""
ret, frame = self.camera.read()
if not ret:
raise RuntimeError("Camera capture failed")
# BGR → RGB
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.resize(frame, (640, 480))
return frame
def run_inference(self, image, instruction: str) -> np.ndarray:
"""
Run VLA inference → action chunk.
Returns:
actions: (chunk_size, action_dim) numpy array
"""
actions = self.model.predict_action(image, instruction)
return actions.cpu().numpy()
def send_joint_command(self, target_positions: np.ndarray):
"""
Send joint position commands to G1 via PD controller.
Args:
target_positions: (31,) — target joint angles (radians)
"""
cmd = LowCmd_()
# Upper body joints
joint_mapping = G1DataCollector.UPPER_BODY_JOINTS
idx = 0
for name, sdk_idx in joint_mapping.items():
cmd.motor_cmd[sdk_idx].mode = 0x01 # Position mode
cmd.motor_cmd[sdk_idx].q = float(target_positions[idx])
cmd.motor_cmd[sdk_idx].kp = self.kp
cmd.motor_cmd[sdk_idx].kd = self.kd
cmd.motor_cmd[sdk_idx].tau = 0.0 # No feedforward torque
idx += 1
# Hand joints
hand_mapping = G1DataCollector.HAND_JOINTS
for name, hand_idx in hand_mapping.items():
cmd.motor_cmd[26 + hand_idx].mode = 0x01
cmd.motor_cmd[26 + hand_idx].q = float(target_positions[idx])
cmd.motor_cmd[26 + hand_idx].kp = self.kp * 0.5 # Softer for hands
cmd.motor_cmd[26 + hand_idx].kd = self.kd * 0.3
idx += 1
self.cmd_publisher.Write(cmd)
def run(self, instruction: str, max_duration: float = 60.0):
"""
Main control loop.
Args:
instruction: Language instruction (e.g., "Pick up the red cup")
max_duration: Maximum execution time (seconds)
"""
print(f"[RUN] Instruction: {instruction}")
print(f"[RUN] Control: {self.control_freq}Hz, "
f"Inference: {self.inference_freq}Hz")
start_time = time.time()
inference_interval = 1.0 / self.inference_freq
control_interval = 1.0 / self.control_freq
last_inference_time = 0
while time.time() - start_time < max_duration:
loop_start = time.time()
# Run inference when needed (every ~333ms at 3Hz)
if (time.time() - last_inference_time > inference_interval
or self.action_buffer is None):
image = self.capture_image()
self.action_buffer = self.run_inference(image, instruction)
self.buffer_idx = 0
last_inference_time = time.time()
# Get next action from buffer
if self.buffer_idx < len(self.action_buffer):
action = self.action_buffer[self.buffer_idx]
self.buffer_idx += 1
# Scale from [-1, 1] to actual joint range
scaled_action = self.scale_to_joint_range(action)
# Send command
self.send_joint_command(scaled_action)
# Control rate limiting
elapsed = time.time() - loop_start
sleep_time = control_interval - elapsed
if sleep_time > 0:
time.sleep(sleep_time)
print("[DONE] Task execution complete")
@staticmethod
def scale_to_joint_range(action: np.ndarray) -> np.ndarray:
"""
Scale action [-1, 1] → actual joint angle ranges (radians).
Each joint has different range per G1 specs.
"""
# Joint limits for G1 upper body (radians)
# Format: (min, max) for each DOF
joint_limits = np.array([
# Left arm
(-3.1, 3.1), (-1.5, 1.5), (-1.5, 1.5), # shoulder
(-2.6, 0.0), # elbow
(-1.5, 1.5), (-0.5, 0.5), (-1.5, 1.5), # wrist
# Right arm
(-3.1, 3.1), (-1.5, 1.5), (-1.5, 1.5), # shoulder
(-2.6, 0.0), # elbow
(-1.5, 1.5), (-0.5, 0.5), (-1.5, 1.5), # wrist
# Waist
(-2.0, 2.0), (-0.5, 0.5), (-0.3, 0.3),
# Left hand (Dex3-1) — 7 DOF
(0.0, 1.6), (0.0, 1.2), (0.0, 1.0), # thumb
(0.0, 1.4), (0.0, 1.2), # index
(0.0, 1.4), (0.0, 1.2), # middle
# Right hand (Dex3-1) — 7 DOF
(0.0, 1.6), (0.0, 1.2), (0.0, 1.0),
(0.0, 1.4), (0.0, 1.2),
(0.0, 1.4), (0.0, 1.2),
])
# Scale: [-1, 1] → [min, max]
lo = joint_limits[:, 0]
hi = joint_limits[:, 1]
scaled = lo + (action + 1.0) / 2.0 * (hi - lo)
return np.clip(scaled, lo, hi)
# Usage example
if __name__ == "__main__":
controller = G1VLAController(
model_path="./checkpoints/unifolm-vla/best_model/model.pt",
control_freq=30,
inference_freq=3,
)
# Run task
controller.run(
instruction="Pick up the red cup and place it on the tray",
max_duration=60.0,
)

Evaluation and Analysis
Comparison with Other VLAs
| Model | Params | Open-source | Humanoid | Task Categories | Action Space |
|---|---|---|---|---|---|
| RT-2 | 55B | No | No | ~10 | Continuous |
| OpenVLA | 7B | Yes | No | 5+ | Continuous |
| pi0 | 3B | Partial | No | 7+ | Flow matching |
| UnifoLM-VLA-0 | 7B | Yes | Yes (G1) | 12 | Discrete tokens |
Strengths
-
Single policy for 12 task categories: No need to train separate models for each task — one model handles everything from simple pick-and-place to complex cloth folding.
-
Fully open-source: Includes pretrained weights, training code, data collection pipeline, and inference code. This is a major differentiator compared to RT-2 (closed) or pi0 (weights only).
-
Dexterous manipulation: Thanks to the Dex3-1 hand with 7 DOF per hand, G1 can perform tasks requiring dexterity that many standard robot arms (2-finger grippers) cannot achieve.
-
Action chunking: Predicting 10 steps at once helps smooth trajectories and reduce latency (only needs inference at 3Hz instead of 30Hz).
Limitations
-
G1-specific: The model is trained specifically for G1 — transferring to other robots requires retraining or at minimum fine-tuning the action head.
-
Strong GPU required: Real-time inference needs at least a Jetson AGX Orin or RTX 4070+ — cannot run on small edge devices.
-
Expensive teleoperation data: Collecting demonstration data via teleoperation requires experienced operators and VR equipment.
-
No locomotion integration: UnifoLM-VLA-0 only controls the upper body — legs still require a separate controller (typically an RL-based locomotion policy).
Implications for the Robotics Community
UnifoLM-VLA-0 opens up significant opportunities for robotics research groups and startups globally. With the G1 priced at approximately $16,000 USD (significantly cheaper than Boston Dynamics Atlas or Figure 02), combined with an open-source VLA model, the barrier to entry for humanoid manipulation research has dropped substantially.
Promising research directions include:
- Fine-tuning for domain-specific tasks: For example, manipulation in electronics manufacturing (component assembly), agriculture (fruit harvesting), or service (beverage preparation).
- Sim-to-real transfer: Combining UnifoLM-VLA-0 with simulators (Isaac Sim, MuJoCo) to reduce the amount of real-world data needed — see our sim-to-real pipeline article for more details.
- Multi-modal fusion: Adding tactile sensors to the Dex3-1 hand to improve grasping in real-world conditions.
Related Articles
- VLA Models: RT-2, Octo, OpenVLA, pi0 — Evolution History — A comprehensive overview of VLA evolution from 2023 to present.
- Spatial VLA — VLA with Spatial Reasoning — Analysis of VLA models combining spatial understanding.
- Imitation Learning — The Foundation for VLA — Understanding how robots learn from demonstrations, the basis of VLA.
- Humanoid Loco-Manipulation — Combining Locomotion and Manipulation — Challenges of integrating locomotion and manipulation on humanoids.
References
- UnifoLM-VLA-0: A Unified Foundation Language Model for Vision-Language-Action on Humanoid Robots — Unitree Robotics, January 2026
- GitHub Repository: unitreerobotics/unifolm-vla — Source code, pretrained weights, sample data
- Qwen2.5-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution — Wang et al., Alibaba Group, 2024
- OpenVLA: An Open-Source Vision-Language-Action Model — Kim et al., Stanford / UC Berkeley, 2024
- pi0: A Vision-Language-Action Flow Model for General Robot Control — Physical Intelligence, 2024